深度学习AI美颜系列----基于抠图的人像特效算法
美颜算法的重点在于美颜,也就是增加颜值,颜值的广定义,可以延伸到整个人体范围,也就是说,你的颜值不单单和你的脸有关系,还跟你穿什么衣服,什么鞋子相关,基于这个定义(这个定义是本人自己的说法,没有权威性考究),今天我们基于人体抠图来做一些人像特效算法。
抠图技术很早之前就有很多论文研究,但是深度学习的出现,大大的提高了抠图的精度,从CNN到FCN/FCN+/UNet等等,论文层出不穷,比如这篇Automatic Portrait Segmentation for Image Stylization,在FCN的基础上,提出了FCN+,专门针对人像抠图,效果如下:

图a是人像原图,图b是分割的Mask,图cde是基于Mask所做的一些效果滤镜;
要了解这篇论文,首先我们需要了解FCN,用FCN做图像分割:
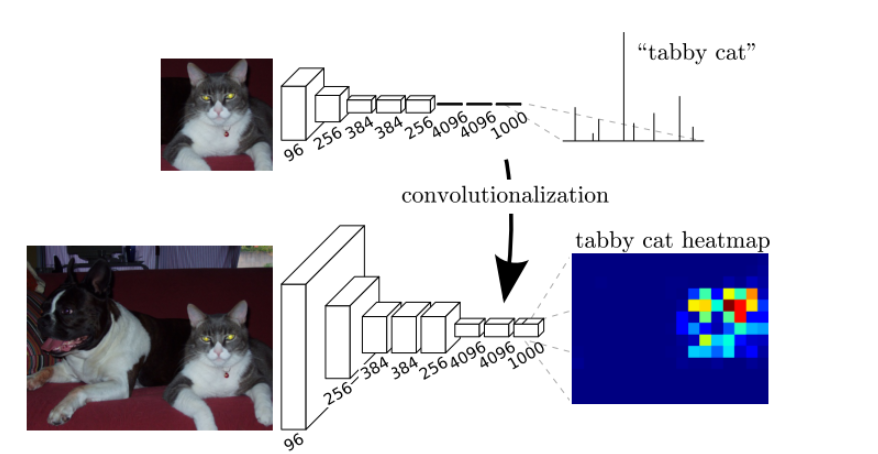
该图中上面部分是CNN做图像分割的网络模型,可以看到,最后是全连接层来处理的,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率;而下图部分是FCN,它将最后的三个全连接层换成了卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1),这样以来,所有层都是卷积层,因此称为全卷积网络;
FCN网络流程如下:
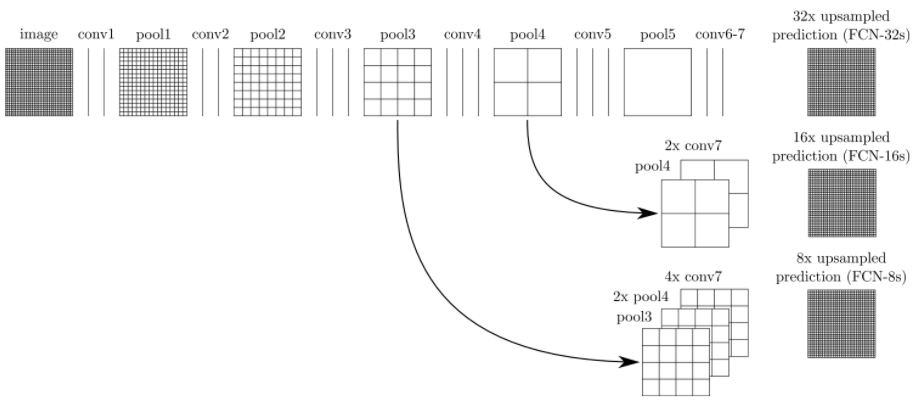
在这个网络中,经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍,对于第5层的输出,是缩小32倍的小图,我们需要将其进行上采样反卷积来得到原图大小的分辨率,也就是32倍放大,这样得到的结果就是FCN-32s,由于放大32倍,所以很不精确,因此,我们对第4层和第3层依次进行了反卷积放大,以求得到更加精细的分割结果,这个就是FCN的图像分割算法流程。
与传统CNN相比FCN的的优缺点如下:

