hadoop集群 安装 部署
软件安装等严格按照目录
Root用户
虚拟机环境准备
克隆三台虚拟机
修改主机名 /etc/sysconfig/network sync然后重启
主机名分别为:hadoop101;hadoop102;hadoop103;
修改克隆虚拟机的静态ip,分别为:
IP分别为:192.168.1.101;192.168.1.102;192.168.1.103
配置主机名和IP的映射关系(便于使用主机名访问虚拟机)
[root@ hadoop101桌面]$ vim /etc/hosts
添加如下内容
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
修改window7的主机映射文件(hosts文件)
(1)进入C:\Windows\System32\drivers\etc路径
(2)打开hosts文件并添加如下内容
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
关闭防火墙 service iptables stop;chkconfig iptables off
在各个机器上使用root用户在/opt目录下创建module、software文件夹
安装jdk
1. 卸载现有jdk
(1)查询是否安装java软件:
[root@hadoop101 opt]$ rpm -qa | grep java
(2)如果安装的版本低于1.7,卸载该jdk:
[root@hadoop101 opt]$ rpm -e 软件包
2. 用文件传输工具将jdk导入到opt目录下面的software文件夹下面
3. 在linux系统下的opt目录中查看软件包是否导入成功
[root@hadoop101 opt]$ cd software/
[root@hadoop101 software]$ ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
4. 解压jdk到/opt/module目录下
[root@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
5. 配置jdk环境变量
(1)先获取jdk路径:
[root@hadoop101 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
(2)打开/etc/profile文件:
[root@hadoop101 software]$ vi /etc/profile
在profile文件末尾添加jdk路径:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(3)保存后退出:
:wq
(4)让修改后的文件生效:
[root@hadoop101 jdk1.8.0_144]$ source /etc/profile
6. 测试jdk是否安装成功
[root@hadoop101 jdk1.8.0_144]$ java -version
java version "1.8.0_144"
重启(如果java -version可以用就不用重启)
[root@hadoop101 jdk1.8.0_144]$ reboot
安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
1.用文件传输工具工具将hadoop-2.7.2.tar.gz导入到opt目录下面的software文件夹下面
2.进入到Hadoop安装包路径下
[root@hadoop101 ~]$ cd /opt/software/
3.解压安装文件到/opt/module下面
[root@hadoop101 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
4.查看是否解压成功
[root@hadoop101 software]$ ls /opt/module/
hadoop-2.7.2
5. 将hadoop添加到环境变量
(1)获取hadoop安装路径:
[root@ hadoop101 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
(2)打开/etc/profile文件:
[root@ hadoop101 hadoop-2.7.2]$ vi /etc/profile
在profie文件末尾添加jdk路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
(3)保存后退出:
:wq
(4)让修改后的文件生效:
[root@ hadoop101 hadoop-2.7.2]$ source /etc/profile
6. 测试是否安装成功
[root @hadoop101 ~]$ hadoop version
Hadoop 2.7.2
7. 重启(如果hadoop命令不能用再重启)
[root@ hadoop101 hadoop-2.7.2]$ reboot
集群配置
1. 集群部署规划

2. 配置集群
(1)配置Hadoop所使用Java的环境变量:hadoop-env.sh
[root@hadoop101 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(1)核心配置文件:core-site.xml(hdfs的核心配置文件)
[root@hadoop101 hadoop]$ vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(2)hdfs配置文件 hdfs-site.xml
[root@hadoop101 hadoop]$ vim hdfs-site.xml
<!--副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode的地址--> 辅助namenode工作
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
(3)yarn配置文件yarn-env.sh
[root@hadoop101 hadoop]$ vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
yarn-site.xml
[root@hadoop101 hadoop]$ vim yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
(4)mapreduce配置文件mapred-env.sh,mapred-site.xml
[root@hadoop101 hadoop]$ vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
[root@hadoop101 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[root@hadoop101 hadoop]$ vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.配置集群中从节点信息
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[root@hadoop101 hadoop]$ vim slaves
hadoop101
hadoop102
hadoop103
4.分发文件
1. scp:secure copy 安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
安装scp命令,这个安装需要每个节点都要安装
yum install -y openssh-server openssh-clients
(2)实操
(a)将hadoop101中/opt/module目录下的软件拷贝到hadoop102上。
[root@hadoop101 /]$ scp -r /opt/module/* hadoop102:/opt/module
5.查看文件分发情况
[root@hadoop102 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode(格式化只进行一次!!!)
[root@hadoop101 hadoop-2.7.2]$ hadoop namenode -format
(2)在hadoop101上启动NameNode
[root@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
[root@hadoop101 hadoop-2.7.2]$ jps
3461 NameNode
(3)在hadoop101、hadoop102、hadoop103上分别启动DataNode
[root@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[root@hadoop101 hadoop-2.7.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode
[root@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[root@hadoop102 hadoop-2.7.2]$ jps
3190 DataNode
3279 Jps
[root@hadoop103 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[root@hadoop103 hadoop-2.7.2]$ jps
3237 Jps
3163 DataNode
SSH无密登录配置
1. 配置ssh
(1)基本语法
ssh 另一台电脑的ip地址
如果提示 command not found,需要安装ssh服务,命令:
yum install -y openssh-server openssh-clients
(2)ssh连接时出现Host key verification failed的解决方法
[root@hadoop101 opt] $ ssh hadoop102
The authenticity of host 'hadoop102(192.168.1.102)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
(3)解决方案如下:直接输入yes
2. 无密钥配置
生成公钥和私钥:
[root@hadoop101 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
[root@hadoop101 .ssh]$ ssh-copy-id hadoop101
[root@hadoop101 .ssh]$ ssh-copy-id hadoop102
[root@hadoop101 .ssh]$ ssh-copy-id hadoop103
3. .ssh文件夹下(~/.ssh)的文件功能解释
(1)known_hosts :记录ssh访问过计算机的公钥(public key)
(2)id_rsa :生成的私钥
(3)id_rsa.pub :生成的公钥
(4)authorized_keys :存放授权过得无密登录服务器公钥
集群启动/停止方式
1. 各个服务组件逐一启动/停止(集群某个进程挂掉使用这种方式重启 )
(1)分别启动/停止hdfs组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
(2)启动/停止yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
2. 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止hdfs(在namenode节点启动)
start-dfs.sh
stop-dfs.sh
(2)整体启动/停止yarn (在resourcemanager节点启动)
start-yarn.sh
stop-yarn.sh
集群测试
1. 启动集群
(1)如果集群是第一次启动,需要格式化NameNode,如果单点启动的时候已经格式化,就不需要再次进行格式化了!!!
[root@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)启动HDFS:
[root@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh
[root@hadoop101 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[root@hadoop101 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[root@hadoop101 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
启动成功之后查看hdfs的页面:http://192.168.1.101:50070/
(3)启动yarn
[root@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。如果不在一台机器上,则ResourceManger所在机器也需要配置到其他机器的ssh免密登录
通过jps命令查看进程:
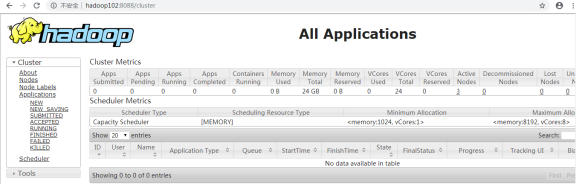
Yarn的web页面查看地址:http://hadoop102:8088/
(4)web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop103:50090/status.html
(b)查看SecondaryNameNode信息,如图所示。

图SecondaryNameNode的web端
2. 集群基本测试
(1)上传文件到集群
上传小文件 file system
[root@hadoop101 hadoop-2.7.2]$ hadoop fs -mkdir -p /user/root/input
[root@hadoop101 hadoop-2.7.2]$ hadoop fs -put wcinput/wc.input /user/root/input
上传大文件
[root@hadoop101 hadoop-2.7.2]$ hadoop fs -put /opt/software/hadoop-2.7.2.tar.gz /user/root/input
(2)上传文件后查看文件存放在什么位置
查看HDFS文件存储路径
[root@hadoop101 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.10.101-1495462844069/current/finalized/subdir0/subdir0
查看HDFS在磁盘存储文件内容
[root@hadoop101 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
root
root
(3)拼接
-rw-rw-r–. 1 hadoop hadoop 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r–. 1 hadoop hadoop 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r–. 1 hadoop hadoop 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r–. 1 hadoop hadoop 495635 5月 23 16:01 blk_1073741837_1013.meta
[root@hadoop101 subdir0]$ cat blk_1073741836>>tmp.file
[root@hadoop101 subdir0]$ cat blk_1073741837>>tmp.file
[root@hadoop101 subdir0]$ tar -zxvf tmp.file
(4)下载
[root@hadoop101 hadoop-2.7.2]$ hadoop fs -get
/user/root/input/hadoop-2.7.2.tar.gz ./
集群时间同步(配置即可)
时间同步的方式:在集群中找一台机器,作为时间服务器,集群中其他机器与这台机器定时的同步时间,比如,每隔十分钟,同步一次时间。
配置时间同步实操:
- 时间服务器配置(必须root用户)
(1)检查ntp是否安装,若没有安装则使用yum install -y ntp进行安装
[root@hadoop101 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
[root@hadoop101 桌面]# vim /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他的网络时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@hadoop101 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd
[root@hadoop101 桌面]# service ntpd status
ntpd 已停
[root@hadoop101 桌面]# service ntpd start
正在启动 ntpd: [确定]
(5)执行:
[root@hadoop101 桌面]# chkconfig ntpd on
2. 其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@hadoop102 hadoop-2.7.2]# crontab -e
编写脚本
*/10 * * * * /usr/sbin/ntpdate hadoop101
(2)修改任意机器时间
[root@hadoop102 root]$ date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@hadoop102 root]$ date
