1 批量归一化理论
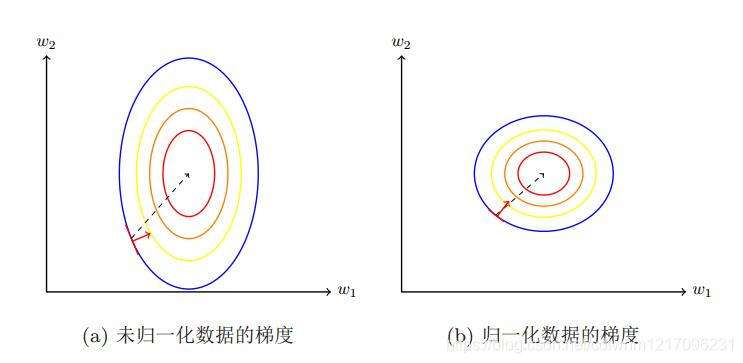
1.1 批量归一化原理


1.2 批量归一化定义
将每一层运算出来的数据归一化成均值为0、方差为1的标准高斯分布。这样就会在保留样本的分布特征,又消除了层与层间的分布差异。
在实际应用中,批量归一化的收敛非常快,并且具有很强的泛化能力,某种情况下可以完全代替前面讲过的正则化、Dropout。

在训练过程中,会通过优化器的反向求导来优化出合适的r,β值。BN层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证过程中,会使用训练求得的均值和方差对验证数据做归一化处理。
1.3 批量归一化实现
- BatchNorm1d:对二维或三维的线性数据进行批量归一化处理,输入形然是[N,D]或者[D,N,L](N代表批次数,D代表数据的个数,L代表数据的长度)。
- BatchNorm2d:对二维的平面数据进行批量归一化处理,输入形然是以[N,C,H,W](N代表批次数,C代表通道数,H代表亮度,W代表宽度)。
- BatchNorm3d:对三维的立体数据进行批量归一化处理,输入形状是[N,C,D,H,W](N代表批次数,C代表通道数,D代表深度,H代表高度,W代表宽度)。
2 批量归一化实操
torch.nn.BatchNormld(num_features,eps=1e-05,momentum=0.1,affine=True,trackrunning_stats=True)其中的参数含义如下。
- num features:待处理的输入数据的特征数,该值需要手动计算,如果输入数据的形状是[N,D](N代表批次数,D代表数据的个数),那么该值为D。如果是在BatchNorm2d中,那么该参数要填入图片的通道数。
- s:默认值为1e-5。为保证数值稳定性(分母不取0),给分母加上值,即给式(7-11)中的σ加上eps。
- momentum:动态均值和动态方差使用的动量,默认值为0.1。
- affine:是否使用自适应模式。如果参数值设置为True,那么使用自适应模式,系统将自动对式(7-11)中的r、β值进行优化学习;如果参数值设置为Flase,那么不使用自适应模型,相当于将式(7-11)中的r、β去掉。
- track_running stats:是否跟踪当前批次数据的统计特性。在训练过程中,如果参数值设置为False,那么系统只使用当前批次数据的均值和方差;如果参数值设置为True,那么系统将跟踪每批次输入的数据并实时更新整个数据集的均值和方差。(在使用过程中,该参数值一般设置为True,表示系统将使用训练时的均值和方差。)

3 批量归一化函数的手动代码实现
3.0 使用批量归一化方法的注意事项
- 1、批量归一化方法不能紧跟在Dropout,层后面使用若有这种情况,Dropout层的结果会改变批量归一化所计算的数据分布,导致批量归一化后的偏差更大。
- 2、在批量归一化方法与Switch激活函数一起使用时,需要对Switch激活函数进行权值缩放(可以使用缩放参数自学习的方法),否侧则会引起更大的抖动。
- 3、批量归一化方法对拟次依赖严重,即对于较小批次,效果并不理想。因为批量归一化侧重的是对批次样本的归一化,当输入批次较小时,个体样本将无法代替批次样本的特征,导致模型抖动,难以收敛。
- 4、批量归一化方法适用深层网络。因为在浅层网络中,内部协变量转移问题并不明显,所以批量归一化的效果也不明显。
3.1 使用接口调用方式实现批量归一化计算
实例描述:以二维的平面数据为例,调用BN接口对一组数据执行批量归一化算法,并将该计算结果与手动方式计算的结果进行比较。
import torch
import torch.nn as nn
# 1.1 使用接口调用的方式实现批量归一化计算
data = torch.randn(2,2,2,1) # 定义一个形状为[2,2,2,1]的模拟数据,批次中的样本数为2,每个样本的通道数为2,高和宽分别为2和1。
print(data) # 输出模拟数据
# 实例化BatchNorm2d接口,并调用该实例化对象对模拟数据进行批量归一化计算。
obn = nn.BatchNorm2d(2,affine=True) # 实例化自适应BN对象
print(obn.weight) # 输出自适应参数 r
print(obn.bias) # 输出自适应参数β
print(obn.eps) # 输出BN中的eps
output = obn(data) # 计算BN
print(output,output.size()) # 输出BN结果及形状# 两个模拟样本数据,每个样本都有两个通道
tensor([[[[-1.3640], [ 0.7662]],[[ 1.0771], [ 0.4655]]],
[[[-1.4258], [ 1.0477]],[[-0.1646],[ 1.6063]]]])# 自适应参数
Parameter containing:tensor([1., 1.], requires_grad=True)
Parameter containing:tensor([0., 0.], requires_grad=True)
1e-05# 批量归一化结果及形状===》仅改变输入数据的值,没有修改输入数据的形状
tensor([[[[-0.9694],[ 0.8743]], [[ 0.4994],[-0.4232]]],
[[[-1.0228], [ 1.1179]], [[-1.3738], [ 1.2977]]]],grad_fn=<NativeBatchNormBackward0>) torch.Size([2, 2, 2, 1])
