写在前面
在刚开始接触hadoop的时候,在学习了好多久,有一些不仔细导致掉了好多坑,后面搭建成功写下这篇文章希望能帮助到更多人少掉坑。我的惯例先介绍各个版本:
系统环境:Linux Mint 18.2(Ubuntu16.04)
hadoop版本:hadoop 2.7.1
其次我用到了两台电脑作为集群的节点,应用如下:
| 节点类型 | 节点机器名称 | IP |
|---|---|---|
| master | mryang | 192.168.27.228 |
| slave | workstation | 192.168.27.165 |
注意:此处坑来了
1.必须保证两个机器的IP的路由段一样,之前遇到两个IP分别是:192.168.1.112和192.168.27.170,到后面无论如何有一个都拒绝ssh访问通信。
2.必须保证在所有slave节点上创建的用户名和master节点上创建的用户名一样,因为hadoop是通过hadoop2.7.1@slave来访问slave节点的,master节点上的用户名(本文为hadoop2.7.1),如果不一样则访问不了。
SSH无密码登录节点
选择一台机器作为master
在这台master机器首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户(一旦创建就会在主用户的/home/目录产生一个对应目录如下,其中youjun是我的主用户,其它两个为我新创建的用户用来搭建hadoop集群的,请勿删除) :
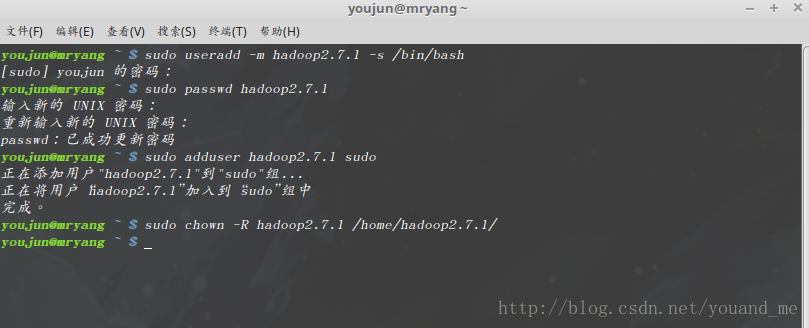
sudo useradd -m hadoop2.7.1 -s /bin/bash这条命令创建了可以登陆的hadoop2.7.1用户,并使用/bin/bash作为shell。
接着使用如下命令设置密码,按提示输入两次密码:sudo passwd hadoop2.7.1可为hadoop_master用户增加管理员权限,并且给hadoop2.7.1用户处理/home/hadoop2.7.1/目录的权限,方便部署,避免一些对刚接触的人来说比较棘手的权限问题:
sudo adduser hadoop2.7.1 sudo sudo chown -R hadoop2.7.1 /home/hadoop2.7.1/执行效果如下图:
最后注销当前用户(注销,免得占用进程),在登陆界面使用刚创建的hadoop2.7.1用户进行登陆。
选定另一台机器作为slave
以下的创建用户同理上述创建过程,只是在另外一个机器上创建一个新的同名用户(前面已经说了,为了不出错误,请设置和master机器上创建的hadoop2.7.1用户名字相同的用户,假设你还有机器可用于slave节点,你就做和这台机器相同的操作就好)
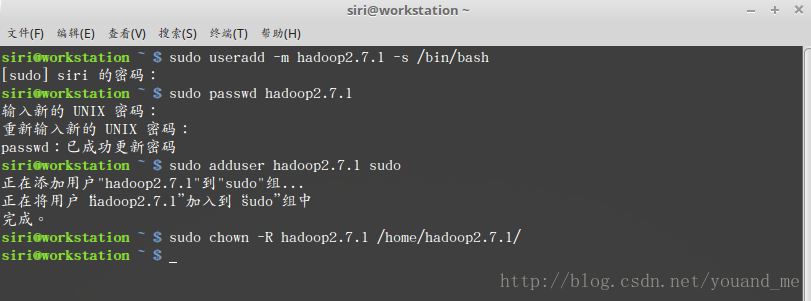
在这台slave机器上首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :sudo useradd -m hadoop2.7.1 -s /bin/bash这条命令创建了可以登陆的hadoop2.7.1用户,并使用/bin/bash作为shell。
