简 介: 对于若干设备所使用时间(Utilization Time)分布进行汇总和统计分析,大体看到它分布接近于指数分布。 根据网络上对比几种分布波形可以看到,对于满足指数分布的概率统计利用Gaussian去逼近,误差很大。对于上面分布结果如果进行解释,是否还有其它分解方式,有待后面进一步探讨。
关键词: 使用时间,指数分布,统计
§01 建模数据
1.1 背景介绍
来自于同事(JYH)给出的设备使用数据,为了能够为将来对设备利用情况做评价,希望设备使用时间分布进行建模,获得设备利用时间理想分布,进而建立设备利用效率准确的评价标准。
由于数据存在一下问题:
- 数据量相对比较少。时间上只有五年数据;设备个数约有3000台;
- 没有标签。也就是建模和分类标准不明;
- 设备数值是由人工填写,所以本身具有很强的不确定性;
因此下面的分析仅仅初步探讨,判断是否该数据中可能存在的模式,确定是否可以进一步处理。
1.2 原始数据说明
1.2.1 数据载体
存储的原始数据为一个EXCEL表格。包含有 2017- 2021五年之间年的设备使用情况。 EXCEL每条记录包括有六个记录:填报院系、使用单位、仪器编号、分类号,仪器名称,有效机时。

▲ 图1.2.1 数据EXCEL表格
1.2.2 数据原有的预分析
原来数据中已经有了初步的统计信息。对于使用时间进行的直方图的统计。下面给出了五年所使用的数据的直方图分布。
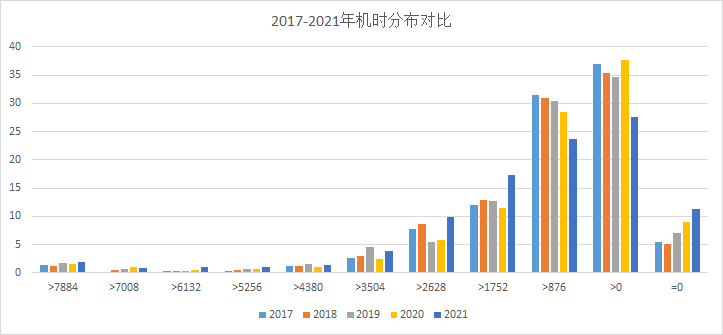
▲ 图1.2.2 数据的统计信息
下面表格给出了直方图的数据。
| 机时分段 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|
| >7884 | 24 | 22 | 40 | 40 | 57 |
| >7008 | 4 | 9 | 14 | 27 | 25 |
| >6132 | 7 | 8 | 9 | 14 | 32 |
| >5256 | 6 | 11 | 15 | 16 | 29 |
| >4380 | 20 | 23 | 34 | 29 | 44 |
| >3504 | 46 | 60 | 100 | 65 | 118 |
| >2628 | 134 | 170 | 122 | 154 | 296 |
| >1752 | 208 | 255 | 281 | 304 | 521 |
| >876 | 546 | 610 | 668 | 751 | 712 |
| >0 | 641 | 695 | 763 | 994 | 828 |
| =0 | 95 | 102 | 155 | 237 | 338 |
图中可以大体看到:
- 五年中的数据分布在中天梯上大体相似;
- 但是在细节部分,还是存在着差异。这种差异也许来自于数据内部所存在的固有噪声,也可能是设备所使用需求发生了变化。比如受到“新冠疫情”的影响。
1.3 研究方案
下面仅仅对于所有设备有效使用时间统计分布进行建模。首先建立使用机时建立它的直方图统计数据;然后利用高斯曲线分布来对该直方图进行逼近,看是否可以获得内部独立存在的若干高斯分布。
下面的分析出于以下假设:
- 忽略设备在五年中的使用差异,因此为了提高统计的数据量,因此把五年的数据合成一起,提高统计的数据量;
- 只使用高斯分布对数据进行逼近,其它的分布现在还没有确切的理由和模型来佐证。
§02 数据建模
2.1 数据预处理
2.1.1 EXCEL到TEXT文件
为了方便Python读取数据,先将所有的数据存储成CSV格式。可以参考在 快速检索并引用你在CSDN上所有的博文笔记 中对于CSV读取的Python过程。
