4 AP3D for Video-based ReID
为了研究AP3D对基于视频的ReID的有效性,本文使用2D ConvNet (C2D)形式作为基线方法,并使用提出的AP3D将其扩展到AP3DConvNet。网络架构的细节在4.1 节中描述,然后损失函数在4.2节中介绍。
4.1 Network Architectures
C2D baseline. 使用在ImageNet上预训练的ResNet-50作为backbone,并去除 [28] 之后的stage5的下采样操作以丰富粒度。给定一个具有 T T T帧的输入视频剪辑,它输出一个形状为 T × H × W × 2048 T \times H \times W \times 2048 T×H×W×2048的张量。在空间最大池化和时间平均池化之后,产生一个2048维的特征。在输入分类器之前,使用BatchNorm操作对[13]之后的特征进行归一化。C2D基线不涉及任何时间操作,除了最终的时间平均池化。
AP3D ConvNet. 用AP3D残差块替换部分2D残差块,将C2D转换为AP3D ConvNet,用于时空特征学习。具体而言,在ResNet的一个阶段中替换一个、一半或所有残差块,结果在第5.4节中报告。
4.2 Objective Function
在 [30] 之后,将交叉熵损失和三元组损失结合起来进行时空表示学习。由于交叉熵损失主要优化角子空间[31]中的特征,为了保持一致性,使用余弦距离进行三重损失。
5 Experiments
5.1 Datasets and Evaluation Protocol
数据集。 在三个基于视频的 ReID 数据集上评估所提出的方法,即 MARS 、DukeMTMC-VideoReID和 iLIDS-VID。由于MARS和DukeMTMC-VideoReID具有固定的训练/测试划分,为了方便起见,主要对这两个数据集进行消融研究。此外,报告了 iLIDS-VID 的最终结果,以与最先进的技术进行比较。
评估协议。 使用CMC和mAP作为评估指标。
5.2 Implementation Details
Training. 在训练阶段,对于每个视频轨迹,随机抽取4帧,步长为8帧,形成一个视频片段。每批8人,每人4个视频剪辑。将所有视频帧调整为 256 × 128 256 \times128 256×128像素,并使用水平翻转来增强数据。对于优化器,采用了权重衰减为0.0005的Adam来更新参数。总共训练了240个epoch的模型。学习速率初始化为 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4每60个epoch后乘以0.1。
Testing. 在测试阶段,对于每个视频tracklet,首先将其分割为几个32帧的视频片段。然后提取每个视频片段的特征表示,最终的视频特征是所有视频片段的平均表示。特征提取后,计算查询和图库特征之间的余弦距离,并根据余弦距离执行检索。
5.3 Comparison with Related Approaches
AP3D vs. original 3D convolution. 为了验证所提出的 AP3D 的有效性和泛化能力,分别使用 AP3D 和原始 3D 卷积来实现 I3D 和 P3D 残差块。然后,在 C2D ConvNets 的 stage2 和 stage3 中每 2 个残差块用 3D 块替换 1 个 2D 块,总共替换 5 个残差块。如表 1 所示,与 C2D 基线相比,I3D 和 P3D 由于外观破坏而显示接近或更低的结果。通过 APM 对齐外观表示,相应的 AP3D 版本在两个数据集上显着且一致地提高了性能,几乎没有额外的参数和额外的计算复杂度。具体来说,AP3D 在 MARS 数据集上比 I3D 和 P3D 增加了大约 1% 的 top-1 和 2% 的 mAP。请注意,DukeMTMC-VideoReID 上的 mAP 改进不如 MARS 上的那么多。一种可能的解释是,DukeMTMC-VideoReID 数据集中视频样本的边界框是人工标注的,外观错位不太严重,因此 AP3D 的提升不是很显著。
表 1. AP3D 与原始 3D 卷积的比较
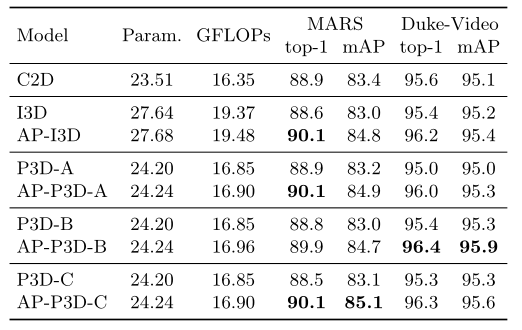
与其他方法相比,AP-P3D-C在大多数设置中表现最好。因此,如果没有特别说明,基于APP3D-C(简称AP3D)进行以下实验。
