1.loss要规范化,这样就不会受图片大小的影响
2.w、h采用log:比较特殊的是w,hw,h的regression targets使用了log space. 师兄指点说这是为了降低w,hw,h产生的loss的数量级, 让它在loss里占的比重小些, 不至于因为w,hw,h的loss太大而让x,yx,y产生的loss无用
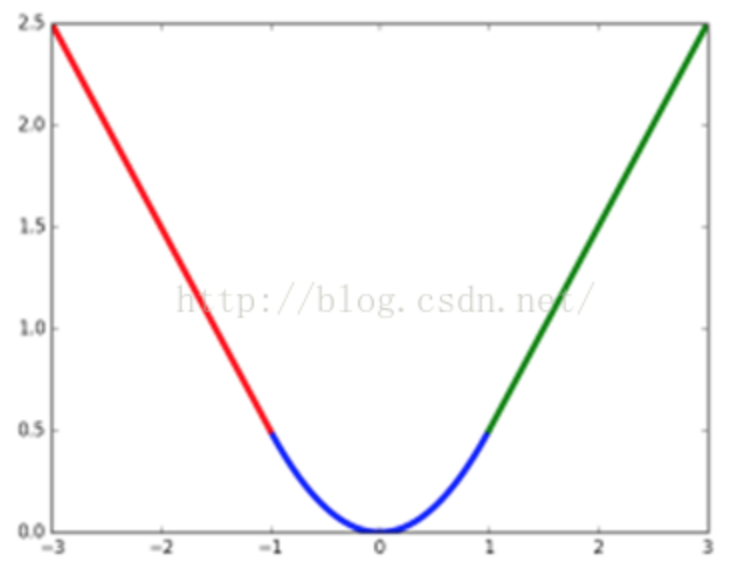
3.当预测值与目标值相差很大时, 梯度容易爆炸, 因为梯度里包含了x−t. 所以rgb在Fast RCNN里提出了SmoothL1Loss.当差值太大时, 原先L2梯度里的x−tx−t被替换成了±1±1, 这样就避免了梯度爆炸, 也就是它更加健壮. 因此L1 loss对噪声(outliers)更鲁棒.
论文原话:"...... L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet."
smoothl1曲线:
https://blog.csdn.net/weixin_35653315/article/details/54571681 非常全面的解释