作者‖ 黎国溥,3D视觉开发者社区签约作者,CSDN博客专家,华为云-云享专家
编辑‖ 3D视觉开发者社区
文章目录
前言
MV3D-Net 融合了视觉图像和激光雷达点云信息;输入数据有三种,分别是点云俯视图、点云前视图和RGB图像。通过特征提取、特征整合和特征融合,最终得到类别标签、3D边界框。这样的设计既能减少计算量,又保留了主要的特征信息。
MV3D-Net 开源代码:https://github.com/bostondiditeam/MV3D
MV3D-Net 论文地址:Multi-View 3D Object Detection Network for Autonomous Driving
AVOD-Net算是MV3D-Net的加强版,它也融合了视觉图像和激光雷达点云信息。但它去掉了激光点云的前视图输入、去掉了俯视图中的强度信息;输入数据有二种,分别是点云俯视图和RGB图像。AVOD-Net使用FPN来提取特征,同时添加边界框的几何约束,整体模型效果有提升。
AVOD-Net 开源代码:https://github.com/kujason/avod
AVOD-Net 论文地址:Joint 3D Proposal Generation and Object Detection from View Aggregation
本文思路是先介绍MV3D-Net,再介绍AVOD-Net;在理解MV3D-Net的基础上,去看AVOD-Net做出了哪些改变和对应效果如何。
一、MV3D-Net篇
1.1、框架了解
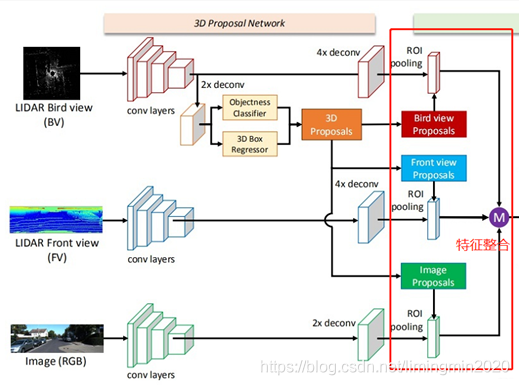
先看下总体网络结构:下图中的紫色圆圈中M是表示:基于元素的均值。
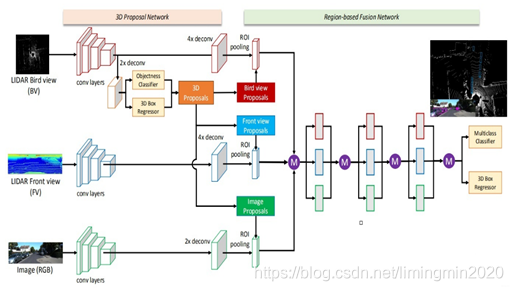
输入的数据:有三种,分别是点云俯视图、点云前视图和二维RGB图像。“点云投影”,其实并非简单地把三维压成二维,而是提取了高程、密度、光强等特征,分别作为像素值,得到的二维投影图片。
输出数据:类别标签、3D边界框。
1.1.1 网络的主体部分
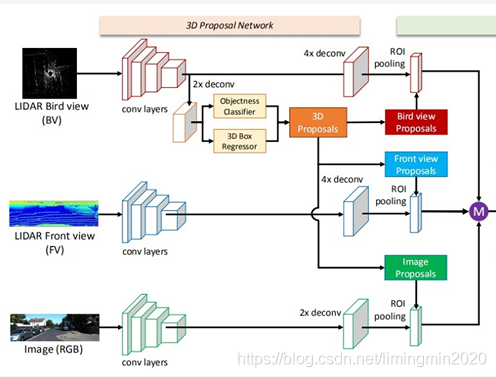
网络的主体结构的思路流程:
1)提取特征。
提取点云俯视图特征;
提取点云前视图特征;
提取图像特征。
2)从点云俯视图特征中计算ROI候选区域。
3)把候选区域分别与提取到的点云俯视图特征、点云前视图特征和图像特征进行整合。
先把俯视图候选区域投影到前视图和图像中;
再经过ROI pooling整合成同一维度。
1.1.2 网络的融合部分
融合部分部是把整合后的数据进行融合,最终得到类别标签、3D边界框。
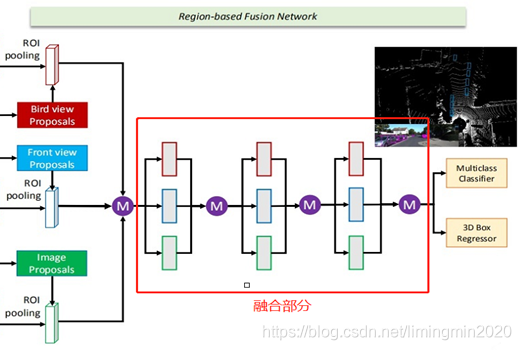
上图中的紫色圆圈中M是表示:基于元素的均值。
1.2、MV3D的点云处理
MV3D将点云和图片数据映射到三个维度进行融合,从而获得更准确的定位和检测的结果。这三个维度分别为点云的俯视图、点云的前视图以及图片。

