import torch
from torch import nn,optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
class simpleNet(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(simpleNet,self).__init__()
self.layer1 = nn.Linear(in_dim,n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1,n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2,out_dim)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
#设置激活函数
class Activation_Net(nn.Module):
def __init__(self, in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Activation_Net,self).__init()
self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class Batch_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Batch_Net,self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.BatchNorm1d(n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.BatchNorm1d(n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
# Hyperparameters
batch_size = 24
learning_rate = 1e-2
epochs = 20
# preprocessing the dataset
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])])
train_dataset = datasets.MNIST(
root='./data',train=True, transform=data_tf,download=True)
test_dataset = datasets.MNIST(root='./data',train=False, transform=data_tf)
train_loader = DataLoader(train_dataset,batch_size=batch_size, shuffle = True)
test_loader = DataLoader(test_dataset,batch_size = batch_size,shuffle = False)
# We show image from the iterable object train_loader
# remender, data inside images are of tensor type
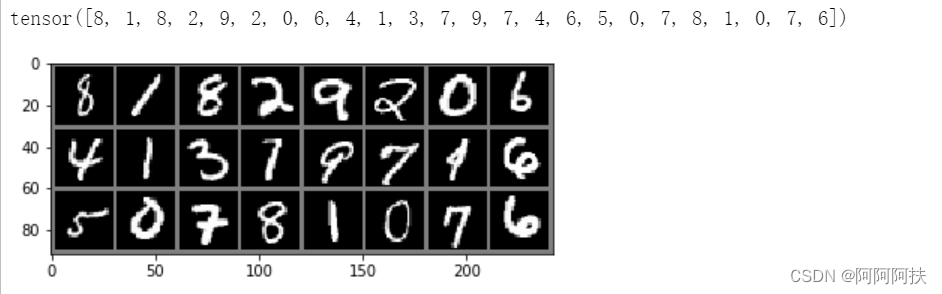
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print(labels)
plt.imshow(img)
plt.show()
net = Batch_Net(28*28, 300,100,10)
criterion =nn.L1Loss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
from torch import autograd
import matplotlib.pyplot as plt
import math
def one_hot(label, depth=10):
out = torch.zeros(label.size(0), depth)
idx = torch.LongTensor(label).view(-1, 1)
out.scatter_(dim=1, index=idx, value=1)
return out
epochs=20
x1=[]
y1=[]
for e in range(epochs):
x1=x1+[e]
net.train()
for data in train_loader:
x,y = data
y_onehot = one_hot(y)
optimizer.zero_grad()
output = net(x.view(-1, 28*28))
loss = criterion (output, y_onehot)
loss.backward()
optimizer.step()
print( 'Loss=%.4f' % loss.data)
y1=y1+[loss.data]
log_y1=[ math.log(abs(y1[i]),10)for i in range(0,len(y1))]
print(log_y1)
plt.plot(x1,log_y1)
plt.xlabel('epochs', fontsize = 14)
plt.ylabel('L1Loss_log_loss',fontsize = 14)
plt.yticks([-1.2,-1,-0.8])
#plt.savefig("积分误差函数1.pdf", bbox_inches='tight')
plt.show()

x=np.array(x1)
y1=[math.log(abs(result[i]),10)for i in range(0,len(result))]
y=np.array(y1)
fig = plt.figure()
plt.plot(x,y)
plt.title('RMSprop_loss_eposhs')
plt.ylabel('RMSprop_loss')
plt.xlabel('eposhs')
plt.show()

optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
x1=[]
result=[]
for e in range(epochs):
x1.append(e)
net.train()
for data in train_loader:
x, y = data
optimizer.zero_grad()
output = net(x.view(-1, 28*28))
loss = criterion(output, y)
loss.backward()
optimizer.step()
print( 'Loss=%.4f' % loss.data)
result.append(loss.data)
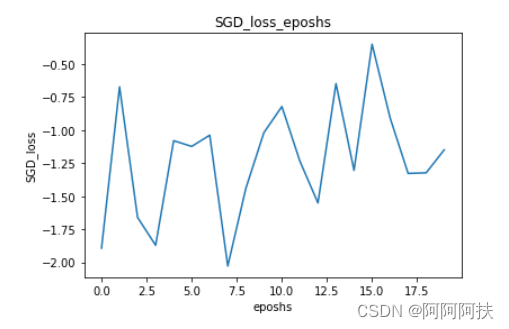
x=np.array(x1)
y1=[math.log(abs(result[i]),10)for i in range(0,len(result))]
y=np.array(y1)
fig = plt.figure()
plt.plot(x,y)
plt.title('SGD_loss_eposhs')
plt.ylabel('SGD_loss')
plt.xlabel('eposhs')
plt.show()