- 前言:
-
目录
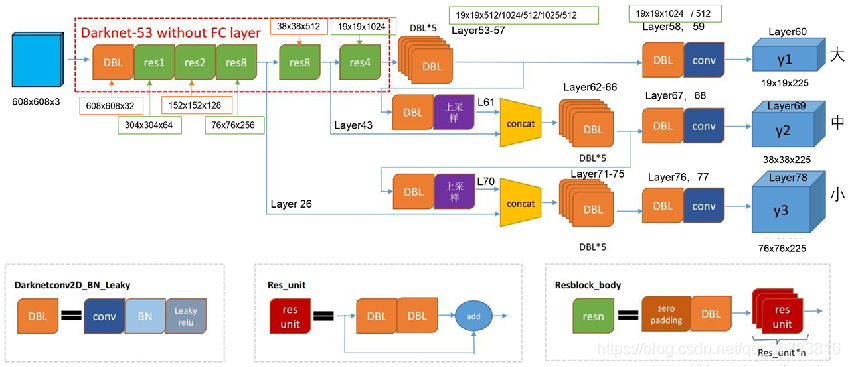
yolov3 structure
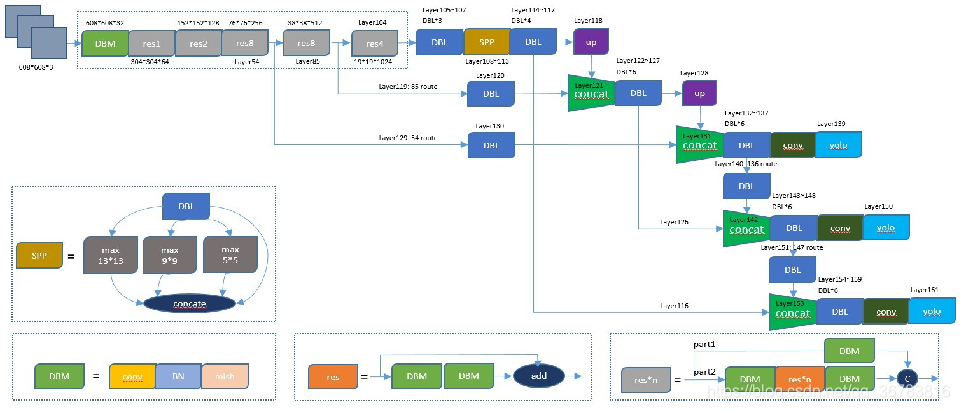
1 YOLOv4 Structure
CSPNet+Darknet53
layer0~layer104
第一个CSP结构如图所示,对应从layer 1到layer 10,layer 1的特征图经过1×1卷积不降维得到layer 2保存,另一条路对layer 1进行一系列残差操作得到layer 8,将layer 2和layer 8进行concate得到layer 9,对layer 9进行1×1卷积进行特征融合,便完成了该分辨率下的CSP构建。
SPPNet
实现是对layer107进行5×5,9×9,13×13size的最大池化,分别得到layer 108,layer 110和layer 112,完成池化后,将layer 107,layer 108,layer 110和layer 112进行concate,连接成一个特征图
layer 114并通过1×1降维到512个通道。
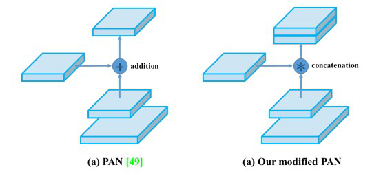
PANet融合的时候使用的方法是Addition
这里YOLOv4将融合的方法由加法改为乘法,也没有解释详细原因,yolov4.cfg中用的是route来链接两部分特征。
PANe上采样对应的layer为layer 105到layer 128,从layer 132开始,为Down Sample和YOLOv3 head。
1.1 Backbone: CSPDarknet53(CSPNet + Darknet53)
1.1.1 CSPNet

CSPNet:可以增强 CNN 学习能力的新型 backbone,简单来讲,CSPNet既可以减少计算量,又可以提高推理速度和准确性。
背景:当神经网络变得更深和更宽时,神经网络特别强大。但是,扩展神经网络的体系结构通常会带来更多的计算,这使大多数人难以承受诸如目标检测之类的计算量繁重的任务。轻量级计算已逐渐受到越来越多的关注,因为现实世界中的应用程序通常需要在小型设备上缩短推理时间,这对计算机视觉算法提出了严峻的挑战。
主要解决了什么问题:就是从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题。
作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSPNet是一种处理的思想,可以和ResNet、ResNeXt和DenseNet结合。
概况来讲,CSPNet提出主要是为了解决三个问题:
增强CNN的学习能力,能够在轻量化的同时保持准确性。
降低计算瓶颈
降低内存成本
上图是DenseNet的示意图以及CSPDenseNet的改进,改进点在于CSPNet将浅层特征映射为两个部分:
一部分经过Dense模块(图中的Partial Dense Block),另一部分直接与Partial Dense Block输出进行concate。
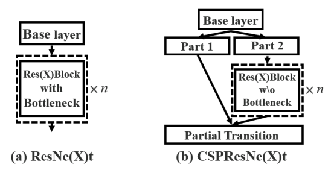
将CSPNet应用于ResNeXt:
跟CSPDenseNet一样,将上一层分为两部分,Part1不进行操作直接concate,Part2进行卷积操作
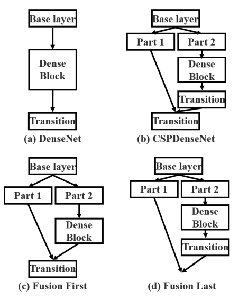
CSPNet作者也设计了几种特征融合的策略,如图所示
图中的Transition Layer代表过渡层,主要包含瓶颈层(1x1卷积)和池化层(可选)。
(a)图是原始的DenseNet的特征融合方式。
(b)图是CSPDenseNet的特征融合方式(trainsition->concatenation->transition)。
(c)图是Fusion First的特征融合方式(concatenation->transition)
(d)图是Fusion Last的特征融合方式(transition->concatenation)
Fustion First的方式是对两个分支的feature map先进行concatenation操作,这样梯度信息可以被重用。Fusion Last的方式是对Dense Block所在分支先进性transition操作,然后再进行concatenation, 梯度信息将被截断,因此不会重复使用梯度信息 。
