学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
当下是数据信息时代,数据规模往往无法在单台计算机上处理。但是可以应用 Apache Spark、Hadoop 等技术可以解决这种问题。Python 也可以使用 PySpark 进行相关操作。

文章目录
Python 中的大数据概念
Python 的几种编程范式,例如面向数组的编程、面向对象的编程、异步编程,还有函数式编程。函数方式代码可以在多个 CPU 甚至完全不同的机器上运行,从而解决单个工作站的物理内存和 CPU 限制。
函数式编程的核心思想是数据应该由函数操作,而不需要维护任何外部状态。函数式编程中另一个常见的想法是匿名函数。Python 使用 lambda 关键字。
Lambda 函数
Python 中的 lambda 函数是内联定义的,并且仅限于单个表达式。
sorted 排序
x = ['bachou', 'batai', 'chouhi', 'chouhou']
print(sorted(x))
['bachou', 'chouhou', 'chouhi', 'batai']
print(sorted(x, key=lambda arg: arg.upper()))
['chouhou', 'chouhi', 'batai', 'bachou']
filter() 条件过滤
x = ['bachou', 'batai', 'chouhi', 'chouhou']
print(list(filter(lambda arg: len(arg) < 6, x)))
['batai']
# 等价于
def is_less_than_6_characters(item):
return len(item) < 6
x = ['bachou', 'batai', 'chouhi', 'chouhou']
results = []
for item in x:
if is_less_than_6_characters(item):
results.append(item)
print(results)
map() 迭代应用每个项目
x = ['bachou', 'batai', 'chouhi', 'chouhou']
print(list(map(lambda arg: arg.upper(), x)))
['BACHOU', 'BATAI', 'CHOUHI', 'CHOUHOU']
## 等价于
results = []
x = ['bachou', 'batai', 'chouhi', 'chouhou']
for item in x:
results.append(item.upper())
print(results)
['BACHOU', 'BATAI', 'CHOUHI', 'CHOUHOU']
reduce() 函数应用于可迭代的元素
from functools import reduce
x = ['bachou', 'batai', 'chouhi', 'chouhou']
print(reduce(lambda val1, val2: val1 + val2, x))
bachoubataichouhichouhou
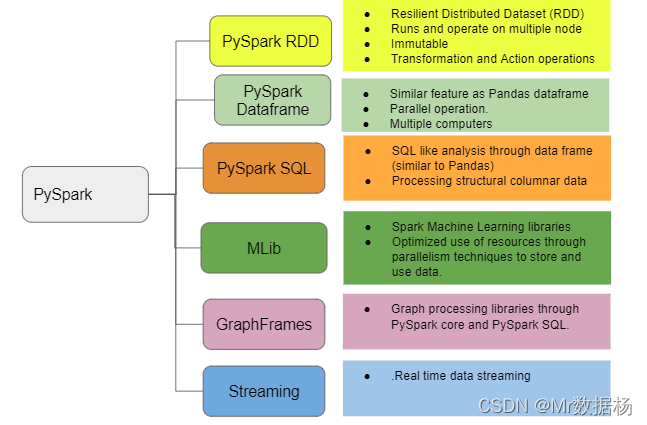
Spark 和 PySpark
Apache Spark 由几个组件组成,Spark 的核心是用于处理大量数据的通用引擎。Spark 用 Scala编写并在JVM上运行。Spark 具有用于处理流数据、机器学习、图形处理甚至通过 SQL 与数据交互的内置组件。
