RADIANT:一种全新的雷达图像关联网络用于3D目标检测
论文地址:RADIANT: Radar-Image Association Network for 3D Object Detection
源码:https://github.com/longyunf/radiant
单位:密歇根大学、福特
动机
作为一种能够直接测量深度的传感器,其相较于Lidar存在较大的误差,因此利用雷达本身精度难以精确地将雷达结果与单目方法的3D估计相关联。本文提出了一种融合网络RADIANT来解决雷达-摄像机关联的挑战。通过预测雷达点到真实目标中心点的3D偏移,随后利用修正后的雷达点修正图像预测结果,使得网络在特征层和检测层完成融合。
贡献
- 通过增强毫米波点云获得3D目标的中心位置
- 使用增强后的毫米波点云完成相机-雷达的检测结果关联
- 在多个单目SOTA模型中验证了结构有效性并取得SOTA
背景&问题定义
正雷达样本点
对于目标检测的训练,关键就是:候选点的选择、定义正负样本,FCOS3D将每个像素点作为目标候选点,而正样本点定义为GT目标中心周围的区域内。同样,对于本文,我们将每个雷达反射点作为目标的候选点,将成功与目标相关联的雷达像素点作为正样本点。但是,由于毫米波反射点的模糊性(存在多径干扰)和不准确性(检测的分辨率不高)等问题,导致反射点许多无法反映真实的目标位置框内,同时目前的主流多模态数据集(radar+camera)没有提供point-wise(点云级别)的标记,以上两种原因导致了:现有的毫米波反射点无论是精度上还是标注上,都需要做一些工作。
由此,作者如此解决:
- 3D框内部的点云当然归属于对应目标,但是对于外部点云,作者设置距离阈值将一定范围内的点云考虑在内
- 同时为了防止误召回,上一步召回的点云还需要再径向速度上与分配的GT目标相差在一定范围内
Radar Depth Offset
