在之前的任意一种顺序数据结构中,要查找某个元素时,都要进行遍历来查找。所以时间复杂度不可能为O(1)。如果有一种数据结构能不经过任何的比较就能直接得到要查找的元素,这种数据结构就是哈希表。
哈希表概念
在一种数据结构中,在插入元素时,由待插入元素的值根据一个特殊函数计算出该元素的存储位置,并将该元素放置在此处。在搜索元素时,还是由搜索的元素值根据这个特殊函数计算存储位置,直接在该位置将元素取出即可。
上述所说的特殊函数即为哈希函数,上述构造出来的结构称为哈希表(由数组实现)。
比如:一组数据:1 2 8 5 9。定义哈希函数是:hash(key) = key % m(m为内存单元个数,可以自己定义)。这里我们定义为10。
根据哈希函数计算存储位置:
hash(1) = 1;hash(2) = 2;hash(8) = 8;hash(5) = 5;hash(10) = 0
所以,这组数据存储如下:
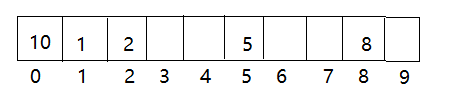
如在查找2时,根据哈希函数得到存储位置为2,则此时直接在下标为2处进行查找,便可以不用比较就可以得到要查找的数据。
哈希冲突
如果在上述表中再插入一个元素12,发现根据哈希函数计算的下标也为2,而在下表为2处已经存放了数据。此时就发生了哈希冲突。
根据不同的关键字通过相同的哈希函数计算出相同的哈希地址,就称为发生了哈希冲突或哈希碰撞。
上述用到的哈希函数是除留余数法。
可以设计精妙的哈希函数来使产生哈希冲突的可能性尽可能的低,但不可能避免哈希冲突。
处理哈希冲突
闭散列:也叫开放地址法。当发生哈希冲突时,如果哈希表未被装满,说明哈希表中还有位置,此时就可以把key插入到下一个位置上。
可以使用线性探测来寻找下一个空余的位置。
线性探测:从发生冲突的位置开始,依次向后探测,直到找到空位置为止。
负载因子
当发生哈希冲突时,不同的关键码占据了可利用的空位置,使得寻找某关键码的位置需要进行多次比较,导致搜索效率降低。
当哈希表长一定时,填入表中的元素越多时,发生冲突的概率就越大,所以要控制插入表中的元素个数。因此引入负载因子。
哈希表的负载因子:a = 填入表中的元素个数/哈希表的长度。
所以当哈希表的负载因子达到一定的数值时,就不能要考虑扩容来使降低扩容因子,从而使搜索效率提高。
下面实现基于线性探测解决哈希冲突的哈希表(哈希函数为除留余数法)。
1. 哈希表的结构定义
用数组来实现哈希表的结构,哈希函数为除留余数法。再用一个变量记录哈希表中的实际元素个数。
哈希表中的元素类型为一键值对(key和value),其中key值在整个哈希表中是唯一的。可以根据key值来查找对应的value值。将这两个变量的类型都定义为整型数据。
同时为了表示哈希表中某个位置处是否插入了元素,可以在定义一个状态标志位,来记录该位置是未插入的状态还是已插入的状态。因为数组中的值在未插入元素前是随机的,如果要插入的元素与随机值相等,我们就可能理解为该处已经插入了元素,但是这只是随机值,并没有插入元素。所以要定义该状态位表示两个状态,一个是已插入状态,一个是未插入状态。这样即使随机值与要插入的元素相同,只要该处的状态为未插入状态,就可以往其中继续插入元素。
如果2和12计算的下标值均为2,先插入2时会将2插入在下标为2的位置处,再插入12时会插入到下标2之后的位置。当删除key为2的值时,如果只是将下标为2处的状态设置为未插入状态。当在查找12时,会先找到下标2处,发现此处为未插入状态,此时会认为该哈希表中没有12,则会导致查找失败。所以不能简单的将该处的状态设置为未插入状态。
此时,要在引入一个删除状态。当某处的值设置为删除状态或未插入状态(即不为插入状态)时,可以继续往该处插入元素。只有该处的状态为未插入状态时,认为查找失败,当为插入状态和删除状态时,可以继续往后探测。
代码编写如下:
//定义哈希表,哈希表是由一个数组构成
//哈希函数使用除留余数法
#define HASHMAXSIZE 1000
typedef int KeyType;
typedef int ValType;
typedef enum
{
Empty,//未插入状态
Valid,//插入状态
Deleted//删除状态
}Stat;
//哈希表数组中的元素类型
typedef struct HashElemType
{
KeyType key;//包含一个键值
ValType value;//包含一个值
Stat stat;//定义哈希表中的元素状态
}HashElemType;
2. 初始化哈希表
哈希表中有三个成员,一个是数组,一个是哈希表实际元素个数,一个是哈希函数。所以,在初始化时,将哈希表中的实际元素个数置为0,哈希函数由插入的参数给出。在数组中,要对每个元素的状态赋值为未插入状态,表明这些位置为空位置,均可以进行插入。数组元素中的键值对不用赋值为随机值,因为元素个数和未插入状态已经保证了这些位置上的元素为无效元素。
//哈希表的初始化
void HashInit(HashTable* ht,HashFunc func)
{
if(ht == NULL)
{
//非法输入
return;
}
ht->size = 0;
ht->func = func;
size_t i = 0;
for(;i < HASHMAXSIZE;++i)
{
ht->data[i].stat = Empty;
}
return;
}
3. 向哈希表中插入元素
实现思路如下:
(1)首先判定该哈希表中的元素个数是否已经达到负载因子(自定义为0.8),如果达到了则可以进行扩容或插入失败。这里我们定义为插入失败
(2)如果不为(1)。根据所插入元素的Key值由哈希函数计算要插入的位置下标
(3)判断该下标处的插入状态
a)如果该位置处的状态为未插入状态或删除状态(即不为已插入状态),则直接将该元素插入即可
b)如果该位置处的状态为已插入状态且该处的Key值与所给的Key值相等。此时,可以替换为新的Value值,或者将要插入的键值对根据线性探测插入到后面的空余位置,或者认为插入失败。在这里,我们处理为插入失败
c)如果不为a)b),即该位置为插入状态但Key值不相同,则进行线性探测将新的元素插入到后面的空余位置
如果线性探测到数组的最大下标处,还没找到空余位置,则将下标置为0,继续开始探测。
(4)最后,元素插入成功之后,数组元素长度加1
根据上述的思路,实现代码如下:
//向哈希表中插入元素
void HashInsert(HashTable* ht,KeyType key,ValType value)
{
if(ht == NULL)
{
//非法输入
return;
}
//首先判断哈希表中的元素个数是否达到负载因子,如果达到了,则插入失败
if(ht->size >= 0.8*HASHMAXSIZE)
{
return;
}
//如果没有达到,
//1. 根据key计算offset
size_t offset = ht->func(key);
while(1)
{
//2. 如果offset处的值为Empty或为Delete,则将key和value的值插入到该处
if(ht->data[offset].stat != Valid)
{
ht->data[offset].key = key;
ht->data[offset].value = value;
ht->data[offset].stat = Valid;
break;
}
//3. 如果offset处的值为Valid,且该处的key值与要插入的key值相同,则插入失败
else if(ht->data[offset].stat == Valid && ht->data[offset].key == key)
{
//插入失败
return;
}
//4. 否则,++offset,继续判断offset处的值
else
{
++offset;
// 如果offset的值等于HASHMAXSIZE,则将offset赋值为0
if(offset >= HASHMAXSIZE)
{
offset = 0;
}
}
}
//哈希表实际元素个数加1
++ht->size;
return;
}
4. 根据指定的Key值在哈希表中查找Value值
实现思路如下:
(1)首先判定哈希表中的元素个数,如果为0,表明哈希表中没有元素,则查找失败
(2)如果元素个数不为0。则根据指定的Key值由哈希函数计算下标位置
(3)判断该下标处的状态
a)如果该下标处的元素状态为未插入状态,说明要查找的元素不存在,此时查找失败
b)如果该下标处的元素为插入状态,且此处的Key值与指定的Key值相同,则返回该处的Value值,此时查找成功。
c)如果不为a)b),即该处为插入状态但Key值不相同或者为删除状态,此时都需要向后进行线性探测。后移一次,判断一次。如果后移到数组的最大下标处还未找到,则将下标置为0,在从头开始探测。