使用Fusion First有助于降低计算代价,但是准确率有显著下降。
使用Fusion Last也是极大降低了计算代价,top-1 accuracy仅仅下降了0.1个百分点。
同时使用Fusion First和Fusion Last的CSP所采用的融合方式可以在降低计算代价的同时,提升准确率。
1.2 Neck: SPP, PAN
1.2.1 SPPNet
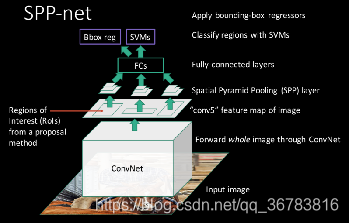 背景:SPP——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 空间金字塔池化,大神何恺明于2014年写的paper
背景:SPP——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 空间金字塔池化,大神何恺明于2014年写的paper
RCNN在2013年发表后,针对RCNN做的改进,当时RCNN检测速度慢, 同期overfeat提出的多尺度训练方式,但是RCNN很难实现。
R-CNN的最大瓶颈是2k个候选区域都要经过一次CNN,速度非常慢。Kaiming He大神最先对此作出改进,提出了SPP-net,最大的改进是只需要将原图输入一次,就可以得到每个候选区域的特征。
大佬在2014年提出了空间金字塔池化,性能和准确率都大幅提高,且在后面很多网络中都延续了这一思想。
贡献:
不管输入尺寸如何,SPP层可以产生固定大小的输出,用于多尺度的训练
每张图只提取一次特征
解决什么问题:当前深度卷积神经网络(CNNs)都需输入固定的图像尺寸(fixed-size),如224×224)。这种需要是“人为”的,并且当面对任意尺寸或比例的图像/子图像时,识别的精度降低(reduce the recognition accuracy)。本文中,我们给网络装配一个“空间金字塔池化”(spatial pyramid pooling)的池化策略,消除上述限制。本SPP-net结构能够产生固定大小的表示(fixed-length representation),而不关心输入图像的尺寸或比例。金字塔池化对物体形变很鲁棒(robust to object deformations)
为什么CNN需要固定输入大小?卷积层和池化层的输出尺寸都是和输入尺寸相关的,它们的输入是不需要固定图片尺寸的,真正需要固定尺寸的是最后的全连接层。
由于FC层的存在,普通的CNN通过固定输入图片的大小来使得全连接层输入固定。作者不这样思考,既然卷积层可以适应任何尺寸,那么只需要在卷积层的最后加入某种结构,使得后面全连接层得到的输入为固定长度就可以了。
这个结构就是SPP。
简单理解,权重保存的是卷积层以及全连接层, 池化层是不用保存的,SPP即修改了池化层的size以及stride, 保持输出一样大小,然后进行多尺度的训练。
SPP网络用在YOLOv4中的目的是增加网络的感受野。
实现是对layer107进行5×5,9×9,13×13size的最大池化,分别得到layer 108,layer 110和layer 112,完成池化后,
将layer 107,layer 108,layer 110和layer 112进行concate,连接成一个特征图layer 114并通过1×1降维到512个通道。
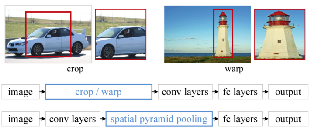
第一行中的图像即为要求固定尺寸输入的CNN对图像的处理方式
第二行为要求固定尺寸输入的CNN (如R-CNN)的处理流程,先将图片按照类似第一行中的方式进行处理,然后输入卷积以及全连接层,最后输出结果
第三行为SPP-net的处理方式,不固定图像的大小,直接输入给卷积层处理,卷积出来的特征并不是直接输入给全连接层,而是先给SPP层处理,
然后得到一个固定长度的输出传给全连接层,最后输出结果。
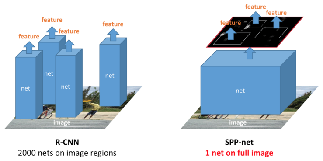
R-CNN对于一张图片,先使用segment seletive方法提取出约2000个候选区域,然后将这两千个候选区域分别送入网络中,即一张图片要经历2000次前向传播,这样会造成大量冗余。