1.2.1 提取点云俯视图
点云俯视图由高度、强度、密度组成;作者将点云数据投影到分辨率为0.1的二维网格中。
高度图的获取方式为:将每个网格中所有点高度的最大值记做高度特征。为了编码更多的高度特征,将点云被分为M块,每一个块都计算相应的高度图,从而获得了M个高度图。
强度图的获取方式为:每个单元格中有最大高度的点的映射值。
密度图的获取方式为:统计每个单元中点云的个数,并且按照公式:
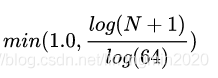
其中N为单元格中的点的数目。强度和密度特征计算的是整个点云,而高度特征是计算M切片,所以,总的俯视图被编码为(M + 2)个通道的特征。
1.2.2 提取点云前视图
由于激光点云非常稀疏的时候,投影到2D图上也会非常稀疏。相反,作者将它投影到一个圆柱面生成一个稠密的前视图。 假设3D坐标为:
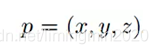
那么前视图坐标:
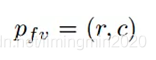
可以通过如下式子计算
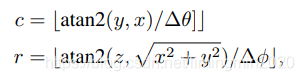
1.3、MV3D的图像处理
采用经典的VGG-16来提取图像特征,下图是VGG-16的网络结构。
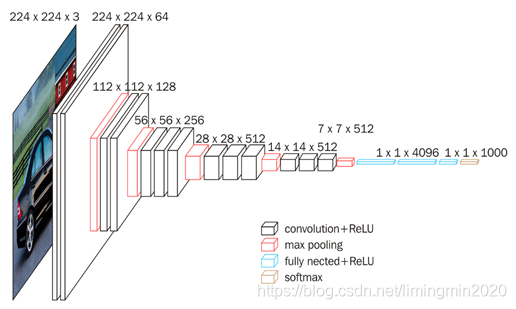
VGG-16结构中有13个卷积层和3个全链接层,它的结构简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。它验证了通过不断加深网络结构可以提升性能。但VGG-16耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。
1.4、俯视图计算候选区域
物体投射到俯视图时,保持了物体的物理尺寸,从而具有较小的尺寸方差,这在前视图/图像平面的情况下不具备的。在俯视图中,物体占据不同的空间,从而避免遮挡问题。
在道路场景中,由于目标通常位于地面平面上,并在垂直位置的方差较小,可以为获得准确的3Dbounding box提供良好基础。候选区域网络是RPN,下面介绍一下它的原理。
RPN全称是Region Proposal Network,也可理解为区域生成网络,或区域候选网络;它是用来提取候选框的。
1.4.1 RPN的由来
在RCNN和Fast RCNN等物体检测架构中,提取候选框的方法通常是传统的Selective Search,比较耗时。
在Faster RCNN中,RPN专门用来提取候选框,这也是RPN第一次被使用;RPN耗时少。Faster RCNN = RPN + Fast RCNN。
1.4.2 RPN思路流程
RPN网络的任务是找到proposals。输入:feature map。输出:proposal。
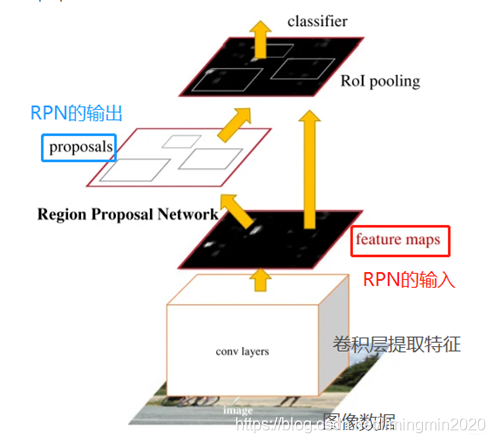
RPN总体流程:
- 生成anchors(anchor boxes)。
- 判断每个 anchor box 为 foreground(包含物体) 或者background(背景) ,二分类;softmax分类器提取positvie anchors 。
- 边界框回归(bounding box regression) 对 anchor box 进行微调,使得 positive anchor 和真实框(Ground Truth Box)更加接近。
- Proposal Layer生成proposals。
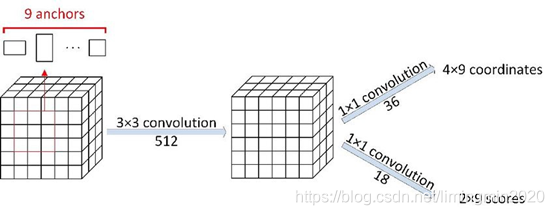
1.4.3 feature maps与锚框 anchor boxes
feature maps 的每一个点都配9个锚框,作为初始的检测框。重要的事说三遍:**锚框作为初始的检测框!、锚框作为初始的检测框!、锚框作为初始的检测框!**虽然这样得到的检测框很不准确,但后面可通过 bounding box regression 来修正检测框的位置。
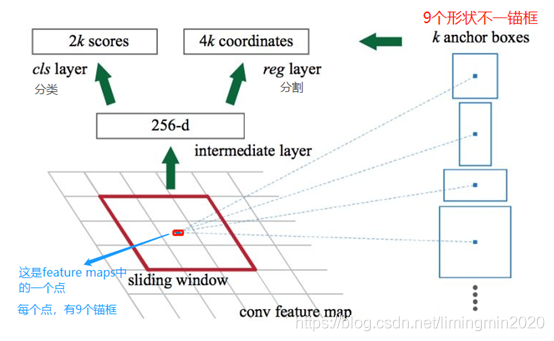
下面介绍那9个anchor boxes 锚框,先看看它的形状:
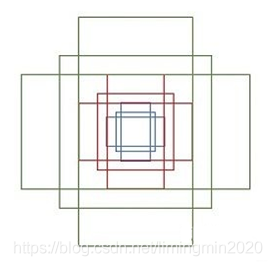
这里一共有9个框框,绿色3个,红色3个,蓝色3个。有3种形状,长宽比分别是1:1, 1:2, 2:1
1.4.4 判断anchor boxes是否包含物体
在feature map上,设置了密密麻麻的候选anchor boxes 锚框。为什么会有这么多?因为 feature maps 的每一个点都配9个锚框,如果一共有1900个点,那一共有1900*9=17100个锚框了。
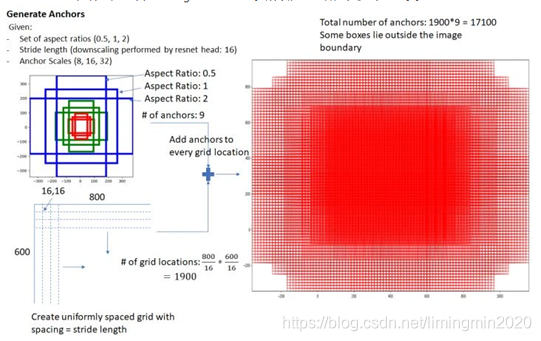
设 feature maps 的尺寸为 WH,那么总共有 WH*9个锚框。(W:feature maps的宽;H:feature maps 的高。)
然后用cnn去判断哪些anchor box是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,RPN做的只是个二分类。
关于cnn的模型结构,可以参考下图:
1.4.5 修正边界框
已知anchor box 包含物体称为positive anchors,那怎么调整,才能使得 anchor box 与 ground truth 更接近?

