论文名称:YOLOv4: Optimal Speed and Accuracy of Object Detection
论文下载地址:https://arxiv.org/abs/2004.10934
对应视频讲解:https://b23.tv/WLptQ7Q
文章目录
0 前言
YOLOv4是2020年Alexey Bochkovskiy等人发表在CVPR上的一篇文章,并不是Darknet的原始作者Joseph Redmon发表的,但这个工作已经被Joseph Redmon大佬认可了。之前我们有聊过YOLOv1~YOLOv3以及Ultralytics版的YOLOv3 SPP网络结构,如果不了解的可以参考之前的视频,YOLO系列网络详解。如果将YOLOv4和原始的YOLOv3相比效果确实有很大的提升,但和Ultralytics版的YOLOv3 SPP相比提升确实不大,但毕竟Ultralytics的YOLOv3 SPP以及YOLOv5都没有发表过正式的文章,所以不太好讲。所以今天还是先简单聊聊Alexey Bochkovskiy的YOLOv4。
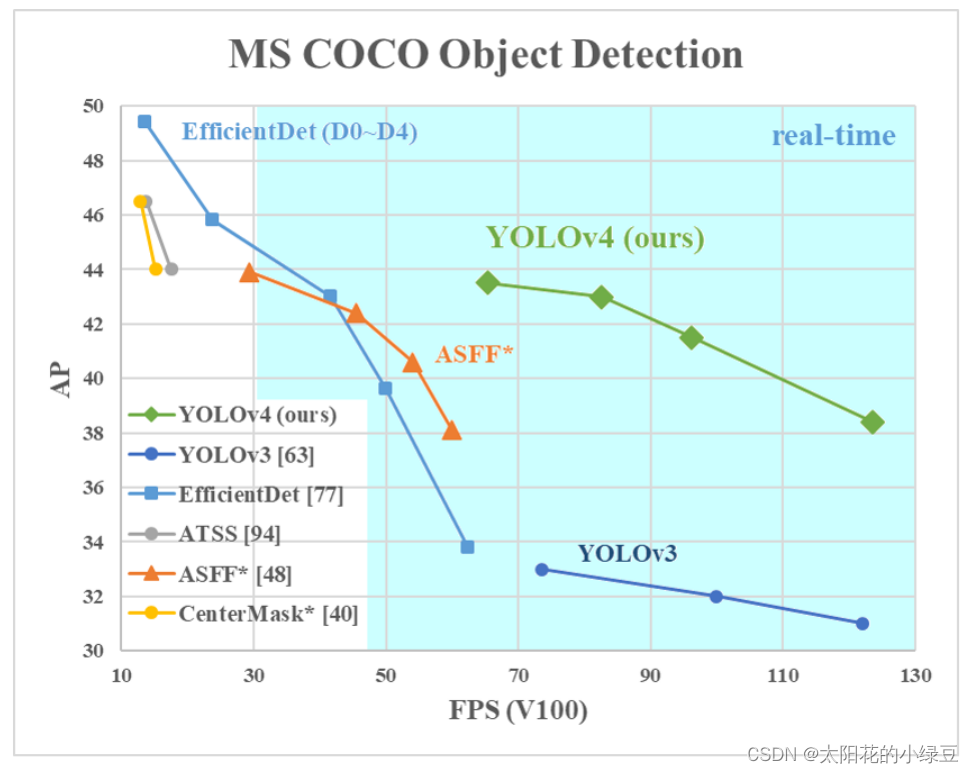
1 YOLOv4中的亮点
如果之前有阅读过YOLOv4这篇论文的小伙伴,你会发现作者就是把当年所有的常用技术罗列了一遍,然后做了一堆消融实验。实验过程及结果写的还是很详细的,但对我个人而言感觉有点杂乱,没能很好的突出重点。如果大家对实验不敢兴趣的话,直接从论文3.4章节往后看就行了。
1.1 网络结构
在论文3.4章节中介绍了YOLOv4网络的具体结构:
- Backbone:
CSPDarknet53 - Neck:
SPP,PAN - Head:
YOLOv3
相比之前的YOLOv3,改进了下Backbone,在Darknet53中引入了CSP模块(来自CSPNet)。在Neck部分,采用了SPP模块(Ultralytics版的YOLOv3 SPP就使用到了)以及PAN模块(来自PANet)。Head部分没变还是原来的检测头。
 关于
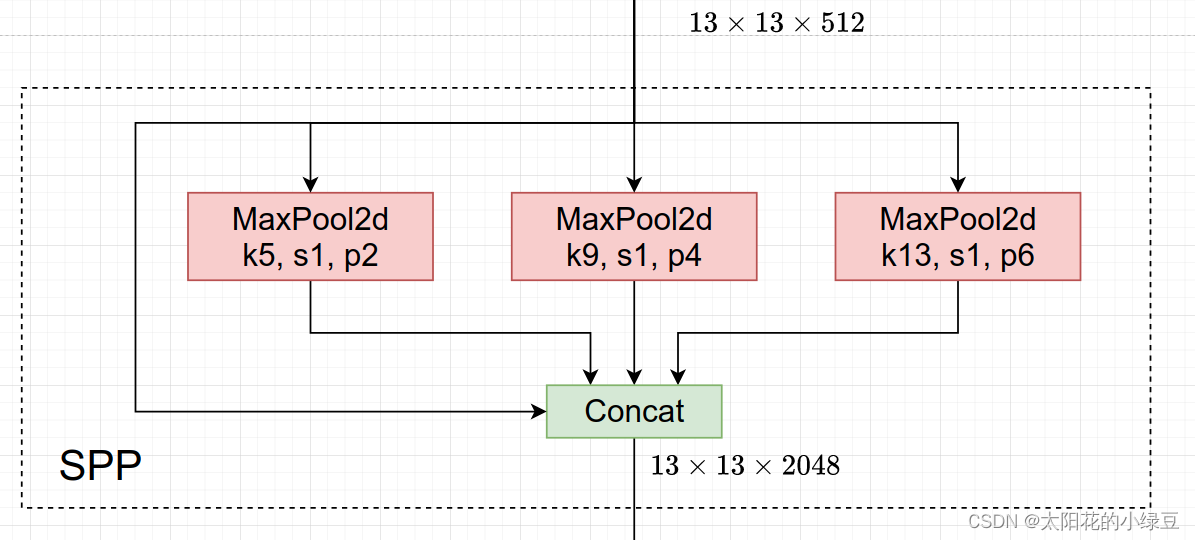
关于CSPDarnet53,后面有专门的章节讲解,这里暂时跳过。关于SPP(Spatial Pyramid Pooling)模块之前讲YOLO系列网络详解时详细介绍过,SPP就是将特征层分别通过一个池化核大小为5x5、9x9、13x13的最大池化层,然后在通道方向进行concat拼接在做进一步融合,这样能够在一定程度上解决目标多尺度问题,如下图所示。
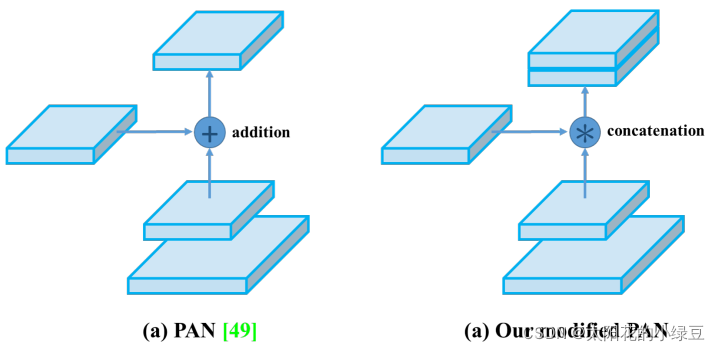
PAN(Path Aggregation Network)结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合,如下图(b)所示。

但YOLOv4的PAN结构和原始论文的融合方式又略有差异,如下图所示。图(a)是原始论文中的融合方式,即特征层之间融合时是直接通过相加的方式进行融合的,但在YOLOv4中是通过在通道方向Concat拼接的方式进行融合的。
1.2 优化策略