SPP-net则提出了一种从候选区域到全图的特征(feature map)之间的对应映射关系,通过此种映射关系可以直接获取到候选区域的特征向量,不需要重复使用CNN提取特征,从而大幅度缩短训练时间。
每张图片只需进行一次前向传播即可。
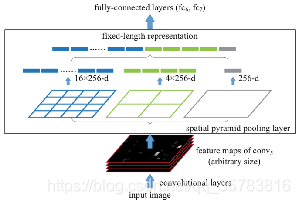
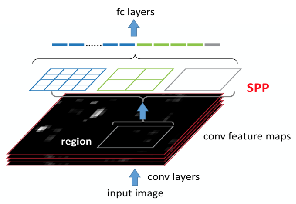
详细讲解一下改进的方法:
1.SPP层(spatial pyramid pooling)
首先要明确的是这一层的位置,这一层加在最后一个卷积层与全连接层之间,目的就是为了输出固定长度的特征传给要求固定输入的全连接层
SPP层的结构如图所示。
2.SPP层的输入:
如图灰色框所示
最后一层卷积输出的特征(我们称为feature map),feature map为下图的黑色部分表示,SPP层的输入为与候选区域对应的在feature map上的一块区域
上面这句话可能有点绕,我们可以理解为一张图有约2000个候选区域,而对一张图做完卷积后得到feature map,在这个feature map上也有约2000个与候选区域对应的区域
3. SPP层的输出:
SPP layer分成1x1,2x2,4x4三个pooling结构(这部分结构如图所示),对每个输入(这里每个输入大小是不一样的)都作max pooling(论文使用的),出来的特征再连接到一起,就是(16+4+1)x256的特征向量。
无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像中候选区域尺寸如何,SPP层的输出永远是(16+4+1)x256特征向量。
候选区域在原图与feature map之间的映射关系,这部分的计算其实就是感受野大小的计算。
在CNN中感受野(receptive fields)是指某一层输出结果中一个元素所对应的上一层的区域大小。后面不再展开。
缺点:
SPP-net缺点也很明显,CNN中的conv层在微调时是不能继续训练的。它仍然是R-CNN的框架,离我们需要的端到端的检测还差很多。
既然端到端如此困难,那就先统一后面的几个模块吧,把SVM和边框回归去掉,由CNN直接得到类别和边框可不可以?于是就有了Fast R-CNN。
1.2.2 PANet
背景:
PANet是CVPR 2018的一篇实例分割论文,作者来自港中文,北大,商汤和腾讯优图。
论文全称为:Path Aggregation Network for Instance Segmentation ,即用于实例分割的路径聚合网络。
PANet在Mask RCNN的基础上做了多处改进,在COCO 2017实例分割比赛上夺冠,同时也是目标检测比赛的第二名。
Mask R-CNN 是一个很简单有效的实例分割框架。
本文研究者指出当前最优的 Mask R-CNN 中的信息传播还可以进一步优化。
具体来说,低层级的特征对于大型实例识别很有用。但最高层级特征和较低层级特征之间的路径很长,增加了访问准确定位信息的难度。
此外,每个建议区域都是基于从一个特征层级池化得到的特征网格而预测的,此分配是启发式的。
由于其它层级的丢弃信息可能对于最终的预测还有用,这个流程还有进一步优化的空间。
最后,掩码预测仅在单个视野上执行,无法获得更加多样化的信息。
即,该网络通过加速信息流和整合不同层级的特征,可以极大提高生成预测掩码的质量。
贡献:
PANet整体上可以看做是对Mask-RCNN做了多个改进,充分的融合了特征,具体来说PANet的贡献可以总结为如下几点。
FPN(这个已经有了,不算论文的贡献)
Bottom-Up Path Augmentation
Adaptive Feature Pooling
Fully-Connected Fusion
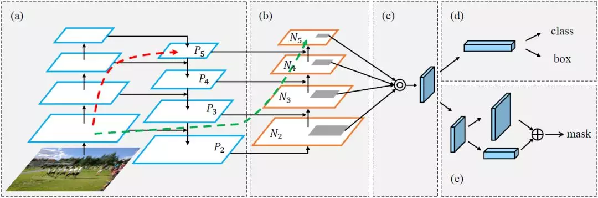
框架图示
(a)FPN 主干网络
(b)自下而上的路径增强
(c)适应性特征池化
(d)边框分支
(e)全连接融合层
注意:为简洁起见,(a)和(b)中省略了特征图的通道维度。
FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递。而PANet在FPN的后面添加一个自底向上的金字塔,这样的操作是对FPN的补充,将低层的强定位特征传递上去。
