步态横向网络:学习用于步态识别的判别和紧凑表示
论文题目:Gait Lateral Network: Learning Discriminative and Compact Representations for Gait Recognition
paper是中科院自动化所发表在ECCV 2020的工作
论文地址:链接
Abstract.
步态识别的目的时候通过步行模式识别不同的人,无需受试者合作即可远距离进行识别。步态识别的一个关键挑战是从轮廓中学习表示,这些表示不受服装、携带条件和相机视角等因素的影响。除了在识别方面具有判别性外,步态表示还应该是紧凑的存储,以保持数百万受试者在gallery中注册。在这项工作中,作者提出了一个名为 Gait Lateral Network (GLN) 的新型网络,它可以从步态识别的轮廓中学习判别和紧凑表示。具体来说,GLN 利用深度卷积神经网络中的固有特征金字塔来增强步态表示。将不同阶段提取的轮廓级和集合级特征以自上而下的方式与横向连接融合。此外,GLN 配备了一个 Compact Block,可以在不影响准确性的情况下显着降低步态表示的维度。对 CASIA-B 和 OUMVLP 的大量实验表明,GLN 可以使用 256 维表示实现最先进的性能。在 CASIA-B 上穿着不同衣服行走的具有挑战性的条件下,本文方法将 rank-1 准确率提高了 6.45%。
Keywords:
步态识别;横向连接;判别性表示;紧凑表示。
1 Introduction
步态识别目的是使用记录步行模式的视频来识别不同的人。与人脸、指纹和虹膜等其他生物特征相比,人的步态可以在没有受试者合作的情况下远距离获取,这有助于其在预防犯罪、法医鉴定和社交等方面的广泛应用安全。然而,步态识别会受到很多变化的影响,例如服装、携带条件和相机视角。一个关键的挑战是从对上述因素不变的步态序列的轮廓中学习表示。
为了解决这个问题,已经提出了各种方法,大致可以分为三类。第一类将完整步态序列的轮廓聚合成图像(或模板)以进行识别,例如步态能量图。尽管简单,但在预处理中不可避免地会丢失时间和细粒度的空间信息。第二类是将步态序列的轮廓视为视频。例如,在 [40] 中,采用3D-CNN来提取空间和时间信息,而模型相对难以训练。第三类是最近提出的,将步态序列的轮廓视为无序集合,对轮廓的数量具有鲁棒性,并取得了显著的提升。然而,GaitSet学习到的表示的维度高达15872,远高于人脸识别(180)或行人重识别(2048)的维度。
在这项工作中,作者处理步态识别,目的是从步态识别的轮廓中学习判别的和紧凑的表示。提出了一个名为 Gait Lateral Network(表示为 GLN)的新型网络,其中每个步态序列的轮廓被视为无序集合。如图 1 所示,除了区分不同的人外,每个轮廓集合的学习表示还应尽可能紧凑,否则会产生沉重的存储负担,以保持数百万受试者在gallery中注册。值得注意的是,GLN 学习到的表示的维度固定为 256,与GaitSet相比减少了近两个数量级,并且同时提高了所有步行条件的性能。
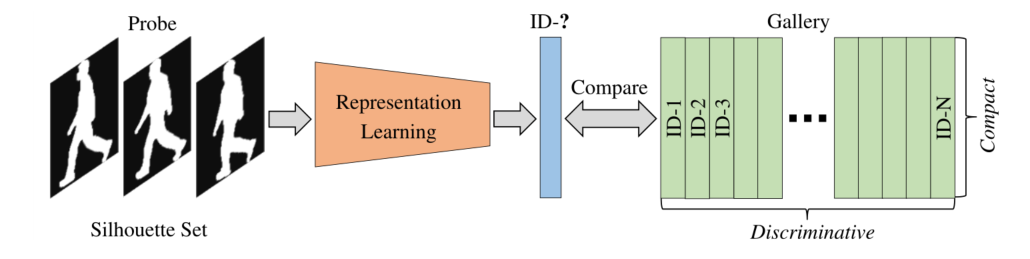