图中红框为positive anchors,绿框为真实框(Ground Truth Box,简称GT)
positive anchors 和GT的梯度可以有dx, dy, dw, dh四个变换表示,bounding box regression通过线性回归学习到这个四个梯度,使positive anchors 不断逼近GT,从而获得更精确的proposal。
bounding box regression 思路,简单一点的,可以先做平移,再做缩放,最终包含物体anchor box和真实框很接近。
1.4.6 Proposal(最有可能包含物体的区域)
通过上面的判断anchor boxes是否包含物体,对有物体的anchor boxes通过回归进行修正它的尺子,最终包含物体anchor box和真实框很接近。RPN会输出一些框框,和这些框框包含物体的概率。
总结一下,Proposal 的输入有三个:
softmax 分类矩阵
Bounding Box Regression 坐标矩阵
im_info 保存了缩放的信息
输出为:
rpn_rois: RPN 产生的 ROIs(Region of Interests,感兴趣的区域)
rpn_roi_probs: 表示ROI包含物体的概率。
RPN 只挑选出了可能包含物体的区域(rpn_rois)以及其包含物体的概率(rpn_roi_probs)。在后续处理中,设定一个阈值 threshold,如果某个ROI包含物体的概率的概率大于阈值,再判断其类别;否则直接忽略。
1.5、特征整合
把候选区域分别与提取的特征进行整合。
特征整合流程:
• a. 把俯视图候选区域投影到前视图和图像中
• b. 经过ROI pooling整合成同一维度
1.6、特征融合
有了整合后的数据,需要对特征进行融合,最终得到类别标签、3D边界框。
作者介绍了三种不同的融合方式,分别为
• a、Early Fusion 早期融合
• b、Late Fusion 后期融合
• c、Deep Fusion 深度融合。
各自的结构如下图所示。
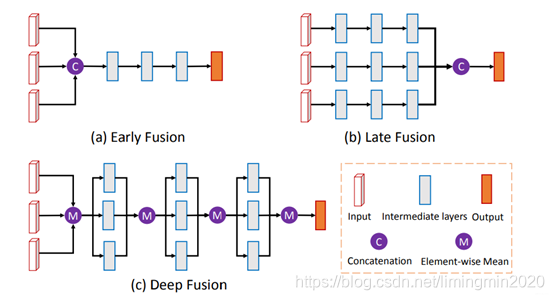
上图中的紫色圆圈中M是表示:基于元素的均值。C是表示:串接。
最终选择了Deep Fusion 深度融合。融合的特征用作:分类任务(人/车/…)、更精细化的3D Box回归(包含对物体朝向的估计)。
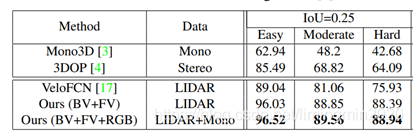
1.7、模型效果
和其他模型对比的数据:

