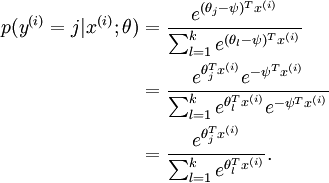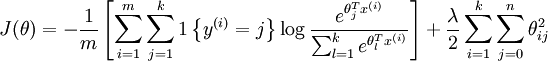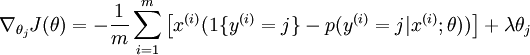在机器学习领域,很多模型都是属于广义线性模型(Generalized Linear Model, GLM),如线性回归,逻辑回归,Softmax回归 等。
广义线性模型有3个基本假设:
(1) 样本观测值
y
i
y_i
y i 参数
η
\eta
η 。即GLM是基于指数分布族的,所以我们先来看一下指数分布族的一般形式:
p
(
y
;
η
)
=
b
(
y
)
e
x
p
(
η
T
T
(
y
)
−
a
(
η
)
)
p(y;\eta)=b(y)exp(\eta^TT(y)-a(\eta))
p ( y ; η ) = b ( y ) e x p ( η T T ( y ) − a ( η ) )
其中,
η
\eta
η
η
\eta
η
η
\eta
η
T
(
y
)
T(y)
T ( y )
T
(
y
)
=
y
T(y)=y
T ( y ) = y
a
(
η
)
a(\eta)
a ( η )
T
,
a
,
b
T,a,b
T , a , b
η
\eta
η
进一步解释下什么是充分统计量:
T
(
y
)
T(y)
T ( y )
p
p
p
θ
\theta
θ
T
(
y
)
T(y)
T ( y )
θ
\theta
θ
对于假设1,换句话说:给定
x
,
θ
x,\theta
x , θ
y
y
y
η
\eta
η
(2) 分布模型参数
η
\eta
η
x
x
x
η
=
θ
T
x
\eta=\theta^{T}x
η = θ T x
η
\eta
η
η
i
=
θ
i
T
x
\eta_i=\theta_i^Tx
η i = θ i T x
(3)
h
(
x
)
=
E
[
y
∣
x
]
h(x)=E[y|x]
h ( x ) = E [ y ∣ x ]
h
(
x
)
=
p
(
y
=
1
∣
x
;
θ
)
h(x)=p(y=1|x;\theta)
h ( x ) = p ( y = 1 ∣ x ; θ )
E
[
y
∣
x
]
=
1
∗
p
(
y
=
1
∣
x
;
θ
)
+
0
∗
p
(
y
=
0
∣
x
;
θ
)
E[y|x]=1*p(y=1|x;\theta)+0*p(y=0|x;\theta)
E [ y ∣ x ] = 1 ∗ p ( y = 1 ∣ x ; θ ) + 0 ∗ p ( y = 0 ∣ x ; θ )
h
(
x
)
=
E
[
y
∣
x
]
h(x)=E[y|x]
h ( x ) = E [ y ∣ x ]
接下来,我们首先证明高斯分布、伯努利分布和多项式分布属于指数分布族,然后我们由广义线性模型推导出线性回归,逻辑回归和多项式回归。这是因为:线性回归假设样本和噪声服从高斯分布,逻辑回归假设样本服从伯努利分布,多项式回归假设样本服从多项式分布。
注:关于多项式回归,会介绍得稍微详细点。
因为方差
σ
2
\sigma^2
σ 2
θ
\theta
θ
h
θ
(
x
)
h_\theta(x)
h θ ( x )
σ
=
1
\sigma=1
σ = 1
p
(
y
;
u
)
=
1
2
π
σ
e
x
p
(
−
(
y
−
u
)
2
2
σ
2
)
=
1
2
π
e
x
p
(
−
(
y
−
u
)
2
2
)
=
1
2
π
e
x
p
(
−
1
2
y
2
)
∗
e
x
p
(
u
y
−
1
2
u
2
)
\begin{aligned} p(y;u)&={1\over \sqrt{2\pi}\sigma}exp(-{(y-u)^2\over 2\sigma^2})\\ &= {1\over \sqrt{2\pi}}exp(-{(y-u)^2\over 2})\\ &={1\over \sqrt{2\pi}}exp(-{1\over 2}y^2)*exp(uy-{1\over 2}u^2) \end{aligned}
