算法重点
算法分类汇总:
- 聚类:无监督学习,学习结果将产生几个集合,集合中的元素彼此相似;
- 分类 (class) :有监督学习,学习结果将产生几个函数,通过函数划分为几个集合,数据对象是离散值;
- 回归 (regression):有监督学习,学习结果将产生几个函数,通过函数产生连续的结果,数据对象是连续值;
算法集成有三种方式(bagging ,Boosting,Stacking), 常见集成算法:
- 随机森林(Random Forest: bagging + 决策树): 将训练集按照横(随机抽样本)、列(随机抽特征)进行有放回的随机抽取,获得n个新的训练集,训练出n个决策树,通过这n个树投票决定分类结果。主要的parameters 有n_estimators 和 max_features。
-
Adaboost (adaptive boosting: boosting + 单层决策树): 训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在统一数据集上再训练分类器。在第二次训练中,会调高那些前一个分类器分类错误的样本的权重。如此反复,训练出许多分类器来进行加权投票,每个分类器的权重是基于该分类器的错误率计算出来的。
-
GBDT (Gradient Boosting Decision Tree: boosting + 决策树):GBDT与Adaboost类似,反复训练出多个决策树,每次更新训练集的权重是按照损失函数负梯度的方向。过程比较复杂,这里不赘述。参数说明:n_estimators是弱分类器个数;max_depth或max_leaf_nodes可以用来控制每棵树的规模;learning_rate是hyper-parameter,取值范围为(0, 1.0], 用来控制过拟合与欠拟合。
-
决策树还有个兄弟回归树,GBDT也有个兄弟GBRT用来做回归:
-
-
自己设计: 根据bagging或者boosting思想,自己选择弱分类器来集成: 比如knn集成算法
召回率和精确率:
-
召回率(Recall): 表示的是样本中的正例有多少被预测正确了(找得全)所有正例中被正确预测出来的比例。 # 本来是正确值同时预测值为正确值的比例
用途:用于评估检测器对所有待检测目标的检测覆盖率
-
精确率(Precision): 表示的是预测为正的样本中有多少是真正的正样本(找得对)。预测结果中真正的正例的比例。
用途:用于评估检测器在检测成功基础上的正确率
可参考博客: 八种常见回归算法解析及代码
一 聚类算法
聚类算法是无监督学习的一种算法,也就是说,并没有一批已经打好标签的数据供机器训练模型。因此该算法用于在数据中寻找数据间隐藏的联系和区别。通过聚类后形成几个集合,集合内部的元素间具有较高的相似度,相似度的衡量可以通过欧几里得距离、概率距离、加权重距离计算。
常见的聚类算法有:
1.划分聚类: K-means 算法、k-medoids算法、K-pototypes算法、CLARANS算法
2.层次聚类:BIRCH算法、CURE算法、
3.密度聚类:DBSCAN算法、OPTICS算法、DENCLUE算法
4.网格聚类:STING算法、CLIQUE算法、WAVE-CLUSTER算法
5.混合聚类:高斯混合模型 (符合正太分布的聚类) 、CLIQUE算法(综合密度和网格的算法)
几个聚类算法的简单对比:
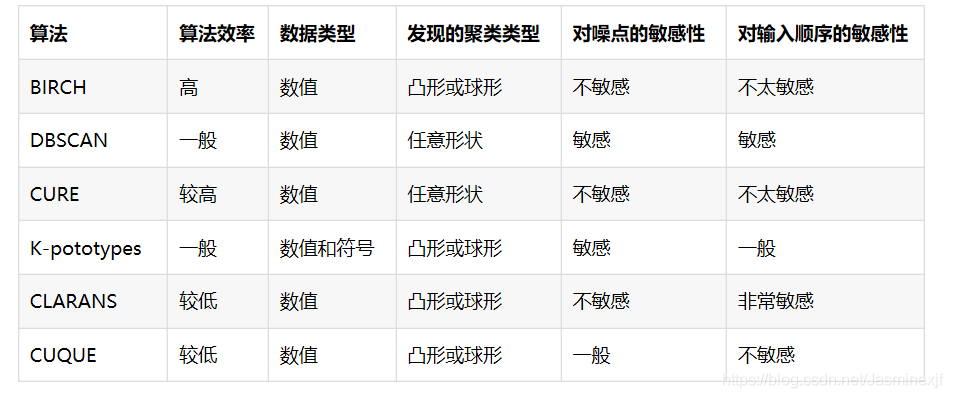
二 分类算法
分类算法要求先向模型输入数据的训练样本,从训练样本中提取描述该类数据的一个函数或模型。通过该模型对其他数据进行预测和归类,分类算法是一种对离散型随机变量建模或预测的监督学习算法,同时产生离散的结果。比如在医疗诊断中判断是否患有癌症,在放贷过程中进行客户评级等。
常见的分类算法:
1.决策树:ID3、C4.5(C5.0)、CART、PUBLIC、SLIQ、SPRINT算法;
2.神经网络:BP网络、径向基RBF网络、Hopfield网络、随机神经网络(Boltzmann机)、竞争神经网络(Hamming网络,自组织映射网络);
3.贝叶斯:朴素贝叶斯(Naive Bayes)算法、TAN算法;
4.基于关联规则的分类:CBA算法、ADT算法、CMAR算法、ARCS算法;
5.混合分类方法:Bagging算法、Boosting算法
6.支持向量机:SVM
7. K近邻:(K-Nearest Neighbor, KNN)knn
三 回归算法
回归算法与分类算法一样都是有监督的学习算法,因此也需要先向模型输入数据的训练样本。但是与分类算法的区别是,回归算法是一种对数值型连续随机变量进行预测和建模的监督学习算法,产生的结果也一般是数值型的。
例如向已经训练好的回归模型中输入一个人的数据,判断此人20年后的经济能力,则模型的回归结果是连续的,往往得到一条回归曲线。当自变量改变时,因变量呈现连续型变化。
常见的回归算法:
1.线性回归/逻辑回归(LogisticRegression)/多项式回归:LR算法、LWLR算法(局部加权)、LRCV算法(交叉验证)、MLP算法(神经网络); (信用卡反欺诈项目 lgr)
2.逐步回归;
3.岭回归;
4.LASSO回归;
5.ElasticNet回归;
四 数据优化处理方式
- 归一化: 减少数据不同数量级对预测的影响, 主要是将数据不同属性的数据都降到一个数量级。