检测效果:

1.8、模型代码
代码地址:https://github.com/bostondiditeam/MV3D
作者使用KITTI提供的原始数据,点击链接

上图是用于原型制作的数据集 。
我们使用了[同步+校正数据] + [校准](校准矩阵)+ [轨迹]()
所以输入数据结构是这样的:

运行 src/data.py 后,我们获得MV3D网络所需的输入。它保存在kitti中。

上图是激光雷达俯视图(data.py后)

上图是将 3D 边界框投影回相机图像中。
二、AVOD-Net篇
2.1、框架了解
先看下总体网络结构:(可以点击图片放大查看)
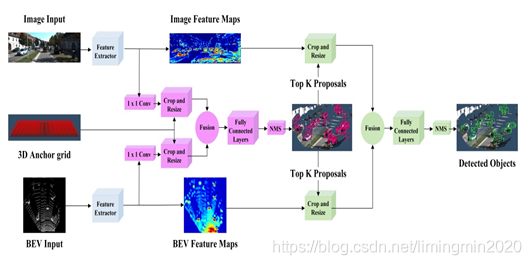
输入的数据:有二种,分别是点云俯视图和二维RGB图像。输出数据:类别标签、3D边界框。
**相对于MV3D-Net的改进措施:**去掉了激光点云的前视图输入。在俯视图中去掉了强度信息。去掉这两个信息仍然能取得号的效果,就说明俯视图和图像信息已经能够完整诠释三维环境了。
2.2、提取特征
AVOD-Net如何提取特征的?它主要提取出二部分数据,分别是图像特征、点云俯视图特征。其中图像+点云俯视图融合特征,在数据整合起到作用。后面将这二种特征进行融合。
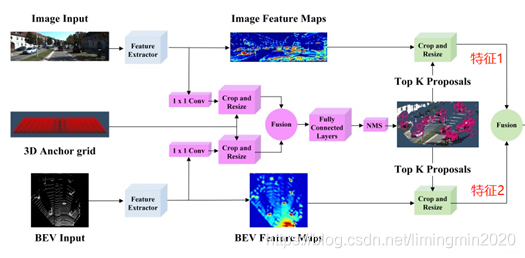
它使用了全分辨率特征,所以为了在整合时降低维度,先进性了1X1的卷积。
AVOD使用的是FPN,MV3D-Net 是使用的VGG16做特征提取。下面介绍一下FPN网络的原理。
FPN,全名是Feature Pyramid Networks,中文称为特征金字塔网络;它是目前用于目标检测、语义分割、行为识别等方面比较重要的一个部分,对于提高模型性能具有较好的表现。
在特征提取中,低层的特征语义信息比较少,但目标位置准确,分辨率高。高层的特征语义信息比较丰富,但是目标位置比较粗略,分辨率低和比较抽象。于是有些算法采用多尺度特征融合的方式,在融合后的特征做预测。
FPN的预测是在不同特征层独立进行的,即:同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。FPN作者认为足够低层高分辨的特征对于检测小物体是很有帮助的。
2.2.1 FPN特征金字塔
FPN的顶层特征通过上采样和低层特征做融合,并且每层都是独立预测的;它使每一层不同尺度的特征图都具有较强的语义信息。
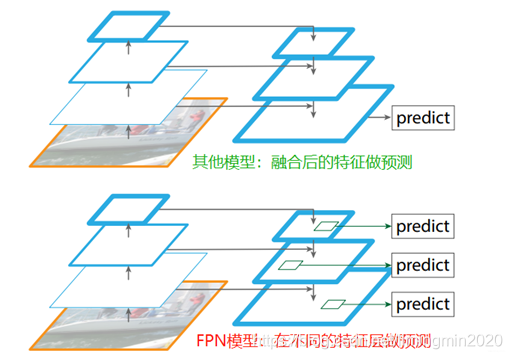
对比:FPN特征金字塔与多尺度特征融合
多尺度特征融合的方式,在融合后的特征做预测。经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预。
FPN是在不同特征层独立进行预测。
2.2.2 FPN网络结构
FPN的主网络采用ResNet,网络结构思路是一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。