p ( y ; u ) = 2 π
σ 1 e x p ( − 2 σ 2 ( y − u ) 2 ) = 2 π
1 e x p ( − 2 ( y − u ) 2 ) = 2 π
1 e x p ( − 2 1 y 2 ) ∗ e x p ( u y − 2 1 u 2 )
因此:
b
(
y
)
=
1
2
π
e
x
p
(
−
1
2
y
2
)
η
=
u
T
(
y
)
=
y
a
(
η
)
=
1
2
u
2
=
1
2
η
2
\begin{aligned} b(y)&={1\over \sqrt{2\pi}}exp(-{1\over 2}y^2)\\ \eta&=u \\ T(y) &=y\\ a(\eta)&={1\over 2}u^2 ={1\over 2}\eta^2 \end{aligned}
b ( y ) η T ( y ) a ( η ) = 2 π
1 e x p ( − 2 1 y 2 ) = u = y = 2 1 u 2 = 2 1 η 2
由以上分析,我们可以得到结论:高斯分布属于指数分布族的一类。
p
(
y
;
ϕ
)
=
ϕ
y
(
1
−
ϕ
)
1
−
y
=
e
x
p
(
y
l
o
g
ϕ
+
(
1
−
y
)
l
o
g
(
1
−
ϕ
)
)
=
e
x
p
(
y
l
o
g
ϕ
1
−
ϕ
+
l
o
g
(
1
−
ϕ
)
)
\begin{aligned} p(y;\phi)&=\phi^y(1-\phi)^{1-y}\\ &= exp(ylog\phi+(1-y)log(1-\phi))\\ &=exp(ylog{\phi\over 1-\phi}+log(1-\phi)) \end{aligned}
p ( y ; ϕ ) = ϕ y ( 1 − ϕ ) 1 − y = e x p ( y l o g ϕ + ( 1 − y ) l o g ( 1 − ϕ ) ) = e x p ( y l o g 1 − ϕ ϕ + l o g ( 1 − ϕ ) )
因此:
b
(
y
)
=
1
η
=
l
o
g
ϕ
1
−
ϕ
T
(
y
)
=
y
a
(
η
)
=
−
l
o
g
(
1
−
ϕ
)
=
l
o
g
(
e
η
+
1
)
\begin{aligned} b(y)&=1\\ \eta&=log{\phi\over 1-\phi} \\ T(y) &=y\\ a(\eta)&=-log(1-\phi)=log(e^\eta+1) \end{aligned}
b ( y ) η T ( y ) a ( η ) = 1 = l o g 1 − ϕ ϕ = y = − l o g ( 1 − ϕ ) = l o g ( e η + 1 )
由以上分析,我们可以得到结论:伯努利分布属于指数分布族的一类。
同时,由
η
=
l
o
g
ϕ
1
−
ϕ
\eta=log{\phi\over 1-\phi}
η = l o g 1 − ϕ ϕ
ϕ
=
1
1
+
e
−
η
\phi={1\over 1+e^{-\eta}}
ϕ = 1 + e − η 1 这就是我们熟悉的sigmoid函数。 同时根据第2个假设中的
η
=
θ
T
x
\eta=\theta^{T}x
η = θ T x
η
=
l
o
g
(
ϕ
1
−
ϕ
)
=
θ
T
x
\eta=log(\frac{\phi}{1-\phi})=\theta^{T}x
η = l o g ( 1 − ϕ ϕ ) = θ T x
Softmax回归本质上是一个多分类问题。假设输出
y
y
y
k
k
k
y
ϵ
[
1
,
2
,
.
.
.
,
k
]
y\epsilon [1,2,...,k]
y ϵ [ 1 , 2 , . . . , k ]
k
k
k
ϕ
1
,
ϕ
2
,
.
.
.