优点:
①可以接受任意大小的输入图像,而不用要求所有的训练图像和测试图像具有同样的尺寸;
②更加高效,避免了由于使用像素块而带来的重复存储和计算卷积的问题;
缺点:
①得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感;
②没有充分考虑像素与像素之间的关系,也就是丢失了空间信息的考虑;
在了解了FCN之后,就容易理解FCN+了,Automatic Portrait Segmentation for Image Stylization这篇论文就是针对FCN的缺点,进行了改进,在输入的数据中添加了人脸的空间位置信息,形状信息,以求得到精确的分割结果,如下图所示:
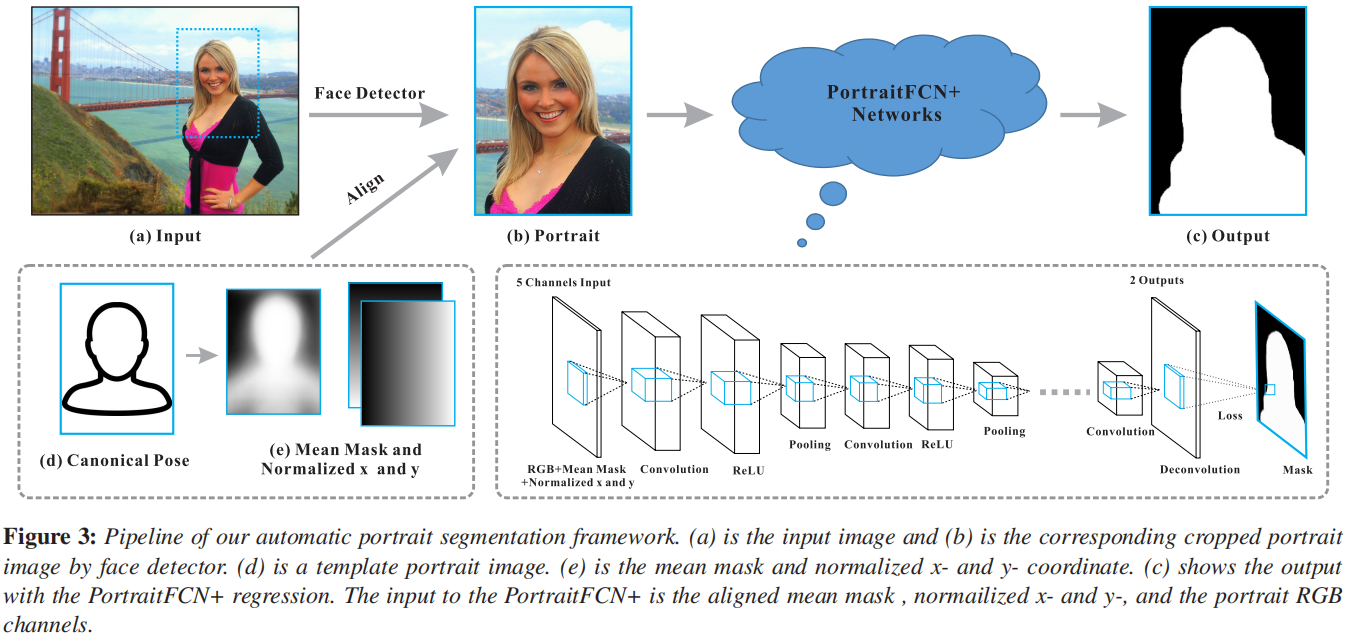
对于位置和形状数据的生成:
位置通道:标识像素与人脸的相对位置,由于每张图片位置都不一样,我们采用归一化的x和y通道(像素的坐标),坐标以第一次检测到人脸特征点为准,并预估了匹配到的特征与人体标准姿势之间的一个单应变换T,我们将归一化的x通道定义为T(ximg),其中ximg是以人脸中心位置为0点的x坐标,同理y也是如此。这样,我们就得到了每个像素相对于人脸的位置(尺寸也有相应于人脸大小的缩放),形成了x和y通道。
形状通道:参考人像的标准形状(脸和部分上身),我们定义了一个形状通道。首先用我们的数据集计算一个对齐的平均人像mask。计算方法为:对每一对人像+mask,用上一步得到的单应变换T对mask做变换,变换到人体标准姿势,然后求均值。
W取值为0或1,当变换后在人像内的取值为1,否则为0。
然后就可以对平均mask类似地变换以与输入人像的面部特征点对齐。
论文对应的代码链接:点击打开链接
主体FCN+代码:
- from __future__ import print_function
- import tensorflow as tf
- import numpy as np
- import TensorflowUtils_plus as utils
- #import read_MITSceneParsingData as scene_parsing
- import datetime
- #import BatchDatsetReader as dataset
- from portrait_plus import BatchDatset, TestDataset
- from PIL import Image
- from six.moves import xrange
- from scipy import misc
- FLAGS = tf.flags.FLAGS
- tf.flags.DEFINE_integer("batch_size", "5", "batch size for training")
- tf.flags.DEFINE_string("logs_dir", "logs/", "path to logs directory")
- tf.flags.DEFINE_string("data_dir", "Data_zoo/MIT_SceneParsing/", "path to dataset")
- tf.flags.DEFINE_float("learning_rate", "1e-4", "Learning rate for Adam Optimizer")
- tf.flags.DEFINE_string("model_dir", "Model_zoo/", "Path to vgg model mat")
- tf.flags.DEFINE_bool('debug', "False", "Debug mode: True/ False")
- tf.flags.DEFINE_string('mode', "train", "Mode train/ test/ visualize")
- MODEL_URL = 'http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat'
- MAX_ITERATION = int(1e5 + 1)
- NUM_OF_CLASSESS = 2
- IMAGE_WIDTH = 600
- IMAGE_HEIGHT = 800
- def vgg_net(weights, image):
- layers = (
- 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
- 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
- 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
- 'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
- 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
- 'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
- 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
- 'relu5_3', 'conv5_4', 'relu5_4'
- )
- net = {}
- current = image
- for i, name in enumerate(layers):
- if name in ['conv3_4', 'relu3_4', 'conv4_4', 'relu4_4', 'conv5_4', 'relu5_4']:
- continue
- kind = name[:4]
- if kind == 'conv':