自底向上的路径增强,为了缩短信息传播路径,同时利用低层特征的精准定位信息
动态特征池化,每个proposal利用金字塔所有层的特征,为了避免proposal的随意分配,对分类及定位更加有利。
全连接层融合,为了给掩码预测增加信息来源
红色的箭头表示在FPN中,因为要走自底向上的过程,浅层的特征传递到顶层需要经过几十个甚至上百个网络层,当然这取决于BackBone网络用的什么,因此经过这么多层传递之后,浅层的特征信息丢失就会比较严重。
绿色的箭头表作者添加了一个Bottom-up Path Augemtation结构,这个结构本身不到10层,这样浅层特征经过原始FPN中的横向连接到P2然后再从P2沿着Bottom-up Path Augemtation传递到顶层,经过的层数不到10层,能较好的保存浅层特征信息。注意,这里的N2和P2表示同一个特征图。 但N3,N4,N5和P3,P4,P5不一样,实际上N3,N4,N5是P3,P4,P5融合后的结果。
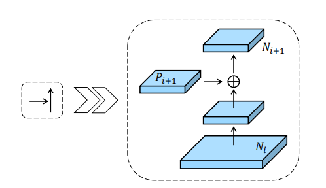
Bottom-up Path Augemtation的详细结构如图所示,是一个常规的特征融合操作,这里展示的是Ni经过一个尺寸为33,步长为2的卷积之后,
特征图尺寸减小为原来的一半然后和Pi+1这个特征图做add操作,得到的结果再经过一个卷积核尺寸为33,stride =1的卷积层得到Ni+1。
Yolov4中:
PANet的网络结构如图所示,与FPN相比,UpSample之后又加了DownSample的操作,再接YOLO Head。
PANe上采样对应的layer为layer 105到layer 128,从layer 132开始,为Down Sample和YOLOv3 head。
PANet融合的时候使用的方法是Addition
这里YOLOv4将融合的方法由加法改为乘法,也没有解释详细原因,yolov4.cfg中用的是route来链接两部分特征。
1.3 Head: YOLOv3
Head 还是和原来的那个Head
2 YOLOv4 Uses
2.1 Bag of Freebies (BoF)
2.1.1 Backbone:
- CutMix
- Mosaic data augmentation
- DropBlock regularization
- Class label smoothing
2.2.2 Detector:
- CIoU-loss
- CmBN
- DropBlock regularization
- Mosaic data augmentation
- Self-Adversarial Training
- Eliminate gridsensitivity
- Using multiple anchors for a single groundtruth
- Cosine annealing scheduler
- Optimal hyperparameters
- Random training shapes
2.2 Bag of Specials (BoS)
2.2.1 Backbone:
- Mish activation
- Cross-stage partial connections (CSP)
- Multi-input weighted residual connections(MiWRC)
2.2.2 Detector:
- Mish activation
- SPP-block
- PAN path-aggregation block
- DIoU-NMS
3 Reference
[1] https://arxiv.org/abs/2004.10934
[2] https://github.com/AlexeyAB/darknet
[3] https://arxiv.org/pdf/1911.11929.pdf
[4] https://github.com/WongKinYiu/CrossStagePartialNetworks
[5] https://arxiv.org/pdf/1406.4729.pdf
[6] https://arxiv.org/pdf/1803.01534.pdf