,
ϕ
k
\phi_1,\phi_2,...,\phi_k
ϕ 1 , ϕ 2 , . . . , ϕ k
ϕ
k
=
1
−
∑
i
=
1
k
−
1
ϕ
i
\phi_k = 1-\sum_{i=1}^{k-1}\phi_i
ϕ k = 1 − ∑ i = 1 k − 1 ϕ i
T
(
y
)
ϵ
R
k
−
1
T(y)\epsilon R^{k-1}
T ( y ) ϵ R k − 1
T
(
1
)
=
[
1
0
0
⋮
0
]
,
T
(
2
)
=
[
0
1
0
⋮
0
]
,
T
(
3
)
=
[
0
0
1
⋮
0
]
,
.
.
.
,
T
(
k
−
1
)
=
[
0
0
0
⋮
1
]
,
T
(
k
)
=
[
0
0
0
⋮
0
]
T(1)=\begin{bmatrix} 1 \\ 0 \\ 0 \\ \vdots\\ 0 \end{bmatrix},T(2)=\begin{bmatrix} 0 \\ 1 \\ 0 \\ \vdots\\ 0 \end{bmatrix},T(3)=\begin{bmatrix} 0 \\ 0 \\ 1 \\ \vdots\\ 0 \end{bmatrix},...,T(k-1)=\begin{bmatrix} 0 \\ 0 \\ 0 \\ \vdots\\ 1 \end{bmatrix},T(k)=\begin{bmatrix} 0 \\ 0 \\ 0 \\ \vdots\\ 0 \end{bmatrix}
T ( 1 ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 1 0 0 ⋮ 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ , T ( 2 ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 1 0 ⋮ 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ , T ( 3 ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 1 ⋮ 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ , . . . , T ( k − 1 ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 0 ⋮ 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ , T ( k ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 0 ⋮ 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
我们可以看到,
T
(
y
)
T(y)
T ( y )
k
−
1
k−1
k − 1
(
T
(
y
)
)
i
(T(y))_i
( T ( y ) ) i
T
(
y
)
T(y)
T ( y )
i
i
i
为了方便表示,我们使用
1
{
.
}
1\{.\}
1 { . }
1
{
.
}
=
1
1\{.\}=1
1 { . } = 1
1
{
.
}
=
0
1\{.\}=0
1 { . } = 0
1
{
2
=
3
}
=
0
1\{2=3\}=0
1 { 2 = 3 } = 0
1
{
3
=
4
−
1
}
=
1
1\{3=4-1\}=1
1 { 3 = 4 − 1 } = 1
(
T
(
y
)
)
i
=
1
{
y
=
i
}
(T(y))_i=1\{y=i\}
( T ( y ) ) i = 1 { y = i }
E
[
(
T
(
y
)
)
i
]
=
p
(
y
=
i
)
=
ϕ
i
.
E[(T(y))_i]=p(y=i)=\phi_i.
E [ ( T ( y ) ) i ] = p ( y = i ) = ϕ i .
多项式分布:
p
(
y
∣
x
;
θ
)
=
ϕ
1
1
{
y
=
1
}
ϕ
2
1
{
y
=
2
}
.
.
.
ϕ
k
1
{
y
=
k
}
=
ϕ
1
1
{
y
=
1
}
ϕ
2
1
{
y
=
2
}
.
.
.
ϕ
k
1
−
∑
i
=
1
k
−
1
1
{
y
=
i
}
=
ϕ
1
(
T
(
y
)
)
1
ϕ
2
(
T
(
y
)
)
2
.
.
.
ϕ
k
1
−
∑
i
=
1
k
−
1
(
T
(
y
)
)
i
=
e
x
p
(
(
T
(
y
)
)
1
l
o
g
ϕ
1
+
(
T
(
y
)
)
2
l
o
g
ϕ
2
+
.
.
.
+
(
1
−
∑
i
=
1
k
−
1
(
T
(
y
)
)
i
)
l
o
g
ϕ
k
)
=
e
x
p
(
(
T
(
y
)
)
1
l
o
g
ϕ
1
ϕ
k
+
(
T
(
y
)
)
2
l
o
g
ϕ
2
ϕ
k
+
.