- 最大值最小值归一化:优点是可以把所有数值归一到 0~1 之间,缺点受离群值影响较大。
- 0-均值标准化: 经过处理的数据符合标准正态分布,即均值为0,标准差为1, 有正有负。
- 降低维度算法: 降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式,试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。
- 常见的算法包括:主成份分析(Principle Component Analysis, PCA)、偏最小二乘回归(Partial Least Square Regression,PLS)、 Sammon 映射、多维尺度(Multi-Dimensional Scaling, MDS)、投影追踪(Projection Pursuit)等。
-
多项式回归:数据升维, 数据不够时防止欠拟合, 通常是使用现有参数相乘, 或者自身平方达到增加数据量的目的。
- 使用 PolynomialFeatures 进行 特征升维
- 特征自身的高阶版:
- 特征与特征之间的组合特征:
五 算法集成
集成算法有三种(bagging ,Boosting,Stacking)
- 1. bagging: 训练多个分类器取平均(最典型的就是随机森林)
- 随机:数据采样随机,特征选择随机
- 森林:多棵树
- 随机优点:
- 处理 很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要(根据噪音值训练出的结果影响程度)
- 容易做成并行化方法,速度比较快
- 可以进行可视 化展示,便于分析
- 2、 Boosting: 从弱学习器(弱分类器)开始加强,通过加权来进行训练,先构造第一棵树,计算残差,每增加一颗树,与之前的树对比,使得残差变小 (典型代表是AdaBoost Xgboost)
- AdaBoost : 第一次训练每个数据的权重是一样的,如果某一个数据分类错了,下一次的训练就会增增加这个数据的权重。 (手写数字识别项目)
- Xgboost: 高效地实现了GBDT算法并进行了算法和工程上的改进。(京东购买意向项目)
-
LightGBM: 该算法也是基于GBDT算法的改进,,但相较于GBDT、XGBoost算法, LightGBM算法有效地解决了处理海量数据的问题。 (天猫复购项目)
-
GBDT算法的基本思想是把上一轮的训练残差作为下一轮学习器训练的输入,即每一次的输入数据都依赖于上一次训练的输出结果。因此,这种训练迭代过程就需要多次对整个数据集进行遍历,当数据集样本较多或者维数过高时会增加算法运算的时间成本,并且消耗更高的内存资源。
而XGBoost算法作为GBDT的一种改进,在训练时是基于一种预排序的思想来寻找特征中的最佳分割点,这种训练方式同样也会导致内存空间消耗极大,例如算法不仅需要保存数据的特征值,还需要保存特征排序的结果;在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大,特别是当数据量级较大时,这种方式会消耗过多时间。
为了对这些问题进行优化,2017年微软公司提出了LightGBM算法(Light Gradient Boosting Machine),该算法也是基于GBDT算法的改进,,但相较于GBDT、XGBoost算法,LightGBM算法有效地解决了处理海量数据的问题,在实际应用中取得出色的效果。LightGBM算法主要包括以下几个特点:直方图算法(寻找最佳分裂点、直方图差加速)、Leaf-wise树生长策略、GOSS、EFB、支持类别型特征、高效并行以及Cache命中率优化等。
-
- 最终的结果:根据每棵树的准确性来确定树的权重
- 3、 Stacking: 聚合多个分类或回归模型
- 根据之前的多个算法的结果进行新的训练
- 分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
- 可以堆叠各种各样的分类器(KNN,SVM,RF等)
六 自然语言算法
- 概率图模型:可以分为有向图模型和无向图模型。
- 有向图模型(又称为贝叶斯网络),例如:隐马尔科夫模型(Hidden Markov Model,HMM)
- 无向图模型(又称为马尔科夫网络),例如:条件随机场(Conditional Random Fields,CRF)
- 朴素贝叶斯: 可以看做是贝叶斯网络的特殊情况:即该网络中无边,各个节点都是独立的(前提是独立性假设)。
- 贝叶斯网络: 那么,当朴素贝叶斯中的假设:独立同分布不成立时,应该如何解决呢?可以使用贝叶斯网络。
- 隐马尔科夫: HMM 就是贝叶斯网络的一种--虽然它的名字里有和"马尔可夫网"一样的马尔可夫。
七 最佳参数筛选
param_grid = {'C': [0.01,0.1, 1, 10, 100, 1000,],'penalty': [ 'l1', 'l2']}
# 确定模型LogisticRegression,和参数组合param_grid ,cv指定10折
grid_search = GridSearchCV(LogisticRegression(),param_grid,cv=10)
grid_search.fit(X_train, y_train) # 使用训练集学习算法