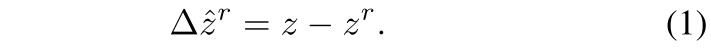
z为反射点相关联的目标深度,z_r为反射点的原始测量深度
细化动机:
- 单目3D检测性能一直受到深度估计不精确问题的裹挟
- 毫米波雷达能提供相较相机更精确的深度,但是其稀疏性、穿透性导致其很难反映出目标真实中心,甚至出现幽灵点,反射点到物体中心的偏移是未知的,但是又是关键的,我们通常需要通过物体的中心特征回归目标的各类属性
- 预测的偏移不仅要包括深度偏移,还有image-plane的投影像素偏移,补偿雷达反射点在横向等方向上误差
- 因为点云和目标匹配需要类别信息,毫米波用于分类的信息较少(无法通过形状判断)
网络架构
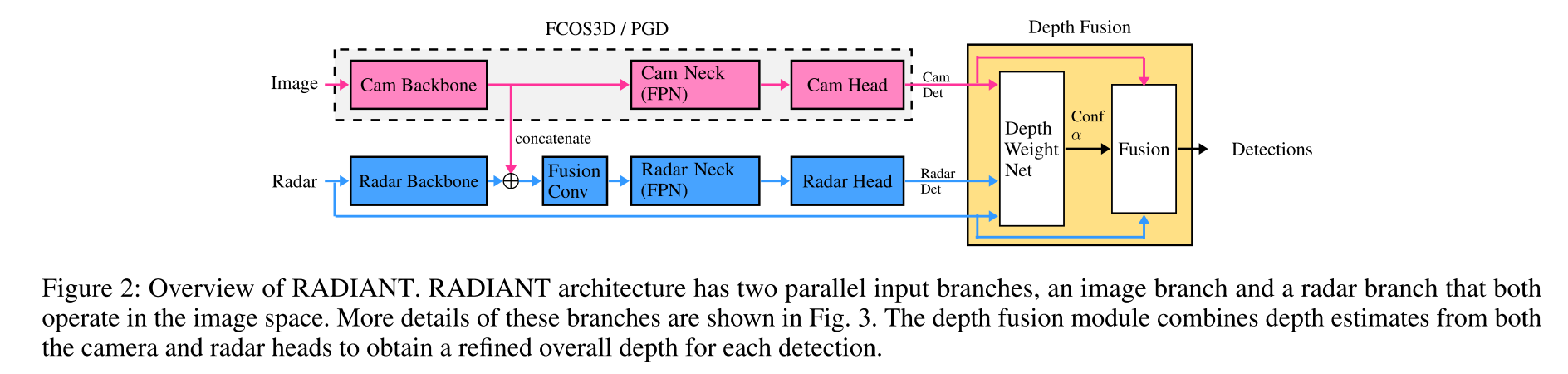
整体上,作者使用“双流”网络结构,图像、雷达分支分别使用原始FCOS3D网络、引入图像特征的轻量级FCOS3D网络,在Depth Fusion结构中,通过DWN(depth weight net)对两个head预测结果引入可学习的深度加权网络,并在最后预测加权后的目标深度。
我们按照(Backbone, Neck, Heads):分别生成图像预测结果和点云预测结果, (Depth Fusion Modules):修正图像预测结果,两个部分介绍细节:

Backbone, Neck, Heads
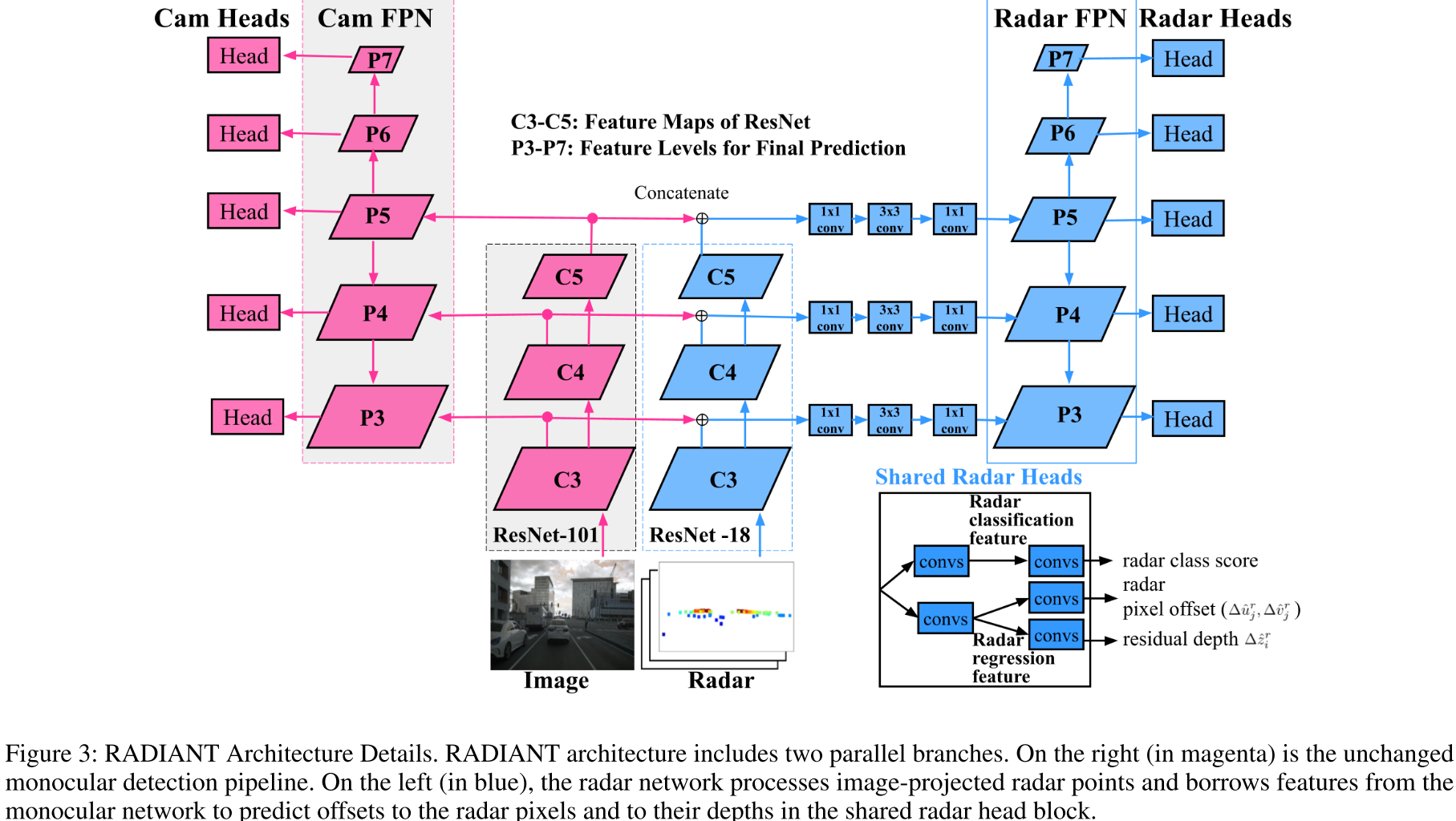
更进一步,对图像分支采用原始FCOS3D网络,不过多介绍。对Radar分支,输入的是投影到image-plane的数据,其中包括深度、坐标、速度、占位掩码(象征点云是否存在于像素中方便后面后处理),在neck部分加入了一些bottleneck瓶颈结构融合图像和雷达数据,解决点云分类能力不足的问题。最后就是在Head上,与图像的各类目标属性回归不同,点云只在其分布的投影像素中,计算类别得分、像素偏移、深度残差(偏移)三个属性。最后的结果形式如下。