.
.
+
(
T
(
y
)
)
k
−
1
l
o
g
ϕ
k
−
1
ϕ
k
+
l
o
g
ϕ
k
)
\begin{aligned} p(y|x;\theta)&=\phi_1^{1\{y=1\}}\phi_2^{1\{y=2\}}...\phi_k^{1\{y=k\}}\\ &=\phi_1^{1\{y=1\}}\phi_2^{1\{y=2\}}...\phi_k^{1-\sum_{i=1}^{k-1}1\{y=i\}}\\ &=\phi_1^{(T(y))_1}\phi_2^{(T(y))_2}...\phi_k^{1-\sum_{i=1}^{k-1}(T(y))_i}\\ &=exp((T(y))_1log\phi_1+(T(y))_2log\phi_2+...+(1-\sum_{i=1}^{k-1}(T(y))_i)log\phi_k)\\ &=exp((T(y))_1log{\phi_1\over \phi_k}+(T(y))_2log{\phi_2\over \phi_k}+...+(T(y))_{k-1}log{\phi_{k-1}\over \phi_k}+log\phi_k) \end{aligned}
p ( y ∣ x ; θ ) = ϕ 1 1 { y = 1 } ϕ 2 1 { y = 2 } . . . ϕ k 1 { y = k } = ϕ 1 1 { y = 1 } ϕ 2 1 { y = 2 } . . . ϕ k 1 − ∑ i = 1 k − 1 1 { y = i } = ϕ 1 ( T ( y ) ) 1 ϕ 2 ( T ( y ) ) 2 . . . ϕ k 1 − ∑ i = 1 k − 1 ( T ( y ) ) i = e x p ( ( T ( y ) ) 1 l o g ϕ 1 + ( T ( y ) ) 2 l o g ϕ 2 + . . . + ( 1 − i = 1 ∑ k − 1 ( T ( y ) ) i ) l o g ϕ k ) = e x p ( ( T ( y ) ) 1 l o g ϕ k ϕ 1 + ( T ( y ) ) 2 l o g ϕ k ϕ 2 + . . . + ( T ( y ) ) k − 1 l o g ϕ k ϕ k − 1 + l o g ϕ k )
因此:
b
(
y
)
=
1
η
=
[
l
o
g
ϕ
1
ϕ
k
l
o
g
ϕ
2
ϕ
k
⋮
l
o
g
ϕ
k
−
1
ϕ
k
]
T
(
y
)
=
[
(
T
(
y
)
)
1
(
T
(
y
)
)
2
⋮
(
T
(
y
)
)
k
−
1
]
a
(
η
)
=
−
l
o
g
(
ϕ
k
)
\begin{aligned} b(y)&=1\\ \eta&=\begin{bmatrix}log{\phi_1\over \phi_k}\\ log{\phi_2\over \phi_k}\\ \vdots\\ log{\phi_{k-1}\over \phi_k} \end{bmatrix}\\ T(y) &=\begin{bmatrix}(T(y))_1\\ (T(y))_2\\ \vdots\\ (T(y))_{k-1} \end{bmatrix}\\ a(\eta)&=-log(\phi_k) \end{aligned}
b ( y ) η T ( y ) a ( η ) = 1 = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ l o g ϕ k ϕ 1 l o g ϕ k ϕ 2 ⋮ l o g ϕ k ϕ k − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎡ ( T ( y ) ) 1 ( T ( y ) ) 2 ⋮ ( T ( y ) ) k − 1 ⎦ ⎥ ⎥ ⎥ ⎤ = − l o g ( ϕ k )
由以上分析可得到,多项式分布属于指数分布族的一类。
i
i
i
η
i
=
l
o
g
ϕ
i
ϕ
k
\eta_i=log{\phi_i\over \phi_k}
η i = l o g ϕ k ϕ i
ϕ
i
=
ϕ