3.2 使用手动方式实现归一化计算
3.2.1 方差计算与贝塞尔校正
- 方差的计算方法是先将每个值减去均值的结果后再求平方,并求它们的均值(求和后除以总数量)。
- 贝塞尔校正(Bessel's Correction)是一个与统计学的方差和标准差相关的修正方法,是指在计算提示样本的方差和标准差时,将分母中的n替换成n-1。这种修正方法得到的方差和标准差更近似于当前样本所在的总体集合中的方差和标准差。
3.2.2 归一化实验
为了使手动计算批量归一化的步骤更加清晰,这里只对模拟数据中第一个样本中的第一个具体数据进行手动批量归一化计算,具体步骤如下:
- (1)取出模拟数据中两个样本的第一个通道数据;
- (2)用手动的方式计算该数据均值和方差;
- (3)将均值和方差代入式(7-11),对模拟数据中第一个样本中的第一个具体数据进行计算,具体代码如下。
mport torch
# 1.2 使用手动方式实现批量归一化计算
print("第1通道的数据",data[:,0])
# 计算第1通道数据的平均值与方差
Mean = torch.Tensor.mean(data[:,0])
Var = torch.Tensor.var(data[:,0],False)
print("均值",Mean)
print("方差",Var)
# 计算第1通道中第一个数据的BN结果
batchnorm = ((data[0][0][0][0] - Mean)/(torch.pow(Var,0.5)+obn.eps)) * obn.weight[0]+obn.bias[0]
print("BN结果",batchnorm)输出:
第1通道的数据 tensor([[[-1.3640],[ 0.7662]], [[-1.4258], [1.0477]]])
均值 tensor(-0.2440)
方差 tensor(1.3350)
BN结果 tensor(-0.9694, grad_fn=<AddBackward0>)
4 通过批量归一化方法改善模型的过拟合状况
修改第1篇文章中的# 2 搭建网络模型部分
# 2 搭建网络模型
# model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
# 修改为
class Logic_Dropout_Net(LogicNet):
def __init__(self,inputdim,hiddendim,outputdim):
super(Logic_Dropout_Net, self).__init__(hiddendim=hiddendim)
def forward(self,x):
x = self.Linear1(x)
x = torch.tanh(x)
x = self.BN(x)
x = self.Linear2(x)
return x
model = Logic_Dropout_Net(inputdim=2,hiddendim=500,outputdim=2) # 初始化模型
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。
# 3 训练模型+训练过程loss可视化
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
epochs = 200 # 定义迭代次数
losses = [] # 损失值列表4.2 批量归一化方法改善模型---代码总览
Over_fitting_Batch normalization.py
# 2 搭建网络模型
# model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
# 修改为
class Logic_Dropout_Net(LogicNet):
def __init__(self,inputdim,hiddendim,outputdim): # 初始化网络结构
super(Logic_Dropout_Net, self).__init__(inputdim,hiddendim,outputdim)
self.BN = nn.BatchNorm1d(hiddendim) # 定义BN层
def forward(self,x): # 搭建两个全连接层组成的网络模型
x = self.Linear1(x) # 将输入数据传入第1层
x = torch.tanh(x) # 对第1层的结果进行非线性变换
x = self.BN(x) # 对第1层的数据做BN处理
x = self.Linear2(x) # 将数据传入第2层
return x
model = Logic_Dropout_Net(inputdim=2,hiddendim=500,outputdim=2) # 初始化模型
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。
# 3 训练模型+训练过程loss可视化
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
epochs = 200 # 定义迭代次数
# 带有批量归一化处理的模型比带有Dropout处理的模型需要更少的训练次教。因为Dropout每次都会使一部分节点不参与运算,相当于减少了单次的样本处理量,所以带有Dropout处理的模型需要更多的训练次数才可以使模型收敛。
losses = [] # 损失值列表LogicNet_fun.py
