点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:京东探索研究院
人像抠图,是指从人物图像中提取人物前景,是计算机视觉领域的基础研究问题之一[1,2,3,4,8],在下游任务上应用非常广泛,例如视频会议,电影制作,直播软件等等[7]。鉴于人物图像中经常包含人脸等个人核心隐私,如何防止该类信息被滥用成为一个很重要的问题。然而,之前所有的人像抠图方法都忽略了对于人像隐私信息的保护。使得如何在保护隐私信息的同时,取得高精度的人像抠图结果,成为一个未被探索过的开放问题。
最近,探索研究院联合悉尼大学、Adobe等机构,首次提出面向人像隐私保护的人像抠图任务,并构建了一个目前为止最大型的人像抠图数据集P3M-10k,涵盖10,421张保护了人脸隐私的训练集和两个没有人像隐私问题的测试集。此外,我们基于vision transformer设计了一种端到端的人像抠图模型P3M-Net, 在只使用人像隐私保护的数据训练之后,在多个公开的人像测试集都取得了最优的结果。
模型训练均不涉及人像隐私数据,解决了人像抠图任务中的隐私保护问题。


01
研究背景
近期,由于多媒体行业的兴盛,全自动化人像抠图成为一个备受关注的方向[3,4]。然而,如何解决人像抠图任务中涉及到的人脸信息的隐私问题,成为一个未被关注和研究的领域。在本项研究中,我们提出了一个人像抠图新任务,探索如何在不涉及人脸隐私信息的同时能达到高精度人像抠图结果。为了促进该新任务的研究和评估,我们构建了一个目前为止最大的隐私保护的人像抠图数据集P3M-10k。
此外,以前的人像抠图方法大多需要使用人为生成的辅助信息(三分图,粗糙的分割图,草图等)来帮助完成抠图。而仅有的几种全自动人像抠图网络也是基于CNN的单分支编码-解码网络。不同于上述方法,我们设计了一种全新的基于vision transformer的多分支全自动抠图网络,在诸多公开的人像数据测试集上达到了最优的表现。
02
PPT 任务 和 P3M-10k数据集
为了探索如何在不涉及人脸隐私的同时达到高精度人像抠图,我们提出了一个新的任务,在人脸被保护的抠图数据上进行训练,让模型能够泛化到任意图像上,包括人脸隐私被保护的图像和普通完整人像。我们称之为Privacy Preserving Training (PPT) 任务。
为了探索PPT任务,我们构建了目前为止最大的具备隐私保护的人像抠图数据集 P3M-10k。P3M-10k包括了10,421张人脸隐私被保护的图片,和对应的精细抠图标注。其中训练集有9,421张人脸被遮挡的高清人像图片。测试集分为两个: (1) P3M-500-P提供了500张人脸隐私信息被遮挡的人像及高精度标注,用以验证模型在隐私保护情况下的抠图效果; (2) P3M-500-NP则提供了500张名人的人像图像,其人脸信息是可公开的,用以验证模型在普通完整人像上的泛化能力。下图展示了数据集中的部分图片和精细抠图标注。(a) 训练集样张 (b) 测试集 P3M-500-P 样张 (c) 测试集 P3M-500-NP样张。左图为人像,右图为标注信息。