接着使用如下命令设置密码,按提示输入两次密码:sudo passwd hadoop2.7.1可为hadoop_slave用户增加管理员权限,方便部署,避免一些对刚接触的人来说比较棘手的权限问题:
sudo adduser hadoop2.7.1 sudo sudo chown -R hadoop2.7.1 /home/hadoop2.7.1/创建过程如下图:
另外讲一个删除用户的命令(hadoop_master是我之前在这台机器上创建的用户,其中-r代表删除根目录,hadoop_master是我要删除的用户名,提示邮件池未找到不管,因为之前没有设置用户信息):
sudo userdel -r hadoop_master
最后注销当前用户(注销,免得占用进程),在登陆界面使用刚创建的hadoop_slave用户进行登陆。在master机器上的配置
如果没有安装vim的话先安装:
sudo apt-get install vim按 ctrl+alt+t 打开终端窗口,输入如下命令():
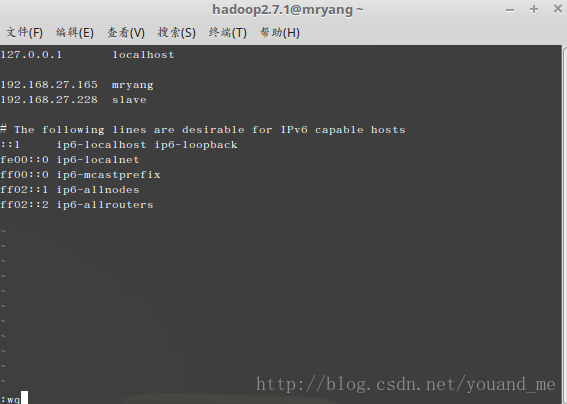
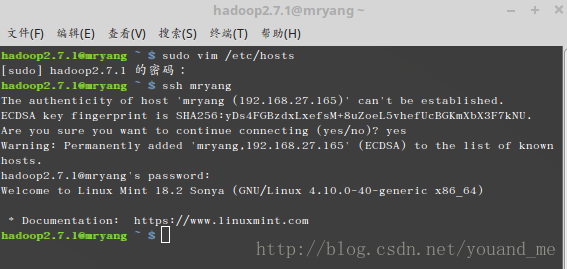
sudo vim /etc/hosts将IP和别名全部写入(不会用vim的百度一下,按i键开始编辑,插入下面两行后按esc键退出编辑,再输入:wq回车就保存了):
192.168.27.165 mryang 192.168.27.228 slave继续执行如下命令(第一次执行会产生.ssh目录,否则后面无法打开.ssh目录):
ssh mryang输入yes回车继续,输入本用户的密码继续,出现welcome to …代表连接成功。
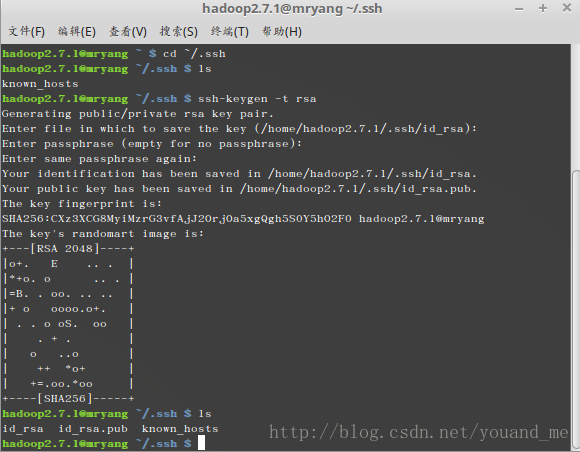
接着进入.ssh目录,生成公钥:
cd ~/.ssh ssh-keygen -t rsa连续回车(使用默认)产生公钥:
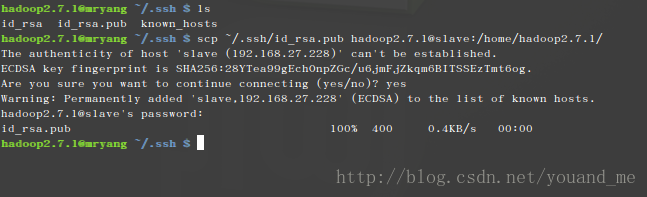
如果你想实现后续ssh无密登录mryang(本机的IP),执行如下第一条命令(不执行的话后面开启hadoop的时候会要求你输入密码,所以也执行了吧),第二条命令将生成的公钥传输给slave对应IP下的hadoop2.7.1用户的/home/hadoop2.7.1/目录下
注意:你的slave节点的hadoop2.7.1用户必须包含/home/hadoop2.7.1/这个目录,这个目录你可以更改,但是必须保证在hadoop2.7.1用户中有这个目录。cat ./id_rsa.pub >> ./authorized_keys scp ~/.ssh/id_rsa.pub hadoop2.7.1@slave:/home/hadoop2.7.1/输入yes回车,再输入hadoop_slave用户的密码回车,接下来就会看到id_rsa.pub文件传输成功:
你现在可以去slave节点的hadoop2.7.1用户的/home/hadoop2.7.1/目录看到这个文件了。
在slave节点上的配置
当你还有一个作为slave节点的时候配置可类似做配置。
如果没有安装vim的话先安装:sudo apt-get install vim按 ctrl+alt+t 打开终端窗口,输入如下命令():
