文章目录
3D目标检测概述
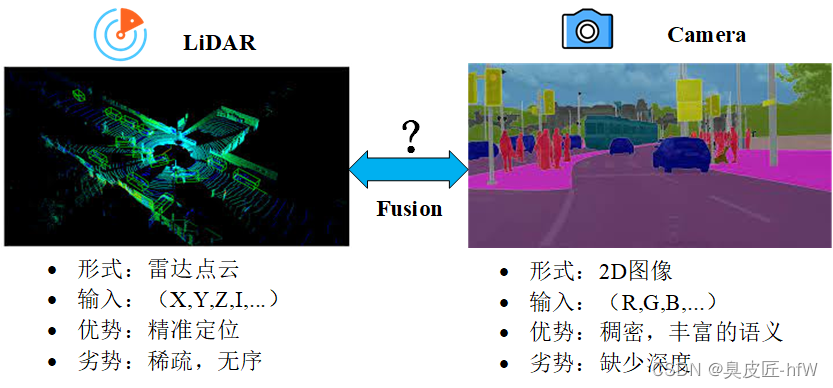
点云和图像都是自动驾驶中常用的传感器数据类型,它们各自有不同的优缺点。点云目标检测在自动驾驶领域中有着不可替代的优势,尤其是在需要精准定位和避障的场景下,点云目标检测可以为自动驾驶车辆提供更为准确和可靠的感知能力,点云的主要优势为:
- 三维信息丰富:点云可以提供物体的位置、形状、尺寸和距离等三维信息,这对于一些需要进行精准定位、避障和规划的自动驾驶应用来说非常重要。
- 可靠性高:相对于图像数据,点云数据通常由激光雷达等传感器生成,具有稳定性高、抗干扰能力强的特点,可以应对一些复杂的环境和场景。
- 适用性广:点云目标检测可以适用于各种自动驾驶应用场景,如障碍物检测、行人检测、车辆检测等。
- 原始数据处理量小:相对于基于图像的目标检测方法,点云目标检测在数据预处理和降噪等方面的处理量相对较小,处理效率较高。
纯点云数据根据输入表征分类
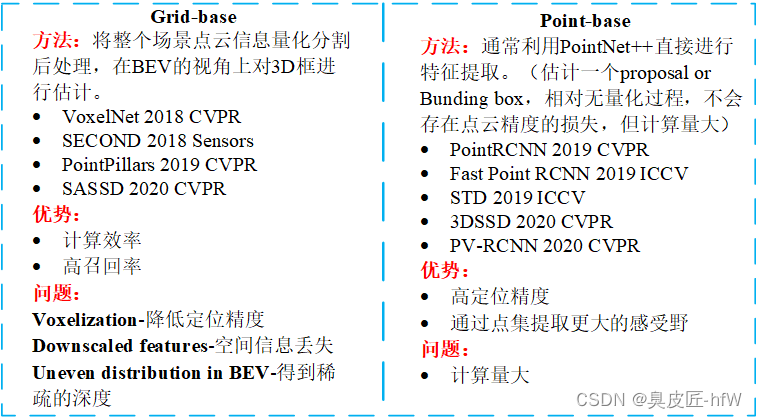
根据输入表征,大致可分为两类,分别Grid-base和Point-base,参考下图:
3D目标检测流程
- 数据预处理:将点云数据转换为网络可以处理的格式,例如将点云转换为三维体素(voxel)表示或使用基于点的表示方式(例如PointNet)。
- 点云特征提取:利用卷积神经网络(CNN)从点云中提取特征,以便检测目标。特征提取的方法包括传统的二维卷积神经网络(CNN)、基于点的方法(例如PointNet)和基于体素的方法(例如VoxelNet)。
- 点云分割:利用分割算法将点云中的每个点分配到特定的物体类别中。分割方法可以是基于传统的机器学习方法,如支持向量机(SVM)和随机森林,也可以是基于深度学习的方法,如PointRCNN和Pillar-based方法。
- 目标检测:在分割后的点云中检测目标。目标检测可以是传统的二维目标检测算法,也可以是基于3D的算法,例如Frustum PointNet和MV3D。
- 后处理:通过滤波和非最大值抑制(NMS)等后处理方法,来消除重复的检测结果,并提高目标检测的准确性。
值得注意的是:每个步骤都可以采用不同的算法和技术,具体的实现方式因任务不同而异。
OpenPCDet3D目标检测框架
注:本文介绍基于OpenPCDet
模块化模型拓扑设计
