一、PySpark 简介
1、Apache Spark 简介
Spark 是 Apache 软件基金会 顶级项目 , 是 开源的 分布式大数据处理框架 , 专门用于 大规模数据处理 , 是一款 适用于 大规模数据处理 的 统一分析引擎 ;
与 Hadoop 的 MapReduce 相比,
- Spark 保留了 MapReduce 的 可扩展、分布式、容错处理框架的优势 , 使用起来更加 高效 简洁 ;
- Spark 把 数据分析 中的 中间数据保存在内存中 , 减少了 频繁磁盘读写 导致的延迟 ;
- Spark 与 Hadoop 生态系统 的 对象存储 COS 、HDFS 、Apache HBase 等紧密集成 ;
借助 Spark 分布式计算框架 , 可以调度 由 数百乃至上千 服务器 组成的 服务器集群 , 计算 PB / EB 级别的海量大数据 ;
Spark 支持多种编程语言 , 包括Java、Python、R和Scala , 其中 Python 语言版本的对应模块就是 PySpark ;
Python 是 Spark 中使用最广泛的语言 ;
2、Spark 的 Python 语言版本 PySpark
Spark 的 Python 语言版本 是 PySpark , 这是一个第三方库 , 由 Spark 官方开发 , 是 Spark 为 Python 开发者提供的 API ;
PySpark 允许 Python 开发者 使用 Python 语言 编写Spark应用程序 , 利用 Spark 数据分析引擎 的 分布式计算能力 分析大数据 ;
PySpark 提供了丰富的的 数据处理 和 分析功能模块 :
- Spark Core : PySpark 核心模块 , 提供 Spark 基本功能 和 API ;
- Spark SQL : SQL 查询模块 , 支持多种数据源 , 如 : CSV、JSON、Parquet ;
- Spark Streaming : 实时流数据处理模块 , 可处理 Twitter、Flume等 实时数据流 ;
- Spark MLlib : 机器学习 算法 和 库 , 如 : 分类、回归、聚类 等 ;
- Spark GraphFrame : 图处理框架模块 ;
开发者 可以使用 上述模块 构建复杂的大数据应用程序 ;
3、PySpark 应用场景
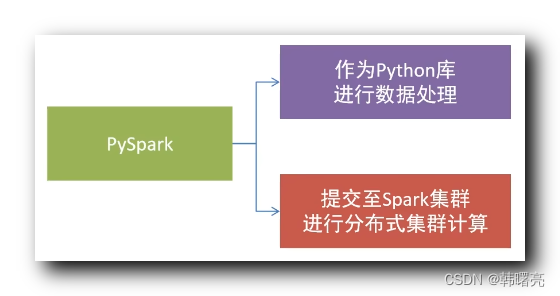
PySpark 既可以作为 Python 库进行数据处理 , 在自己的电脑上进行数据处理 ;
又可以向 Spark 集群提交任务 , 进行分布式集群计算 ;
4、Python 语言使用场景
Python 语言的使用场景很丰富 , 可以有如下应用场景 :
- 桌面 GUI 程序开发
- 嵌入式开发
- 测试开发 / 运维开发
- Web 后端开发
- 音视频开发
- 图像处理
- 游戏开发
- 办公自动化
- 科学研究
- 大数据分析
- 人工智能
大部分场景 都有专用的 语言 与 开发平台 , 不要贸然使用 Python 进行一般领域进行开发 , 如 : Web 领域 , Python 对其支持并不是很好 , 生态环境不全 ;
Python 语言主流应用于 大数据 与 人工智能 领域 , 在其它领域 , 基本不使用 Python 语言开发 ;