OHEM - non_local - smooth L1 loss - Libra R-CNN
从 目标检测不平衡综述里看到的
本文还是主要讲libra rcnn 和一些拓展知识
我C
我这一看我每天实习的内容不就是hard neagtive mining吗 ,还是人工的那种☹️☹️☹️
OHEM
正常的hard negative minine 确实存在训练慢的问题,比如我自己每次训练完模型都得重新弄一套测试+重新训练的pipeline 很麻烦。
OHEM的思路也不太难理解
- faster rcnn的训练策略出了什么问题?
- faster rcnn : 正样本标记规则,如果Anchor对应的reference box与ground truth的IoU>0.7。负样本标定规则:如果Anchor对应的reference box与ground truth的IoU<0.3,标记为负样本。剩下的既不是正样本也不是负样本,不用于最终训练.,而中间这一段正是问题的关键,应该选出一部分在这个区间的样本标记为0(背景)并加入训练。
- 怎么选?
- 不能从高低排列loss然后选其中高的,因为有些相近的ROI会被重复选到,然后反向传播了两次,导致了梯度翻倍,所以先用下nms过滤一下。
- 选出来了怎么算?
- 不能直接反向传播,否则虽然把非hard 的neagtive置为0了,还是要分配内存,这会导致很严重的内存占用,所以另外设计一个专门用于反向传播hard negative example的网络,然后共享就行了。
—————————————————————————————————相对来说 libra简洁一点
libra
解释一下这张图
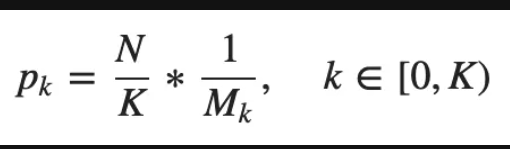
就是把需要找出N个hard neagtive的指标分配到 K个iou区域上去,那每个区域就分摊到了 N/K个,而且每个区域共有Mk这个多个ROI,所以Pk代表着每个区域内能找到hard neagtive的概率。
—————————————————————————————————
Non-local Neural Networks
non_local
这里面只需要看一下那几种attention的表现形式即可
—————————————————————————————————
smooth_l1_loss
smooth
总的来说就是,在梯度大的时候,控制梯度别过大,否则就一直波动。在梯度小的时候改小就小。
设计 Balanced L1 Loss的目的是促进关键梯度的回归,文中举例子是说要促进那些inner的回归,而这是可以使用α 和 γ 控制的。