HTML文本是一种树形结构,所以bs4的内容遍历方法也是基于树形结构的,它共有下行遍历、上行遍历和平行遍历这三种遍历方法。
| 属性 | 说明 |
| .contents | 子节点的列表,将<tag>所有子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
我们仍以上一节中的网页为例用bs4对其进行处理
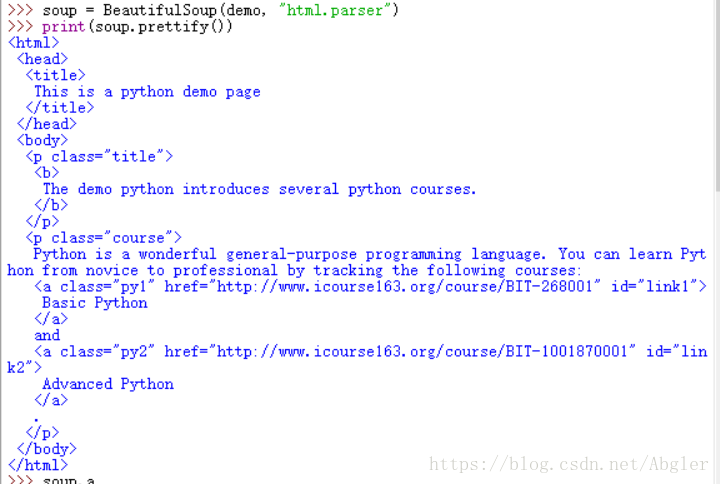
我们对其中的某些节点的子节点进行遍历

可以看到,子节点不仅包含各个标签,还包含了诸如'/n'这种类型的字符串,又因为".children"与".descendants"返回的是迭代类型,所以可以用"for"循环来对其进行遍历
for child in soup.body.children:
print(child)
for child in soup.body.children:
print(child)
| 属性 | s说明 |
| .parent | 节点的父标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
其中.parents不仅能遍历父节点,它能一直向上遍历到soup节点本身,而soup的先辈节点为None,所以在循环遍历时需要把soup这一特殊情况考虑进来,防止程序出现异常。
| 属性 | 说明 |
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
平行遍历只发生在同一个父节点之下的各节点间,而不会遍历到其他父节点之下,遍历时若返回空值则说明已该节点不存在上一个或下一个平行节点了。另外还需注意,标签树中的NavigableString类型也被作为了标签树的节点,所以再在对平行节点进行遍历时,可能会遍历到各标签之间的NavigableString,如:

而如何对NavigableString与标签之间进行区分,我们将在后续的实际应用中进行详解。