由于CSV文件中,无法保存多个表格单,所以把五年的数据分别存储在 EUS2017.CSV 等数据文件中。后来测试,发现直接存储在**.TXT**文件更加的方便。下面是存储的TXT文件。
D:\Temp\EUS\UES2021.txt
D:\Temp\EUS\EUS2017.txt
D:\Temp\EUS\EUS2018.txt
D:\Temp\EUS\EUS2019.txt
D:\Temp\EUS\EUS2020.txt
2.1.2 数据合并
利用Python吧上面所有的数据中的时间提取出来,存储在 alltime.npz 数据包中。
(1)处理代码
from headm import *
filedir = r'D:\Temp\EUS'
filedim = os.listdir(filedir)
printf(filedim)
alltime = []
for f in filedim:
fname = os.path.join(filedir, f)
printf(fname)
with open(fname, 'r', encoding='gbk') as f:
for id, l in enumerate(f.readlines()):
l = l.strip('\n')
times = l[-1]
if times.isdigit():
alltime.append(int(times))
tspsave('alltime', alltime=alltime)
printf(len(alltime))
printf(mean(alltime), std(alltime))
printf('\a')
(2)数据统计信息
每个文件对应的有效数据:
- D:\Temp\EUS\EUS2017.txt;有效数据:1731
- D:\Temp\EUS\EUS2018.txt;有效数据:1965
- D:\Temp\EUS\EUS2019.txt;有效数据:2201
- D:\Temp\EUS\EUS2020.txt;有效数据:2631
- D:\Temp\EUS\UES2021.txt;有效数据:3003
-
数据合并后的统计:
-
数据量:11496
平均值:1489.23
STD:1574.31
2.1.3 数据直方图
下面分别给出了 BIN个数为100, 50, 25 的直方图统计。

▲ 图2.1.1 直方图:100

▲ 图2.1.2 直方图:50

▲ 图2.1.3 直方图:25
from headm import *
alltime = tspload('alltime', 'alltime')
plt.hist(alltime, 25)
plt.xlabel("Time(Hour)")
plt.ylabel("Statistic")
plt.grid(True)
plt.tight_layout()
plt.show()
2.1.4 指数分布
根据前面的分布,可以看到设备使用机时与 Exponential distribution 接近。
(1)指数分布
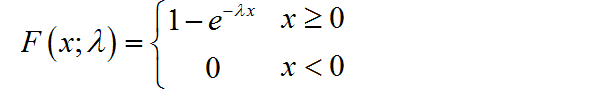
指数分布的数理统计: E [ X ] = 1 λ , V a r [ X ] = 1 λ 2 E\left[ X \right] = {1 \over \lambda },\,\,\,Var\left[ X \right] = {1 \over {\lambda ^2 }} E[X]=λ1,Var[X]=λ21