图 1. 基于轮廓的步态识别示意图。学习到的表示应该具有判别性以识别不同的人,并且还应该紧凑以便于存储
具体来说,作者提出利用深度 CNN 中的固有特征金字塔来学习判别性的步态表示。不同层提取的特征捕获输入的各种视觉细节。注意,不同subject的轮廓在许多情况下只有细微的差异,这使得探索编码局部空间结构信息的浅层特征对于步态识别至关重要。特别的,作者将GaitSet的网络修改为backbone,并将各层明确划分为三个阶段。将不同阶段提取的轮廓级和集合级特征以自上而下的方式与横向连接融合,试图聚合不同层提取的视觉细节以进行准确识别。然后将不同阶段细化后的特征水平分割以学习部分表示,并在所有阶段添加三元组损失作为中间监督。此外,作者提出了一种新颖的紧凑块来学习紧凑的步态表示。初步研究表明,HPM学习的高维表示存在大量冗余,HPM被广泛用于部分表示学习。所提出的紧凑块可以在不影响准确性的情况下将高维步态表示的信息提炼成紧凑的表示。它的架构简单但不平凡,可以与backbone无缝集成并以端到端的方式进行训练。作者将高维表示视为低维表示的集合,并利用 Dropout 选择一个小子集,然后通过全连接层将其映射到一个紧凑空间。
作者对这项工作的贡献在于三个方面:(1)提出利用深度 CNN 中的固有特征金字塔来增强步态表示以实现准确识别。将不同阶段提取的轮廓级和集合级特征以自上而下的方式与横向连接融合。 (2) 提出了一个紧凑块,它可以显着降低步态表示的维度而不影响准确性。 (3) 生成的 GLN 可以从用于步态识别的轮廓中学习判别性的和紧凑的表示。 CASIA-B和OUMVLP的实验表明,GLN 可以使用 256 维表示在所有步行条件下实现最先进的性能。特别的,在 CASIA-B上穿着不同衣服行走的最具挑战性的条件下,GLN 实现的 rank-1 准确率超过了 GaitSet [6] 的 15872 维表示 6.45%。
2 Related Work
Motion-based Gait Recognition. 这些方法包括[1, 3, 16]试图对人体结构进行建模,然后提取运动特征进行步态识别,其优点是对衣服和携带条件具有鲁棒性。然而,它们通常在低分辨率的视频中失败,因为那里很难准确地估计身体参数。
Appearance-based Gait Recognition. 这些方法包括[17, 26, 8, 37]直接从步态序列中学习特征,而不明确地对身体结构进行建模,这适合于低分辨率的条件,因此引来越来越多的关注。轮廓通常被作为输入,一个关键的挑战是从轮廓中学习对服装、携带条件和相机视角等因素具有鲁棒性的表示。基于轮廓的步态识别可以大致分为三类,其中完整步态序列的轮廓分别被视为图像、视频或无序的图像集合。
计算机视觉领域的深度学习也被广泛用于步态识别。具体来说,在[41]中对用于步态识别的深度卷积神经网络进行了全面研究。 [46] 提出了一种自动编码器框架,以明确分解表示学习中的外观和姿势特征。 JUCNet将跨步态和独特步态监督与定制的五元组损失相结合。DiGGAN利用Conditional GAN来学习视角不变的步态特征。 GaitSet将每个步态序列的轮廓视为无序集合,并水平分割特征以学习用于步态识别的部分表示,从而实现显著提高并在不同数据集上保持最佳性能。但是,GaitSet学习到的最终表示的维度太高,即15872维。