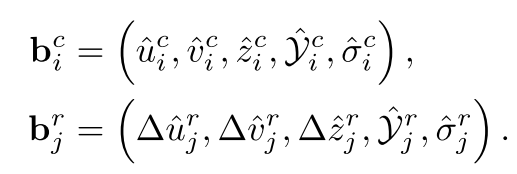
Depth Fusion Module
在得到heads的结果后,这部分的任务就是将两个模态的结果融合,用radar预测的结果修正图像预测结果:
- 关联投影后的雷达反射点radar pixels(预测修正后)与图像检测结果
- 对关联后的每个radar pixels预测深度可靠性概率
- 利用加权后的radar pixels,修正目标的深度,对于目标的尺度、角度等属性不做修改,作者认为是毫米波缺少目标朝向、尺度信息
- Radar-Camera Association

由上图,我们已得到两个Heads的输出,我们取图像预测结果的前1000个boxes按照得分,同样,我们也取radar预测结果中满足置信度>T_r的radar pixels用于融合,我们把雷达预测结果先修正:

修正后,进行关联:匹配要满足以下条件:首先,类别相同,其次投影像素差在一定范围内,最后,深度误差在一定范围内,由此,完成筛选和匹配,假设两个Heads结果分别是M\N个,则复杂度为O(MN)

- Depth Weighting Network
上部分完成了radar pixels的筛选和匹配,本部分进行融合
这部分采用可学习的方式,与之对比的是将匹配的radar pixels深度与图像检测的深度进行平均相加这种不可学习的固定方式

这个网络的目的,就是判断radar pixels是否可信,输出可信度,用于最后的融合。
那么如何规定训练标签呢?
DWN预测的是每个点的置信度,DWN前向完成后,结合图像预测和GT,给予每个点云权重标签,用于训练DWN,DWN仅根据点云head输出特征、原始深度等信息预测,如果GT与radar更接近,α标记为1,反之和图像预测的结果更接近则为0.
- Fused Depth Calculation
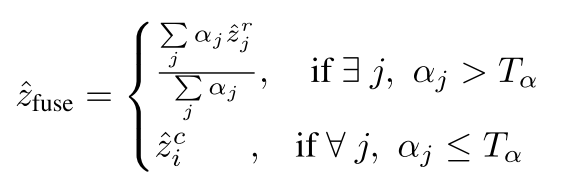
上一步预测的radar pixels权重,这一步根据权重融合加权得到结果,Tα就是阈值,如果任意点云的深度权重阈值<阈值,则只考虑相机的预测结果
实验
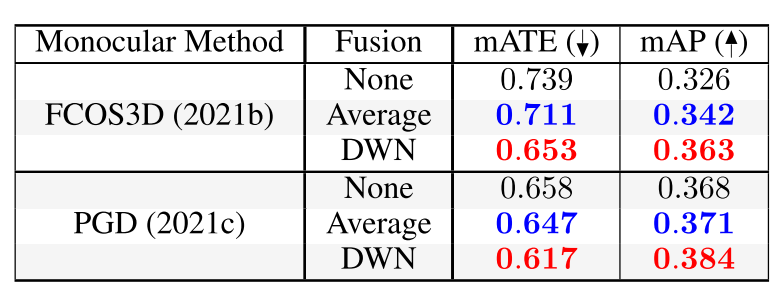
作者对融合方式做了消融实验,其中None是不加入雷达反射点,Average代表平均反射点与图像预测深度,DWN是作者提出的深度权重网络。

由上图,最上面的Table1,表述了从由近到远过程中,图像、原始雷达、修正后雷达(中间)的预测误差,可以看到经过offset的修正后,雷达的深度预测值在近处的修正作用占比更大。这里不要被作者的数据吓到,因为这是丈量雷达反射点到目标中心偏移误差,因为雷达反射点本身就分布在非车身中心。
上图中的Figure 4,分别代表:融合后目标深度预测值和雷达反射点之间的偏差,GT目标深度和雷达反射点之间的偏差,两者的偏差分布整体是相似的,预测结果的偏差分布更加均匀。
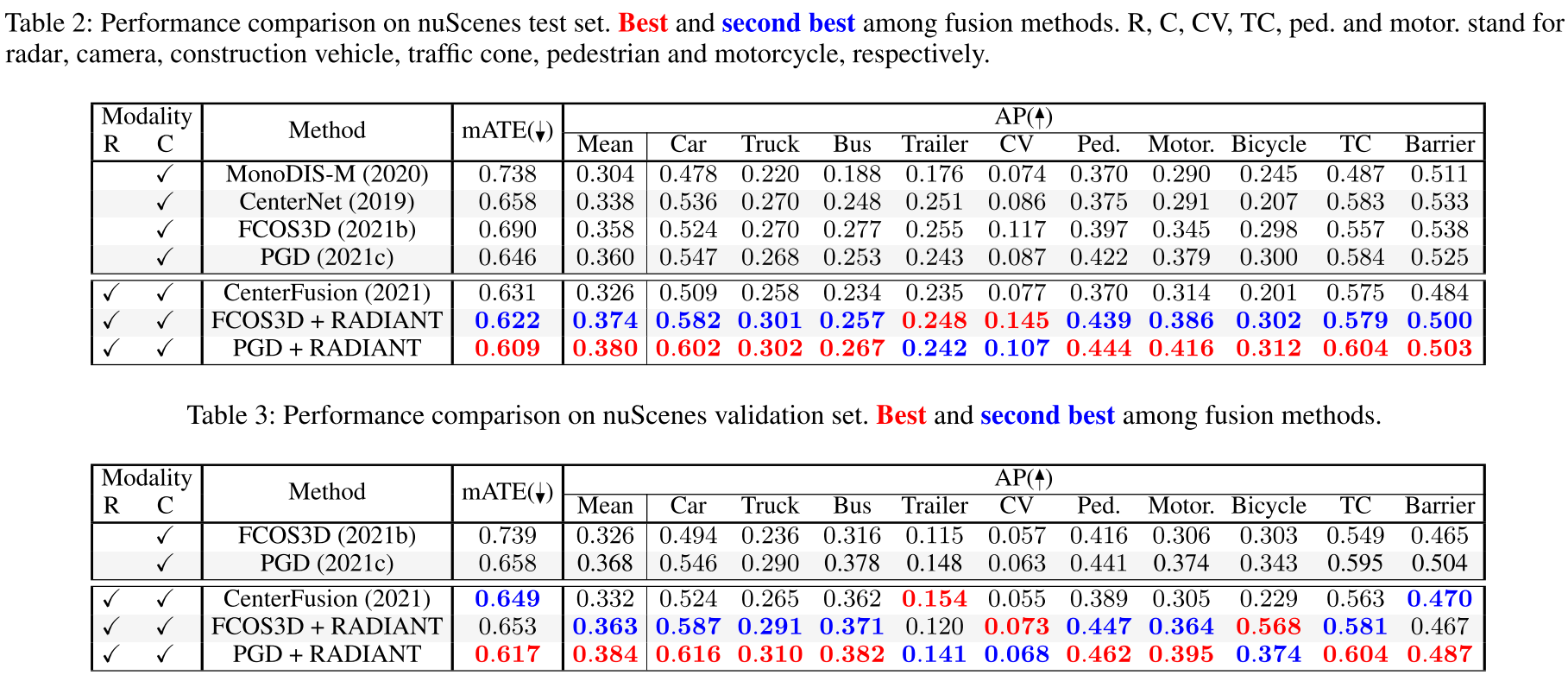
Table2是NuScenes数据集上的实验结果对比,作者基于FOCOS3D, PGD两类单目检测模型改进,都得到了较大的提升,提升体现在mATE,AP两个数据指标上。同时,相比经典的centerfusion,也有较大的提升。
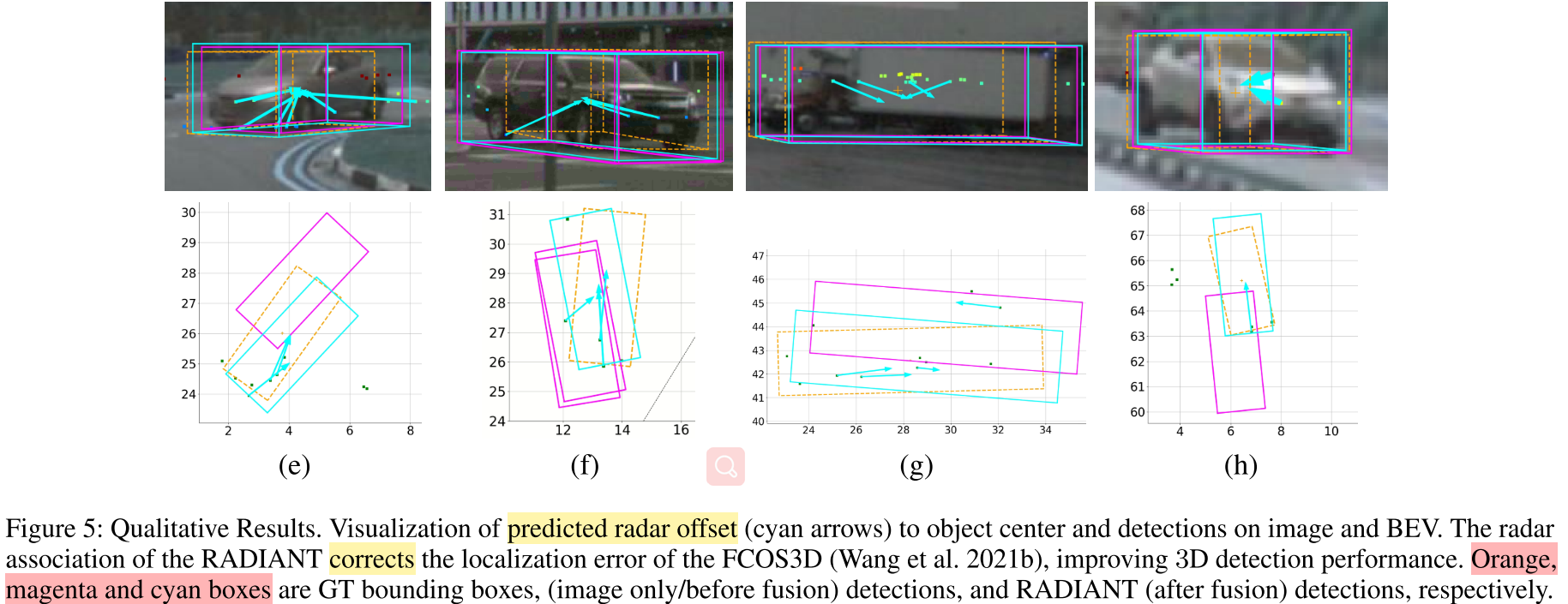
Figure 5中,分散的反射点通过预测offset,集中于目标的中心,目标的深度也得到了进一步的修正。
简单总结:
- 作者提出的这种关联、更新方式,有效改善了单目单帧的目标深度预测能力,提出了细粒度更高的标记NuScenes毫米波点云的一种方式
- 根据具体场景,根据传感器特性,在feature-level和decision-level上多方式非对称融合往往更加有效
- 作者基于image-plane,选择的投影方式导致了点云偏移预测受限于特征提取方式,事实上雷达点云投影存在遮挡,同时点云稀疏,将其投影到image-plane上导致原本形状进一步丢失,进一步加剧了数据的稀疏性
- 作者只通过radar改善了目标的位置性能和平均精度,事实上目标的RCS等信息对于其他属性仍然有一定修正作用