转载:https://blog.csdn.net/wfei101/article/details/79809332
多任务损失(来自Fast R-CNN)
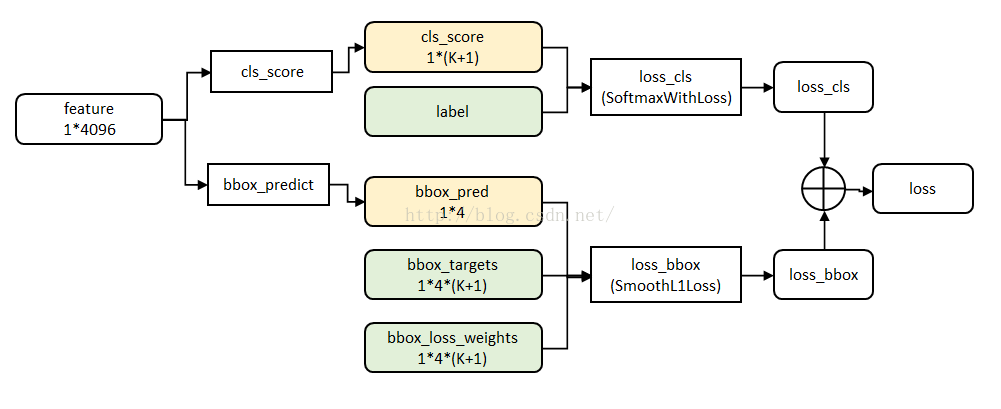
Fast R-CNN网络有两个同级输出层(cls score和bbox_prdict层),都是全连接层,称为multi-task。
① clss_core层:用于分类,输出k+1维数组p,表示属于k类和背景的概率。对每个RoI(Region of Interesting)输出离散型概率分布
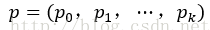
通常,p由k+1类的全连接层利用softmax计算得出。
② bbox_prdict层:用于调整候选区域位置,输出bounding box回归的位移,输出4*K维数组t,表示分别属于k类时,应该平移缩放的参数。
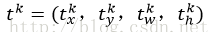
k表示类别的索引,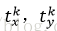
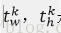
loss_cls层评估分类损失函数。由真实分类u对应的概率决定:

loss_bbox评估检测框定位的损失函数。比较真实分类对应的预测平移缩放参数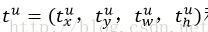
真实平移缩放参数为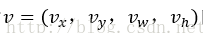
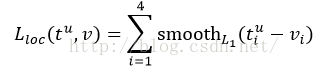
其中,smooth L1损失函数为:
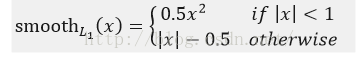
为什么使用L1而不使用L2损失函数
smooth L1损失函数曲线如下图9所示,作者这样设置的目的是想让loss对于离群点更加鲁棒,相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
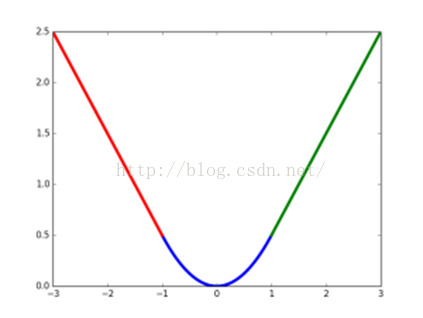
图9 smoothL1损失函数曲线
最后总损失为(两者加权和,如果分类为背景则不考虑定位损失):
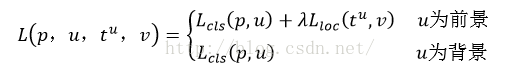
规定u=0为背景类(也就是负标签),那么艾弗森括号指数函数[u≥1]表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作。λ控制分类损失和回归损失的平衡。Fast R-CNN论文中,所有实验λ=1。
艾弗森括号指数函数为:

源码中bbox_loss_weights用于标记每一个bbox是否属于某一个类。
Faster R-CNN损失函数
遵循multi-task loss定义,最小化目标函数,FasterR-CNN中对一个图像的函数定义为:

其中:



其实我个人理解就是softmaxLoss后面加了一个SmoothL1Loss函数,梯度求导就是softmaxLoss和SmoothL1Loss的分阶段的梯度求导! 其中softmax的详细推导请见上一篇Blog