学习笔记|Pytorch使用教程36
本学习笔记主要摘自“深度之眼”,做一个总结,方便查阅。
使用Pytorch版本为1.2
- 循环神经网络(RNN) 是什么?
- RNN如处理成不定长输入?
- 训练RNN实现人名分类
- 总结
一.循环神经网络(RNN) 是什么?
RNN :
循环神经网络
- 处理不定长输入的模型
- 常用于NLP及时间序列任务(输入 数据具有前后关系)
- 网络结构
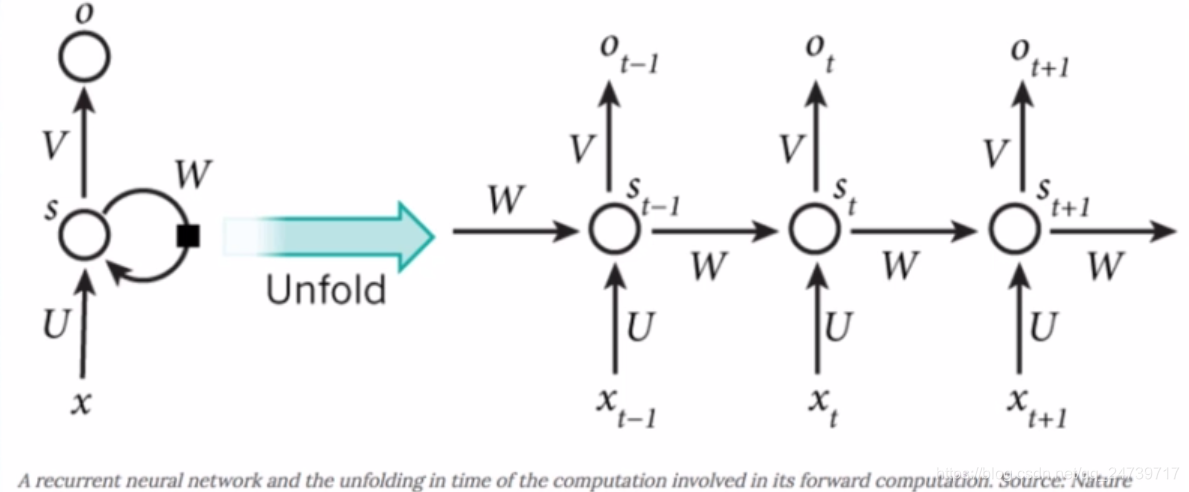
xt:时刻t的输入,shape = (1, 57)
st:时刻的状态值,shape=(1, 128)
ot:时刻的输出值,shape=(1, 18)
U: linear层的权重参数shape = (128, 57)
W: linear层的权重参数shape = (128, 128)
V: linear层的权重参数shape = (57, 128) - 公式:
- hidden state:隐藏层状态信息,记录过往时刻的信息
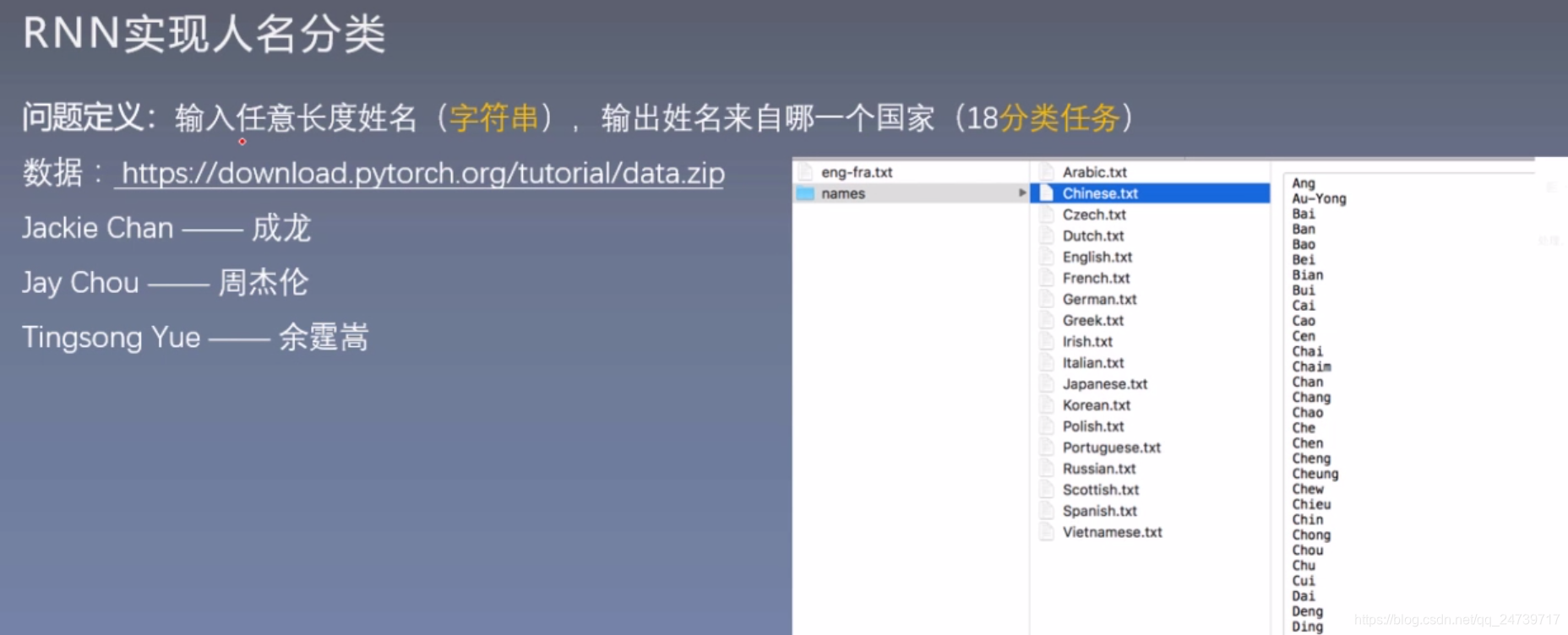
二.RNN如处理成不定长输入?
思考:计算机如何实现不定长字符串到分类向量的映射?
Chou (字符串)–> RNN --> Chinese (分类类别)
- 1.单个字符–>数字
- 2.数字–>model
- 3.下一个字符–>数字–>model
- 4.最后一个字符–>数字–>model–>分类向量
伪代码:
for stringin[C, h, 0, u]:
1. one-hot: string > [0, 0,...,1,...,0]
2. y,h = model([0, 0,...,1,...,0], h)
三.训练RNN实现人名分类
测试代码:
# -*- coding: utf-8 -*-
"""
# @file name : rnn_demo.py
# @author : TingsongYu https://github.com/TingsongYu
# @date : 2019-12-09
# @brief : rnn人名分类
"""
from io import open
import glob
import unicodedata
import string
import math
import os
import time
import torch.nn as nn
import torch
import random
import matplotlib.pyplot as plt
import torch.utils.data
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
# Read a file and split into lines
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters)
# Find letter index from all_letters, e.g. "a" = 0
def letterToIndex(letter):
return all_letters.find(letter)
# Just for demonstration, turn a letter into a <1 x n_letters> Tensor
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
# Turn a line into a <line_length x 1 x n_letters>,
# or an array of one-hot letter vectors
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
def categoryFromOutput(output):
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
def randomTrainingExample():
category = randomChoice(all_categories) # 选类别
line = randomChoice(category_lines[category]) # 选一个样本
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line) # str to one-hot
return category, line, category_tensor, line_tensor
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