k
e
η
i
\phi_i=\phi_ke^{\eta_i}
ϕ i = ϕ k e η i
∑
i
=
1
k
ϕ
i
=
∑
i
=
1
k
ϕ
k
e
η
i
=
1
\sum_{i=1}^k\phi_i=\sum_{i=1}^k\phi_ke^{\eta_i}=1
∑ i = 1 k ϕ i = ∑ i = 1 k ϕ k e η i = 1
ϕ
k
=
1
∑
i
=
1
k
e
η
i
\phi_k={1\over \sum_{i=1}^ke^{\eta_i}}
ϕ k = ∑ i = 1 k e η i 1
ϕ
i
=
e
η
i
∑
j
=
1
k
e
η
j
\phi_i={e^{\eta_i}\over \sum_{j=1}^ke^{\eta_j}}
ϕ i = ∑ j = 1 k e η j e η i
我们知道,在线性回归中
y
∣
x
;
θ
−
N
(
μ
,
σ
2
)
y|x;\theta-N(\mu,\sigma^2)
y ∣ x ; θ − N ( μ , σ 2 )
y
y
y
μ
\mu
μ
h
θ
(
x
)
=
E
[
y
∣
x
]
=
μ
=
η
=
θ
T
x
\begin{aligned} h_\theta(x)&=E[y|x]\\ &= \mu\\ &=\eta\\ &=\theta^Tx \end{aligned}
h θ ( x ) = E [ y ∣ x ] = μ = η = θ T x
其中,第一个等式由假设3得到,第二个等式是高斯分布的数学期望,第三个等式由假设1得到,即由高斯分布属于指数分布族推导出来,第四个等式由假设2得到。
我们知道,在逻辑回归中,
y
∣
x
;
θ
−
B
e
r
n
o
u
l
l
i
(
ϕ
)
y|x;\theta-Bernoulli(\phi)
y ∣ x ; θ − B e r n o u l l i ( ϕ )
ϕ
=
p
(
y
=
1
∣
x
;
θ
)
\phi=p(y=1|x;\theta)
ϕ = p ( y = 1 ∣ x ; θ )
y
y
y
h
θ
(
x
)
=
E
[
y
∣
x
]
=
p
(
y
=
1
∣
x
;
θ
)
=
ϕ
=
1
1
+
e
−
η
=
1
1
+
e
−
θ
T
x
\begin{aligned} h_\theta(x)&=E[y|x]\\ &= p(y=1|x;\theta)\\ &=\phi\\ &={1\over 1+e^{-\eta}} \\ &={1\over 1+e^{-\theta^Tx}} \end{aligned}
h θ ( x ) = E [ y ∣ x ] = p ( y = 1 ∣ x ; θ ) = ϕ = 1 + e − η 1 = 1 + e − θ T x 1
其中,第一个等式由假设3得到,第二个等式是高斯分布的数学期望,第三个等式是我们的定义,第四个等式由假设1得到,即由伯努利分布属于指数分布族推导出来,第五个等式由假设2得到。
在多项式回归中预测输出值:
h
θ
(
x
)
=
E
[
y
∣
x
]
=
[
1
{
y
=
1
}
∣
x
;
θ
1
{
y
=
2
}
∣
x
;
θ
⋮
1
{
y
=
k
−
1
}
∣
x
;
θ
]
=
[
ϕ
1
ϕ
2
⋮
ϕ
k
−
1
]
=
[
e
x
p
(
θ
1
T
x
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
)
e
x
p
(
θ
2
T
x
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
)
⋮
e
x
p
(
θ
k
−
1
T
x
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
)
]
