3 Appearance-Preserving 3D Convolution
本节首先说明所提出的AP3D的总体框架。然后,解释核心模块的细节,即外观保持模块(APM),并进行讨论。最后,介绍如何将AP3D与现有的3D ConvNets相结合。
3.1 The Framework
3D 卷积广泛用于视频分类任务并实现了最先进的性能。最近,一些研究人员将其引入基于视频的ReID。然而,他们忽略了ReID任务的性能高度依赖于外观表示,而不是运动表示。由于不完美的检测结果或姿势变化,在基于视频的ReID样本中,外观错位是不可避免的。在这种情况下,现有的3D卷积在整个相邻帧之间处理相同的空间位置,可能会破坏人物视频的外观表示,因此它们对ReID是有害的。
本文中提出了一种新的AP3D方法来解决上述问题。提出的AP3D由一个APM和一个后续的3D卷积组成。具有 3 × 3 × 3 3 \times 3 \times 3 3×3×3卷积核的AP3D示例如图2所示。具体来说,给定一个具有 T T T帧的输入张量,每个帧都被视为中心帧。首先为每帧采样两个邻居,并在填充零后总共获得 2 T 2 T 2T个相邻特征图。其次,APM用于重建每个相邻的特征图,以保证外观与相应的中心特征图对齐。然后,将重建的相邻特征图和原始输入特征图整合形成一个临时张量。最后,执行步长为 ( 3 , 1 , 1 ) (3,1,1) (3,1,1)的 3 × 3 × 3 3 \times 3 \times 3 3×3×3卷积,可以生成具有 T T T帧的输出张量。在APM保证外观对齐的情况下,后面的3D卷积可以在不破坏外观的情况下对时间关系进行建模。APM的详细信息将在下一小节中介绍。

图 2. 提出的 AP3D 的总体框架。输入张量的每个特征图被认为是中心特征图,其两个邻居被采样为相应的相邻特征图。APM用于重建相邻特征图,以保证相对于相应中心特征图的外观对齐。然后进行下面的3D卷积。注意,3D卷积核的时间步长设置为其时间核大小。在这种情况下,输出张量的形状与输入张量的形状相同
3.2 Appearance-Preserving Module
特征图注册。 APM的目标是重建每个相邻的特征图,以保证重建的和对应的中心特征图上的相同空间位置属于同一身体部位。它可以被认为是每两个特征图之间的图匹配或注册任务。一方面,由于人体是一个非刚性物体,简单的仿射变换无法实现这一目标。另一方面,现有的基于视频的ReID数据集没有额外的对应标注。因此,注册过程并不是那么简单。
注意到来自ConvNet的中级特征包含一些语义信息。一般来说,具有相同外观的特征具有较高的余弦相似度,而具有不同外观的特征具有较低的余弦相似度。如图3所示,红叉表示中心(图3(a))和相邻(图3(b))框架上的相同位置,但它们属于不同的身体部位。计算中心特征图上标记位置与相邻特征图上所有位置之间的跨像素余弦相似度。归一化后,相似性分布在图 3 © (s = 1) 中可视化。可以看出,外观相同的区域被突出显示。因此,在本文中,根据跨像素相似度来定位相邻帧中的相应位置,以实现特征图配准。

图 3. (a) 中心帧、(b) 其相邻帧和 © 在相邻特征图上具有不同比例因子 s 的相似度分布的可视化。在合理的 s s s下,APM 可以根据中心框上的标记位置准确定位相邻特征图上的相应区域
由于相邻特征图上同一身体部位的尺度可能不同,因此中心特征图上的一个位置可能在其相邻特征图上有几个对应的像素,反之亦然。因此,仅用原始相邻特征图上最相似的位置填充重建特征图上的对应位置是不准确的。为了包含具有相同外观的所有像素,将重建的相邻特征图上每个位置的响应 y i y_{i} yi计算为原始相邻特征图上所有位置的特征 x j x_{j} xj的加权和:
y i = ∑ j e f ( c i , x j ) x j ∑ j e f ( c i , x j ) y_{i}=\sum_{j} \frac{e^{f\left(c_{i}, x_{j}\right)} x_{j}}{\sum_{j} e^{f\left(c_{i}, x_{j}\right)}} yi=j∑∑jef(ci,xj)ef(ci,xj)xj
其中 c i c_{i} ci是中心特征图上与 y i y_{i} yi具有相同空间位置的特征, f ( c i , x j ) f\left(c_{i}, x_{j}\right) f(ci,xj)定义为 c i c_{i} ci和 x j x_{j} xj之间的余弦相似度,比例因子 s > 0 s>0 s>0:
f ( c i , x j ) = s g ( c i ) ⋅ g ( x j ) ∥ g ( c i ) ∥ ∥ g ( x j ) ∥ f\left(c_{i}, x_{j}\right)=s \frac{g\left(c_{i}\right) \cdot g\left(x_{j}\right)}{\left\|g\left(c_{i}\right)\right\|\left\|g\left(x_{j}\right)\right\|} f(ci,xj)=s∥g(ci)∥∥g(xj)∥g(ci)⋅g(xj)
其中 g ( ⋅ ) g(\cdot) g(⋅)是将特征映射到低维空间的线性变换。比例因子 s s s用于调整余弦相似度的范围。并且一个大的 s s s可以使相对高的相似度更高,而相对低的相似度更低。如图 3(c)所示,在合理的比例因子 s s s下,APM 可以精确定位相邻特征图上的对应区域。本文比例因子设置为4。
对比注意力。 由于行人检测的误差,一些回归边界框小于ground truth,因此一些身体部位可能会在相邻帧中丢失(见图1(a))。在这种情况下,相邻的特征图不能与中心特征图完美对齐。为了避免不完美的配准引起的错误传播,提出了对比注意力来寻找重建和中心特征图之间的不匹配区域。然后,将学习到的注意力掩码施加到重建的特征图上。重建特征图上每个位置的最终响应 z i z_{i} zi定义为:
z i = ContrastiveAtt ( c i , y i ) y i z_{i}=\text { ContrastiveAtt }\left(c_{i}, y_{i}\right) y_{i} zi= ContrastiveAtt (ci,yi)yi
这里 ContrastiveAtt ( c i , y i ) \operatorname{ContrastiveAtt}\left(c_{i}, y_{i}\right) ContrastiveAtt(ci,yi)根据 c i c_{i} ci和 y i y_{i} yi之间的语义相似性在 [ 0 , 1 ] [0,1] [0,1]中产生一个注意力值:
ContrastiveAtt ( c i , y i ) = sigmoid ( w T ( θ ( c i ) ⊙ ϕ ( y i ) ) ) \text{ContrastiveAtt} \left(c_{i}, y_{i}\right)=\operatorname{sigmoid}\left(w^{T}\left(\theta\left(c_{i}\right) \odot \phi\left(y_{i}\right)\right)\right) ContrastiveAtt(ci,yi)=sigmoid(wT(θ(ci)⊙ϕ(yi)))
其中 w w w是通过 1 × 1 1 \times 1 1×1卷积实现的可学习权重向量,而 ⊙ \odot ⊙是哈达玛c乘积。由于 c i c_{i} ci和 y i y_{i} yi分别来自中心和重建的特征图,使用两个非对称映射函数 θ ( ⋅ ) \theta(\cdot) θ(⋅)和 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)将 c i c_{i} ci和 y i y_{i} yi映射到共享的低维语义空间。

APM的配准和对比注意力如图4所示。所有三个语义映射,即 g g g, θ \theta θ和 ϕ \phi ϕ,都由 1 × 1 1 \times 1 1×1卷积层实现。为了减少计算量,这些卷积层的输出通道设置为 C / 16 C / 16 C/16。
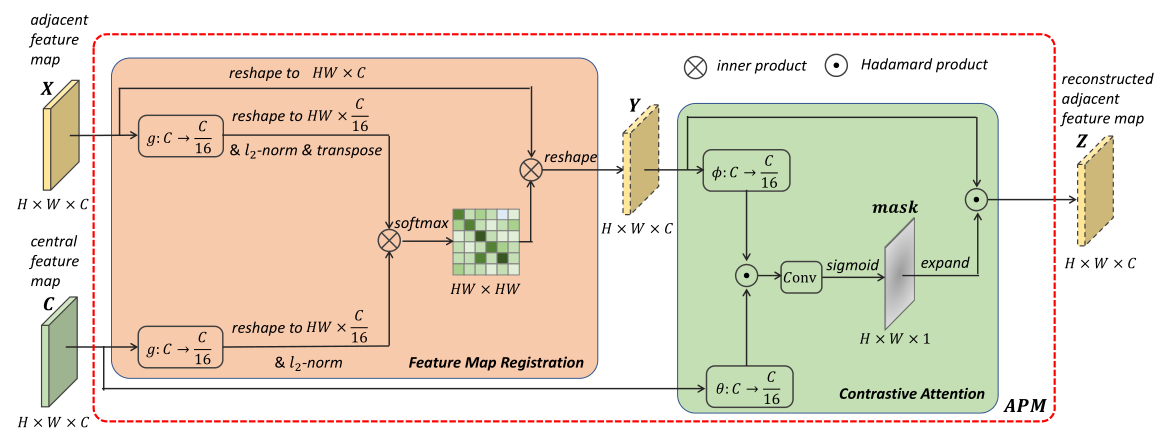
图4. APM的图示。首先通过特征图的配准来重建相邻的特征图。然后将Contrastive Attention mask与重建的feature map相乘,以避免由于配准不完善而导致的错误传播。
3.3 Discussion
APM 和Non-local之间的关系。 APM和Non-local(NL)操作可以看作是两个图神经网络模块。两个模块都将特征图上每个位置的特征视为图中的一个节点,并使用加权和来估计特征。但是它们有很多不同之处:
\quad \quad (a)NL旨在使用时空信息来增强特征,其本质是图卷积或时空图上的自注意力。而APM的目的是重建相邻的feature map,避免后续的3D Conv破坏外观。其本质是两个空间图之间的图匹配或配准。
\quad \quad (b)NL中加权和中的权重仅用于建立每对节点之间的依赖关系,没有特定含义。相比之下,APM 使用具有合理比例因子的余弦相似度来定义权重,以便准确地找到相邻特征图上具有相同外观的位置(见图 3)。
\quad \quad ©APM之后,图2中的集成特征图仍然可以保持时空相对关系,由后面的3D Conv编码,而NL不能。
\quad \quad (d)给定一个 N N N帧的时空图,NL的计算复杂度为 O ( N 2 ) O(N^2) O(N2),而APM的计算复杂度仅为 O ( N ) O(N) O(N),远低于NL。
对比注意力和空间注意力之间的关系。 APM中的Contrastive Attention旨在找到两帧之间的不匹配区域,以避免由于不完美的配准导致的错误传播,而ReID中广泛使用的空间注意力旨在为每一帧定位更多的判别区域。至于公式化,Contrastive Attention 将两个特征图作为输入并施加在重建的特征图上,而 Spatial Attention 将一个特征图作为输入并施加在自身上。
3.4 Combining AP3D with I3D and P3D Blocks
为了利用成功的 3D ConvNet 设计,我们将提出的AP3D与I3D和P3D残差块相结合。将I3D和P3D Residual块转移到其AP3D版本只需将原始时间卷积核替换为具有相同内核大小的 AP3D。残差块的 C2D、AP-I3D 和 AP-P3D 版本如图 5 所示。
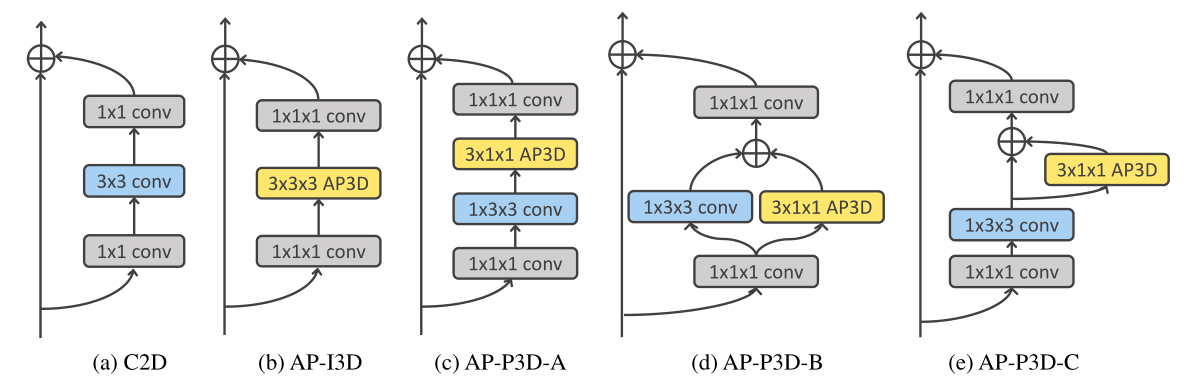
图 5. 残差块的 C2D、AP-I3D 和 AP-P3D 版本。至于 AP-I3D 和 AP-P3D Residual blocks,只有原始的时间卷积核被 AP3Ds 替换