11的卷积核减少卷积核的个数,也就是减少feature map的个数,并不改变feature map的尺寸大小。
自底向上的过程也称为下采样,feature map尺寸在逐渐减小,同时提取到的特征语义信息逐渐丰富。在下采样过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程也称为上采样进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合。其中,11的卷积核减少卷积核的个数,也就是减少feature map的个数,并不改变其尺寸大小。
在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
FPN同时使用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。
2.3、数据整合
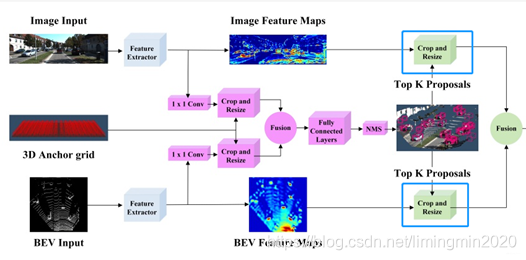
AVOD使用的是裁剪和调整(crop and resize),数据整合结构如下图所示。
2.4、边界框的几何约束
AVOD在3D Bounding Box的编码上添加了几何约束。MV3D, Axis Aligned, AVOD三种不同的3D Bounding Box编码方式如下图所示,
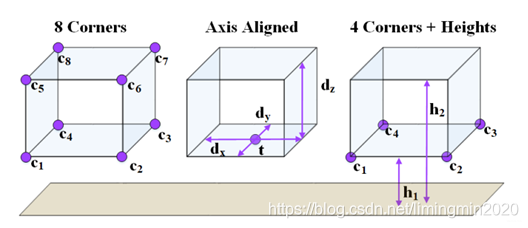
AVOD利用一个底面以及高度约束了3D Bounding Box的几何形状,即要求其为一个长方体。MV3D只是给出了8个顶点,没有任何的几何约束关系。
此外,MV3D中8个顶点需要一个24维(3x8)的向量表示,而AVOD只需要一个10维(2x4+1+1)的向量即可,做到了很好的编码降维工作。
2.5、模型效果
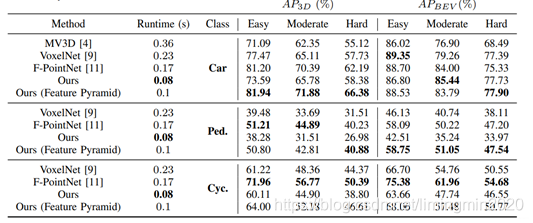
与其他模型的对比:
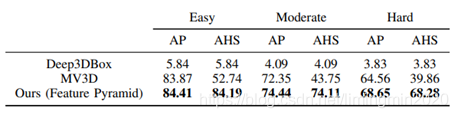
在KITTI上,AVOD目前(2018.7.23)名列前茅,在精度和速度上都表现较好,与MV3D, VoxelNet, F-PointNet对比的结果如下表所示。
模型预测效果:

2.6、模型代码
AVOD-Net 开源代码:https://github.com/kujason/avod
作者代码的运行环境:
**系统:**Ubuntu 16.04
****深度框架:****TensorFlow1.3(GPU 版本)
**其他依赖库:**numpy>=1.13.0 、opencv-python 、pandas、pillow、protobuf==3.2.0 、scipy、sklearn 等。
**数据集:**在Kitti 对象检测数据集上进行训练。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
或可微信关注官方公众号 3D视觉开发者社区 ,获取更多干货知识哦。