Inherent Feature Pyramid. 深度卷积神经网络中的固有特征金字塔已在许多视觉任务中得到利用。例如,FCN利用不同层的特征来逐步细化语义分割的预测。 Hypercolumns提出了一种有效的计算策略来聚合不同层的特征以进行对象分割和定位。 SSD分别使用不同层的特征检测对象,而不融合特征或分数。
在GLN中自上而下地合并不同阶段的特征的方式受到FPN的启发,用于目标检测。然而,本文的方法在三个方面与FPN不同。首先,在GLN的最后两个阶段有两个分支,如图2所示,GLN中的横向连接被用来同时合并轮廓级和集合级特征。第二,FPN中不同阶段的训练标签是根据感受野分配的,而GLN中不同阶段的监督信号是相同的。第三,FPN在不同阶段的头部共享参数,而GLN中不同阶段的后续层具有独立参数。
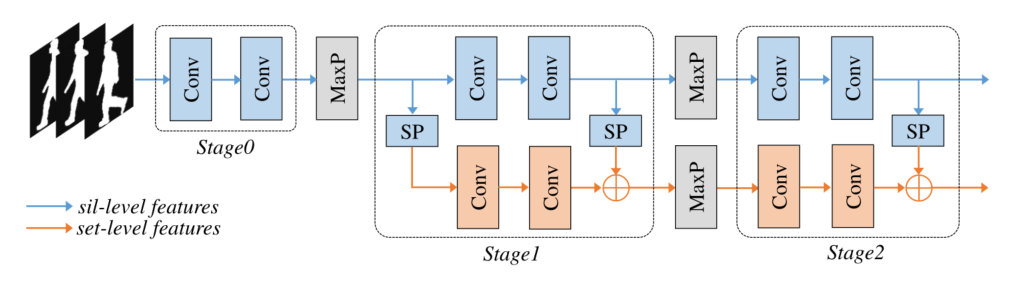
图 2. backbone划分示意图,Sil-level 为 Silhouette-level,MaxP 为 Max Pooling,SP 为 Set Pooling。轮廓级特征是从每个轮廓中分别提取的,而集合级特征是从所有轮廓中提取的。 Set Pooling 是一种聚合轮廓集中特征的操作
3 Our Approach
在这项工作中,作者提出了一个名为 Gait Lateral Network (GLN) 的新型网络,它可以从步态识别的轮廓中学习判别和紧凑表示。完整步态序列的轮廓被视为无序集合。网络结构如图3所示。backbone中不同阶段提取的轮廓级和集合级特征以自上而下的方式与横向连接融合,目的是增强步态表示以实现准确识别。作者提出了一个紧凑块,它可以显着降低步态表示的维度而不影响准确性。在下文中,首先详细说明 GLN 中的横向连接。然后介绍Compact Block的组成。最后,描述 GLN 的相应训练策略。
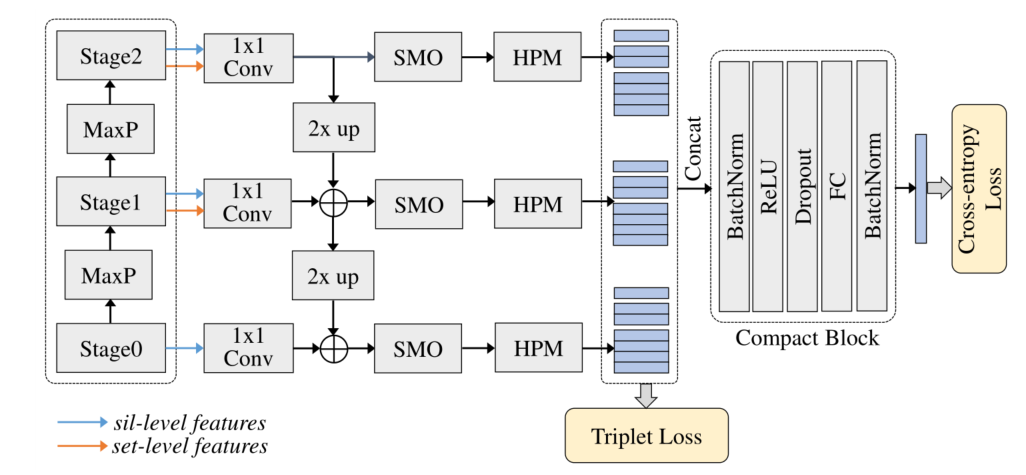
图 3. 步态横向网络示意图,Sil-level 代表轮廓级别,MaxP 代表最大池化,SMO 代表平滑层,HPM 代表水平金字塔映射。为简单起见,省略了每个 1 × 1 1 \times 1 1×1卷积层之前轮廓级特征的集合池化,使用尺度 S = { 1 , 2 , 4 } S=\{1,2,4\} S={ 1,2,4}在 HPM 中水平分割特征。以 Compact Block 的输出作为最终表示
3.1 Lateral Connections
在 GLN 中,作者提出利用深度卷积神经网络中的固有特征金字塔来学习判别性的步态表示。聚合backbone中不同层提取的特征以增强步态表示。