在PCDet中搭建3D目标检测框架只需要写config文件将所需模块定义清楚,然后PCDet将自动根据模块间的拓扑顺序组合为3D目标检测框架,来进行训练和测试。
模块化设计如下图所示:
 PCDet可以支持目前已有的绝大多数面向LiDAR点云的3D目标检测算法,包括voxel-based,point-based,point-voxel hybrid以及one-stage/two-stage等等3D目标检测算法,详见:点击这里。
PCDet可以支持目前已有的绝大多数面向LiDAR点云的3D目标检测算法,包括voxel-based,point-based,point-voxel hybrid以及one-stage/two-stage等等3D目标检测算法,详见:点击这里。
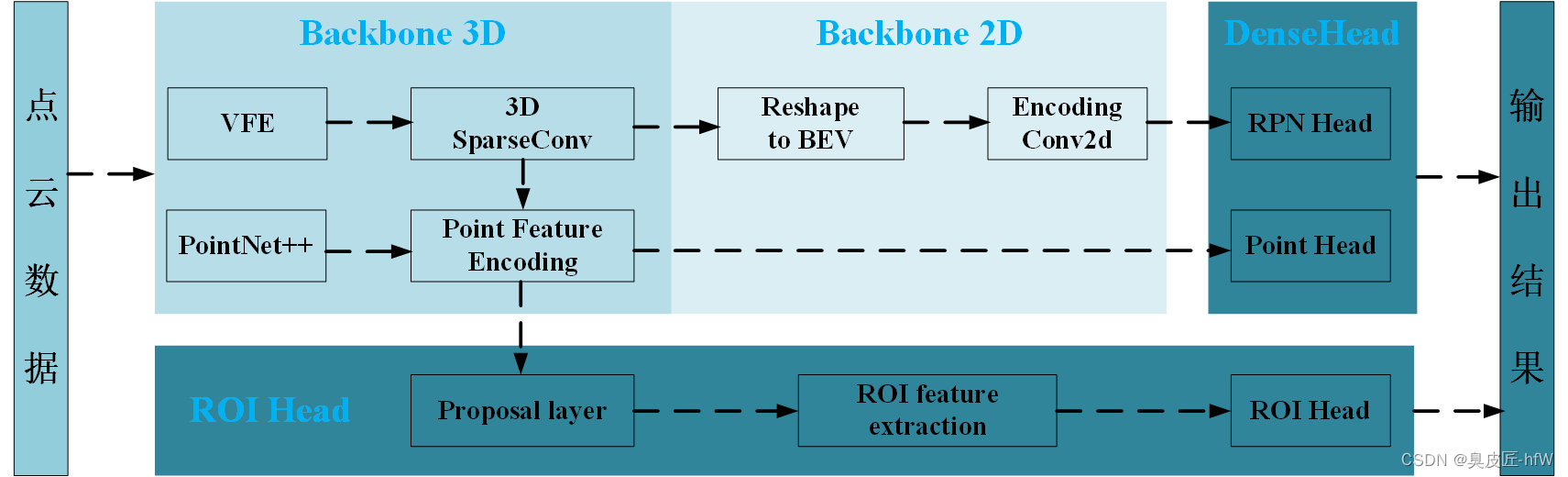
PCDet主要模块作用
- Backbone3D用来处理原始的点云和voxel信息。
- Backbone2D进一步将3D信息压缩到2D平面去提取特征。
- DenseHead是一阶段的检测头。
- RoIHead是二阶段的检测头。
Backbone3D
backbone3D分两个支路:point branch和voxel branch(实际操作中,可能保留一个或两个都要)。
- 上路是Voxel分支:Voxel Feature Encoder(VFE)将点云特征先聚合到voxel中,再利用稀疏卷积(SparseConv)提取3D特征。最简单VFE(mean VFE)的方式就是将空间划分成等体积的voxel,对落入某个voxel中的点云集合,将他们的特征做一个平均。其他的VFE方法(Pillar VFE)有:先将特征描述成局部关系的形式(f, fcluster, fcenter),其中f是point特征,fcluster 是point到点集合中心的距离, fcenter是point到空间中心的距离,然后对该形式的特征做MLP计算得到VFE结果。
在得到VFE的结果之后,可以利用稀疏卷积(SparseConv)提取3D特征,该卷积的计算原理与2D卷积相同,不过为了加速计算,只在有值的区域进行计算。具体的实现是通过开源仓库spconv。3D稀疏卷积主要结构是将原始输入的3维特征进行聚合压缩(一般8倍降采样) - 下路是Point分支:主要是对原始点云进行特征聚合Point Feature Encoding(PFE),利用PointNet++操作对局部点云先MLP聚合,然后在插值计算对feature进行propogation还原回原来的尺度。