\begin{aligned} h_\theta(x)&=E[y|x]\\ &=\begin{bmatrix} 1\{y=1\}|x;\theta\\ 1\{y=2\}|x;\theta\\ \vdots\\ 1\{y=k-1\}|x;\theta \end{bmatrix}\\ &=\begin{bmatrix} \phi_1\\ \phi_2\\ \vdots\\ \phi_{k-1} \end{bmatrix}\\ &=\begin{bmatrix} {exp(\theta_1^Tx)\over \sum_{j=1}^kexp(\theta_j^Tx)}\\ {exp(\theta_2^Tx)\over \sum_{j=1}^kexp(\theta_j^Tx)}\\ \vdots\\ {exp(\theta_{k-1}^Tx)\over \sum_{j=1}^kexp(\theta_j^Tx)} \end{bmatrix} \end{aligned}
h θ ( x ) = E [ y ∣ x ] = ⎣ ⎢ ⎢ ⎢ ⎡ 1 { y = 1 } ∣ x ; θ 1 { y = 2 } ∣ x ; θ ⋮ 1 { y = k − 1 } ∣ x ; θ ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎡ ϕ 1 ϕ 2 ⋮ ϕ k − 1 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ∑ j = 1 k e x p ( θ j T x ) e x p ( θ 1 T x ) ∑ j = 1 k e x p ( θ j T x ) e x p ( θ 2 T x ) ⋮ ∑ j = 1 k e x p ( θ j T x ) e x p ( θ k − 1 T x ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
p
(
y
=
k
∣
x
;
θ
)
=
1
−
∑
i
=
1
k
−
1
p
(
y
=
i
∣
x
;
θ
)
p(y=k|x;\theta)=1-\sum_{i=1}^{k-1}p(y=i|x;\theta)
p ( y = k ∣ x ; θ ) = 1 − ∑ i = 1 k − 1 p ( y = i ∣ x ; θ )
接下来,我们来看一下多项式回归中如何求解参数:就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者什么样的参数才能使我们观测到目前这组数据的概率最大 ) 。
即:对数似然函数为:
J
(
θ
)
=
l
o
g
∏
i
=
1
m
p
(
y
(
i
)
∣
x
(
i
)
;
θ
)
=
∑
i
=
1
m
l
o
g
p
(
y
(
i
)
∣
x
(
i
)
;
θ
)
=
∑
i
=
1
m
l
o
g
ϕ
1
1
{
y
(
i
)
=
1
}
ϕ
2
1
{
y
(
i
)
=
2
}
.
.
.
ϕ
k
1
{
y
(
i
)
=
k
}
=
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
l
o
g
ϕ
1
+
1
{
y
(
i
)
=
2
}
l
o
g
ϕ
2
+
.
.
.
+
1
{
y
(
i
)
=
k
}
l
o
g
ϕ
k
=
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
l
o
g
e
x
p
(
θ
1
T
x
(
i
)
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
(
i
)
)
+
1
{
y
(
i
)
=
2
}
l
o
g
e
x
p
(
θ
2
T
x
(
i
)
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
(
i
)
)
+
.
.
.
+
1
{
y
(
i
)
=
k
}
l
o
g
e
x
p
(
θ
k
T
x
(
i
)
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
(
i
)
)
=
∑
i
=
1
m
(
1
{
y
(
i
)
=
1
}
l
o
g
e
θ
1
T
x
(
i
)
+
1
{
y
(
i
)
=
2
}
l
o
g
e
θ
2
T
x
(
i
)
+
.
.
.