我们在P3M-10k数据集上训练并测试了现有的抠图算法,包括基于辅助信息的抠图方法和全自动抠图方法,并且进一步探讨了因为隐私保护(即PPT任务)而产生的模型泛化能力的差异。具体实验结果可见论文[1,2]。实验结果表明,大部分的全自动抠图方法都因为采用了人脸被保护的数据进行训练,能够在人脸被遮挡的图片上表现良好,却无法很好地泛化到普通完整的人像图片上。如何缓解全自动抠图方法泛化性能差的问题,是本项研究的目标之一。另外,我们也发现由一个共享编码器,和两个不同任务的解码器组成的结构能够有效缓解因隐私保护而产生的抠图模型泛化能力差的问题。基于此,我们设计了全新的单编码器-双解码器的人像抠图模型P3M-Net。
03
全新端到端抠图网络 P3M-NET
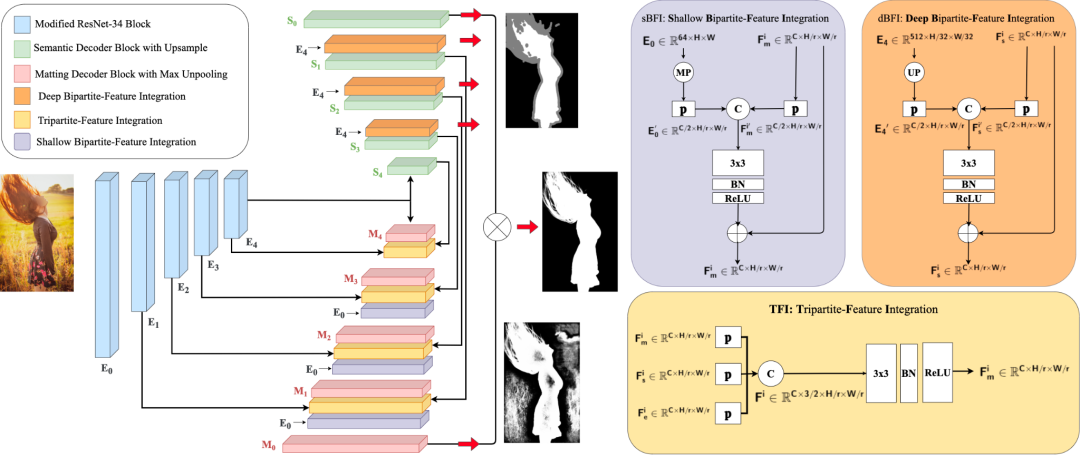
首先,我们将全自动化人像抠图任务分解成人像语义信息获取和人像细节信息提取两个子任务。基于此,我们设计的P3M-Net由一个共享的编码器和两个分开的解码器组成,分别进行共同特征提取和完成上述两个子任务。我们还设计了一个三方特征融合模块,为了促进两个子任务之间的信息交互,使得预测错误可以在深层网络里被逐步纠正。此外,我们还额外设计了一个深层双向特征融合模块和浅层双向特征融合模块来确保每个子任务与其对应的不同层次的编码进行充分的融合。后续的实验验证了我们所提出的三个模块的作用。
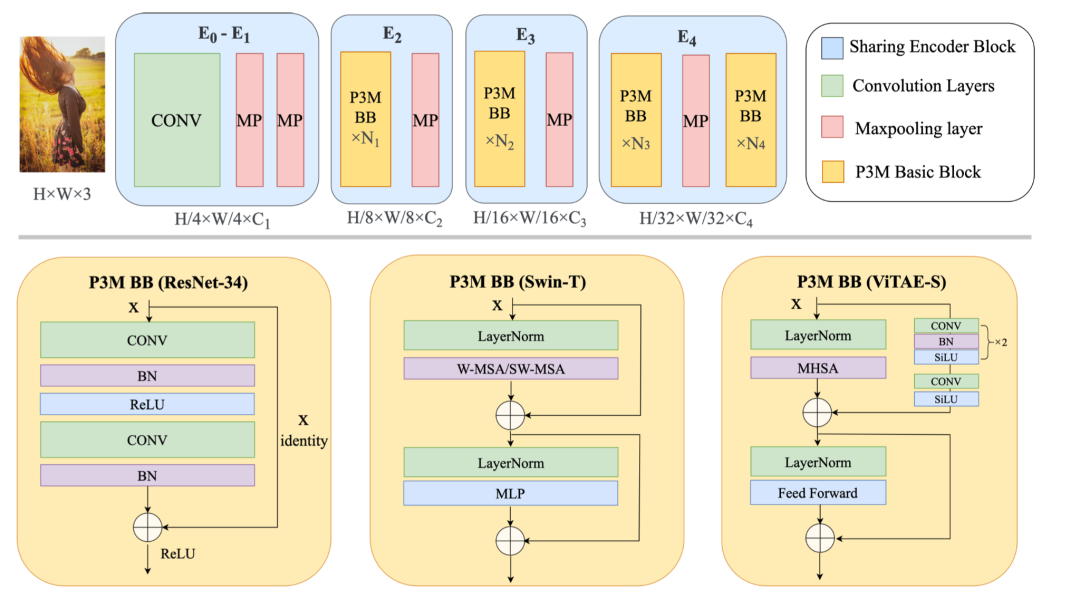
另外,我们也探究了使用CNN和vision transformer作为编码模块的性能差异。具体的,我们使用了ResNet-34[9], Swin Transformer[10]和ViTAE Transformer[5,6]作为我们的基础模块。我们观察到,Swin相比于ResNet, 鉴于它具有更好的长距关系建模能力,使得它对于语义层面的提取能力更强。相比于CNN和Swin,ViTAE在具有长距关系建模能力的同时,还保有CNN的局部性和不变性建模能力,使其具有很强的语义提取能力,同时对于人物图像中细节的感知能力也更胜一筹。我们在后面的主观和客观结果中都说明了这一点。
04
隐私数据训练的影响与研究
尽管P3M-Net模型缓解了PPT任务下对于普通人像上的泛化性能降低的问题,但依然存在人脸部分虚化,前后景语义错误的情况。为了进一步解决这个问题,我们提出了Copy and Paste (P3M-CP) 模块。这是一个即插即用的模块,能够将可公开的人脸信息注入到任意抠图模型中,有效缓解PPT设置带来的泛化性能下降的问题。
P3M-CP 模块能够在数据和特征两个层面提取公开的名人人像中的人脸信息,用 “copy and paste” 的模式注入到模型中,补充训练阶段的缺乏的人脸信息,因此提升模型在完整人像上的泛化能力。下图中展示了P3M-CP如何从source domain(名人数据)向target domain(隐私保护下的训练数据)注入信息的过程。具体的,P3M-CP可以在数据层面(P3M-ICP)和特征层面(P3M-FCP)上分别进行。

05
实验结果
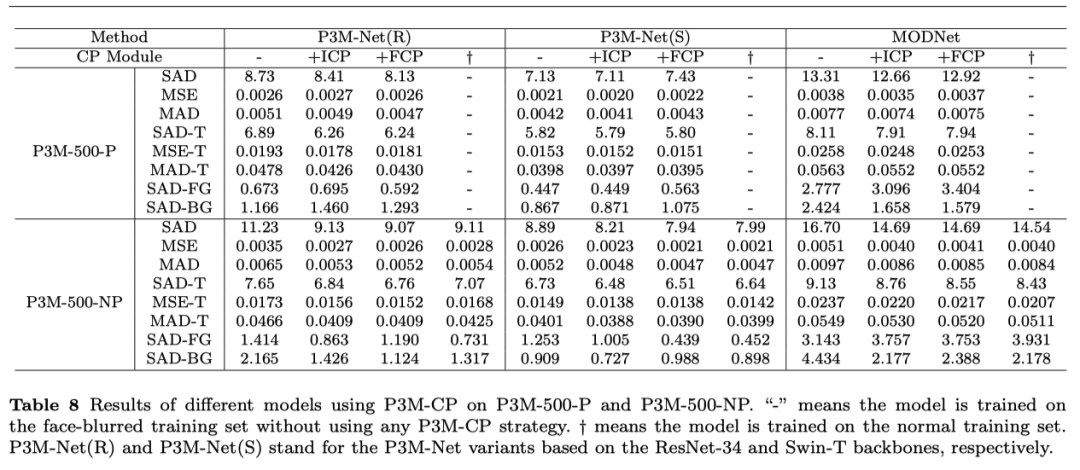
为了验证P3M-Net 模型在人像抠图下的效果,我们在P3M-10k 的训练集上进行训练,在两个测试集上进行验证。其中P3M-500-P测试集能够验证模型在隐私保护下的抠图效果,而P3M-500-NP测试集则可以检验模型在人脸被模糊的情况下训练后在完整人像上的泛化能力。我们采用了MSE, SAD, GRAD, CONN等评价指标。客观结果如下表所示。主观效果如下图所示。可以看出,我们所有的P3M-Net变种都超越了目前所有的前沿抠图模型,优势明显。
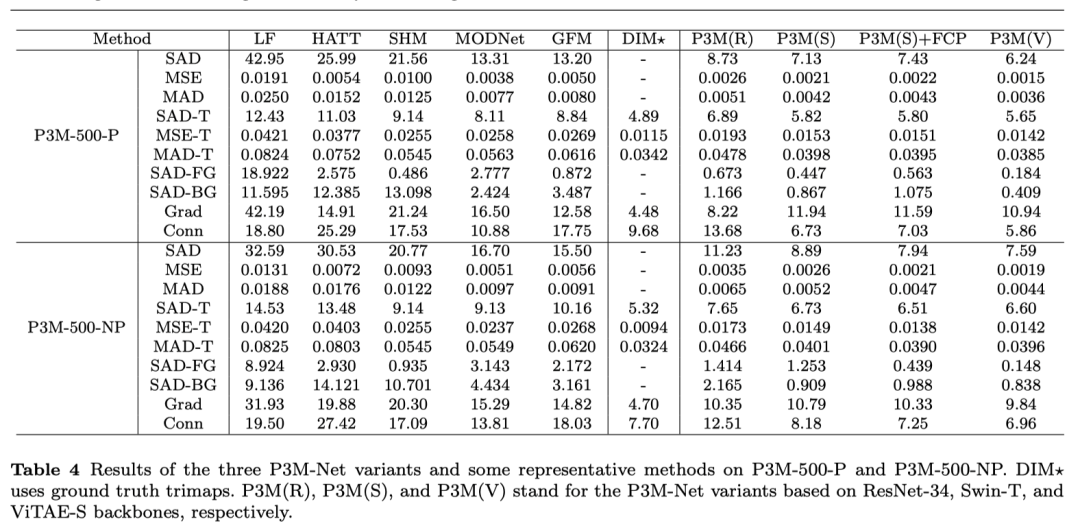


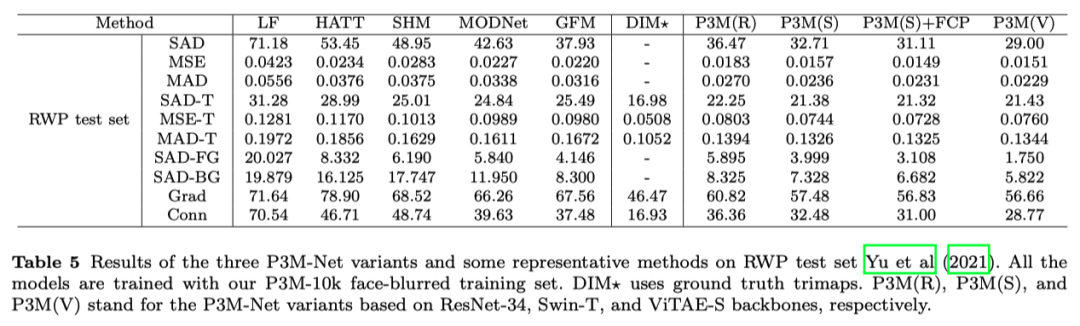
另外,我们在Adobe发布的 RWP test set上也进行了测试,进一步验证模型的性能。我们的模型均由P3M-10k训练集进行训练,在RWP test set上直接测试。测试结果如下。可见,P3M-Net依然表现最优,证明了其具有很强的跨数据集泛化能力。
另外我们对P3M-CP 模型进行了消融实验,实验结果证明P3M-CP在大部分模型上都能够显著提升对普通图像的泛化能力,甚至达到了和在普通图像上训练一致的效果。值得注意的是,P3M-Net ViTAE 模型由于自身已经具有了优异的泛化能力,在不加任何模块的情况下,也能够取得非常满意的泛化效果。
未来我们将在模型设计和训练方法层面,进一步研究隐私保护下的人像抠图问题。针对视频数据,研究轻量化人像抠图模型,降低模型复杂度,提升推理速度。我们希望本项研究能促进社区关注人像抠图任务中的隐私保护问题,并进一步激发相关问题的深入研究。
论文链接:
https://dl.acm.org/doi/10.1145/3474085.3475512
https://arxiv.org/abs/2203.16828
Github链接
https://github.com/JizhiziLi/P3M
https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting
参考文献
1. Li, J., Ma, S., Zhang, J., & Tao, D. (2021, October). Privacy-preserving portrait matting. In Proceedings of the 29th ACM International Conference on Multimedia (pp. 3501-3509).
2. Ma, S., Li, J., Zhang, J., Zhang, H., & Tao, D. (2022). Rethinking Portrait Matting with Privacy Preserving. arXiv preprint arXiv:2203.16828.
3. Li, J., Zhang, J., Maybank, S. J., & Tao, D. (2022). Bridging composite and real: towards end-to-end deep image matting. International Journal of Computer Vision, 1-21.
4. Li, J., Zhang, J., & Tao, D. (2021). Deep Automatic Natural Image Matting. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, {IJCAI-21}
5. Xu, Y., Zhang, Q., Zhang, J., & Tao, D. (2021). ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias. NeurIPS 2021.
6. Zhang, Q., Xu, Y., Zhang, J., & Tao, D. (2022). Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond. arXiv preprint arXiv:2202.10108.
7. Zhang, J., & Tao, D. (2020). Empowering things with intelligence: a survey of the progress, challenges, and opportunities in artificial intelligence of things. IEEE Internet of Things Journal, 8(10), 7789-7817.
8. Levin, A., Lischinski, D., & Weiss, Y. (2007). A closed-form solution to natural image matting. IEEE transactions on pattern analysis and machine intelligence, 30(2), 228-242.
9. He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
10. Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., ... & Guo, B. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10012-10022).
THE END
点击进入—> CV 微信技术交流群
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()