ML入门4.0 手写逻辑斯蒂回归 (Logistic Regression)
逻辑斯蒂回归简介
Logistic Regression 即对数概率回归,是一种广义的线性回归分析模型,是一种应用于二分类问题的分类算法。
常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。百度百科
原理简介
逻辑回归解决二分类问题,所谓分类就是分割数据,那么逻辑回归的本质就是通过在数据集中学习,拟合出分类的决策边界(决策函数)。
决策边界
两个条件属性(二维平面直角坐标系中):决策边界为直线;
三个条件属性(三维空间直角坐标系中):决策边界为平面;
四个条件属性(四维坐标系中):决策边界为超平面;
线性分割面的表达
二维: (PS: )
三维:
四维:
向量表达:
n维:
(X为行向量,W为列向量)
学习与分类
Logistic Regression 的回归任务就是计算向量W
二分类:对于新的对象X’,计算X’W:结果小于0则为0类,否则为1类
损失函数
定义:度量预测结果和实际结果之间的差别
第一种损失函数
令 ,
MSE =
其中
就是分类函数给出的标签, 是真实标签
优点:表达了错误率
缺点:函数H不连续,无法使用优化理论
第二种损失函数
MSE =
其中 ,
;
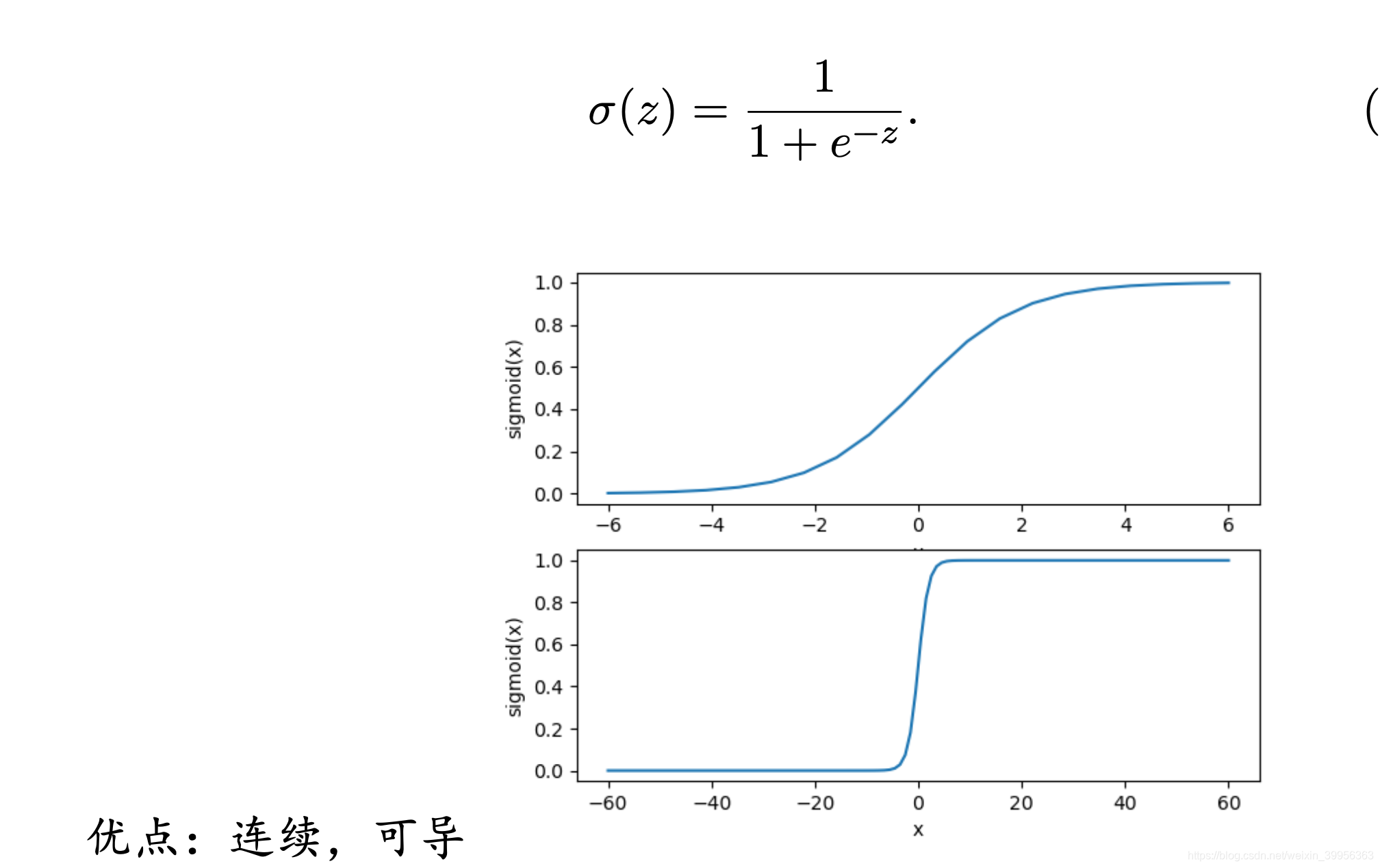
缺点:非凸优化,多个局部最优解
第三种损失函数
因为
, 所以将分类函数强行看作概率。
假设:
$P (y_{i} = 0|x_{i}; w) = 1 - σ(x_{i}w)
综合两式可得
由此获得似然函数:
因为log具有单调性
优化目标为 :
梯度下降法
通过求得优化目标的方向导数(梯度),来确定函数下降的最快方向,由此来更新W以获得最佳W
代码实现
Func1: LoadDataSet(paraFileName)加载数据集
def LoadDataSet(paraFileName):
'''
LoadDataSet
:param paraFileName:
:return: 特征&标签
'''
dataMat = []
labelMat = []
txt = open(paraFileName)