+
1
{
y
(
i
)
=
k
}
l
o
g
e
θ
k
T
x
(
i
)
−
l
o
g
∑
j
=
1
k
e
θ
j
T
x
)
\begin{aligned} J(\theta)&=log\prod_{i=1}^mp(y^{(i)}|x^{(i)};\theta)\\ &=\sum_{i=1}^mlog \ p(y^{(i)}|x^{(i)};\theta)\\ &=\sum_{i=1}^mlog \ \phi_1^{1\{y^{(i)}=1\}}\phi_2^{1\{y^{(i)}=2\}}...\phi_k^{1\{y^{(i)}=k\}}\\ &=\sum_{i=1}^m{1\{y^{(i)}=1\}}log \ \phi_1+{1\{y^{(i)}=2\}}log \ \phi_2+...+{1\{y^{(i)}=k\}}log \ \phi_k\\ &=\sum_{i=1}^m{1\{y^{(i)}=1\}}log \ {exp(\theta_1^Tx^{(i)})\over \sum_{j=1}^kexp(\theta_j^Tx^{(i)})}+{1\{y^{(i)}=2\}}log \ {exp(\theta_2^Tx^{(i)})\over \sum_{j=1}^kexp(\theta_j^Tx^{(i)})}+...+{1\{y^{(i)}=k\}}log \ {exp(\theta_k^Tx^{(i)})\over \sum_{j=1}^kexp(\theta_j^Tx^{(i)})}\\ &=\sum_{i=1}^m(1\{y^{(i)}=1\}log \ e^{\theta_1^Tx^{(i)}}+1\{y^{(i)}=2\}log \ e^{\theta_2^Tx^{(i)}}+...+1\{y^{(i)}=k\}log \ e^{\theta_k^Tx^{(i)}}-log\sum_{j=1}^ke^{\theta_j^Tx}) \end{aligned}
J ( θ ) = l o g i = 1 ∏ m p ( y ( i ) ∣ x ( i ) ; θ ) = i = 1 ∑ m l o g p ( y ( i ) ∣ x ( i ) ; θ ) = i = 1 ∑ m l o g ϕ 1 1 { y ( i ) = 1 } ϕ 2 1 { y ( i ) = 2 } . . . ϕ k 1 { y ( i ) = k } = i = 1 ∑ m 1 { y ( i ) = 1 } l o g ϕ 1 + 1 { y ( i ) = 2 } l o g ϕ 2 + . . . + 1 { y ( i ) = k } l o g ϕ k = i = 1 ∑ m 1 { y ( i ) = 1 } l o g ∑ j = 1 k e x p ( θ j T x ( i ) ) e x p ( θ 1 T x ( i ) ) + 1 { y ( i ) = 2 } l o g ∑ j = 1 k e x p ( θ j T x ( i ) ) e x p ( θ 2 T x ( i ) ) + . . . + 1 { y ( i ) = k } l o g ∑ j = 1 k e x p ( θ j T x ( i ) ) e x p ( θ k T x ( i ) ) = i = 1 ∑ m ( 1 { y ( i ) = 1 } l o g e θ 1 T x ( i ) + 1 { y ( i ) = 2 } l o g e θ 2 T x ( i ) + . . . + 1 { y ( i ) = k } l o g e θ k T x ( i ) − l o g j = 1 ∑ k e θ j T x )
最后一步中,为什么只有一个
l
o
g
∑
j
=
1
k
e
θ
j
T
x
log\sum_{j=1}^ke^{\theta_j^Tx}
l o g ∑ j = 1 k e θ j T x
1
{
.
}
1\{.\}
1 { . }
l
l
l
∂
J
(
θ
)
∂
θ
j
=
∑
i
=
1
m
(
1
{
y
(
i
)
=
l
}
∗
x
(
i
)
−
1
∑
j
=
1
k
e
x
p
(
θ
j
T
x
(
i
)
)
∗
e
x
p
(
θ
l
T
x
)
∗
x
(
i
)
)
=
∑
i
=
1
m
(
1
{
y
(
i
)
=
l
}
∗
x
(
i
)
−
p
(
y
(
i
)
=
l
∣
x
(
i
)
;
θ
)
∗
x
(
i
)
)
\begin{aligned} {\partial J(\theta)\over \partial \theta_j}&=\sum_{i=1}^m(1\{y^{(i)}=l\}*x^{(i)}-{1\over \sum_{j=1}^kexp(\theta_j^Tx^{(i)})}*exp(\theta_l^Tx)*x^{(i)})\\ &=\sum_{i=1}^m(1\{y^{(i)}=l\}*x^{(i)}-p(y^{(i)}=l|x^{(i)};\theta)*x^{(i)}) \end{aligned}
∂ θ j ∂ J ( θ ) = i = 1 ∑ m ( 1 { y ( i ) = l } ∗ x ( i ) − ∑ j = 1 k e x p ( θ j T x ( i ) ) 1 ∗ e x p ( θ l T x ) ∗ x ( i ) ) = i = 1 ∑ m ( 1 { y ( i ) = l } ∗ x ( i ) − p ( y ( i ) = l ∣ x ( i ) ; θ ) ∗ x ( i ) )
