(阅读需要对InnoDB索引页的结构和原理有基本了解,图片来源《MySQL是怎样运行的》)
InnoDB的主键B+树索引结构
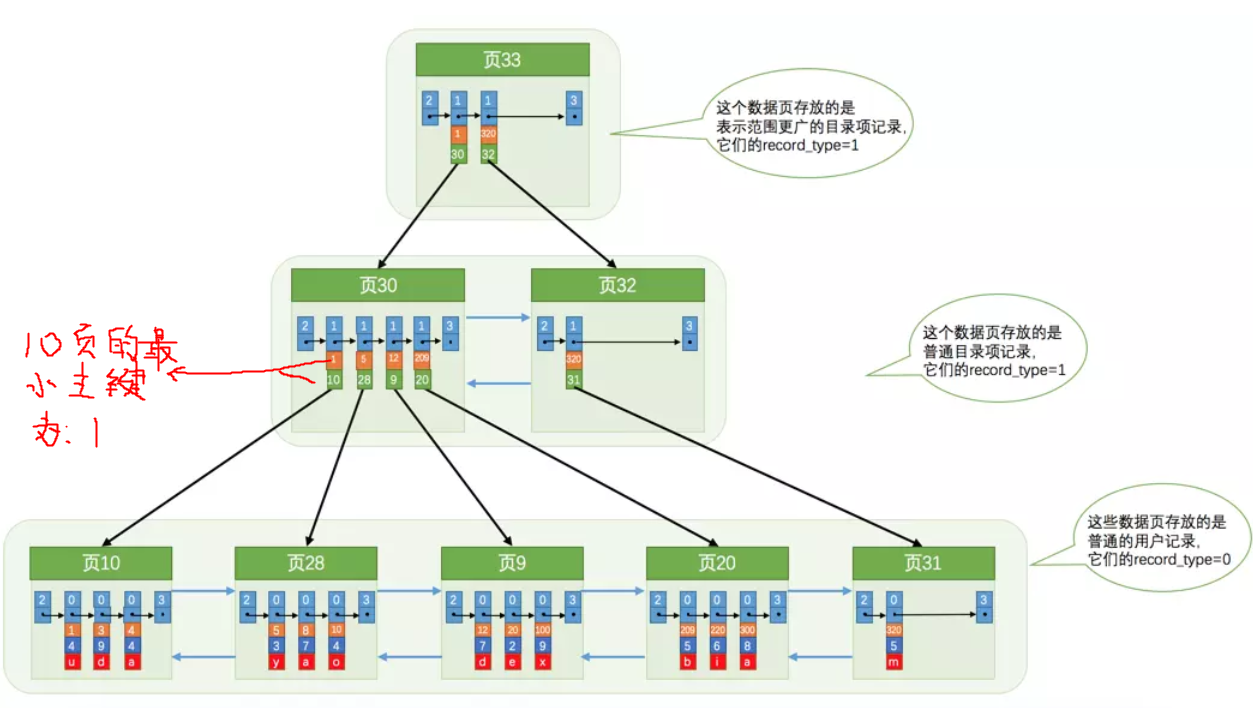
简单解释
(1)可以看到,InnoDB的B+树索引的结点就是InnoDB的数据页,这些结点通过File Header中的上一页、下一页左右相连成为一个双向链表;
(2)B+树只有叶子结点才存放数据,非叶子结点的记录头的record_type字段都置为1,叶子节点的记录的record_type字段则是0(除了系统插入的最大记录、最小记录);
(3)非叶子结点的只有两个字段有效:页号+该页号的页内记录的最小主键id(注意图中红字部分)。这样根据要查的目标记录的id就可以找到它属于拿个页了,然后在页内根据要查的记录主键二分找到最
相近的槽号,通过槽号到记录组后就个位数的记录了,直接遍历即可。
(4)二级索引或叫辅助索引也是类似的结构,只是把按照主键寻找改成按照索引字段+主键寻找结点而已(加主键不仅是为了回访主键索引,也是为了保证非叶子结点中记录的唯一性,因为索引字段可能重复)。
二级索引的叶子结点不记录所有数据,只有索引字段和主键,确定查找目标后需要拿主键回访主键索引。
(5)为c1、c2建立联合索引,也就是二级索引。优先按照建立索引时的左边字段进行排序,即c1。当c1字段相同时,在这些c1相同的连续一串结点里再根据c2字段进行索引。这也是左前缀原则的原理。
B树和B+树的不同点及思考
(1)我们知道从磁盘搬运数据到内存一般都是几KB的搬,避免频繁磁盘IO。所以InnoDB选择一个页作为一个结点,一次性运一个结点进内存,然后在内存中二分查找、遍历找到对应记录。B树的每个结点里的每条
记录都是带有完整的一行数据的,这就导致了一个结点中可存储的记录条数变少了,就意味着一个结点开的叉变少了很多,就意味着整个索引树的高度变大了,这显然是不好的。基于此,B+树让全部数据存到
叶子结点中,其他结点不存放数据,每个非叶子结点的分叉大大增多,代价就是每次查找都必须走到叶子结点。4层B+树已经可以存很多很多记录了,5到6层已经是极限了。
(2)B+树的所以数据都存到叶子结点,还有双向的指针将这些结点组成双向链表,非常适合范围查找。