目录
1. 作者介绍
盛思宇,男,西安工程大学电子信息学院,2021级研究生
研究方向:基于无监督网络工业图像缺陷检测研究
电子邮件:[email protected]
吴燕子,女,西安工程大学电子信息学院,2021级研究生,张宏伟人工智能课题组
研究方向:模式识别与人工智能
电子邮件:[email protected]
2. 逻辑回归
2.1 逻辑回归
在回归模型中,处理的因变量都是数值型区间变量,建立的模型描述是因变量的期望与自变量之间的线性关系。比如常见的线性回归模型:
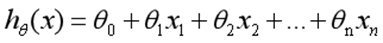
而在采用回归模型分析实际问题中,所研究的变量往往不全是区间变量而是顺序变量或属性变量,比如二项分布问题。通过分析年龄、性别、体质指数、平均血压、疾病指数等指标,判断一个人是否换糖尿病,Y=0表示未患病,Y=1表示患病,这里的响应变量是一个两点(0-1)分布变量,它就不能用h函数连续的值来预测因变量Y(只能取0或1)。
总之,线性回归模型通常是处理因变量是连续变量的问题,如果因变量是定性变量,线性回归模型就不再适用了,需采用逻辑回归模型解决。
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
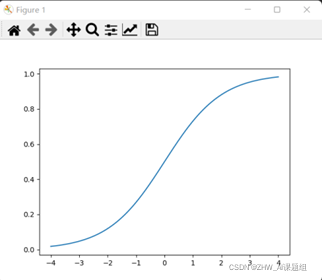
二分类问题的概率与自变量之间的关系图形往往是一个S型曲线,如上图所示,采用的Sigmoid函数实现。
这里我们将该函数定义如下:
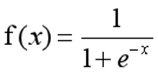
函数的定义域为全体实数,值域在[0,1]之间,x轴在0点对应的结果为0.5。当x取值足够大的时候,可以看成0或1两类问题,大于0.5可以认为是1类问题,反之是0类问题,而刚好是0.5,则可以划分至0类或1类。对于0-1型变量,y=1的概率分布公式定义如下:
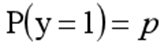 y=0的概率分布公式定义如下:
y=0的概率分布公式定义如下:
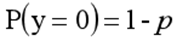
其离散型随机变量期望值公式如下:
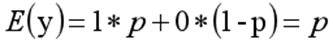
采用线性模型进行分析,其公式变换如下:
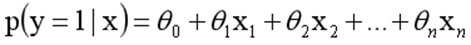 而实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit§与自变量之间存在线性相关的关系,逻辑回归模型定义如下:
而实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit§与自变量之间存在线性相关的关系,逻辑回归模型定义如下:
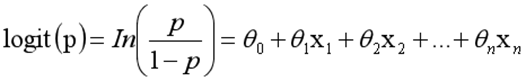
通过推导,概率p变换如下,这与Sigmoid函数相符,也体现了概率p与因变量之间的非线性关系。以0.5为界限,预测p大于0.5时,我们判断此时y更可能为1,否则y为0。
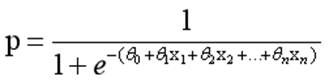
得到所需的Sigmoid函数后,接下来只需要和前面的线性回归一样,拟合出该式中n个参数θ即可。
Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归。对于多类分类问题,可以将其看做成二类分类问题:保留其中的一类,剩下的作为另一类。
2.2 逻辑回归算法
LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
导入模型:调用逻辑回归LogisticRegression()函数。
fit()训练:调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
predict()预测:利用训练得到的模型对数据集进行预测,返回预测结果。
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
1.正则化选择参数:penalty
LogisticRegression和LogisticRegressionCV默认就带了正则化项。penalty参数可选择的值为"l1"和"l2".分别对应L1的正则化和L2的正则化,默认是L2的正则化。
在调参时如果我们主要的目的只是为了解决过拟合,一般penalty选择L2正则化就够了。但是如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化。另外,如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。
2.优化算法选择参数:solver
solver参数决定了我们对逻辑回归损失函数的优化方法,有4种算法可以选择,分别是:
liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候,SAG是一种线性收敛算法,这个速度远比SGD快。关于SAG的理解,参考博文线性收敛的随机优化算法之 SAG、SVRG(随机梯度下降)
总结而言,liblinear支持L1和L2,只支持OvR做多分类,“lbfgs”, “sag” “newton-cg”只支持L2,支持OvR和MvM做多分类。
3.分类方式选择参数:multi_class
multi_class参数决定了我们分类方式的选择,有 ovr和multinomial两个值可以选择,默认是 ovr。
ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
从上面的描述可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。
如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg, lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
4.类型权重参数: class_weight
class_weight参数用于标示分类模型中各种类型的权重,可以不输入,即不考虑权重,或者说所有类型的权重一样。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者我们自己输入各个类型的权重,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。
如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。
5.样本权重参数: sample_weight
在样本不失衡的问题下由于样本本身的不平衡,导致样本不是总体样本的无偏估计,从而可能导致我们的模型预测能力下降。遇到这种情况,我们可以通过调节样本权重来尝试解决这个问题。调节样本权重的方法有两种,第一种是在class_weight使用balanced。第二种是在调用fit函数时,通过sample_weight来自己调节每个样本权重。
3. 实验过程
3.1 fetch_20newsgroups(20类新闻文本)数据集的简介
20newsgroups数据集18000多篇新闻文章,一共涉及到20种话题,所以称作20newsgroups text dataset,分为两部分:训练集和测试集,通常用来做文本分类,均匀分为20个不同主题的新闻组集合。20newsgroups数据集是被用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。一些新闻组的主题特别相似(e.g. comp.sys.ibm.pc.hardware/ comp.sys.mac.hardware),还有一些却完全不相关 (e.g misc.forsale /soc.religion.christian)。
3.2 实验代码
整个过程分为4个部分完成:数据采集、特征提取、模型训练、模型评估。
1.数据采集
from sklearn.datasets import fetch_20newsgroups
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
twenty_train = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, random_state=42)
data_home指的是数据集的地址,如果默认的话,所有的数据都会在’~/scikit_learn_data’文件夹下。
subset就是train,test,all三种可选,分别对应训练集、测试集和所有样本。
categories:是指类别,如果指定类别,就会只提取出目标类,如果是默认,则是提取所有类别出来。
shuffle:是否打乱样本顺序,如果是相互独立的话。
random_state:打乱顺序的随机种子
remove:是一个元组,用来去除一些停用词的,例如标题引用之类的。
download_if_missing: 如果数据缺失,是否去下载。
经测试知:
twenty_train.data是一个list类型,每一个元素是str类型,也就是一篇文章。
twenty_train.target则是它的标签。
2.特征提取
'''
这是开始提取特征,这里的特征是词频统计。
'''
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(twenty_train.data)
'''
这是开始提取特征,这里的特征是TFIDF特征。
'''
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
3.模型训练
'''
使用逻辑回归分类,并做出简单的预测
'''
from sklearn.linear_model import LogisticRegression # 逻辑回归
clf = LogisticRegression().fit(X_train_tfidf, twenty_train.target)
docs_new = ['God is love', 'OpenGL on the GPU is fast']
X_new_counts = count_vect.transform(docs_new)
X_new_tfidf = tfidf_transformer.transform(X_new_counts)
predicted = clf.predict(X_new_tfidf)
for doc, category in zip(docs_new, predicted):
print('%r => %s' % (doc, twenty_train.target_names[category]))
使用逻辑回归算法来进行训练,并对两个类别的语句进行预测测试得到结果

4.模型评估
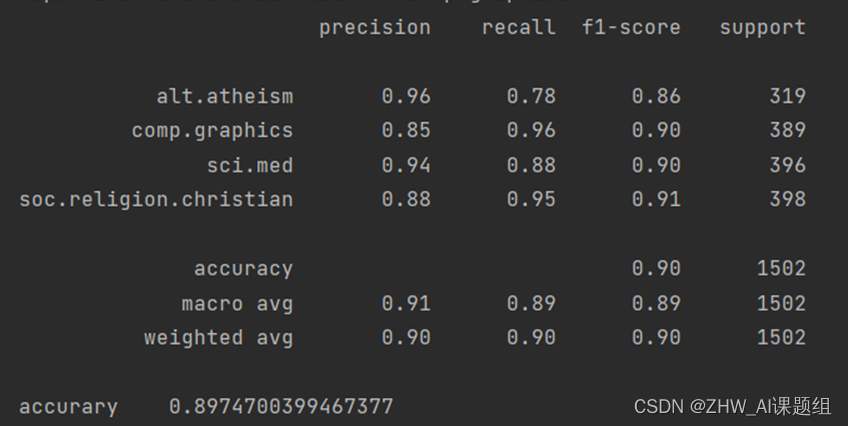
模型的评估一般使用PRF(精确率,召回率,F1值)和Acc值(准确值)来评估,因此我们使用metrics.classification_report方法可以轻松获取这些信息,同时可以使用这个方法可以比较两个target的差异:
from sklearn import metrics
import numpy as np
twenty_test = fetch_20newsgroups(subset='test', categories=categories, shuffle=True, random_state=42)
docs_test = twenty_test.data
X_test_counts = count_vect.transform(docs_test)
X_test_tfidf = tfidf_transformer.transform(X_test_counts)
predicted = clf.predict(X_test_tfidf)
print(metrics.classification_report(twenty_test.target, predicted,target_names=twenty_test.target_names))
print("accurary\t"+str(np.mean(predicted == twenty_test.target)))
3.3 运行结果
参考
1.[Python]20Newsgroup文本分类(TF-IDF向量化,十种sklearn分类器)
2.Dataset:fetch_20newsgroups(20类新闻文本)数据集的简介、安装、使用方法之详细攻略
3.逻辑回归(Logistic Regression)