注意:
∂
J
(
θ
)
∂
θ
j
{\partial J(\theta)\over \partial \theta_j}
∂ θ j ∂ J ( θ )
最后,我们的预测输出值的表达式如下:
h
θ
(
x
)
=
[
e
x
p
(
θ
1
T
x
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
)
e
x
p
(
θ
2
T
x
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
)
⋮
e
x
p
(
θ
k
−
1
T
x
)
∑
j
=
1
k
e
x
p
(
θ
j
T
x
)
]
\begin{aligned} h_\theta(x) &=&\begin{bmatrix} {exp(\theta_1^Tx)\over \sum_{j=1}^kexp(\theta_j^Tx)}\\ {exp(\theta_2^Tx)\over \sum_{j=1}^kexp(\theta_j^Tx)}\\ \vdots\\ {exp(\theta_{k-1}^Tx)\over \sum_{j=1}^kexp(\theta_j^Tx)} \end{bmatrix} \end{aligned}
h θ ( x ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ∑ j = 1 k e x p ( θ j T x ) e x p ( θ 1 T x ) ∑ j = 1 k e x p ( θ j T x ) e x p ( θ 2 T x ) ⋮ ∑ j = 1 k e x p ( θ j T x ) e x p ( θ k − 1 T x ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
取
h
θ
(
x
)
h_\theta(x)
h θ ( x )
Softmax 回归有一个不寻常的特点:它有一个“冗余”的参数集。为了便于阐述这一特点,假设我们从参数向量
θ
j
\theta_j
θ j
ψ
\textstyle \psi
ψ
θ
j
\theta_j
θ j
θ
j
−
ψ
(
j
=
1
,
2
,
.
.
.
,
k
)
\theta_j-\psi(j=1,2,...,k)
θ j − ψ ( j = 1 , 2 , . . . , k )
θ
j
\theta_j
θ j
ψ
\textstyle \psi
ψ
h
θ
h_\theta
h θ
进一步而言,如果参数
(
θ
1
,
θ
2
,
…
,
θ
k
)
(\theta_1, \theta_2,\ldots, \theta_k)
( θ 1 , θ 2 , … , θ k )
J
(
θ
)
J(\theta)
J ( θ )
(
θ
1
−
ψ
,
θ
2
−
ψ
,
…
,
θ
k
−
ψ
)
\textstyle (\theta_1 - \psi, \theta_2 - \psi,\ldots, \theta_k - \psi)
( θ 1 − ψ , θ 2 − ψ , … , θ k − ψ )
ψ
\textstyle \psi
ψ
J
(
θ
)
\textstyle J(\theta)
J ( θ )
那么,应该如何解决这个问题呢?
我们通过添加一个权重衰减项
λ
2
∑
i
=
1
k
∑
j
=
0
n
θ
i
j
2
\textstyle \frac{\lambda}{2} \sum_{i=1}^k \sum_{j=0}^{n} \theta_{ij}^2
2 λ ∑ i = 1 k ∑ j = 0 n θ i j 2
λ
>
0
\textstyle \lambda > 0
λ > 0
J
(
θ
)
\textstyle J(\theta)
J ( θ )
为了使用优化算法,我们需要求得这个新函数
J
(
θ
)
\textstyle J(\theta)
J ( θ )
J
(
θ
)
\textstyle J(\theta)
J ( θ )
如果你在开发一个音乐分类的应用,需要对
k
k
k
k
k
k
这一选择取决于你的类别之间是否互斥,例如,如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数
k
=
4
k = 4
k = 4
k
k
k
如果你的四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
现在我们来看一个计算视觉领域的例子,你的任务是将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。你会使用sofmax回归还是 3个logistic 回归分类器呢? (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片,你又会选择 softmax 回归还是多个 logistic 回归分类器呢?
在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。
【1】广义线性模型与指数分布族 机器学习(二)广义线性模型:逻辑回归与Softmax分类 机器学习算法系列(24):机器学习中的损失函数 Softmax回归