# Just return an output given a line
def evaluate(line_tensor):
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
def predict(input_line, n_predictions=3):
print('\n> %s' % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
# Get top N categories
topv, topi = output.topk(n_predictions, 1, True)
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print('(%.2f) %s' % (value, all_categories[category_index]))
def get_lr(iter, learning_rate):
lr_iter = learning_rate if iter < n_iters else learning_rate*0.1
return lr_iter
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.u = nn.Linear(input_size, hidden_size)
self.w = nn.Linear(hidden_size, hidden_size)
self.v = nn.Linear(hidden_size, output_size)
self.tanh = nn.Tanh()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, inputs, hidden):
u_x = self.u(inputs)
hidden = self.w(hidden)
hidden = self.tanh(hidden + u_x)
output = self.softmax(self.v(hidden))
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
def train(category_tensor, line_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
line_tensor = line_tensor.to(device)
hidden = hidden.to(device)
category_tensor = category_tensor.to(device)
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
loss = criterion(output, category_tensor)
loss.backward()
# Add parameters' gradients to their values, multiplied by learning rate
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item()
if __name__ == "__main__":
# config
path_txt = os.path.join(BASE_DIR, "..", "..", "data", "data", "names", "*.txt")
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters) # 52 + 5 字符总数
print_every = 5000
plot_every = 5000
learning_rate = 0.005
n_iters = 200000
# step 1 data
# Build the category_lines dictionary, a list of names per language
category_lines = {}
all_categories = []
for filename in glob.glob(path_txt):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
# step 2 model
n_hidden = 128
# rnn = RNN(n_letters, n_hidden, n_categories)
rnn = RNN(n_letters, n_hidden, n_categories)
rnn.to(device)
# step 3 loss
criterion = nn.NLLLoss()
# step 4 optimize by hand
# step 5 iteration
current_loss = 0