sudo vim /etc/hosts将IP和别名全部写入(这个别名以后就可以代替其前面的IP了,不会用vim的百度一下,按i键开始编辑,插入下面两行后按esc键退出编辑,再输入:wq回车就保存了):
192.168.27.165 mryang 192.168.27.228 slave继续执行如下命令(第一次执行会产生.ssh目录,否则后面无法打开.ssh目录):
ssh slave输入yes回车继续
cd ~/.ssh ssh-keygen -t rsa连续回车产生公钥,以上和master节点的hadoop2.7.1用户的操作一样我就不上图了。
如果你想实现后续在slave节点上ssh无密登录无密登录slave(本机的IP别名,一般不用),则执行下述第一条命令,第二条命令将生成的公钥传输给mryang对应IP下的hadoop2.7.1用户的/home/hadoop2.7.1/目录下cat ./id_rsa.pub >> ./authorized_keys scp ~/.ssh/id_rsa.pub hadoop2.7.1@mryang:/home/hadoop2.7.1/一旦执行了第一条命令则再连接slave就不用输密码了,如下:
接下来将master节点的hadoop2.7.1用户传过来的公钥加入authorized_keys就可以实现用master节点的hadoop2.7.1用户ssh无密码登录slave节点(你可以理解为master机器向slave机器提交一个申请,申请以后连接slave不需要密码,这个申请书就是id_rsa.pub公钥,而slave将这个公钥接受(如下命令,在slave节点的hadoop2.7.1用户上把公钥加入authorized_keys)就行了):
cat /home/hadoop2.7.1/id_rsa.pub >> ~/.ssh/authorized_keys同样,如果想slave节点的hadoop2.7.1用户也能无密码登录master节点(一般也不用,只需要master节点的hadoop2.7.1用户能无密码访问所有的slave节点就ok),那么在master节点的hadoop2.7.1用户上也将slave节点的hadoop2.7.1用户传过去的公钥加入到authorized_keys中就行,不过得先传公钥过去再切换到master节点的hadoop2.7.1用户,执行:
cat /home/hadoop2.7.1/id_rsa.pub >> ~/.ssh/authorized_keys至此,你就可以在master节点的hadoop2.7.1用户上无密码登录slave节点了,切换到master节点的hadoop2.7.1用户,执行以下命令(slave其实就是一个IP的别名,hadoop2.7.1是slave节点创建的一个用户),结果如图:
ssh hadoop2.7.1@slave




hadoop配置
- 下载hadoop 2.7.1
安装hadoop2.7.1
切换到master机器的hadoop2.7.1用户:
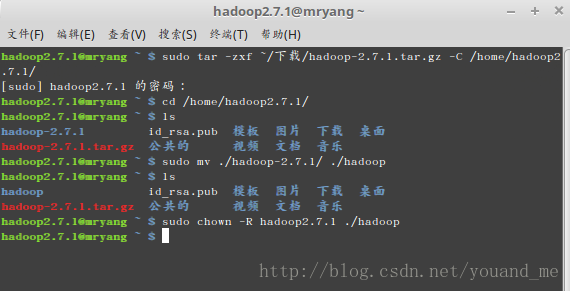