for line in txt.readlines():
tempValuesStringArray = np.array(line.replace("\n", "").split(','))
tempValues = [float(tempValue) for tempValue in tempValuesStringArray]
tempArray = [1.0] + [tempValue for tempValue in tempValues] # 相当于w0对应的x0
tempX = tempArray[:-1]
tempY = tempArray[-1]
dataMat.append(tempX)
labelMat.append(tempY)
return dataMat, labelMat
Func2: sigmoid(paraX)分类函数实现
def sigmoid(paraX):
'''
sigmoid函数实现
:param paraX:参数
:return: 计算结果
'''
return 1.0/(1 + np.exp(-paraX))
Func3: gradAscent(dataMat, labelMat)梯度上升法(因为取了优化目标的相反数,所以要求上升最快的方向)求W
def gradAscent(dataMat, labelMat):
'''
用梯度上升法求得最优权重
:param dataMat:
:param labelMat:
:return:
'''
X = np.mat(dataMat)
Y = np.mat(labelMat) #transfer the input to matrix
Y = Y.transpose()
m, n = np.shape(X)
alpha = 0.001 # 学习步长
maxCycles = 1000
W = np.ones( (n,1))
for i in range(maxCycles):
y = sigmoid(X * W)
error = Y - y
W = W + alpha * X.transpose() * error
return W
Func4: STLogisticClassifierTest ()手写分类器
