前面我们讨论了线性回归、softmax分类和感知机这些模型,这些模型构建的过程都是有监督的学习,需要借助大量的样本来学习最优的参数,基本原理时通过链式法则使用梯度下降来对参数进行调整。虽然说起来比较简单,但是在实际操作的时候,模型训练需要关注很多细节,包括去模型是否会出现过拟合的现象,模型的超参数是否合理,训练的数据和验证的数据如何进行划分,这都需要进一步来探讨。今天这节我们来一起讨论一下深度学习中模型训练你需要关注的一些细节以及你需要掌握的一些基础知识。
开始之前给大家安利一下我之前写的使用tensorflow2构建物体分类模型的博客,我在博客中详细介绍了数据集收集、模型构建和模型使用三个方面,结合视频你也可以快速构建自己的物体分类模型,快去试试吧!
手把手教你用tensorflow2.3训练自己的分类数据集_dejahu的博客-CSDN博客
训练集和验证集
和我们高考一样,如果时学习的方法不合理,虽然你在平时的作业中可以取得好的成绩,但是遇到考试的时候你还是不能考的很好,即使你做了大量的练习题,在机器学习的过程中也存在这个问题,平时的练习好比训练,最后的考试好比验证,我们不会使用平时的成绩来对你的学习能力进行衡量,而是通过你最后的考试成绩来决定你是否足够优秀。
所以在机器学习中存在两个误差:训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
数据集一般会划分为3类,训练数据集、验证数据集和测试数据集,其中训练数据集是用来调整模型权重参数使用的,验证数据集用来保存模型,测试数据集用来评估模型。可以将训练数据集看作是练习题,验证数据集看作是模考,测试数据集是最后的高考。
在小规模的数据集上可以采用k-折交叉验证的方法来对模型进行评估,我们将原始的数据分为K个部分,选择其中的一个部分作为验证集,另外的部分作为训练集,不断更换,进行k轮,这样得到的模型鲁棒性更好。一般而言,k取5或者10。
过拟合和欠拟合
在房价预测的任务上,我们可以将样本看作是一个在二维空间上分布的一个个的点,通过mlp强大的学习能力,能够学习到一个参数很多的模型,完美地通过所有的样本点,但是这样做是不对的,因为一是数据存在噪声,而是这样的模型就失去的预测的功能,只能在已知的数据上表现好的效果,如下图所示,第一张图展示的是欠拟合的情况,第二张图展示的是拟合的情况,第三张图展示的则是过拟合的情况。
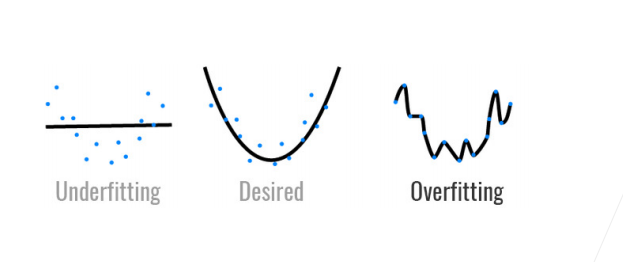
所以模型的容量至关重要,一般而言,模型的容量越小,学习能力不足,容易导致欠拟合的情况出现,这种情况下模型的训练误差和泛化误差都比较高,另外一种情况是模型的容量过大,导致模型的学习能力过大,在训练集上表现得特别好,但是在实际验证得过程中表现得特别不好,这样得到得模型训练误差小,但是泛化误差极大。
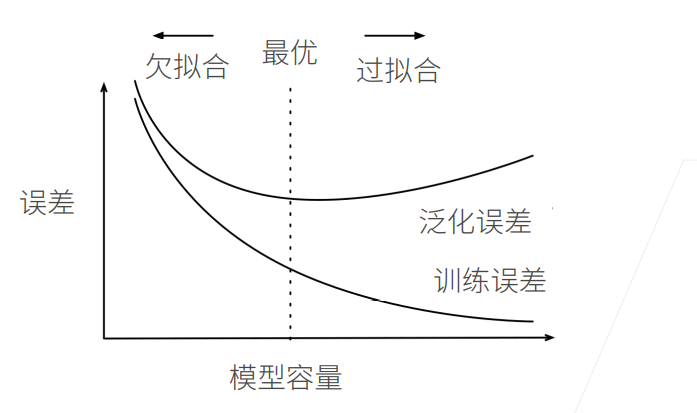