机器学习、SQL 等所有其他组件也都可以通过 PySpark 用于 Python 项目。
PySpark
通过 Python 访问所有 Spark 是在 Scala 中实现的在 JVM 上运行的操作。将 PySpark 视为 Scala API 之上的基于 Python 的包装器。更多接口类的内容可以参考 Spark官方文档 。
PySpark API 和数据结构
与 PySpark 交互,需要创建称为弹性分布式数据集(RDD) 的专用数据结构。在集群上运行 RDD 隐藏了调度程序在多个节点上自动转换和分发数据的所有复杂性。

集群的身份认证
conf = pyspark.SparkConf()
conf.setMaster('spark://data_node:00001')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)
PySpark 中的 Hello World
任何 PySpark 程序的入口点都是一个SparkContext对象。
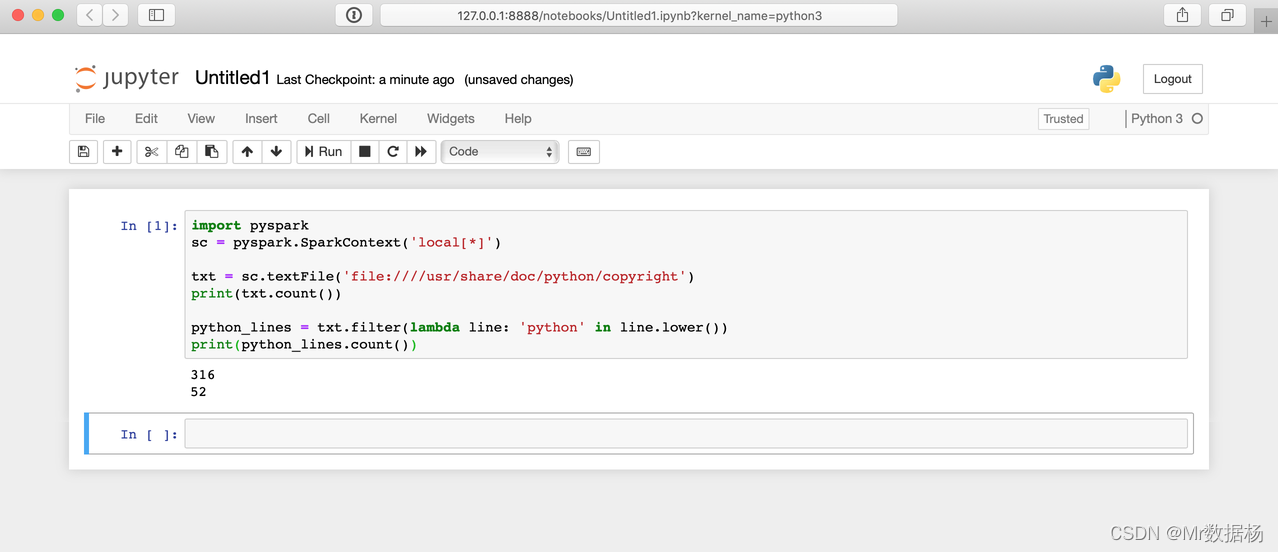
import pyspark
sc = pyspark.SparkContext('local[*]') # 使用本地集群
txt = sc.textFile('file:usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'bachou' in line.lower())
print(python_lines.count())
PySpark 安装
PySpark 运行在 JVM 之上,需要大量底层Java基础设施才能运行。在当下的 Docker 时代却使得 PySpark 的实验变得更加容易。
Jupyter 团队出色开发人员已经发布了一个 Dockerfile,其中包含所有 PySpark 依赖项以及 Jupyter。因此可以直接在 Jupyter notebook 中进行各种操作。
构建 PySpark 单节点设置的 Docker 容器。
$ docker run -p 8888:8888 jupyter/pyspark-notebook
PySpark 运行
Jupyter Notebook
这里有个问题就是浏览器不会像Win系统一样自动弹出,需要手动复制连接到浏览器。
$ http://127.0.0.1:8888/?token=xxxxxxxxxxxxxxxxxxxxx
执行之前的 Hello World 程序。
命令行操作
运行 Docker 容器需要通过 shell 而不是 Jupyter 笔记本连接脚本。
$ docker run -p 8888:8888 jupyter/pyspark-notebook
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1d5ab1a23912 jupyter/pyspark-notebook "tini -g -- start-no…" 10 seconds ago Up 10 seconds 0.0.0.0:8888->8888/tcp xxxxx
其中 1d5ab1a23912 作为容器的唯一ID使用。
PySpark 与其他工具结合使用
PySpark 附带了额外的库来执行机器学习和大型数据集的类似 SQL 的操作。也可以使用其他常见的科学库,例如 NumPy 和 Pandas 。
使用时候注意确保每个集群的节点上都安装对应的三方库,才能正常使用。
建议保持 python 的版本一致和三方库的版本一致。