首先我将下载的hadoop-2.7.1.tar.gz文件解压并放在/home/hadoop2.7.1/目录下(不要放到其它目录,不然会导致权限问题,因为hadoop2.7.1用户只对/home/hadoop2.7.1/目录有操作权限),然后修改其名字为hadoop,最后修改这个文件的权限,命令如下:sudo tar -zxf ~/下载/hadoop-2.7.1.tar.gz -C /home/hadoop2.7.1/ cd /home/hadoop2.7.1/ sudo mv ./hadoop-2.7.1/ ./hadoop sudo chown -R hadoop2.7.1 ./hadoop集群/分布式模式需要修改 /home/hadoop2.7.1/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
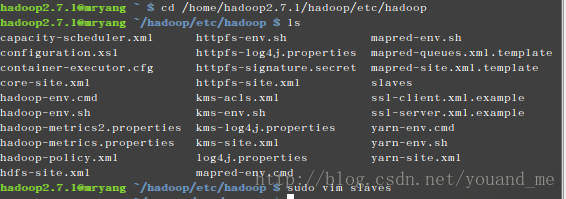
首先进入/home/hadoop2.7.1/hadoop/etc/hadoop,执行如下:cd /home/hadoop2.7.1/hadoop/etc/hadoop然后修改以下几个文件:
1.文件 slaves。
将作为 DataNode 的主机名写入该文件,每行一个。分布式配置可以保留 localhost,也可以删掉,让 mryang 节点仅作为 NameNode 使用。
本教程让 mryang 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加一行内容:slave。2.文件core-site.xml修改为下面,同样用“sudo vim core-site.xml”命令来修改,以下类似:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mryang:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop2.7.1/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>3.文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 slave 节点,所以 dfs.replication 的值还是设为 1:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>mryang:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop2.7.1/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop2.7.1/hadoop/tmp/dfs/data</value> </property> </configuration>4.文件 mapred-site.xml (可能需要先重命名重命名的命令是“sudo mv mapred-site.xml.template mapred-site.xml ”,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>mryang:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>mryang:19888</value> </property> </configuration>5.文件 yarn-site.xml:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>mryang</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>配置环境变量
