InnoDB中记录与数据页结构及如何构成B+树
文章目录
一、概述
在以前在Buffer Pool的文章中说到了缓存页,那个其实就是数据页在内存中的叫法,今天我们将一同探究一下这个数据页到底是怎样的结构,以及它又是如何构成B+树的。
二、为什么需要BufferPool?
首先第一点 ,我们的电脑在将数据从磁盘加载到内存中的时候是有一个最小Size,可以理解为最小单位,因为如果每次因为几字节的数据就IO一次,是很浪费的。也就是说,假如你现在要加载两条记录到内存中来,可能这两条记录就几十字节,但是因为有一个最小单位的限制——16k,所以你这次可能还加载了很多这两条记录周围的其他数据到内存中来,这也有点符合空间局部性原理。InnoDB中数据页的大小是固定16k,正好也符合这个最小单位。
第二点就是为了方便数据的管理,你可以把一条数据想象成一个人,数据库就想象成学习,如果全部个体化的去管理肯定很难,但是如果把这些人进行“分班”,也就是说让很多条数据一起组成一个数据页,再分别去管理这些数据页就回方便很多了,减少了管理成本。
三、Buffer Pool中的记录是什么样的结构?
1、底层结构
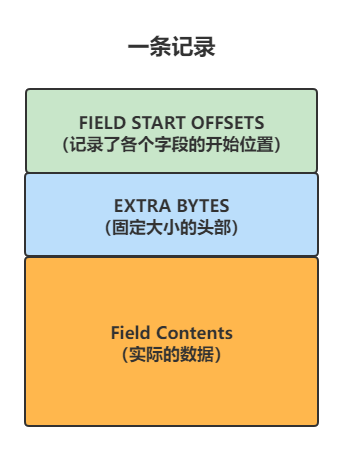
2、各个部分的作用
FIELD START OFFSETS
中文翻译过来就是字段起始位置的偏移量,没错,这个字段就是记录了一条记录中每一个字段开始的位置。为什么需要记录这个呢?记得字段的类型中的varchar这种可变类型吗?因为大小不是固定的,所以才需要记录开始位置在哪、偏移量是多少这信息,这样才能读取到正确的数据
(注:偏移量是以Fiedl Contents的第一个字节为起点进行计算的)
举个简单的例子来理解一下这个:假如现在有三个列,长度分别为1,2,4。那么他们的偏移量分别就是1,3(1+2),7(1+2+4)。因为这个值是颠倒过来存储的,所以最终就是:07,03,01
EXTRA BYTES
这个大小是固定的,为48bit,里面记录了记录的是字段一些描述信息,下面进行一些举例:
1、 deleted_flag (是否被删除)
2、min_rec_flag(是否是最小记录)
3、n_fields(字段个数)
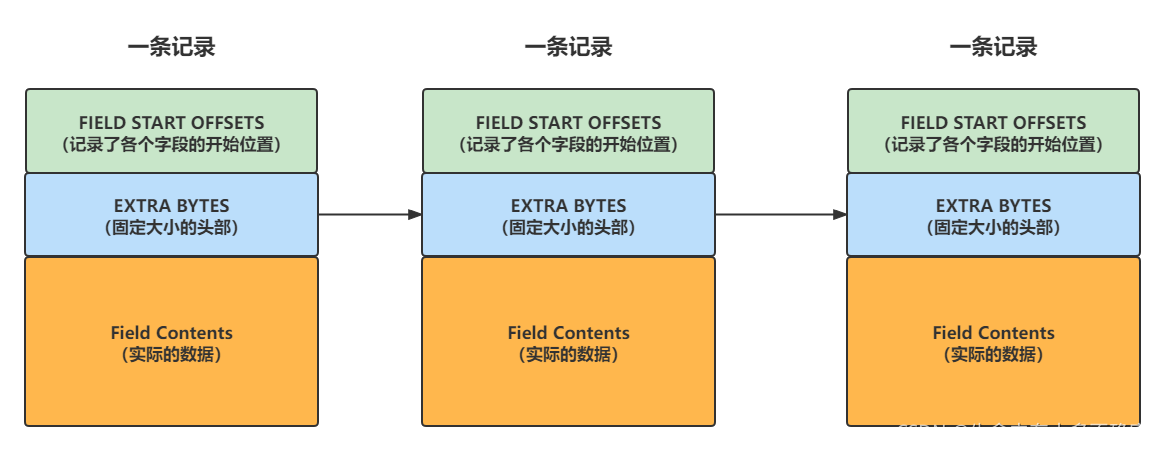
4、next 16 bits(指向下一条记录的指针,记录之间构成单向链表)
注意:正是因为这个“next 16 bits”这个信息,使得数据页中的记录连成了一个单向链表的结构
FIELD CONTENTS
这个部分就比较简单了,就是按顺序存储的各个字段的数据。因为是通过偏移量来读取的,所以字段之间没有标记,末尾也没有标记或者填充符。
这里需要留意的是,对于每一条记记录,系统都字段增加了三条字段,也就是所谓的”隐藏字段“,他们分别是:row ID,transaction ID,rollback pointer
这几个字段在说MVCC机制那篇文章中有介绍过
注意:如果某个字段的值为NULL,那么在FIELD CONTENTS中是不占空间的
四、Buffer Pool中的数据页是什么样的结构?