有关训练Backbone时采用的优化策略就不讲了有兴趣自己看下论文的4.2章节,这里直接讲下训练检测器时作者采用的一些方法。在论文4.3章节,作者也罗列了一堆方法,并做了部分消融实验。这里我只介绍确实在代码中有使用到的一些方法。
1.2.1 Eliminate grid sensitivity
在原来YOLOv3中,关于计算预测的目标中心坐标计算公式是:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y bx=σ(tx)+cxby=σ(ty)+cy
其中:
- t x t_x tx是网络预测的目标中心 x x x坐标偏移量(相对于网格的左上角)
- t y t_y ty是网络预测的目标中心 y y y坐标偏移量(相对于网格的左上角)
- c x c_x cx是对应网格左上角的 x x x坐标
- c y c_y cy是对应网格左上角的 y y y坐标
- σ \sigma σ是
sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域
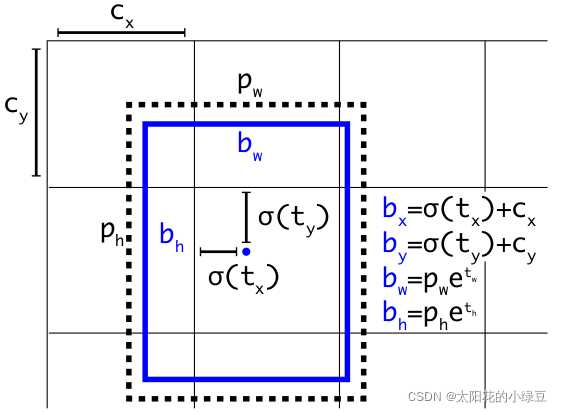
但在YOLOv4的论文中作者认为这样做不太合理,比如当真实目标中心点非常靠近网格的左上角点( σ ( t x ) \sigma(t_x) σ(tx)和 σ ( t y ) \sigma(t_y) σ(ty)应该趋近与0)或者右下角点( σ ( t x ) \sigma(t_x) σ(tx)和 σ ( t y ) \sigma(t_y) σ(ty)应该趋近与1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。为了解决这个问题,作者引入了一个大于1的缩放系数( s c a l e x y {\rm scale}_{xy} scalexy):
b x = ( σ ( t x ) ⋅ s c a l e x y − s c a l e x y − 1 2 ) + c x b y = ( σ ( t y ) ⋅ s c a l e x y − s c a l e x y − 1 2 ) + c y b_x = (\sigma(t_x) \cdot {\rm scale}_{xy} - \frac{
{\rm scale}_{xy}-1}{2}) + c_x \\ b_y = (\sigma(t_y) \cdot {\rm scale}_{xy} - \frac{
{\rm scale}_{xy}-1}{2})+ c_y bx=(σ(tx)⋅scalexy−2scalexy−1)+cxby=(σ(ty)⋅scalexy−2scalexy−1)+cy
通过引入这个系数,网络的预测值能够很容易达到0或者1,我看现在比较新的实现方法包括YOLOv5都将 s c a l e x y {\rm scale}_{xy} scalexy设置2,即:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) + c x b y = ( 2 ⋅ σ ( t y ) − 0.5 ) + c y b_x = (2 \cdot \sigma(t_x) - 0.5) + c_x \\ b_y = (2 \cdot \sigma(t_y) - 0.5) + c_y bx=(2⋅σ(tx)−0.5)+cxby=(2⋅σ(ty)−0.5)+cy