首先切换到mater机器的hadoop2.7.1用户执行下述操作。
如果安装了Java jdk的话,使用以下命令查看jdk的安装路径:echo $JAVA_HOME注意:即使安装了jdk,由于这是新建的用户,所以JAVA_HOME就在这个用户中不存在,需要重新配置,由于我的jdk安装在/usr/lib/jvm/java-8-oracle目录(如果你没安装jdk则先去主用户安装)。
执行下述命令:sudo vim ~/.bashrcPATH是hadoop的安装路径,先写上去,后面再配置,不过怎么写就得怎么安装。
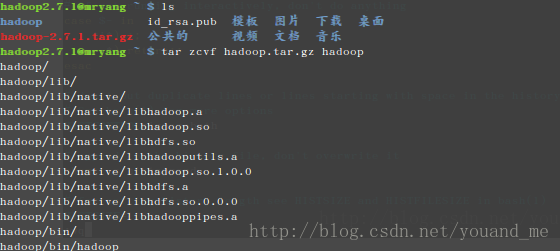
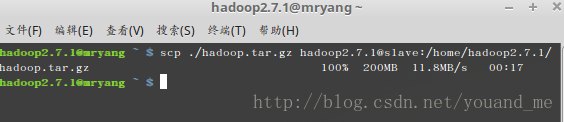
进入到/home/hadoop2.7.1/目录然后打包之前修改好的hadoop配置文件,然后传输到slave节点上,执行如下:cd /home/hadoop2.7.1/ tar zcvf hadoop.tar.gz hadoop scp ./hadoop.tar.gz hadoop2.7.1@slave:/home/hadoop2.7.1/压缩成功截图:
下图为传输成功图:
然后切换到slave机器的hadoop2.7.1用户执行下述操作。
进入到/home/hadoop2.7.1/目录然后解压master机器传输过来的压缩文件,然后修改~/.bashrc文件的环境变量:
cd /home/hadoop2.7.1/ tar zxvf hadoop.tar.gz hadoop
启动
先切换到master的hadoop2.7.1用户。
cd /home/hadoop2.7.1/hadoop/第一次启动得格式化(紧接上面执行):
./bin/hdfs namenode -format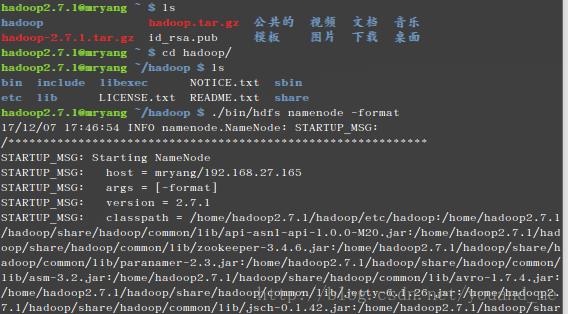
启动dfs
./sbin/start-dfs.sh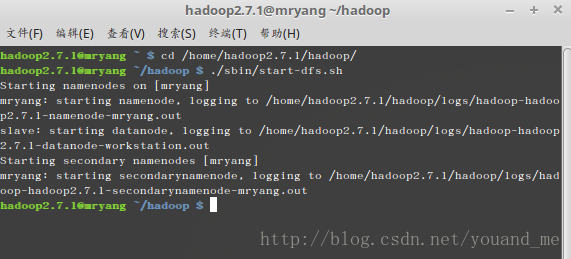
启动yarn
./sbin/start-yarn.sh
停止hadoop(注意目录):
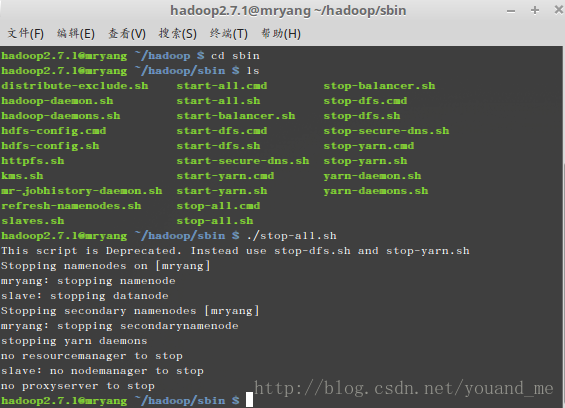
后面再开启hadoop:
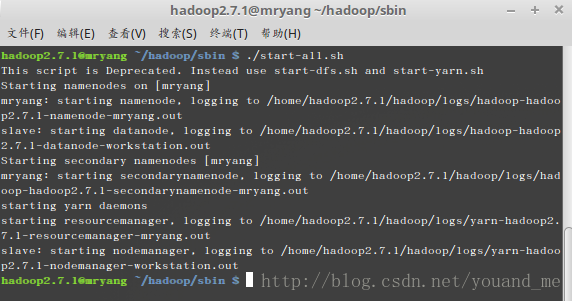
master机器的hadoop2.7.1用户下jps查看:
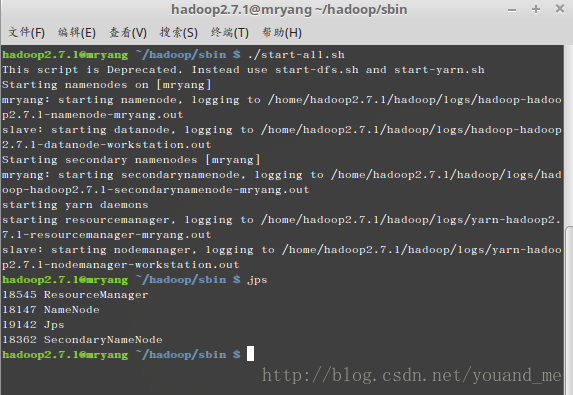
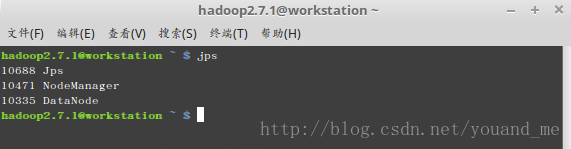
slave机器的hadoop2.7.1用户下jps查看(切换机器):
结语
以上就是hadoop集群的搭建的大部分内容了,总的注意那几个坑就是。