上面介绍了一条记录的结构,接下来我们来说一下这个数据页的结构是什么样的。在此之前需要知道的是,每个数据页的大小是固定16k,所有的记录都存储在数据页中。
1、底层结构
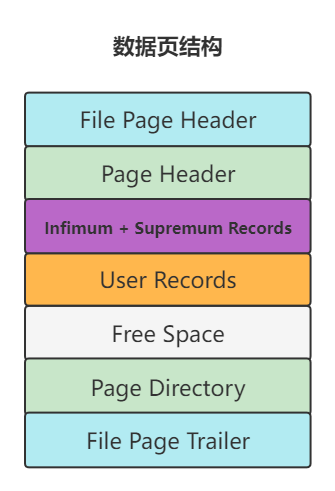
2、各部分的作用
File Page Header
这一部分所记录的内容是整个数据页与外部的一些信息,举例几个比较重要的信息:
1、FIL_PAGE_SPACE(记录所在的表空间,就是标记这个数据页是属于哪个表的)
2、FIL_PAGE_PREV(指向上一个数据页的指针,用于组成 双向链表)
3、FIL_PAGE_NEXT(指向下一个数据页的指针,用于组成 双向链表)
4、FIL_PAGE_TYPE(数据页类型,可以是: FIL_PAGE_INDEX, FIL_PAGE_UNDO_LOG, FIL_PAGE_INODE, FIL_PAGE_IBUF_FREE_LIST,至于为什么要分这些类型,可以复习一下BufferPool的文章)
通过这一部分中的两个指针,就可以实现所谓的B+树,长下面这个样子:
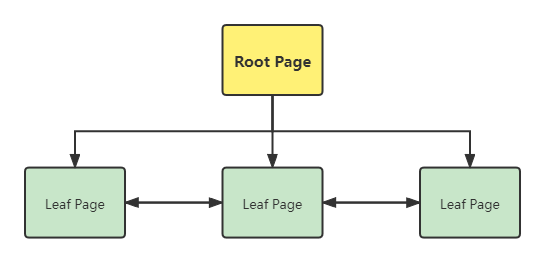
在经典的B树当中,只有Root Page才能指向Leaf Page,但是在B+树中,Leaf Page也可以指向 Leaf Page,这意味着,在查数据的时候不用每次都经过Root Page,这允许我们直接在Leaf Page去遍历查找,这可能就是为什么称作B+树的原因吧
Page Header
上面介绍的File Page Header是记录数据页与外界相关的信息,这里的Page Header则记录的是数据页内部的一些重要信息,这里举几个例子:
1、PAGE_N_DIR_SLOTS(Page Directory 部分中的目录槽数,初始值为2,后面会说到用处)
2、PAGE_HEAP_TOP(指向堆中第一条记录的指针)
3、PAGE_LAST_INSERT(指向堆中最后一条记录的指针)
4、PAGE_N_RECS(记录数)
5、PAGE_FREE(指向已释放[被删除或迁移]的记录的指针,构成一个单向链表)
Infimum 和 Supremum 记录
这两个词是数学中的术语,下确界和上确界,作用是用于确定边界。Infimum (下确界)小于最小的键的值,Supremum 大于最大的键的值。
有了这两条记录,保证了在利用索引进行查找的时候不会发生越界的行为,因此Infimum 和 Supremum 记录是索引页开销的一部分
除此之外,infimum 记录可以是记录锁的虚拟目标
User Records
这两部分顾名思义,也就是存放着用户插入的所有记录
用户浏览记录有两种方式,取决于这些记录是有序的还是无序的
无序的列表通常被称为“堆”,新插入的数据会被插入到Free Space顶部或者插入到已经被删除的记录所在的位置
对于有序的列表,根据B树的定义,记录必可以须按照键的顺序进行访问,因此,每条记录的next指针都会指向按照键的顺序排列的下一条记录。通俗的说,记录会根据键的顺序,通过next指针组成一个单向链表
Free Space
这个不需要多解释,从名字就可以看出来,就是空闲空间
Page Directory
这个也被称为页目录,目录的目的就是为了便于快速查找,而且我们知道的是,目录肯定不是精确查找,只能缩小我们查找的范围。
在这一部分在,由数量不固定的指向记录的指针组成,这些指针也被称为槽(slot),他们不会指向每一条记录,在完整的数据页中,每6条记录对应一个槽,可以理解为每相隔6个记录就会有一个记录被槽指向着。值得一提的是,槽记录的是逻辑顺序,并不是插入的顺序,比如你依次插入1,7,5,6。那么槽的顺序回事1,5,6,7。因为槽是按照逻辑顺序排列的并且大小也是固定的,因此,可以很容易的在槽上进行二分查找。由于只能找出大致的位置,因此可能还需要利用到记录的next指针才能找到正确的数据
File Page Trailer
这是数据页的最后一部分,之所以会有这个部分,是因为架构师在设计的时候担心完整性的问题。虽然不太可能出现写数据写到一半就崩溃的情况,因为有undo log做回滚。但是不怕一万就怕万一,所以就在这一部分设计了一个校验和的东西,想必学过网络协议,或者一些加密策略的应该对这个都不陌生,作用和那些有点类似。这个值必须与数据页最开始的值相同。
五、小结
学完了上面的内容之后我们现在再回过头来看一下数据页的结构就会清晰很多
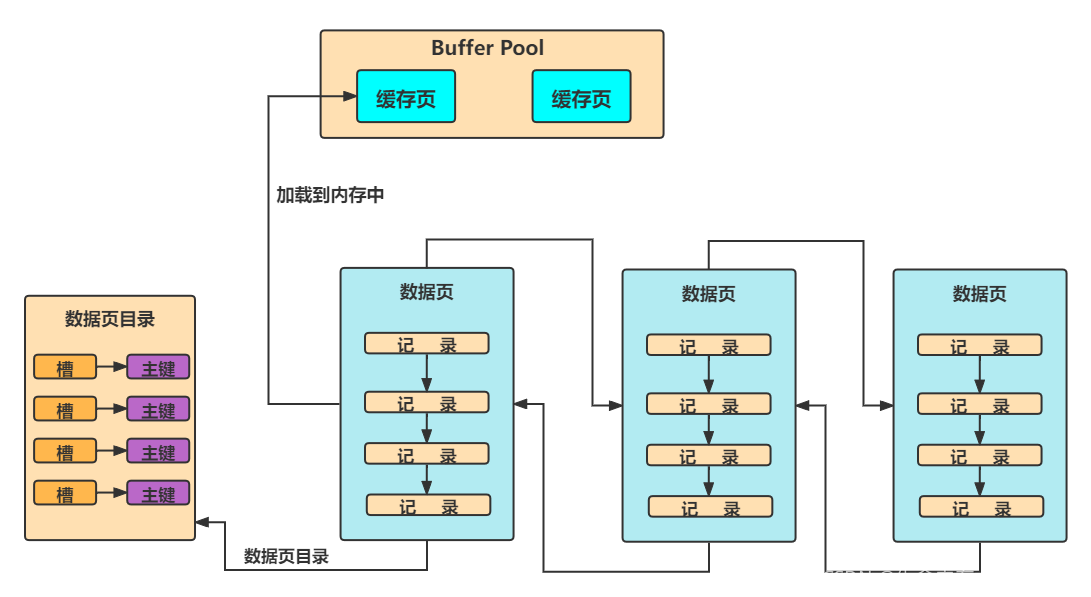
结合本文所讲的内容,可以知道数据页之间通过两个指针来构成双向链表以及B+树的叶子节点,而记录之间是通过next指针构成的一个单向链表。并且,每个数据页都有一个数据页目录,可以进行二分查找提高查找效率。
以上就是本篇的全部内容了,如果对某些地方有疑惑或者本文有什么问题欢迎指出。