具体来说,作者将GaitSet的网络修改为第二个 Set Pooling 和 Max Pooling 的顺序交换的backbone。如图 2 所示,明确地将backbone中的层分为三个阶段。第一阶段由两个卷积层组成,它们将轮廓转换为内部特征。第二和第三阶段由两个分支组成,分别学习轮廓级和集合级特征。 Set Pooling 是一种聚合轮廓集合中特征的函数,它应该对轮廓的顺序是置换不变的,并且为简单起见由 Max Pooling 实现。
注意,与沿空间维度(高度和宽度)运行的不同阶段之间的 Max Pooling 不同,Max Pooling for Set Pooling 沿集合维度运行。backbone以自下而上的方式提取轮廓级特征以及集合级特征。三个阶段提取的特征分别记为 { C 0 , C 1 , C 2 } \left\{C_{0}, C_{1}, C_{2}\right\} { C0,C1,C2},相对于输入轮廓的步长为 { 1 , 2 , 4 } \{1,2,4\} { 1,2,4}。
backbone中不同阶段的特征捕捉轮廓的各种视觉细节,作者提出以自上而下的方式将不同阶段提取的特征与横向连接合并。该策略如图 3 所示。具体来说,首先,在最后两个阶段,采用 Set Pooling 来处理轮廓级特征,并将输出与沿通道维度的集合级特征连接起来。在第一阶段,只有轮廓级特征可用,这些特征也由集合池化处理。然后在每个阶段,取一个 1 × 1 1 \times 1 1×1的卷积层来重新排列特征并调整通道维度。接下来,从最后阶段生成的特征开始,将空间维度(高度和宽度)上采样 2 倍,并添加到上一阶段生成的特征(在 1 × 1 1 \times 1 1×1卷积层后具有相同的通道维度)通过元素相加。这个过程不断迭代,直到所有阶段生成的特征都被合并。最后,在每个阶段之后附加一个平滑层,以减轻由上采样和不同阶段之间的语义差距引起的混叠效应。平滑层的输出表示为三个阶段的 { F 0 , F 1 , F 2 } \left\{F_{0}, F_{1}, F_{2}\right\} { F0,F1,F2},对应于 { C 0 , C 1 , C 2 } \left\{C_{0}, C_{1}, C_{2}\right\} { C0,C1,C2},它们分别具有相同的空间维度。
注意, 1 × 1 1 \times 1 1×1卷积层和平滑层的输出具有相同的通道尺寸,通过实验固定为256。每个平滑层都由一个 3 × 3 3 \times 3 3×3的卷积层实现。此外,横向连接中不涉及非线性激活函数,在不同阶段之间使用最近邻上采样。
3.2 Compact Block
本节将详细阐述紧凑块的组成,该块被提出用于学习紧凑步态表示。在此之前,首先回顾水平金字塔映射(HPM)作为背景,这导致了高表示维度。
HPM 相当于人 ReID 的水平金字塔池(HPP),GLN 采用它来学习步态识别的部分表示。尽管有效,但 HPM 获得的表示具有非常高的维度,例如15872 维。具体来说,HPM首先使用多个尺度 S S S水平分割特征,例如 S = { 1 , 2 , 4 , 8 , 16 } S=\{1,2,4,8,16\} S={