- kernels, bias = weights[i][0][0][0][0]
- # matconvnet: weights are [width, height, in_channels, out_channels]
- # tensorflow: weights are [height, width, in_channels, out_channels]
- kernels = utils.get_variable(np.transpose(kernels, (1, 0, 2, 3)), name=name + "_w")
- bias = utils.get_variable(bias.reshape(-1), name=name + "_b")
- current = utils.conv2d_basic(current, kernels, bias)
- elif kind == 'relu':
- current = tf.nn.relu(current, name=name)
- if FLAGS.debug:
- utils.add_activation_summary(current)
- elif kind == 'pool':
- current = utils.avg_pool_2x2(current)
- net[name] = current
- return net
- def inference(image, keep_prob):
- """
- Semantic segmentation network definition
- :param image: input image. Should have values in range 0-255
- :param keep_prob:
- :return:
- """
- print("setting up vgg initialized conv layers ...")
- model_data = utils.get_model_data(FLAGS.model_dir, MODEL_URL)
- mean = model_data['normalization'][0][0][0]
- mean_pixel = np.mean(mean, axis=(0, 1))
- weights = np.squeeze(model_data['layers'])
- #processed_image = utils.process_image(image, mean_pixel)
- with tf.variable_scope("inference"):
- image_net = vgg_net(weights, image)
- conv_final_layer = image_net["conv5_3"]
- pool5 = utils.max_pool_2x2(conv_final_layer)
- W6 = utils.weight_variable([7, 7, 512, 4096], name="W6")
- b6 = utils.bias_variable([4096], name="b6")
- conv6 = utils.conv2d_basic(pool5, W6, b6)
- relu6 = tf.nn.relu(conv6, name="relu6")
- if FLAGS.debug:
- utils.add_activation_summary(relu6)
- relu_dropout6 = tf.nn.dropout(relu6, keep_prob=keep_prob)
- W7 = utils.weight_variable([1, 1, 4096, 4096], name="W7")
- b7 = utils.bias_variable([4096], name="b7")
- conv7 = utils.conv2d_basic(relu_dropout6, W7, b7)
- relu7 = tf.nn.relu(conv7, name="relu7")
- if FLAGS.debug:
- utils.add_activation_summary(relu7)
- relu_dropout7 = tf.nn.dropout(relu7, keep_prob=keep_prob)
- W8 = utils.weight_variable([1, 1, 4096, NUM_OF_CLASSESS], name="W8")
- b8 = utils.bias_variable([NUM_OF_CLASSESS], name="b8")
- conv8 = utils.conv2d_basic(relu_dropout7, W8, b8)
- # annotation_pred1 = tf.argmax(conv8, dimension=3, name="prediction1")
- # now to upscale to actual image size
- deconv_shape1 = image_net["pool4"].get_shape()
- W_t1 = utils.weight_variable([4, 4, deconv_shape1[3].value, NUM_OF_CLASSESS], name="W_t1")
- b_t1 = utils.bias_variable([deconv_shape1[3].value], name="b_t1")
- conv_t1 = utils.conv2d_transpose_strided(conv8, W_t1, b_t1, output_shape=tf.shape(image_net["pool4"]))
- fuse_1 = tf.add(conv_t1, image_net["pool4"], name="fuse_1")
- deconv_shape2 = image_net["pool3"].get_shape()
- W_t2 = utils.weight_variable([4, 4, deconv_shape2[3].value, deconv_shape1[3].value], name="W_t2")
- b_t2 = utils.bias_variable([deconv_shape2[3].value], name="b_t2")
- conv_t2 = utils.conv2d_transpose_strided(fuse_1, W_t2, b_t2, output_shape=tf.shape(image_net["pool3"]))
- fuse_2 = tf.add(conv_t2, image_net["pool3"], name="fuse_2")
- shape = tf.shape(image)
- deconv_shape3 = tf.stack([shape[0], shape[1], shape[2], NUM_OF_CLASSESS])
- W_t3 = utils.weight_variable([16, 16, NUM_OF_CLASSESS, deconv_shape2[3].value], name="W_t3")
- b_t3 = utils.bias_variable([NUM_OF_CLASSESS], name="b_t3")
- conv_t3 = utils.conv2d_transpose_strided(fuse_2, W_t3, b_t3, output_shape=deconv_shape3, stride=8)
- annotation_pred = tf.argmax(conv_t3, dimension=3, name="prediction")
- return tf.expand_dims(annotation_pred, dim=3), conv_t3
- def train(loss_val, var_list):
- optimizer = tf.train.AdamOptimizer(FLAGS.learning_rate)
- grads = optimizer.compute_gradients(loss_val, var_list=var_list)
- if FLAGS.debug:
- # print(len(var_list))
- for grad, var in grads:
- utils.add_gradient_summary(grad, var)
- return optimizer.apply_gradients(grads)
- def main(argv=None):
- keep_probability = tf.placeholder(tf.float32, name="keep_probabilty")
- image = tf.placeholder(tf.float32, shape=[None, IMAGE_HEIGHT, IMAGE_WIDTH, 6], name="input_image")
- annotation = tf.placeholder(tf.int32, shape=[None, IMAGE_HEIGHT, IMAGE_WIDTH, 1], name="annotation")
- pred_annotation, logits = inference(image, keep_probability)
- #tf.image_summary("input_image", image, max_images=2)
- #tf.image_summary("ground_truth", tf.cast(annotation, tf.uint8), max_images=2)
- #tf.image_summary("pred_annotation", tf.cast(pred_annotation, tf.uint8), max_images=2)
- loss = tf.reduce_mean((tf.nn.sparse_softmax_cross_entropy_with_logits(logits,
- tf.squeeze(annotation, squeeze_dims=[3]),
- name="entropy")))
- #tf.scalar_summary("entropy", loss)
- trainable_var = tf.trainable_variables()
- train_op = train(loss, trainable_var)
- #print("Setting up summary op...")
- #summary_op = tf.merge_all_summaries()
- '''''
- print("Setting up image reader...")
- train_records, valid_records = scene_parsing.read_dataset(FLAGS.data_dir)
- print(len(train_records))
- print(len(valid_records))
- print("Setting up dataset reader")
- image_options = {'resize': True, 'resize_size': IMAGE_SIZE}
- if FLAGS.mode == 'train':
- train_dataset_reader = dataset.BatchDatset(train_records, image_options)