AP3D vs. Non-local. AP3D 中的 APM 和非局部 (NL) 都是基于图的方法。我们将相同的 5 个 NL 块插入到 C2D ConvNets 中,并将 AP3D 与表 2 中的 NL 进行比较。可以看出,AP3D 在两个数据集上的参数和计算复杂度都较低,性能均优于 NL。
表 2 与 NL 和其他时间信息建模方法的比较

为了更公平地进行比较,还实现了嵌入非局部 (CA-NL) 和 NL 和 P3D 的组合 (NL-P3D) 的对比注意。如表 2 所示,CA-NL 在 MARS 上取得了与 NL 相同的结果,但仍不如 AP3D。在 DukeMTMC-VideoReID 上,CA-NL 的 top-1 甚至低于 NL。 APM 中的 Contrastive Attention 更有可能是为了避免由于配准不完善而导致的错误传播。但是,NL 的本质是时空图上的图卷积,而不是图配准。所以NL不能与Contrastive Attention协同工作。此外,由于 P3D 无法处理基于视频的 ReID 中的外观错位,因此 NL-P3D 显示出与 NL 接近的结果,并且也不如 AP3D。通过 APM 对齐外观,NL-AP3D 实现了进一步的改进。该结果表明 AP3D 和 NL 是互补的。
AP3D vs. other methods for temporal information modeling. 还将 AP3D 与可变形 3D 卷积和CNN+LSTM进行了比较。为了公平比较,使用相同的backbone和超参数。如表 2 所示,AP3D 在两个数据集上都显着优于这两种方法。这种比较进一步证明了 AP3D 在学习时间线索方面的有效性。
5.4 Ablation Study
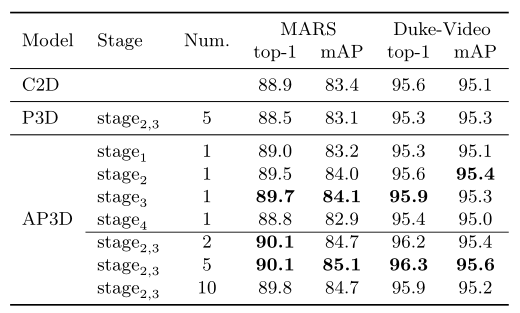
Effective positions to place AP3D blocks. 表 3 比较了 C2D ConvNet 不同阶段用 AP3D 块替换残差块的结果。在这些阶段的每一个中,倒数第二个残差块被替换为 AP3D 块。可以看出,在 stage2 和 stage3 中放置 AP3D 块的改进是相似的。特别是在stage2或stage3中仅放置一个AP3D块的结果超过了在stage2,3中放置5个P3D块的结果。但是,将 AP3D 块放置在 stage1 或 stage4 的结果比 C2D 基线差。很可能stage1中的低级特征不足以提供精确的语义信息,因此AP3D中的APM不能很好地对齐外观表示。相比之下,stage4中的特征不足以提供精确的空间信息,因此外观对齐的改进也有限。因此,只考虑替换stage2和stage3中的残差块。
How many blocks should be replaced by AP3D? 表 3 还显示了更多 AP3D 块的结果。我们研究在 C2D ConvNet 中替换 2 个块(每个阶段 1 个)、5 个块(stage2 和 stage3 中的一半残差块)和 10 个块(stage2 和 stage3 中的所有残差块)。可以看出,更多的 AP3D 块通常会带来更高的性能。更多的 AP3D 块可以执行更多的时间通信,这很难通过 C2D 模型实现。对于 10 个块的结果,性能下降可能在于参数过多导致的过度拟合。
表 3 用 AP3D 块替换不同阶段不同数量的残差块的结果
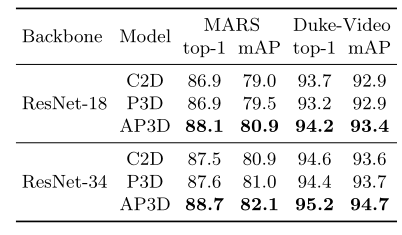
Effectiveness of AP3D across different backbones. 还研究了 AP3D 在不同backbone上的有效性和泛化能力。具体来说,用 AP3D 块替换了 ResNet-18 和 ResNet-34 的 stage2、3 中的一半残差块。如表 4 所示,AP3D 可以在两个数据集上显着且一致地改进这两种架构的结果。特别是,AP3D-ResNet-18 在 MARS 数据集上优于其 ResNet-18 对应物(C2D 和 P3D)和更深的 ResNet-34,该模型的参数数量和计算复杂度几乎翻了一番。这一比较表明,AP3D 的有效性不依赖于额外的参数和计算负载。
表 4. 不同backbone的结果
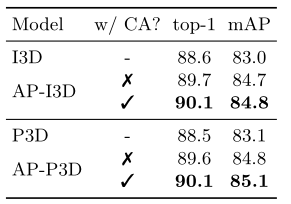
The effectiveness of Contrastive Attention. 如第 3.2 节所述,使用对比注意来避免由不对称外观信息引起的不完美配准的错误传播。为了验证有效性,我们在有/没有对比注意(CA)的情况下重现了 AP3D,在行人检测器生成的数据集 MARS 上的实验结果如表 5 所示。可以看出,在没有对比注意的情况下,AP-I3D 和AP-P3D 仍然可以大幅提高 I3D 和 P3D 基线的性能。在重建的特征图上应用对比注意,可以进一步提高 AP-I3D 和 AP-P3D 的结果。
表 5. 有/无 CA 的 AP3D 在 MARS 上的结果
The influence of the scale factor s. 如 3.2 节所述,比例因子 s 越大,相似度高的像素的权重就越高。在图 6 中展示了 MARS 数据集上不同 s 的实验结果。可以看出,具有不同比例因子的 AP3D 在基线上持续改进,并且当 s = 4 时达到最佳性能。
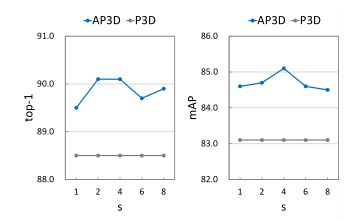
图 6 MARS 数据集上不同 s 的结果
5.5 Visualization
选择一些未对齐的样本,并在图7中APM后的stage3可视化原始特征图和重建的特征图。可以看出,在APM之前,中心特征图和相邻特征图的高亮区域主要集中在各自的前景上,并且没有对齐。APM后,重构特征图的高亮区域与相应中心帧的前景对齐。这可以进一步验证APM的对准机制。

图7。APM后原始和重建特征图的可视化
5.6 Comparison with State-of-the-Art Methods
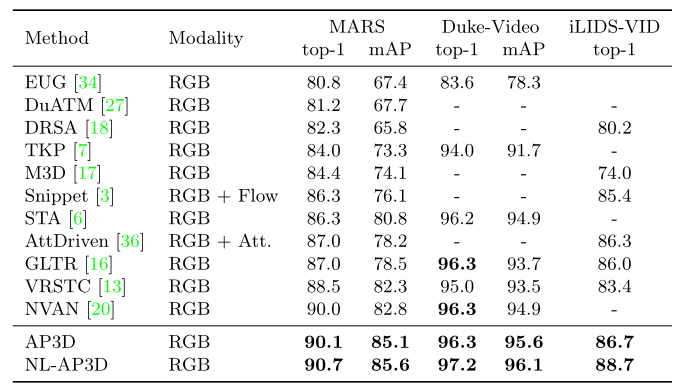
将提出的方法与最先进的基于视频的 ReID 方法进行比较,这些方法在 MARS、DukeMTMC-VideoReID 和 iLIDS-VID 数据集上使用相同的backbone。结果总结在表 6 中。请注意,这些比较方法在许多方面有所不同,例如,使用来自不同模式的信息。然而,仅使用 RGB 和简单的特征集成策略(即时间平均池化),所提出的 AP3D 在这三个数据集上始终超过所有这些方法。特别是,AP3D 在 MARS 数据集上实现了 85.1% 的 mAP。当与 Non-local 结合使用时,可以获得进一步的改进。
表 6. 与 MARS、DukeMTMC-VideoReID 和 iLIDS-VID 数据集上的最新技术的比较。 “Flow”表示光流,“Att.”表示属性
6 Conclusion
在本文中,我们提出了一种新颖的基于视频的 ReID 的 AP3D 方法。 AP3D 由 APM 和 3D 卷积核组成。通过 APM 保证相邻特征图之间的外观对齐,接下来的 3D 卷积可以在保持外观表示质量的前提下对时间信息进行建模。通过这种方式,提出的 AP3D 解决了原始 3D 卷积的外观破坏问题。很容易将 AP3D 与现有的 3D ConvNet 结合起来。大量实验验证了 AP3D 的有效性和泛化能力,在三个广泛使用的数据集上超越了最先进的方法。作为未来的工作,我们将扩展 AP3D,使其成为深度神经网络中用于各种基于视频的识别任务的基本操作。
参考文献
[13.] Hou, R., Ma, B., Chang, H., Gu, X., Shan, S., Chen, X.: Vrstc: Occlusion-free video person re-identification. In: CVPR (2019) 1, 5, 8, 9, 14
[28.] Sun, Y., Zheng, L., Yang, Y., Tian, Q., Wang, S.: Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In: ECCV (2018) 1, 8
[30.] Wang, G., Yuan, Y., Chen, X., Li, J., Zhou, X.: Learning discriminative features with multiple granularities for person re-identification. In: ACM MM (2018) 9
[31.] Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z., Liu, W.: Cosface: Large margin cosine loss for deep face recognition. In: CVPR (2018) 9