all_losses = []
start = time.time()
for iter in range(1, n_iters + 1):
# sample
category, line, category_tensor, line_tensor = randomTrainingExample()
# training
output, loss = train(category_tensor, line_tensor)
current_loss += loss
# Print iter number, loss, name and guess
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else '✗ (%s)' % category
print('Iter: {:<7} time: {:>8s} loss: {:.4f} name: {:>10s} pred: {:>8s} label: {:>8s}'.format(
iter, timeSince(start), loss, line, guess, correct))
# Add current loss avg to list of losses
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0
path_model = os.path.join(BASE_DIR, "rnn_state_dict.pkl")
torch.save(rnn.state_dict(), path_model)
plt.plot(all_losses)
plt.show()
predict('Yue Tingsong')
predict('Yue tingsong')
predict('yutingsong')
predict('test your name')
输出:
Iter: 5000 time: 0m 49s loss: 2.3396 name: Miura pred: Chinese label: ✗ (Japanese)
Iter: 10000 time: 1m 39s loss: 1.7987 name: Maurice pred: Irish label: ✓
Iter: 15000 time: 2m 28s loss: 1.2611 name: Donndubhan pred: Irish label: ✓
Iter: 20000 time: 3m 18s loss: 1.4118 name: Gomulka pred: Czech label: ✗ (Polish)
Iter: 25000 time: 4m 8s loss: 1.7964 name: Turchin pred: Irish label: ✗ (Russian)
Iter: 30000 time: 4m 57s loss: 2.3216 name: Maeda pred: Spanish label: ✗ (Japanese)
Iter: 35000 time: 5m 47s loss: 0.6394 name: Guo pred: Chinese label: ✓
Iter: 40000 time: 6m 37s loss: 0.2239 name: Nahas pred: Arabic label: ✓
Iter: 45000 time: 7m 26s loss: 7.1649 name: Li pred: Vietnamese label: ✗ (Russian)
Iter: 50000 time: 8m 16s loss: 1.6512 name: Petit pred: Czech label: ✗ (French)
Iter: 55000 time: 9m 6s loss: 0.4936 name: Melendez pred: Spanish label: ✓
Iter: 60000 time: 9m 56s loss: 1.4019 name: Kitchen pred: English label: ✓
Iter: 65000 time: 10m 46s loss: 0.2072 name: Mackay pred: Scottish label: ✓
Iter: 70000 time: 11m 36s loss: 1.7573 name: Bello pred: Italian label: ✗ (Spanish)
Iter: 75000 time: 12m 26s loss: 2.4545 name: Petersen pred: Dutch label: ✗ (English)
Iter: 80000 time: 13m 16s loss: 0.0200 name: Baigulov pred: Russian label: ✓