- validation_dataset_reader = dataset.BatchDatset(valid_records, image_options)
- '''
- train_dataset_reader = BatchDatset('data/trainlist.mat')
- sess = tf.Session()
- print("Setting up Saver...")
- saver = tf.train.Saver()
- #summary_writer = tf.train.SummaryWriter(FLAGS.logs_dir, sess.graph)
- sess.run(tf.initialize_all_variables())
- ckpt = tf.train.get_checkpoint_state(FLAGS.logs_dir)
- if ckpt and ckpt.model_checkpoint_path:
- saver.restore(sess, ckpt.model_checkpoint_path)
- print("Model restored...")
- #if FLAGS.mode == "train":
- itr = 0
- train_images, train_annotations = train_dataset_reader.next_batch()
- trloss = 0.0
- while len(train_annotations) > 0:
- #train_images, train_annotations = train_dataset_reader.next_batch(FLAGS.batch_size)
- #print('==> batch data: ', train_images[0][100][100], '===', train_annotations[0][100][100])
- feed_dict = {image: train_images, annotation: train_annotations, keep_probability: 0.5}
- _, rloss = sess.run([train_op, loss], feed_dict=feed_dict)
- trloss += rloss
- if itr % 100 == 0:
- #train_loss, rpred = sess.run([loss, pred_annotation], feed_dict=feed_dict)
- print("Step: %d, Train_loss:%f" % (itr, trloss / 100))
- trloss = 0.0
- #summary_writer.add_summary(summary_str, itr)
- #if itr % 10000 == 0 and itr > 0:
- '''''
- valid_images, valid_annotations = validation_dataset_reader.next_batch(FLAGS.batch_size)
- valid_loss = sess.run(loss, feed_dict={image: valid_images, annotation: valid_annotations,
- keep_probability: 1.0})
- print("%s ---> Validation_loss: %g" % (datetime.datetime.now(), valid_loss))'''
- itr += 1
- train_images, train_annotations = train_dataset_reader.next_batch()
- saver.save(sess, FLAGS.logs_dir + "plus_model.ckpt", itr)
- '''''elif FLAGS.mode == "visualize":
- valid_images, valid_annotations = validation_dataset_reader.get_random_batch(FLAGS.batch_size)
- pred = sess.run(pred_annotation, feed_dict={image: valid_images, annotation: valid_annotations,
- keep_probability: 1.0})
- valid_annotations = np.squeeze(valid_annotations, axis=3)
- pred = np.squeeze(pred, axis=3)
- for itr in range(FLAGS.batch_size):
- utils.save_image(valid_images[itr].astype(np.uint8), FLAGS.logs_dir, name="inp_" + str(5+itr))
- utils.save_image(valid_annotations[itr].astype(np.uint8), FLAGS.logs_dir, name="gt_" + str(5+itr))
- utils.save_image(pred[itr].astype(np.uint8), FLAGS.logs_dir, name="pred_" + str(5+itr))
- print("Saved image: %d" % itr)'''
- def pred():
- keep_probability = tf.placeholder(tf.float32, name="keep_probabilty")