1,2,4,8,16}。对于每个尺度 s ∈ S s \in S s∈S,特征 F F F水平等分为 s s s条。然后,采用全局最大池化和平均池化来为每个特征条生成特征 G s , t G_{s, t} Gs,t:
G s , t = MaxPool ( F s , t ) + AvgPool ( F s , t ) G_{s, t}=\operatorname{MaxPool}\left(F_{s, t}\right)+\operatorname{AvgPool}\left(F_{s, t}\right) Gs,t=MaxPool(Fs,t)+AvgPool(Fs,t)
其中 s ∈ S s \in S s∈S和 t ∈ { 1 , ⋯ , s } t \in\{1, \cdots, s\} t∈{
1,⋯,s}。最后,将全连接层应用于 G s , t G_{s, t} Gs,t,输出表示为 G ^ s , t \widehat{G}_{s, t} G
s,t。在训练阶段,损失被添加到每个部分的特征中。并且在测试阶段,所有部分的特征被连接起来作为最终的表示。结果,最终表示的维度与尺度之和(例如 sum ( S ) = 31 \operatorname{sum}(S)=31 sum(S)=31,其中 S = { 1 , 2 , 4 , 8 , 16 } ) S=\{1,2,4,8,16\}) S={
1,2,4,8,16})和每个部分的特征维度(例如 256 ),这对于现实世界的应用程序是不可行的。通过深入研究 HPM 的公式,观察到不同尺度的表示编码了一些重复的信息。例如,索引为 (s, t) = (4, 1) 和 (s, t) = {(8, 1), (8, 2)} 的部分表示对应于输入轮廓中的相同区域。因此作者推测HPM得到的高维表示存在大量冗余。
为了解决这个问题,作者提出了一个紧凑块,其目的是在不影响准确性的情况下将高维表示的信息提炼成紧凑的表示。如图 3 所示,Compact Block 有一个简单的结构,它由批量归一化 (BN-I)、ReLU、Dropout、全连接层 (FC) 和另一个批量归一化 (BN-II)。该块简单而有效,在这里作者提供每一层的设计原则:
- 采用BN-I对HPM得到的concatenated特征进行归一化,有助于稳定训练处理。
- 引入 ReLU 作为激活函数以增加 Compact Block 的非线性。
- Dropout 是 Compact Block 的关键。如上所述,HPM 获得的表示可以看作是低维表示的集合。在这里,利用 Dropout 从每个高维表示中选择一个小子集。
- FC 用于将 Dropout 中的小子集映射到更具辨别力的空间中。 FC 的输出决定了最终表示的维度,通过实验设置为 256。
- BN-II 的引入是为了方便优化受启发的交叉熵损失,其中训练集中的每个subject都被视为一个单独的类。
总之,Compact Block 将步态表示显着减少到一个固定维度(例如实验中的 256 个),它与backbone无缝集成并以端到端的方式进行训练。注意,作者采用了PyTorch中的 Dropout 的实现。它只在训练阶段起作用,在推理时,最终的表示可以被视为多个归约的集合。