Iter: 85000 time: 14m 5s loss: 0.1932 name: Ly pred: Vietnamese label: ✓
Iter: 90000 time: 14m 55s loss: 0.3289 name: Mcintosh pred: Scottish label: ✓
Iter: 95000 time: 15m 45s loss: 0.1584 name: Winogrodzki pred: Polish label: ✓
Iter: 100000 time: 16m 35s loss: 0.0604 name: Grigorovich pred: Russian label: ✓
Iter: 105000 time: 17m 25s loss: 1.1374 name: Ryjih pred: English label: ✗ (Russian)
Iter: 110000 time: 18m 14s loss: 1.8075 name: Nieves pred: English label: ✗ (Spanish)
Iter: 115000 time: 19m 4s loss: 0.4302 name: Delgado pred: Portuguese label: ✓
Iter: 120000 time: 19m 54s loss: 0.4103 name: King pred: Scottish label: ✓
Iter: 125000 time: 20m 43s loss: 3.1607 name: Howarth pred: Czech label: ✗ (English)
Iter: 130000 time: 21m 33s loss: 0.0026 name: Avgerinos pred: Greek label: ✓
Iter: 135000 time: 22m 23s loss: 1.7262 name: Nagel pred: Arabic label: ✗ (Dutch)
Iter: 140000 time: 23m 12s loss: 0.1067 name: Niemec pred: Polish label: ✓
Iter: 145000 time: 24m 2s loss: 2.6254 name: Paredes pred: Portuguese label: ✗ (Spanish)
Iter: 150000 time: 24m 51s loss: 0.2924 name: Schuhmacher pred: German label: ✓
Iter: 155000 time: 25m 40s loss: 0.0050 name: O'Boyle pred: Irish label: ✓
Iter: 160000 time: 26m 30s loss: 0.0690 name: Gai pred: Chinese label: ✓
Iter: 165000 time: 27m 20s loss: 3.2686 name: Olenew pred: Dutch label: ✗ (Russian)
Iter: 170000 time: 28m 10s loss: 0.2106 name: Son pred: Korean label: ✓
Iter: 175000 time: 29m 0s loss: 0.0273 name: Gallchobhar pred: Irish label: ✓
Iter: 180000 time: 29m 50s loss: 0.1898 name: Pakulski pred: Polish label: ✓
Iter: 185000 time: 30m 40s loss: 0.0998 name: Gauk pred: Chinese label: ✓
Iter: 190000 time: 31m 30s loss: 0.2143 name: Sauvageon pred: French label: ✓
Iter: 195000 time: 32m 19s loss: 0.0265 name: Salib pred: Arabic label: ✓
Iter: 200000 time: 33m 9s loss: 0.0467 name: Zubizarreta pred: Spanish label: ✓
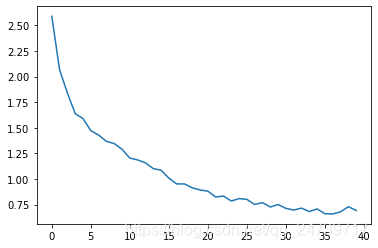
> Yue Tingsong
(-2.25) Russian
(-2.31) Polish
(-2.46) Greek
> Yue tingsong
(-2.26) Russian
(-2.33) Polish
(-2.50) Greek
> yutingsong
(-2.14) Russian
