首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(2)基于bs4库的HTML内容遍历方法
其他
2020-01-22 19:01:12
阅读次数: 0
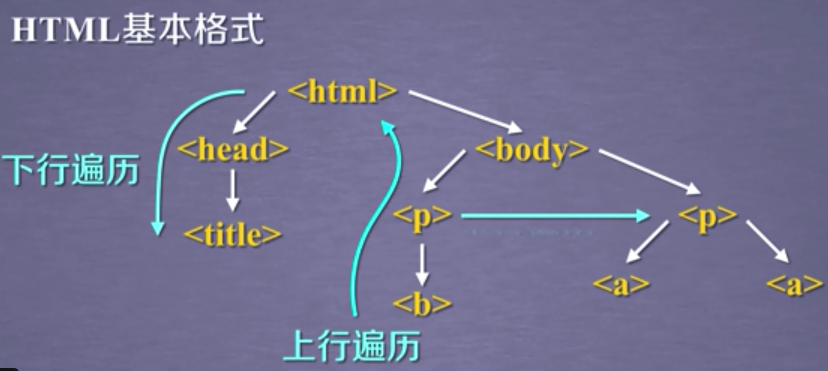
1. 基于bs4库的HTML内容遍历方法
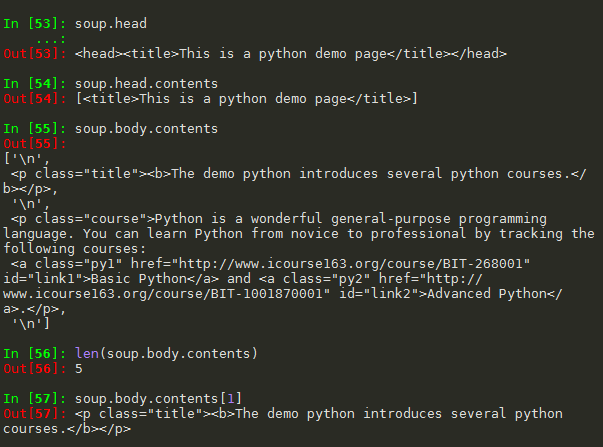
(1).contents 举例
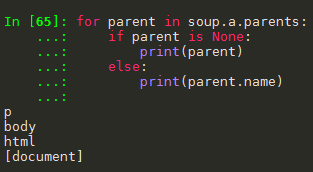
(2)结点的父亲标签
(4)标签树的上行遍历(parents)
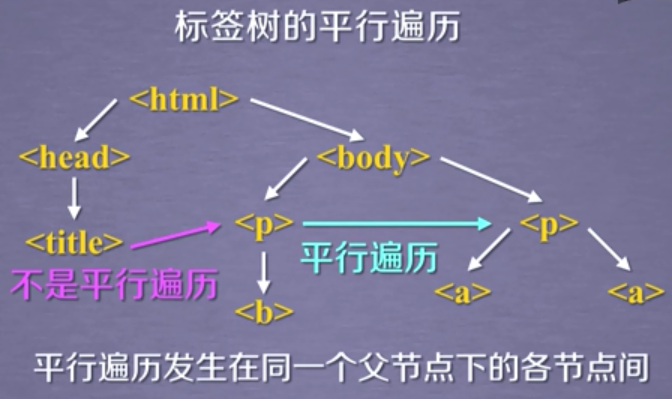
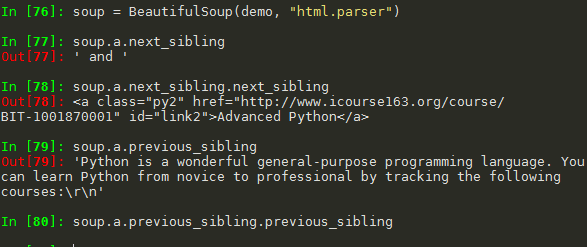
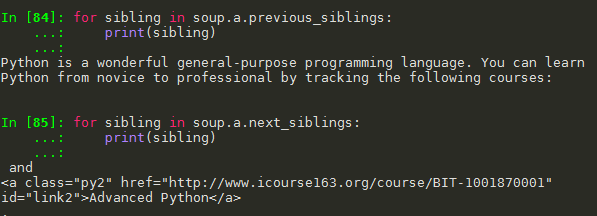
(5)标签树的平行遍历
注意:标签的儿子结点可能是 NavigableString
猜你喜欢
转载自
www.cnblogs.com/douzujun/p/12229160.html
python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(2)基于bs4库的HTML内容遍历方法
python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(3)基于bs4库的格式化和编码
爬虫:基于bs4库的html内容查找方法
python爬虫笔记(五)网络爬虫之提取—信息组织与提取方法(3)基于bs4库的HTML内容查找方法
Python爬虫之基于bs4库的HTML内容查找方法
Python爬虫六 基于bs4库的html内容查找方法
Python网络爬虫之提取&Beautiful Soup库入门学习笔记手札及代码实战
Python网络爬虫(四)——Beautiful Soup库
Python网络爬虫与信息提取(四)bs4的内容遍历方法及注意事项
Python爬虫学习(五)基于bs4库的HTML内容检索
beautiful soup 4.0(bs4)遍历文档树(2)
Python网络爬虫与信息提取笔记04-Beautiful Soup库入门
Python笔记:网络爬虫之XPath、Beautiful Soup、PyQuery的使用
Task 02 bs4 Beautiful Soup库入门(2.1)
Python 网络爬虫笔记5 -- Beautiful Soup库实战
Python 网络爬虫笔记3 -- Beautiful Soup库
Python爬虫之bs4库
初探Python网络爬虫:Beautiful Soup库
04 Python爬虫之Beautiful Soup库
Python爬虫之(八)数据提取-Beautiful Soup
基于bs4库的HTML内容遍历方法
网络爬虫:Beautiful Soup库&&信息组织与提取
爬虫提取规则之Beautiful Soup的使用
Python爬虫速成------bs4库
Python爬虫速成------bs4库
python爬虫8:bs4库
python爬虫之Beautiful Soup库,基本使用以及提取页面信息
爬虫日记-基于bs4库的HTML格式化和编码
bs4之Beautiful Soup
python网络爬虫学习笔记(九):Beautiful Soup的使用
今日推荐
TIOBE 5 月榜单:Fortran “复活”进入 Top 10
GCC 14.1 发布
面壁智能发布 Eurux-8x22B 开源大模型 —— 堪称「理科状元」
开源日报 | 谷歌扶持鸿蒙上位;开源Rabbit R1;Docker加持的安卓手机;微软的焦虑和野心;海尔电器把开放平台关了
中国码农的“35岁魔咒”
蘭雅 CorelDRAW 插件 2024.5.1 国际劳动节版,免费下载
Arc Browser for Windows 1.0 正式 GA
90后程序员开发视频搬运软件、不到一年获利超 700 万,结局很刑!
周排行
Java自定义时间格式
同步整形电路
在开发中最最最常用的字符串的属性大集合
Linux 查看端口占用并杀掉
Java基础四:ArrayList
多线程之死锁就是这么简单
mysql 基础命令集
awk 命令详解
Centos6.3编译安装nginx+php步骤
OCR (Optical Character Recognition,光学字符识别)
每日归档
更多
2024-05-08(42)
2024-05-07(14)
2024-05-06(40)
2024-05-05(0)
2024-05-04(7)
2024-05-03(19)
2024-05-02(0)
2024-05-01(4)
2024-04-30(1)
2024-04-29(40)