考研之数据结构031_算法排序_选择排序_简单选择、堆排序

一、简单选择排序
1、算法思想

第一轮:在待排序元素中,从左往右依次扫描,找到最小的元素,与第一个元素进行交换。
第二轮:从第二个元素开始扫描,找到最小元素,与第二个元素进行交换。
…
第n-1轮:直到剩下最后一个元素,不再处理。
2、代码实现

3、效率复杂度
1.时间复杂度。只有 O(n2)

2.空间复杂度

4、不稳定
5、既可以数组,也可以链表
二、堆排序(重点!!)

一、什么是堆?
1、算法的实现基于一种“堆”的数据结构,那么什么是堆?
从内存视角看起来连续存放的数组,但是从逻辑视角应该理解为,一颗顺序存储的完全二叉树。
2、下图:解释了大根堆和小根堆?

3、回忆二叉树顺序存储。

4、什么是大根堆?
在完全二叉树中,如果所有子树的根节点,都要大于等于左右孩子,这样一个顺序存储的完全二叉树就是大根堆。
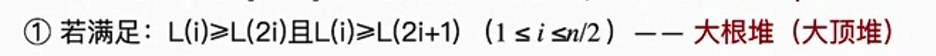

5、什么是小根堆?
在完全二叉树中,任何一个根结点的值都小于左右子树的值。

二、堆排序
堆排序在类别上属于“选择排序”。
选择排序的思想是:每一趟都会在待排序中选取关键字最大或小的元素加入有序序列。
如果有了“大根堆”,从中选出关键字最大的元素,非常方便,那就是堆顶元素,如果从数组角度来看,那就是第一个元素。
所以如果我们能将一个数组整理成“堆”,那么进行选择排序,就会变的很简单。
1.建立大根堆
1.对于初始数列,如何建立大根堆。
2.大根堆的特性是:根大于等于左右。
3.在树里面检查所有的分支节点,分支节点都是所属的子树的根节点。
4.在顺序存储的完全二叉树中,节点下标小于等于n/2节点,都是非终端节点。i=n/2. 例如8个节点,那么需要检查的是小于等于4的结点。(检查1234)
把所有的非终端节点都检查一遍,是否满足大根堆的要求,如果不满足则进行调整。
5. 从编号最大的非叶子结点进行检查。
6.根据以下图,来找到左右孩子:

2.建立大根堆的代码


1.代码流程:
变量的作用是:
- k:代表的是根节点
- i:是根节点的左子树,i+1是右子树
流程具体分析:
BuildMaxHeap()函数:建立大根堆
- 参数是:数组和数组个数
for循环:i初始化值:从最后一个非叶子结点;判断条件是大于0; - 条件是:从最后一个非叶子结点到第一个结点为止。
- 语句是:从后往前所有非终端节点,进行依次调增。调用HeadAdjust(数组、调整的索引,数组个数)函数
- PS:从n到n+1是从下往上调整,而i=1是从上往下调整。
HeadAdjust()函数。将以k为根的子树调整为大根堆。
-
数组索引从1开始,而0暂存子树的根节点。
-
for循环(i的初始化是根k的左子树;判断条件是小于数组长度;根k的左/右子树的左子树)
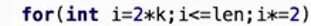
-
if 判断(k根节点的左子树是否小于数组长度 &&并且 右子树是否大于左子树的)
若大于则i++,则i指向的是k根节点的右子树,若不大于,则i指向的是k根节点的左子树。 -
if判断(当前k结点是否大于等于k的左右子树)如果大于则退出循环。不进行交换。
若该结点小于左或右子树,则将左或右子树的值赋值放到根节点k所指向的结点位置。
并且将左或右子树的索引值赋值给k,让该左或右子树为根节点,进行判断是否该根节点(上一个k根节点的左右子树,是现在的根节点为k)的左右子树是否大于该根结点,若大于则重复上面的循环和判断。若小于则退出循环。

-
将BuildMaxHeap函数传过来的根节点,放入左右子树(或者,左右子树的左右子树之中…)
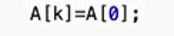
3.如何进行大根堆排序?(递增排序)
- 将最大的元素(第一个元素),与最后一个元素进行交换。
- 下一次进行大根堆建立的时候,数组元素进行减一。表明已经找到最大元素。
- 一直循环下去,直到剩下一个元素,进行n-1次排序。
1.代码实现:

2.代码流程:
- 对于一个元素序列建立大根堆. BuildMaxHeap(数组,数组元素个数)
- 对大根堆进行排序:for(i初始化是指向数组中最后一个元素,因为每次都需要将堆底元素和对顶元素交换;条件是:i大于1,因为剩下的第一个不需要排序了)
- 语句是:将堆底和堆定元素进行交换位置。
- 并将剩余待排序的元素整理成堆。用HeadAdjust函数(数组,从第一个为根开始下坠,到元素的个数【每次都减一】)


4、效率复杂度
1.时间复杂度

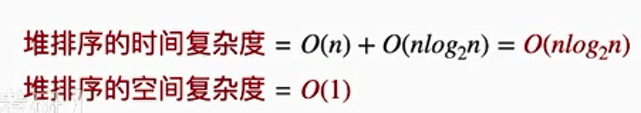
2.空间复杂度O(1)
3.稳定性:不稳定
5、堆的插入和删除