(-2.18) Polish
(-2.20) Greek
> test your name
(-2.61) Russian
(-2.65) Irish
(-2.68) Polish
四.总结
Q.使用pytorch框架解决一个项目时的通用模版
常用的文件夹:
- 1.data: data相关的定义脚本,如各种DataSet
- 2.models:各种网络模型的定义
- 3.log:训练日志存储路径
- 4.utils or tools:存放一些通用工具,例如set_seed, transform_invert
- 5.bins:运行的脚本,例如train.py, demo.py
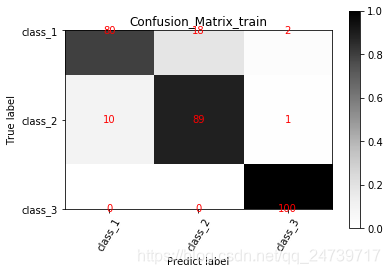
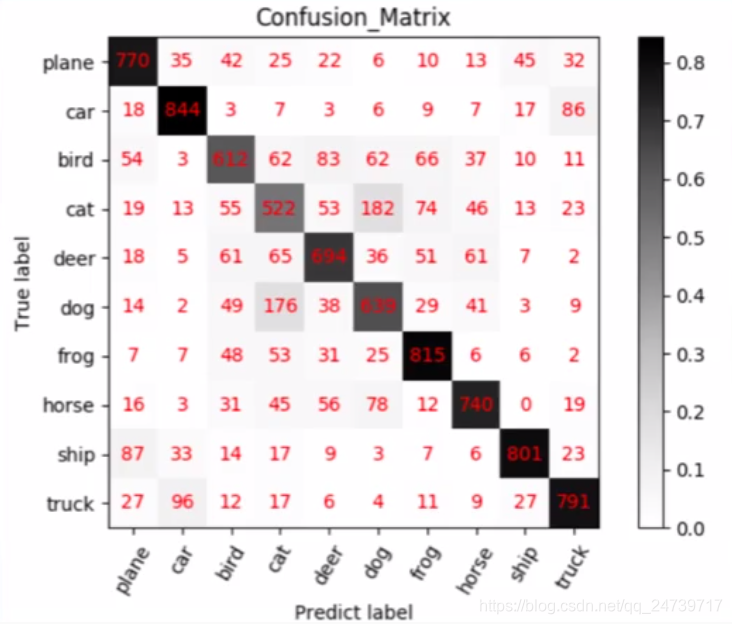
Q5.:混淆矩阵如何绘制
混淆矩阵(Confusion Matrix)常用来观察分类结果,是一个N* N的方阵,N表示类别数
- 行:真实类别,看召回率(Recall)
- 列:预测类别,看精确度(Precision)
- 对角线:看准确率(Acuuracy)
for i in range(len(labels)):
true_i = np.array(labels[i])
pre_i = np.array(predicted)
pre_i = np.array(predicted)
测试代码:
import numpy as np
import os
import matplotlib.pyplot as plt
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
def show_confMat(confusion_mat, classes_name, set_name, out_dir):
"""
可视化混淆矩阵,保存png格式
:param confusion_mat: nd-array
:param classes_name: list,各类别名称
:param set_name: str, eg: 'valid', 'train'
:param out_dir: str, png输出的文件夹
:return:
"""
# 归一化
confusion_mat_N = confusion_mat.copy()
for i in range(len(classes_name)):
confusion_mat_N[i, :] = confusion_mat[i, :] / confusion_mat[i, :].sum()
# 获取颜色
cmap = plt.cm.get_cmap('Greys') # 更多颜色: http://matplotlib.org/examples/color/colormaps_reference.html
plt.imshow(confusion_mat_N, cmap=cmap)
plt.colorbar()
# 设置文字
xlocations = np.array(range(len(classes_name)))
plt.xticks(xlocations, classes_name, rotation=60)
plt.yticks(xlocations, classes_name)
# plt.xlim(-0.5, 2.5)
# plt.ylim(-0.5, 2.5)
plt.xlabel('Predict label')
plt.ylabel('True label')
plt.title('Confusion_Matrix_' + set_name)
# 打印数字
for i in range(confusion_mat_N.shape[0]):
for j in range(confusion_mat_N.shape[1]):
plt.text(x=j, y=i, s=int(confusion_mat[i, j]), va='center', ha='center', color='red', fontsize=10)
# 保存
plt.show()
# plt.savefig(os.path.join(out_dir, 'Confusion_Matrix_' + set_name + '.png'))
# plt.close()
if __name__ == "__main__":
fake_confmat = np.array([[80, 18, 2], [10, 89, 1], [0, 0, 100]], dtype=float)
classes_name = ["class_1", "class_2", "class_3"]
show_confMat(fake_confmat, classes_name, 'train', out_dir=BASE_DIR)
输出: