1、HTML基本格式(树形结构)
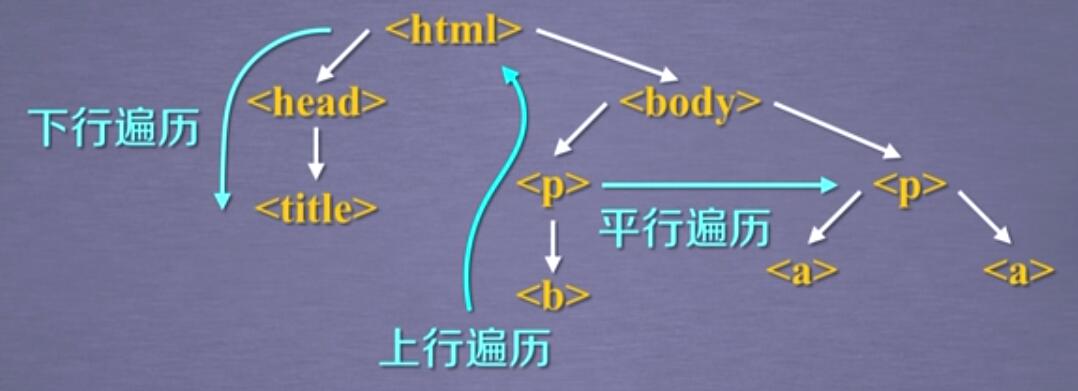
2、标签树的下行遍历

#使用contents对标签树进行遍历 import requests from bs4 import BeautifulSoup #BeautifulSoup是一个类 r = requests.get('http://python123.io/ws/demo.html') # print(r.text) demo = r.text #解析demo的解释器 soup = BeautifulSoup(demo,'html.parser') # print(soup.head) # print(soup.head.contents) # print(soup.body.contents) print(len(soup.body.contents)) print(soup.body.contents[1])
遍历儿子节点:
for child in soup.body,children: print(child)
遍历子孙节点
for child in soup.body.children: print(child)
3、标签树的上行遍历(soup的父节点是空的)

import requests from bs4 import BeautifulSoup #BeautifulSoup是一个类 r = requests.get('http://python123.io/ws/demo.html') # print(r.text) demo = r.text #解析demo的解释器 soup = BeautifulSoup(demo,'html.parser') # print(soup.title.parent) # print(soup.html.parent) #a标签所有先辈的名字进行打印 for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)
4、标签树的平行遍历

标签树的平行遍历条件:
是发生在同一个父节点下的各节点之间
import requests from bs4 import BeautifulSoup #BeautifulSoup是一个类 r = requests.get('http://python123.io/ws/demo.html') # print(r.text) demo = r.text #解析demo的解释器 soup = BeautifulSoup(demo,'html.parser') print(soup.a.next_sibling) print(soup.a.next_sibling.next_sibling) print(soup.a.previous_sibling) print(soup.a.parent)
遍历后续节点:
for sibling in soup.a.next_siblings: print(sibling)
遍历前续节点:
for sibling in soup.a.previous_siblings: print(sibling)