def STLogisticClassifierTest():
'''
Logistic 分类器
'''
X, Y = LoadDataSet('iris2condition2class.csv')
tempStartTime = time.time()
tempScore = 0
numInstances = len(Y)
weights = gradAscent(X, Y)
tempPredicts = np.zeros((numInstances))
for i in range(numInstances):
tempPrediction = X[i] * weights
if tempPrediction > 0:
tempPredicts[i] = 1
else:
tempPredicts[i] = 0
tempCorrect = 0
for i in range(numInstances):
if tempPredicts[i] == Y[i]:
tempCorrect += 1
tempScore = tempCorrect / numInstances
tempEndTime = time.time()
tempRunTime = tempEndTime - tempStartTime
print('STLogistic Score: {}, runtime = {}'.format(tempScore, tempRunTime))
rowWeights = np.transpose(weights).A[0]
plotBestFit(rowWeights)
运行结果

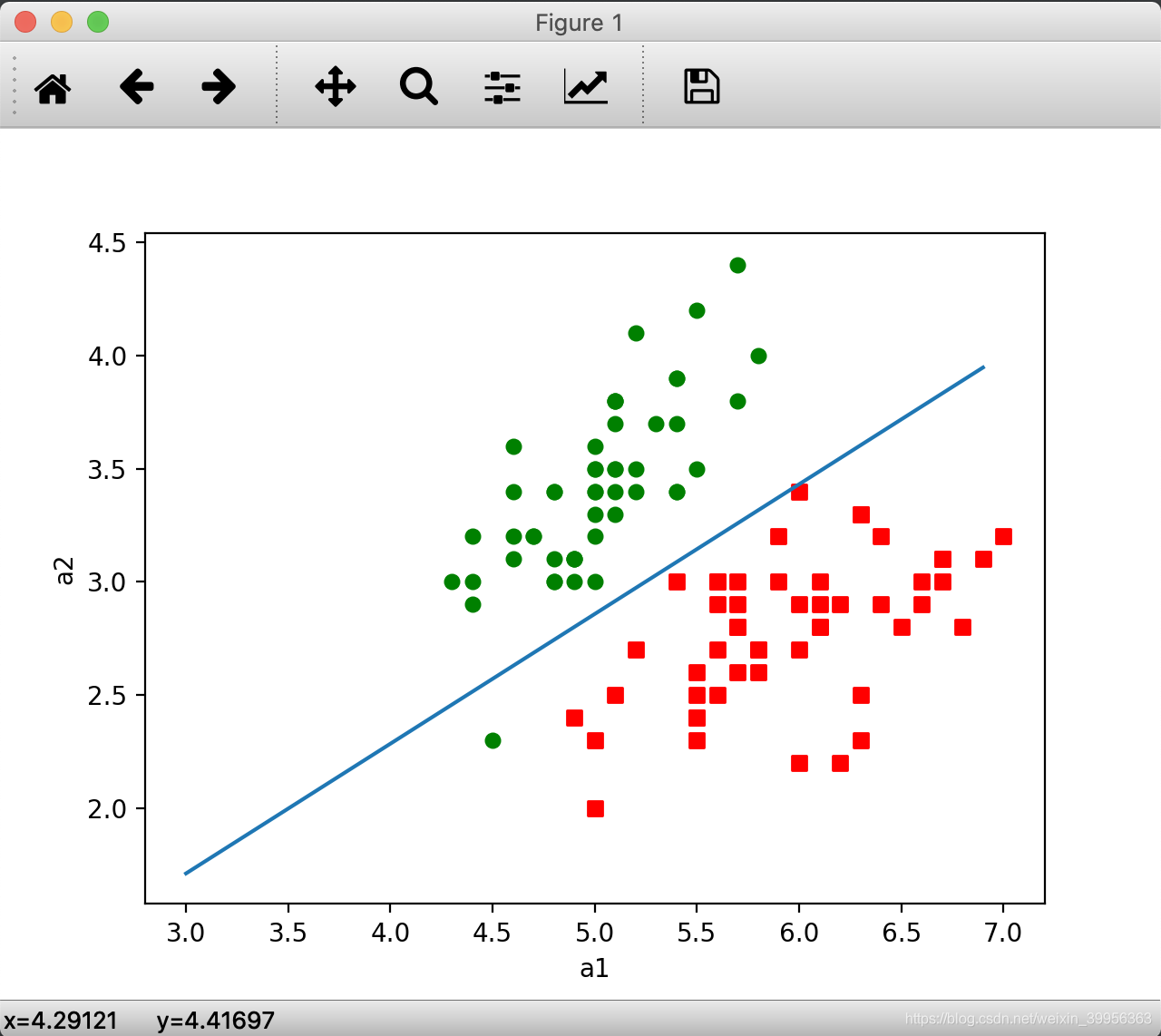
GitHub地址
完整代码和数据集见github.
优缺点
优点:
1.适合需要得到一个分类概率的场景。2.计算代价不高,容易理解实现。LR在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。3.LR对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。
缺点:
1.容易欠拟合,分类精度不高。2.数据特征有缺失或者特征空间很大时表现效果并不好。