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
from LogicNet_fun import LogicNet,moving_average,predict,plot_decision_boundary
# 1 构建数据集
np.random.seed(0) # 设置随机数种子
X , Y =sklearn.datasets.make_moons(40,noise=0.2) # 生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) # 获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) # 获取第2组数据索引
# 显示数据
plt.title("train moons data")
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label = 'data1')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label = 'data2')
plt.legend()
plt.show()
# 2 搭建网络模型
# model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
# 修改为
class Logic_Dropout_Net(LogicNet):
def __init__(self,inputdim,hiddendim,outputdim): # 初始化网络结构
super(Logic_Dropout_Net, self).__init__(inputdim,hiddendim,outputdim)
self.BN = nn.BatchNorm1d(hiddendim) # 定义BN层
def forward(self,x): # 搭建两个全连接层组成的网络模型
x = self.Linear1(x) # 将输入数据传入第1层
x = torch.tanh(x) # 对第1层的结果进行非线性变换
x = self.BN(x) # 对第1层的数据做BN处理
x = self.Linear2(x) # 将数据传入第2层
return x
model = Logic_Dropout_Net(inputdim=2,hiddendim=500,outputdim=2) # 初始化模型
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。
# 3 训练模型+训练过程loss可视化
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
epochs = 200 # 定义迭代次数
# 带有批量归一化处理的模型比带有Dropout处理的模型需要更少的训练次教。因为Dropout每次都会使一部分节点不参与运算,相当于减少了单次的样本处理量,所以带有Dropout处理的模型需要更多的训练次数才可以使模型收敛。
losses = [] # 损失值列表
for i in range(epochs):
loss = model.getloss(xt,yt)
losses.append(loss.item()) # 保存损失值中间状态
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播损失值
optimizer.step() # 更新参数
avgloss = moving_average(losses) # 获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()
# 4 模型结果可视化,观察过拟合现象
plot_decision_boundary(lambda x: predict(model,x),X,Y)
from sklearn.metrics import accuracy_score
print("训练时的准确率",accuracy_score(model.predict(xt),yt))
# 重新生成两组半圆数据
Xtest,Ytest = sklearn.datasets.make_moons(80,noise=0.2)
plot_decision_boundary(lambda x: predict(model,x),Xtest,Ytest)
Xtest_t = torch.from_numpy(Xtest).type(torch.FloatTensor) # 将numpy数据转化为张量
Ytest_t = torch.from_numpy(Ytest).type(torch.LongTensor)
print("测试时准确率",accuracy_score(model.predict(Xtest_t),Ytest_t))4.3 小结
批量归一化更擅长解决深层网络的内部协变量转移问题,在深层网路中,才会体现出更好的性能。
5 扩展:多种批量归一化算法介绍
- 在小批次样本情况下,可以使用与批次无关的renorm方法进行批量归一化;
- 在RNN模型中,可以使用Layer Normalization算法;
- 在对抗神经网络中,可以使用Instance Normalization算法
- Switchable Normalization算法,它可以将多种批量归一化算法融合并赋予可以学习的权重,在使用时,通过模型训练的方法来自动学习。