3.3 Training Strategy.
GLN 的训练策略包括两个步骤:横向预训练和全局训练。如图 3 所示,训练中涉及两种类型的损失,即三元组损失和交叉熵损失。在 HPM 之后部署三元组损失作为中间监督,而在 GLN 的末尾添加交叉熵损失以学习全局表示。
首先,为了获得合理的横向连接初始化,提出了仅由三元组损失监督的横向预训练。具体来说,将所有阶段的三元组损失的batch all版本添加到HPM在所有阶段获得的每个部分的特征中。公式为:
L t p = 1 N t p + ∑ s ∈ S ∑ t = 1 s ⏞ bins ∑ i = 1 P ∑ j = 1 K ⏞ anchors ∑ a = 1 a ≠ j K ⏞ pos. ∑ b = 1 b ≠ i P ∑ c = 1 K ⏞ negative [ m + d s , t , i , j , i , a s , t , i , j , b , c ] + d s , t , i , j , i , a s , t , i , j , b , c = dist ( f ( sil i , j s , t ) , f ( sil i , a s , t ) ) − dist ( f ( sil i , j s , t ) , f ( sil b , c s , t ) ) \begin{aligned} &L_{t p}=\frac{1}{N_{t p_{+}}} \overbrace{\sum_{s \in S} \sum_{t=1}^{s}}^{\text{bins}} \overbrace{\sum_{i=1}^{\text {P }} \sum_{j=1}^{K}}^{\text {anchors }} \overbrace{\sum_{a=1 \atop a \neq j}^{K}}^{\text {pos. }} \overbrace{\sum_{b=1 \atop b \neq i}^{P} \sum_{c=1}^{K}}^{\text {negative }}\left[m+d_{s, t, i, j, i, a}^{s, t, i, j, b, c}\right]_{+}^{\text {}}\\ &d_{s, t, i, j, i, a}^{s, t, i, j, b, c}=\operatorname{dist}\left(f\left(\operatorname{sil}_{i, j}^{s, t}\right), f\left(\operatorname{sil}_{i, a}^{s, t}\right)\right)-\operatorname{dist}\left(f\left(\operatorname{sil}_{i, j}^{s, t}\right), f\left(\operatorname{sil}_{b, c}^{s, t}\right)\right) \end{aligned} Ltp=Ntp+1s∈S∑t=1∑s
binsi=1∑P j=1∑K
anchors a=ja=1∑K
pos. b=ib=1∑Pc=1∑K
negative [m+ds,t,i,j,i,as,t,i,j,b,c]+ds,t,i,j,i,as,t,i,j,b,c=dist(f(sili,js,t),f(sili,as,t))−dist(f(sili,js,t),f(silb,cs,t))
其中 N t p + N_{t p_{+}} Ntp+是在 mini-batch 中导致非零损失项的三元组数, S S S是 HPM 的多个尺度, ( P , K ) (P, K) (P,K)是mini-batch中每个受试者的数量和序列的数量, m m m是margin threshold, f f f表示特征提取, sil \text{sil} sil表示轮廓集,dist衡量两个特征之间的相似度,例如欧几里得距离。请注意,在横向预训练中,不会降低学习率以防止过拟合。
然后,进行全局训练,以三元组损失和交叉熵损失之和对整个网络进行训练。对于交叉熵损失,训练集中的每个受试者都被视为一个单独的类,并采用了标签平滑技术。公式为:
L c e = − 1 P × K ∑ i = 1 P ∑ j = 1 K ∑ n = 1 N q n i j log p n i j L_{c e}=-\frac{1}{P \times K} \sum_{i=1}^{P} \sum_{j=1}^{K} \sum_{n=1}^{N} q_{n}^{i j} \log p_{n}^{i j} Lce=−P×K1i=1∑Pj=1∑Kn=1∑Nqnijlogpnij
其中 N N N是训练集中所有受试者的数量, p p p是属于每个受试者的概率, q q q编码身份信息,计算如下(以第 y t h y^{th} yth个受试者为例):