参数容量的估计可以使用一个VC维的方法,不过我不是数学专业的,这里就不过多讨论,实际的情况是通过我们人的观察来定,这就是机器学习中的炼丹。
如何防止过拟合
现在的深度学习模型的学习能力都比较强大,导致欠拟合的原因多是因为样本不足,这也是目前深度学习的弊端,所以有个热门的研究方向是小样本学习。为了防止欠拟合的情况出现,这里是两个方法,一个是权重衰减,一个是随机丢弃,他们的核心思想就是在原来那么多的参数上想办法把参数减少。
权重衰减是减少边的数量,dropout是减少神经元的数量
权重衰减
权重衰减主要是在原有的损失函数的基础上添加了新的L2正则项,这个的目的是为了减少参数的数量,也就是优化目标同时又两个,一个是减少模型在数据上的误差,一个是让参数的尽可能的少,使用公式表达如下:
l ( w 1 , W 2 , b ) + λ 2 n ∣ ∣ w ∣ ∣ 2 l(w_1, W_2, b) + \frac{\lambda}{2n}||w||^2 l(w1,W2,b)+2nλ∣∣w∣∣2
后面一项中有个参数需要调整,就是这个 λ \lambda λ,这同时也带来一个问题,就是这个超参数的取值,过大和过小都会存在问题,过大会导致模型只是一昧地减少参数,而不是去适应数据集,而这个参数过小又失去了其原有的意义,所以需要根据实际的实验效果来调整。
Dropout
还是刚才所提到的问题,我们不能只追求在训练集上有好的表现,所以对于一个好的模型而言,我们应该给他添加一些噪声,后面的数据增强其实也有这方面的作用。
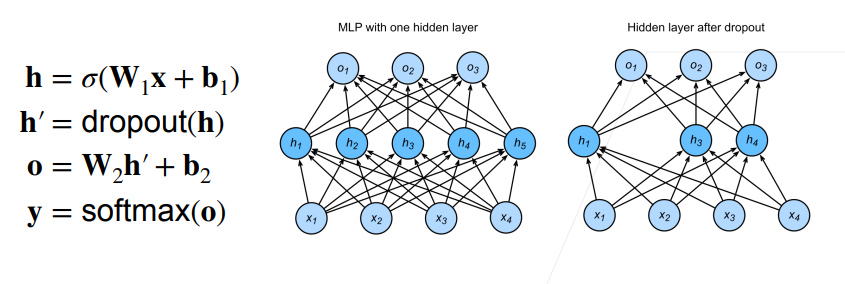
丢弃法没有复杂的数学原理,主要使用在全连接层,指定丢弃的概率,然后随机将这些神经元的梯度设置为0,如下图所示:
数值稳定性
开始我们提到了模型是通过链式法则来进行参数的更新的,在深度学习网络中,累乘是个基本操作,这也就导致梯度消失和梯度爆炸的情况的出现,这张图就非常形象。


这种情况也会导致你在实际的网络训练过程中loss会出现nan和inf,前期研究人员多集中在解决两个问题上,比如传统的sigmoid激活函数在函数的左右两侧的梯度就会非常小,这样导致模型训练缓慢并且没有办法向着更深层次进展,这里给出两个解决方案,一个是随机初始化,一个是更换成合适的激活函数。
这里说下resnet,刚才说了导致问题的原因在乘法,所以可以让乘法变成加法,也就是resnet和lstm的思想。
-
随机初始化
归一化在数学上也比较讲究,可以将每层的输出和梯度看作是随机变量,让他们的均值和方差保持一致,就不容易跑偏,比较好的方案是xavier初始化,好像Pyotrch中是0.7这个区间波动,如下:
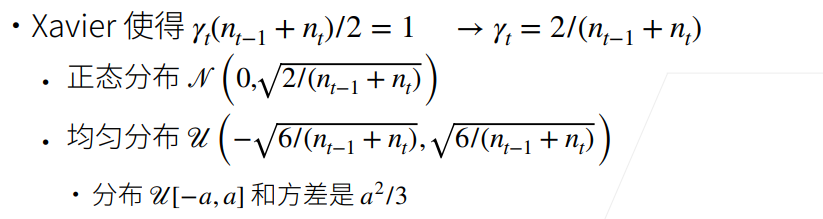
-
激活函数
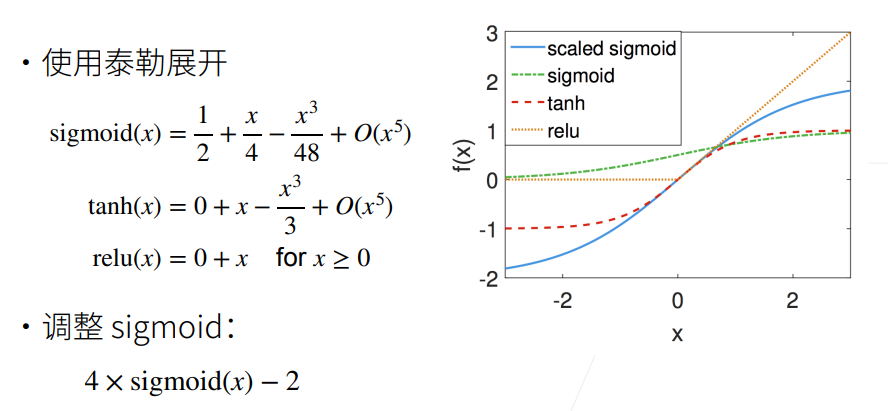
这里是几组常用的激活函数,也可以关注最新的论文进展,在你的模型中使用好的激活函数来试试看。