Backbone2D
在上一阶段提取出了3D特征,但是3D特征的计算量大,因为现在将3D特征压缩到2D鸟瞰图BEV平面上进一步利用成熟的2D卷积方式进一步特征聚合。这个将3D压缩到2D的操作称为Map_to_bev.最简单的方式(Height Compression)就是将一个维度为[H,W,D,C]特征reshape成[H,W,DxC]。还有一种方式(Pillar Scatter):pillar的存储方式是[N,C],按照pillar的空间位置将其放到[HxW,C]的tensor中,然后在reshape成[H,W,C]。
接下来就是进行2D卷积的操作,如下图:
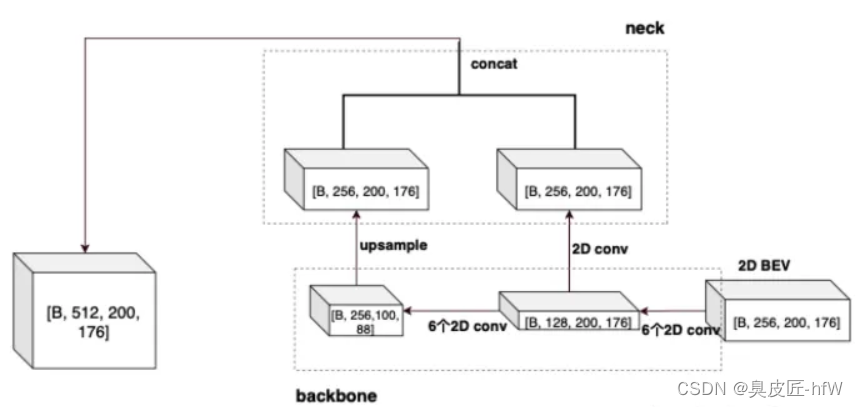
注:Backbone2D是PCDet3D算法中用于处理图像数据的主干网络,通常使用在基于深度学习的3D目标检测中,因为2D图像可以提供物体的几何形状、纹理、边缘等信息。Backbone2D通常采用先进的2D目标检测算法,例如Faster R-CNN、RetinaNet、Mask R-CNN等来提取图像特征。这些算法可以提取出与物体相关的ROI区域,并将这些ROI区域进行特征提取,从而得到图像的高维特征表示。这些特征表示可以与点云特征表示结合在一起,进行联合处理,从而提高检测算法的准确率。
需要注意的是,Backbone3D和Backbone2D均为主干网络,在PCDet3D算法中扮演着重要的角色,通过联合使用这两个主干网络,能够更全面、准确地对目标进行检测。
DenseHead
DenseHead是一阶段的检测头,主要是将2D backbone提取的特征做最后的任务划分,一般通过3个branch做3个任务,分别是物体分类、bbox回归、方向分类任务。此处详细描述一下基于anchor的bbox回归步骤:
- anchor generator先根据不同类别设定不同的anchors;
- 根据gt bbox给每个anchor 分配targets(assign_targets:AxisAligned或ATSS):根据IoU得到anchor的label,用box encoder计算bbox offset,最后用这个batch的物体数量作为weight系数,用来norm该batch的reg_loss.