- image = tf.placeholder(tf.float32, shape=[None, IMAGE_HEIGHT, IMAGE_WIDTH, 6], name="input_image")
- annotation = tf.placeholder(tf.int32, shape=[None, IMAGE_HEIGHT, IMAGE_WIDTH, 1], name="annotation")
- pred_annotation, logits = inference(image, keep_probability)
- sft = tf.nn.softmax(logits)
- test_dataset_reader = TestDataset('data/testlist.mat')
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- ckpt = tf.train.get_checkpoint_state(FLAGS.logs_dir)
- saver = tf.train.Saver()
- if ckpt and ckpt.model_checkpoint_path:
- saver.restore(sess, ckpt.model_checkpoint_path)
- print("Model restored...")
- itr = 0
- test_images, test_annotations, test_orgs = test_dataset_reader.next_batch()
- #print('getting', test_annotations[0, 200:210, 200:210])
- while len(test_annotations) > 0:
- if itr < 22:
- test_images, test_annotations, test_orgs = test_dataset_reader.next_batch()
- itr += 1
- continue
- elif itr > 22:
- break
- feed_dict = {image: test_images, annotation: test_annotations, keep_probability: 0.5}
- rsft, pred_ann = sess.run([sft, pred_annotation], feed_dict=feed_dict)
- print(rsft.shape)
- _, h, w, _ = rsft.shape
- preds = np.zeros((h, w, 1), dtype=np.float)
- for i in range(h):
- for j in range(w):
- if rsft[0][i][j][0] < 0.1:
- preds[i][j][0] = 1.0
- elif rsft[0][i][j][0] < 0.9:
- preds[i][j][0] = 0.5
- else:
- preds[i][j] = 0.0
- org0_im = Image.fromarray(np.uint8(test_orgs[0]))
- org0_im.save('res/org' + str(itr) + '.jpg')
- save_alpha_img(test_orgs[0], test_annotations[0], 'res/ann' + str(itr))
- save_alpha_img(test_orgs[0], preds, 'res/trimap' + str(itr))
- save_alpha_img(test_orgs[0], pred_ann[0], 'res/pre' + str(itr))
- test_images, test_annotations, test_orgs = test_dataset_reader.next_batch()
- itr += 1
- def save_alpha_img(org, mat, name):
- w, h = mat.shape[0], mat.shape[1]
- #print(mat[200:210, 200:210])
- rmat = np.reshape(mat, (w, h))
- amat = np.zeros((w, h, 4), dtype=np.int)
- amat[:, :, 3] = np.round(rmat * 1000)
- amat[:, :, 0:3] = org
- #print(amat[200:205, 200:205])
- #im = Image.fromarray(np.uint8(amat))
- #im.save(name + '.png')
- misc.imsave(name + '.png', amat)
- if __name__ == "__main__":
- #tf.app.run()
- pred()
到这里FCN+做人像分割已经讲完,当然本文的目的不单单是分割,还有分割之后的应用;
我们将训练数据扩充到人体分割,那么我们就是对人体做美颜特效处理,同时对背景做其他的特效处理,这样整张画面就会变得更加有趣,更加提高颜值了,这里我们对人体前景做美颜调色处理,对背景做了以下特效:
①景深模糊效果,用来模拟双摄聚焦效果;
②马赛克效果
③缩放模糊效果
④运动模糊效果
⑤油画效果
⑥线条漫画效果
⑦Glow梦幻效果
⑧铅笔画场景效果
⑨扩散效果
效果举例如下:

原图

人体分割MASK

景深模糊效果

马赛克效果

扩散效果

缩放模糊效果

运动模糊效果

油画效果

线条漫画效果

GLOW梦幻效果

铅笔画效果
最后给出DEMO链接:点击打开链接
本人QQ1358009172