q n i j = { 1 − N − 1 N ϵ if n = y ϵ N otherwise q_{n}^{i j}= \begin{cases}1-\frac{N-1}{N} \epsilon & \text { if } n=y \\ \frac{\epsilon}{N} & \text { otherwise }\end{cases} qnij={
1−NN−1ϵNϵ if n=y otherwise
其中 ϵ \epsilon ϵ是一个小常数,使模型对训练集不那么敏感。实验中, ϵ \epsilon ϵ设置为 0.1。 Global Training 的总损失计算如下:
L = L t p + L c e L=L_{t p}+L_{c e} L=Ltp+Lce
注意,在训练阶段,在 Compact Block 之后引入了另一个全连接层来计算每个subject的概率,但是在推理时弃用。 Compact Block 的输出作为每个轮廓集的最终表示,以匹配probe和gallery。
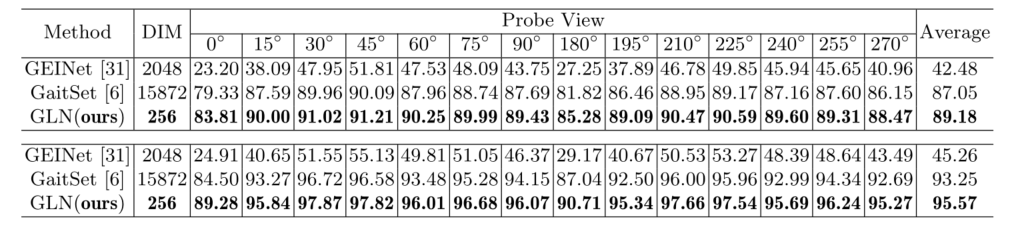
Results
CASIA-B
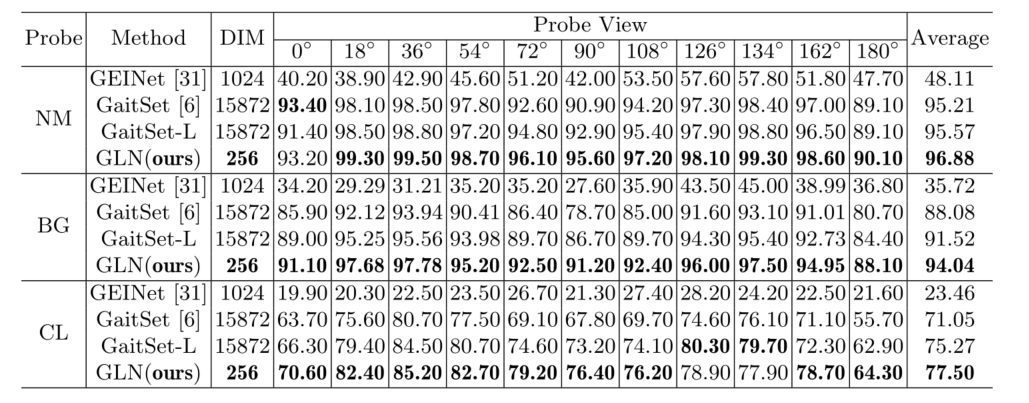
OU-MVLP
参考文献
[1]. Ariyanto, G., Nixon, M.S.: Model-based 3d gait biometrics. In: International JointConference on Biometrics. pp. 1–7 (2011)
[3]. Bodor, R., Drenner, A., Fehr, D., Masoud, O., Papanikolopoulos, N.: View-independent human motion classification using image-based reconstruction. Imageand Vision Computing 27(8), 1194–1206 (2009)
[8]. Han, J., Bhanu, B.: Individual recognition using gait energy image. TPAMI 28(2),316–322 (2005)
[16]. Kusakunniran, W., Wu, Q., Li, H., Zhang, J.: Multiple views gait recognitionusing view transformation model based on optimized gait energy image. In: ICCVWorkshops. pp. 1058–1064 (2009)
[17]. Kusakunniran, W., Wu, Q., Zhang, J., Ma, Y., Li, H.: A new view-invariant featurefor cross-view gait recognition. IEEE Transactions on Information Forensics andSecurity 8(10), 1642–1653 (2013)
[26]. Makihara, Y., Sagawa, R., Mukaigawa, Y., Echigo, T., Yagi, Y.: Gait recognitionusing a view transformation model in the frequency domain. In: ECCV. pp. 151–163 (2006)
[37]. Wang, C., Zhang, J., Wang, L., Pu, J., Yuan, X.: Human identification using tem-poral information preserving gait template. TPAMI 34(11), 2164–2176 (2011)
[40]. Wolf, T., Babaee, M., Rigoll, G.: Multi-view gait recognition using 3d convolutionalneural networks. In: ICIP. pp. 4165–4169 (2016)
[41]. Wu, Z., Huang, Y., Wang, L., Wang, X., Tan, T.: A comprehensive study oncross-view gait based human identification with deep cnns. TPAMI 39(2), 209–226 (2016)
[46]. Zhang, Z., Tran, L., Yin, X., Atoum, Y., Liu, X., Wan, J., Wang, N.: Gait recog-nition via disentangled representation learning. In: CVPR. pp. 4710–4719 (2019)