下面是我绘制的 y = σ ( x ) y = \sigma(x) y=σ(x)对应sigma曲线和 y = 2 ⋅ σ ( x ) − 0.5 y = 2 \cdot \sigma(x) - 0.5 y=2⋅σ(x)−0.5对应scale曲线,很明显通过引入缩放系数scale以后, x x x在同样的区间内, y y y的取值范围更大,或者说 y y y对 x x x更敏感了。并且偏移的范围由原来的 ( 0 , 1 ) (0, 1) (0,1)调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)。

1.2.2 Mosaic data augmentation
在数据预处理时将四张图片拼接成一张图片,增加学习样本的多样性,之前在YOLO系列网络详解P4中讲过,这里不在赘述。

1.2.3 IoU threshold(正样本匹配)
在YOLOv3中针对每一个GT都只分配了一个Anchor。但在YOLOv4包括之前讲过的YOLOv3 SPP以及YOLOv5中一个GT可以同时分配给多个Anchor,它们是直接使用Anchor模板与GT Boxes进行粗略匹配,然后在定位到对应cell的对应Anchor。
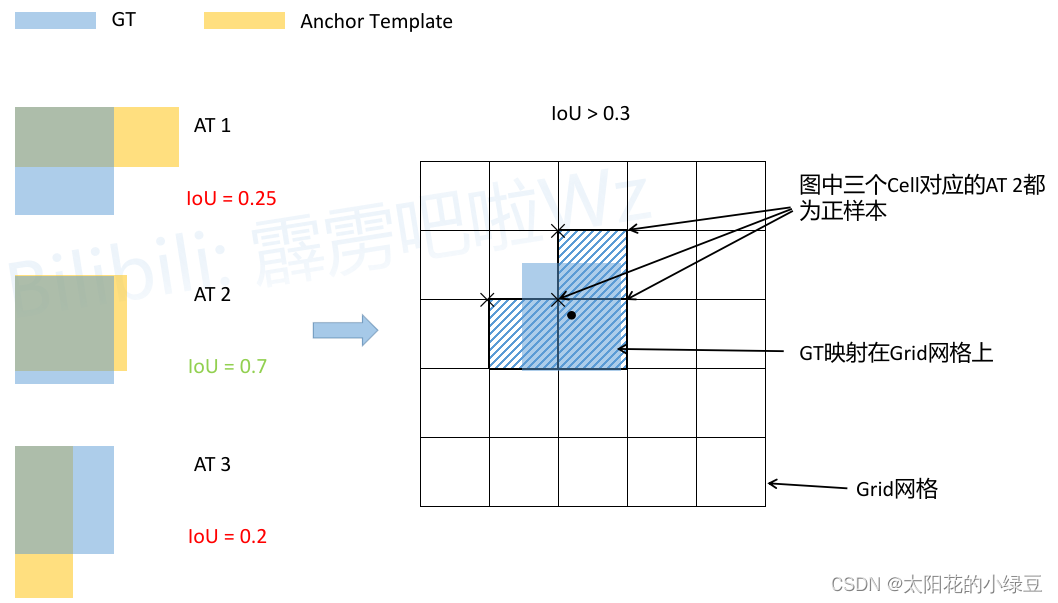
首先回顾下之前在讲YOLOv3 SPP源码解析时提到的正样本匹配过程。流程大致如下图所示:比如说针对某个预测特征层采用如下三种Anchor模板AT 1、AT 2、AT 3

- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU)
- 如果GT与某个Anchor模板的IoU大于给定的阈值,则将GT分配给该Anchor模板,如图中的
AT 2 - 将GT投影到对应预测特征层上,根据GT的中心点定位到对应
cell(图中黑色的 × \times ×表示cell的左上角) - 则该
cell对应的AT2为正样本
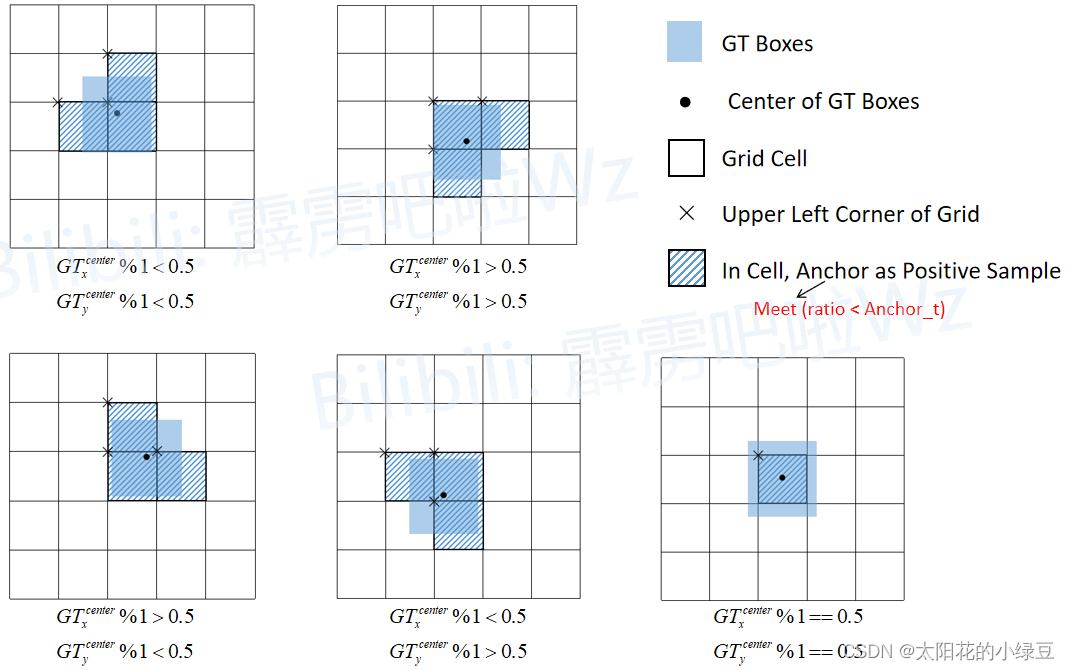
但在YOLOv4以及YOLOv5中关于匹配正样本的方法又有些许不同。主要原因在于1.2.1 Eliminate grid sensitivity中提到的缩放因子 s c a l e x y scale_{xy} scalexy,通过缩放后网络预测中心点的偏移范围已经从原来的 ( 0 , 1 ) (0, 1) (0,1)调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)。所以对于同一个GT Boxes可以分配给更多的Anchor,即正样本的数量更多了。如下图所示:
- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU,在
YOLOv4中IoU的阈值设置的是0.213) - 如果GT与某个Anchor模板的IoU大于给定的阈值,则将GT分配给该Anchor模板,如图中的
AT 2 - 将GT投影到对应预测特征层上,根据GT的中心点定位到对应
cell(注意图中有三个对应的cell,后面会解释) - 则这三个
cell对应的AT2都为正样本
为什么图中的GT会定位到3个cell,这里简单做下解释(这里是通过分析ultralytics的YOLOv5源码得到的)。刚刚说了网络预测中心点的偏移范围已经调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5),所以按理说只要Grid Cell左上角点距离GT中心点在 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)范围内它们对应的Anchor都能回归到GT的位置处。在回过头看看刚刚上面的例子, G T x c e n t e r , G T y c e n t e r GT^{center}_x, GT^{center}_y GTxcenter,GTycenter它们距离落入的Grid Cell左上角距离都小于0.5,所以该Grid Cell上方的Cell以及左侧的Cell都满足条件,即Cell左上角点距离GT中心在 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)范围内。这样会让正样本的数量得到大量的扩充。但需要注意的是,YOLOv5源码中扩展Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。下面又给出了一些根据 G T x c e n t e r , G T y c e n t e r GT^{center}_x, GT^{center}_y GTxcenter,GTycenter的位置扩展的一些Cell,其中%1表示取余并保留小数部分。
1.2.4 Optimizer Anchors
在YOLOv3中使用anchor模板是:
| 目标类型 | Anchors模板 |
|---|---|
| 小尺度 | ( 10 × 13 ) , ( 16 × 30 ) , ( 33 × 23 ) (10 \times 13), (16 \times 30), (33 \times 23) (10×13),(16×30),(33×23) |
| 中尺度 | ( 30 × 61 ) , ( 62 × 45 ) , ( 59 × 119 ) (30 \times 61), (62 \times 45), (59 \times 119) (30×61),(62×45),(59×119) |
| 大尺度 | ( 116 × 90 ) , ( 156 × 198 ) , ( 373 × 326 ) (116 \times 90), (156 \times 198), (373 \times 326) (116×90),(156×198),(373×326) |
在YOLOv4中作者针对 512 × 512 512 \times 512 512×512尺度采用的anchor模板是:
| 目标类型 | Anchors模板 |
|---|---|
| 小尺度 | ( 12 × 16 ) , ( 19 × 36 ) , ( 40 × 28 ) (12 \times 16), (19 \times 36), (40 \times 28) (12×16),(19×36),(40×28) |
| 中尺度 | ( 36 × 75 ) , ( 76 × 55 ) , ( 72 × 146 ) (36 \times 75), (76 \times 55), (72 \times 146) (36×75),(76×55),(72×146) |
| 大尺度 | ( 142 × 110 ) , ( 192 × 243 ) , ( 459 × 401 ) (142 \times 110), (192 \times 243), (459 \times 401) (142×110),(192×243),(459×401) |
1.2.5 CIoU(定位损失)
在YOLOv3中定位损失采用的是MSE损失,但在YOLOv4中作者采用的是CIoU损失。之前在YOLO系列网络详解P4中很详细的讲解过IoU Loss,DIoU Loss以及CIoU Loss,这里不在赘述。

2 CSPDarknet53网络结构
CSPDarknet53就是将CSP结构融入了Darknet53中。CSP结构是在CSPNet(Cross Stage Partial Network)论文中提出的,CSPNet作者说在目标检测任务中使用CSP结构有如下好处:
- Strengthening learning ability of a CNN
- Removing computational bottlenecks
- Reducing memory costs
即减少网络的计算量以及对显存的占用,同时保证网络的能力不变或者略微提升。CSP结构的思想参考原论文中绘制的CSPDenseNet,进入每个stage(一般在下采样后)先将数据划分成俩部分,如下图所示的Part1和Part2。但具体怎么划分呢,在CSPNet中是直接按照通道均分,但在YOLOv4网络中是通过两个1x1的卷积层来实现的。在Part2后跟一堆Blocks然后在通过1x1的卷积层(图中的Transition),接着将两个分支的信息在通道方向进行Concat拼接,最后再通过1x1的卷积层进一步融合(图中的Transition)。

接下来详细分析下CSPDarknet53网络的结构,下图是我根据开源仓库https://github.com/Tianxiaomo/pytorch-YOLOv4中代码绘制的CSPDarknet53详细结构(以输入图片大小为 416 × 416 × 3 416 \times 416 \times 3 416×416×3为例),图中:
- k k k代表卷积核的大小
- s s s代表步距
- c c c代表通过该模块输出的特征层channels
- 注意,
CSPDarknet53Backbone中所有的激活函数都是Mish激活函数

3 YOLOv4网络结构
下图是我绘制的YOLOv4网络的详细结构,大家在搭建或者学习过程中可以进行参考。