- 三个branch(如下图)得到cls; bbox reg; dir作为prediction;
- 用prediction和anchor在box_decoder中计算最终一阶段结果。
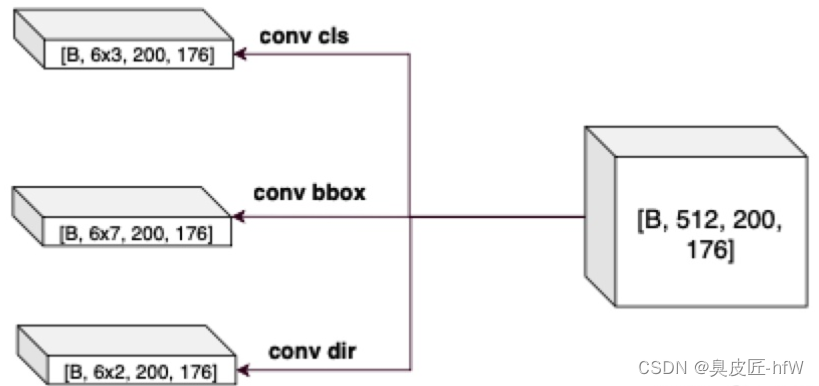
DenseHead是PCDet3D算法中的一个头部网络,用于从点云数据中密集地预测目标的位置和尺寸。DenseHead采用了基于二维卷积神经网络(CNN)的思想,将点云数据转化为三维张量表示。然后,对这些三维张量进行卷积和池化操作,从而提取出具有高表达能力的特征。接下来,通过多层全连接层,对这些特征进行进一步处理,最终得到点云中各个物体的位置和尺寸信息。DenseHead在点云数据中密集地预测物体,能够提高检测算法的召回率和精度。
RoIHead
RoIHead是二阶段检测头,在一阶段得到的结果上,二阶段的refine步骤如下:
(1)在proposal_layer中用NMS去减少一阶段的输出个数;
(2)对剩下的RoI区域assign targets,e.g., 对512个RoI区域按照IoU进行正负样本划分,随机选择符合条件的64个做正样本,64个负样本。
(3)利用RoI Grid Pooling等操作进行RoI区域的特征refine,然后进过MLP得到3个输出任务:cls,bbox reg,dir。
(4)最后经过box decoder得到最后的结果。
RoIHead是PCDet3D算法中的另一个头部网络,用于处理图像数据中的候选区域(RoIs)并进行目标检测。RoIHead通常采用先进的2D目标检测算法,例如Faster R-CNN、RetinaNet、Mask R-CNN等来提取图像特征。RoIHead将特征提取网络(如ResNet)作为主干网络,对RoIs进行特征提取,并将这些特征表示输入全连接层中,进行进一步处理。最终,RoIHead可以输出每个RoI对应的目标类别和位置信息。
需要注意的是,DenseHead和RoIHead都是用于处理不同类型的数据的头部网络,但是它们的输出可以联合在一起,得到最终的目标检测结果。具体来说,DenseHead和RoIHead输出的物体位置和尺寸信息可以通过一定的配准方式,与RoIs对应的图像区域进行配准,从而得到每个物体在三维空间中的准确位置和尺寸信息,实现3D目标检测。
VoxelNet算法解读
VoxelNet概述
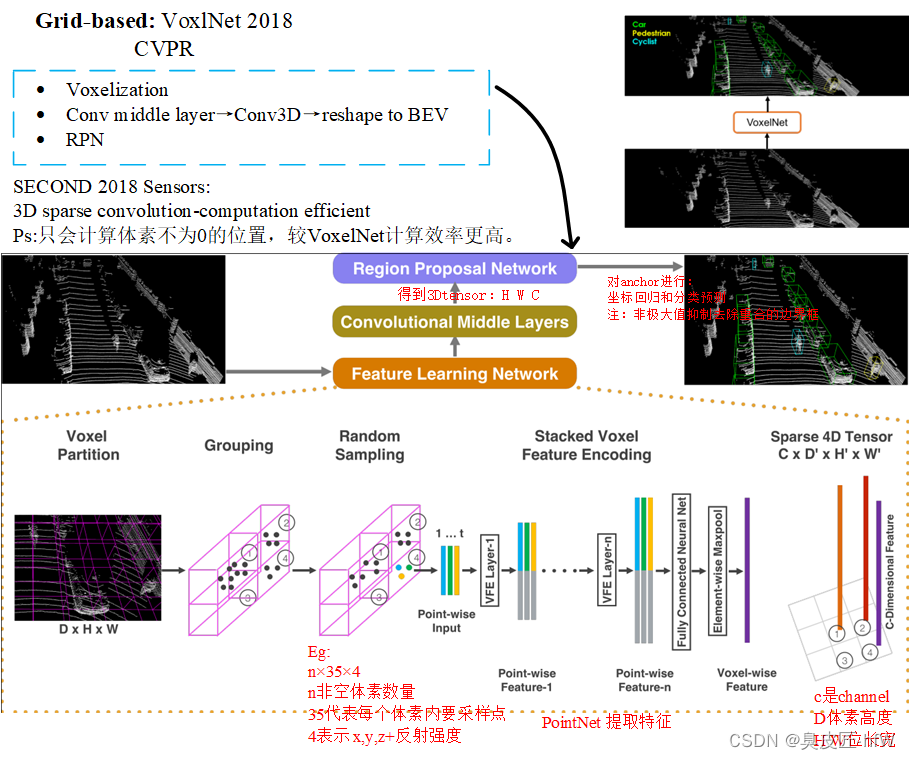
VoxelNet是一种基于体素的特征提取方法,将点云中点的信息与体素代表的局部信息融合,最终得到更具有表征能力的特征,该特征经过3D卷积用于RPN网络中得到目标检测的结果。原文链接:点击这里。
动机:
- 以往的基于体素的方法都是手工设计体素的特征,然后使用3D卷积处理,本文借鉴PointNet的方法,提出一种体素特征编码方法VFE,实现端到端。
- 采用一种简单的偏航角编码方法,也就是直接回归偏航角,不做复杂的偏航角编码。
网络结构
如下图所示:
总体代码解析
数据处理
VoxelNet的输入数据是点云,首先需要将点云数据处理成体素形式。在代码中,VoxelNet将点云数据划分为一系列体素,每个体素代表一块三维空间。然后,对每个体素内的点云进行特征提取,得到该体素内点云的特征表示。特征提取采用了基于二维卷积神经网络的方法,即将每个体素内的点云转换为三维张量,然后通过一系列卷积、池化等操作,提取出特征表示。
Backbone网络
VoxelNet的主干网络是一个基于二维卷积神经网络的三维卷积神经网络。该网络用于提取点云数据的特征表示,从而为目标检测提供特征输入。在代码中,VoxelNet采用了ResNet作为主干网络,用于对体素内的点云进行特征提取。
Proposal网络
VoxelNet采用Proposal网络对特征图中的候选框进行生成。该网络根据特征图中每个体素的特征表示,预测每个体素内是否存在物体,从而生成一系列候选框。在代码中,Proposal网络采用了基于多层感知器(MLP)的方法进行实现。
Region Proposal网络
VoxelNet使用Region Proposal网络对Proposal网络生成的候选框进行筛选。Region Proposal网络采用了二分类的方法,将候选框分为目标和非目标两类。在代码中,Region Proposal网络采用了基于MLP的方法进行实现。
Detection Head网络
VoxelNet采用Detection Head网络对筛选后的候选框进行目标检测。该网络根据候选框内的特征表示,预测目标的类别和位置信息。在代码中,Detection Head网络采用了基于MLP的方法进行实现。
损失函数
VoxelNet的损失函数由两部分组成:分类损失和回归损失。分类损失用于衡量目标分类的准确性,回归损失用于衡量目标位置的准确性。在代码中,分类损失采用了交叉熵损失函数,回归损失采用了平滑L1损失函数。
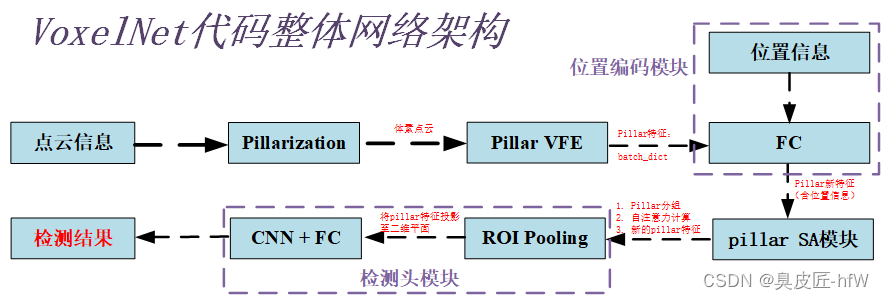
VoxelNet整体网络代码结构
- Pillar VFE模块将点云数据从原始坐标系中转换到体素坐标系中,并对每个体素进行聚合,生成该体素的特征表示
- 网络首先通过一个全连接层来学习每个体素的位置信息,将pillar特征与位置信息进行拼接,得到加入位置信息后的pillar特征。
- 接着将加入位置信息后的pillar特征传递给pillar SA模块进行处理,该模块通过分组的方式将所有pillar分到不同的组,对每个组内的pillar特征进行自注意力计算,最终得到每个pillar的新的特征表示。
- 然后将经过pillar SA模块处理后的pillar特征,传递给detection头,用于目标检测任务。
- detection头将pillar特征进一步加工,包括将pillar特征通过ROI Pooling投影到二维平面,再经过一系列卷积操作和全连接层得到最终的目标检测结果,包括目标的类别、位置和置信度等信息。
总的来说,VoxelNet整体网络可以分为四个模块,包括pillar VFE模块、位置编码模块、pillar SA模块和detection头模块,如下图所示。其中pillar VFE模块用于提取点云的局部特征,位置编码模块用于加入位置信息,pillar SA模块用于学习点云的全局关系,而detection头模块用于目标检测任务的具体实现。
Pillar VFE代码解析
"""
Pillar VFE, credits to OpenPCDet.
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
# Point Feature Net Layer 提取点云数据中的密集特征 PointNer操作
class PFNLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
use_norm=True,
last_layer=False):
super().__init__()
self.last_vfe = last_layer # 将密集特征提取网络中的最后一层保存到类成员变量self.last_vfe中
self.use_norm = use_norm # 归一化
if not self.last_vfe: # 如果last_vfe已经被赋值,则说明已经处理过了,这个if语句就不会执行
out_channels = out_channels // 2 # out_channels是密集特征提取网络中每个体素(pillar)输出的特征通道数
# 输出通道数减半,以适应后续网络模块的需求,2是经验值
if self.use_norm:
self.linear = nn.Linear(in_channels, out_channels, bias=False) # 初始化无偏置项的线性层
self.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01) # 初始化批归一化层(标准化)
else:
self.linear = nn.Linear(in_channels, out_channels, bias=True)
self.part = 50000 # 分批处理的参数,每个批次包含50000个样本
def forward(self, inputs):
if inputs.shape[0] > self.part: # 判断是否分批处理
# nn.Linear performs randomly when batch size is too large
num_parts = inputs.shape[0] // self.part # 处理批次数 //为整数除法
part_linear_out = [self.linear(
inputs[num_part * self.part : (num_part + 1) * self.part])
for num_part in range(num_parts + 1)]
# 列表推导式 , 该处的+1只为避免从0计数
# 使用nn.Linear对每个批次的数据进行线性变换,得到相应的特征表示
# inputs[num_part * self.part:(num_part + 1) * self.part] 切片操作
# 如 [0:50000] [50000:100000]
x = torch.cat(part_linear_out, dim=0) # 特征拼接
else:
x = self.linear(inputs)
torch.backends.cudnn.enabled = False
x = self.norm(x.permute(0, 2, 1)).permute(0, 2,
1) if self.use_norm else x # 如果标准化,使用permute改变张量维度, 如:(3,4,5)-->(3,5,4)
torch.backends.cudnn.enabled = True
x = F.relu(x) # 激活函数
x_max = torch.max(x, dim=1, keepdim=True)[0] # 沿着第二个维度(即channel 维度)取最大值
# keepdim=True 参数表示结果张量与输入张量 x 的维度相同,只是第二个维度变为了 1
if self.last_vfe:
return x_max
else:
x_repeat = x_max.repeat(1, inputs.shape[1], 1) # 如果是最后一层 VFE,只返回每个 pillar 对应的最大值,
x_concatenated = torch.cat([x, x_repeat], dim=2) #如果不是最后一层 VFE,还需要将这个最大值张量进行复制和拼接,以得到更多信息。
return x_concatenated
# 提取点云数据中的密集特征
class PillarVFE(nn.Module):
def __init__(self, model_cfg, num_point_features, voxel_size,
point_cloud_range):
super().__init__()
self.model_cfg = model_cfg # 模型配置,保存在类中,为后边取值
self.use_norm = self.model_cfg['use_norm'] # 是否使用Batch Normalization,默认为True
self.with_distance = self.model_cfg['with_distance'] # 距离信息
self.use_absolute_xyz = self.model_cfg['use_absolute_xyz'] # 绝对坐标
num_point_features += 6 if self.use_absolute_xyz else 3 # 使用绝对坐标6,6特征表示xyz + roll,yaw,pitch
if self.with_distance:
num_point_features += 1 # 使用距离信息特征维度+1
self.num_filters = self.model_cfg['num_filters'] # num_filters表示卷积核数量
assert len(self.num_filters) > 0
num_filters = [num_point_features] + list(self.num_filters)
pfn_layers = []
for i in range(len(num_filters) - 1):
in_filters = num_filters[i]
out_filters = num_filters[i + 1] # +1 可循环至最后一层
pfn_layers.append(
PFNLayer(in_filters, out_filters, self.use_norm,
last_layer=(i >= len(num_filters) - 2)) # 判断是否为最后一层
)
self.pfn_layers = nn.ModuleList(pfn_layers) # self.pfn_layers是一系列PFNLayer层的列表,用于后续的前向计算
self.voxel_x = voxel_size[0]
self.voxel_y = voxel_size[1] # 体素的长宽高
self.voxel_z = voxel_size[2]
self.x_offset = self.voxel_x / 2 + point_cloud_range[0] # 点云数据的范围和体素的大小之间的偏移量,
self.y_offset = self.voxel_y / 2 + point_cloud_range[1] # 用于后续的点云坐标转换操作
self.z_offset = self.voxel_z / 2 + point_cloud_range[2]
def get_output_feature_dim(self):
return self.num_filters[-1] # [-1] 最后一层特征维度
@staticmethod # 静态方法是一种不需要创建类实例即可访问的方法。与实例方法和类方法不同,静态方法不接收额外的参数(即self或cls)
def get_paddings_indicator(actual_num, max_num, axis=0):
actual_num = torch.unsqueeze(actual_num, axis + 1) # torch.unsqueeze 用于在指定维度上增加一个新的维度,eg:torch.Size([3, 4])-->torch.Size([3, 1, 4])
max_num_shape = [1] * len(actual_num.shape) # 增加一个新的维度以便与 max_num 进行比较
max_num_shape[axis + 1] = -1
max_num = torch.arange(max_num,
dtype=torch.int,
device=actual_num.device).view(max_num_shape) # 使用 torch.arange 生成一个张量 max_num,其形状与 actual_num 相同
paddings_indicator = actual_num.int() > max_num # paddings_indicator(布尔型张量),表示哪些位置需要填充
return paddings_indicator
# get_paddings_indicator函数的作用就是生成一个与输入张量的shape相同的张量,用于表示哪些位置是填充的。
# 例如,在PointNet++中,假设我们的输入张量为x,shape为(batch_size, num_points, num_features),
# 其中num_points是点的数量,我们需要将它填充到一个最大的点数max_points,
# 则可以使用get_paddings_indicator函数生成一个shape为(batch_size, max_points)的张量,表示哪些位置是填充的。
def forward(self, batch_dict):
# 先将特征描述成局部关系的形式(f, fcluster, fcenter),
# 其中f是point特征,fcluster 是point到点集合中心的距离,
# fcenter是point到空间中心的距离,然后对该形式的特征做MLP计算得到VFE结果
voxel_features, voxel_num_points, coords = \
batch_dict['voxel_features'], batch_dict['voxel_num_points'], \
batch_dict['voxel_coords'] # 取出体素特征、体素内点的数量和体素坐标,模型的输入数据
# voxel_features张量的形状为 (N,T,C),其中 N 表示非空体素网格的数量,T 表示每个体素点个数,C 表示每点特征
# voxel_coord是(N, 3)的二维张量,包括三列体素坐标(x, y, z)
points_mean = \
voxel_features[:, :, :3].sum(dim=1, keepdim=True) / \
voxel_num_points.type_as(voxel_features).view(-1, 1, 1) # 根据每个体素的特征和点数,计算每个体素中所有点特征的平均值,用于后续计算聚类特征
# 该处的voxel_features[:, :, :3]表示的就是体素的中心在x轴,y轴和z轴上的坐标
f_cluster = voxel_features[:, :, :3] - points_mean # point到点集合中心的距离,得到聚类特征
# 先获取对应体素的坐标,然后根据self.voxel_x、self.voxel_y、self.voxel_z和x_offset、y_offset、z_offset计算出每个坐标轴上的位置,
# 并将其与voxel_features[:, :, :3]相减得到中心相对位置。
# 体素坐标通常用一个四元组 (batch_idx, z_idx, y_idx, x_idx) 来表示,对于一个体素在对应坐标轴上的位置可以通过x = x_idx * voxel_x + x_offset计算
f_center = torch.zeros_like(voxel_features[:, :, :3]) # 创建一个和voxel_features[:, :, :3]形状一样的全零张量f_center,这个张量是用来存储中心相对位置
f_center[:, :, 0] = voxel_features[:, :, 0] - (
coords[:, 3].to(voxel_features.dtype).unsqueeze(
1) * self.voxel_x + self.x_offset) # coords[:, 3]、coords[:, 2]和coords[:, 1]是获取每个体素的x、y、z坐标
# unsqueeze(1)是将它们的形状从(N,)变为(N,1),方便进行广播运算
f_center[:, :, 1] = voxel_features[:, :, 1] - (
coords[:, 2].to(voxel_features.dtype).unsqueeze(
1) * self.voxel_y + self.y_offset)
f_center[:, :, 2] = voxel_features[:, :, 2] - (
coords[:, 1].to(voxel_features.dtype).unsqueeze(
1) * self.voxel_z + self.z_offset)
if self.use_absolute_xyz:
features = [voxel_features, f_cluster, f_center]
else:
features = [voxel_features[..., 3:], f_cluster, f_center]
if self.with_distance:
points_dist = torch.norm(voxel_features[:, :, :3], 2, 2,
keepdim=True)
features.append(points_dist)
features = torch.cat(features, dim=-1) # 拼接特征:将聚类特征、中心特征和其他特征(如法向量)进行拼接,得到每个体素的最终特征。
voxel_count = features.shape[1]
mask = self.get_paddings_indicator(voxel_num_points, voxel_count,
axis=0)
mask = torch.unsqueeze(mask, -1).type_as(voxel_features)
features *= mask # 掩码矩阵mask中的值为0或1,用于将无效的体素特征(即padding的体素)置为0,有效的体素特征不变
for pfn in self.pfn_layers:
features = pfn(features)
features = features.squeeze()
batch_dict['pillar_features'] = features
return batch_dict
# 首先通过一个for循环遍历self.pfn_layers列表中的所有PFN层,对输入的features进行多次处理和转换。在每个PFN层中,
# features会被送入多个卷积和归约操作,以得到更加高维和抽象的特征表示。
# 最终处理完的features被进行squeeze操作,将维度为1的维度去除掉,
# 然后将结果赋值给batch_dict字典的pillar_features键。最后将batch_dict返回