根据上述思路,实现代码如下:
//在哈希表中查找元素
int HashFind(HashTable* ht,KeyType key,ValType* value)
{
if(ht == NULL || value == NULL)
{
//非法输入
return 0;
}
//1. 如果哈希表为空,则查找失败
if(ht->size == 0)
{
return 0;
}
//2. 根据key值计算offset
size_t offset = ht->func(key);
while(1)
{
//3. 如果offset处的key值等于所给的key值,则返回value值
if(ht->data[offset].stat == Valid && ht->data[offset].key == key)
{
*value = ht->data[offset].value;
return 1;
}
//4. 如果offset处的状态为Empty,则说明要查找的元素不存在,查找失败
else if(ht->data[offset].stat == Empty)
{
return 0;
}
//5. 如果,offset处的状态为Valid且不等于key或者状态为Delete,则offset++,往后遍历
else
{
++offset;
if(offset >= HASHMAXSIZE)
{
offset = 0;
}
}
}
}
5. 在哈希表中删除指定的Key值
实现思路如下:
(1)如果哈希表中的元素个数为0,则删除失败
(2)如果不为空表,则根据指定的Key值由哈希函数计算位置下标
(3)判断该下标处的状态
a)如果该下标处的状态为插入状态且该处的Key值与指定的Key值相同,则将该处的状态设置为删除状态,元素个数减1即可
b)如果该处的状态为未插入状态,则说明指定的Key值在哈希表中不存在,则删除失败
c)如果不为a)b),即该处的状态为插入状态且Key值不相同或为Delete状态,则要往后进行线性探测。探测到一个位置,判断一次。如果探测到数组的最大下标处还未成功或失败,则将探测位置设置为0,从头开始探测。
实现代码如下:
//删除哈希表中的元素
void HashDelete(HashTable* ht,KeyType key)
{
if(ht == NULL)
{
//非法输入
return;
}
//1. 如果哈希表为空,则删除失败
if(ht->size == 0)
{
return;
}
//2. 根据key计算offset
size_t offset = ht->func(key);
while(1)
{
//3. 如果offset处的值为key值,如果将该处的状态置为Empty,则在查找与该处下标相同的key值时就会查找失败
// 但有可能要查找的元素在该下标的后面。所以不能将该处的状态设置为Empty
// 所以在设置一个状态Delete,只有该处的状态为Empty时才会查找失败,
// 当该处的状态不是Valid时才能进行插入
if(ht->data[offset].stat == Valid && ht->data[offset].key == key)
{
ht->data[offset].stat = Deleted;
break;
}
//4. 如果该处的状态为Empty,则哈希表中不存在该元素,删除失败
else if(ht->data[offset].stat == Empty)
{
return;
}
//5. 否则,++offset,在往后进行遍历
else
{
++offset;
if(offset >= HASHMAXSIZE)
{
offset = 0;
}
}
}
//6. --size
--ht->size;
return;
}
6. 销毁哈希表
在哈希表销毁之后应当与哈希表初始化前的状态相同。即元素个数为0,哈希函数未定义即为空指针。哈希表中的元素状态均为未插入状态即可。
//销毁哈希表
void HashDestroy(HashTable* ht)
{
if(ht == NULL)
{
//非法输入
return;
}
ht->size = 0;
ht->func = NULL;
size_t i = 0;
for(;i < HASHMAXSIZE;i++)
{
ht->data[i].stat = Empty;
}
return;
}