(2)指数分布逼近
使用 bins=50 的直方图估计指数分布参数。
f B I N ( x ) = a ⋅ e − b ⋅ x f_{BIN} \left( x \right) = a \cdot e^{ - b \cdot x} fBIN(x)=a⋅e−b⋅x
可以获得最小二乘逼近: f B I N ( x ) = 1.541 × e − 0.000659 x f_{BIN} \left( x \right) = 1.541 \times e^{ - 0.000659x} fBIN(x)=1.541×e−0.000659x
下图给出了上述逼近的曲线与实际直方图之间的拟合关系。
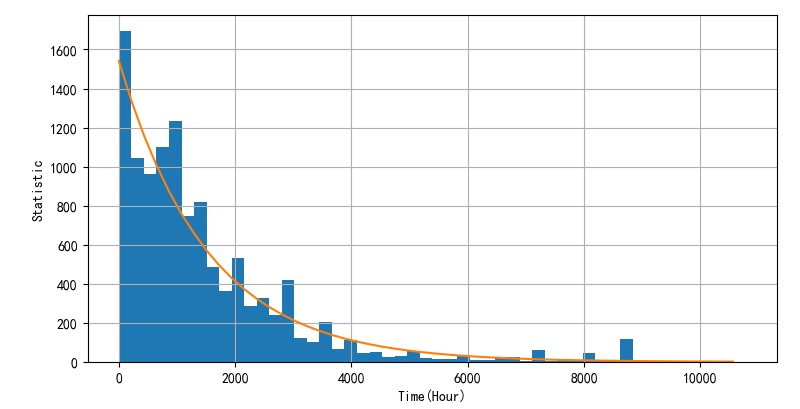
▲ 分布参数
根据上述参数,可以知道 λ = b = 6.5867 × 1 0 − 4 \lambda = b = 6.5867 \times 10^{ - 4} λ=b=6.5867×10−4 ,对应的平均值为: m e a n = 1 λ = 1518 mean = {1 \over \lambda } = 1518 mean=λ1=1518 。这与前面计算对应的平均值接近。
from headm import *
from scipy.optimize import curve_fit
alltime = tspload('alltime', 'alltime')
n,bins, patches = plt.hist(alltime, 50)
printf(n, bins, patches)
def linefun(x, a, b):
return a*exp(-b*x)
param = (1000, 1/2000)
param, conv = curve_fit(linefun, bins[:len(n)], n, p0=param)
printf(param)
fitn = linefun(bins[:len(n)], *param)
plt.plot(bins[:len(n)], fitn)
plt.xlabel("Time(Hour)")
plt.ylabel("Statistic")
plt.grid(True)
plt.tight_layout()
plt.show()
2.2 指数分布
根据 Exponential and normal distributions 对于指数分布描述,它适合对 Poisson process 中事件时间间隔进行描述,也可以表述成事件到达时间的分布。
现在直接把设备的使用时间与符合Poison分布的随机事件时间间隔联系起来,我还没有特别想清楚。
下面是网络上对于给定的攻击数据,分别给利用 Cauchy , Log-noirmal Chi, Chi-Square对于分布的进行近似,可以看到使用指数分别进行逼近精度比较高。 但使用 Normal-Gaussian, Log-Normal进行逼近,误差比较大。
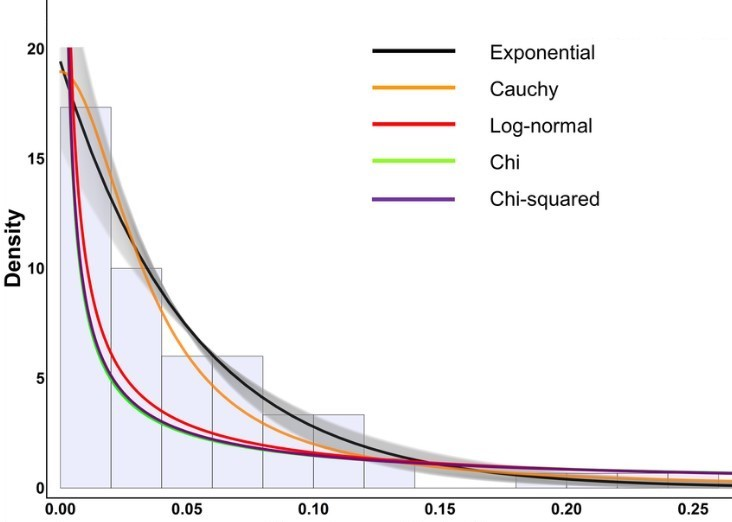
▲ 图2.2.1 类似的几种随机分布
由此可以看出,指数分布利用高斯分布去逼近,都会带来很大的误差。
※ 总 结 ※
对于若干设备所使用时间(Utilization Time)分布进行汇总和统计分析,大体看到它分布接近于指数分布。 根据网络上对比几种分布波形可以看到,对于满足指数分布的概率统计利用Gaussian去逼近,误差很大。对于上面分布结果如果进行解释,是否还有其它分解方式,有待后面进一步探讨。
■ 相关文献链接:
● 相关图表链接: