一句话总结:提出Localized Contrastive Estimation (LCE),来优化检索排序。
摘要
预训练的深度语言模型(LM)在文本检索中表现出色。基于丰富的上下文匹配信息,深度LM微调重新排序器从候选集合中找出更为关联的内容。同时,深度lm也可以用来提高搜索索引,构建更好的召回。当前的reranker方法并不能完全探索到检索结果的效果。因此,本文提出了Localized Contrastive Estimation(LCE)训练重排序模型,从效果上看,显著改进了深度两阶段模型。
方法
训练一个bert模型给query和doc对打分:

其中cls表示bert输出的文本embedding,cls位置的值,将query和doc拼接起来作为整体。Vp是一个projection vector(投影向量,这是什么意思?从何而来?)。
补充:
Vanilla method
它用binary cross entropy 单独算query和doc对的得分。
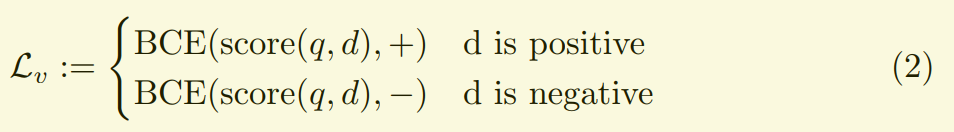
该法将这个问题当做了一个二分类的概率问题。文中说:However, reranker is unique in nature; it deals with the very top portion of retriever results, each of which may contain many confounding signatures. 翻译一下,就是排序本身就不是公平的事情,只关注了检索结果的头部部分,可能包含了一些“混淆信息”,就是其实跟query不相关,但是也进入了头部位置。
Localized Contrastive Estimation (LCE)
Contrastive Loss:相对损失,通俗点说, 一个query和doc对,相对全部query和doc对和的大小。
举个例子:一个query:A,跟一堆doc:B、C、D,<A,B>的loss = <A,B>/(<A,B>+<A,C>+<A,D>)
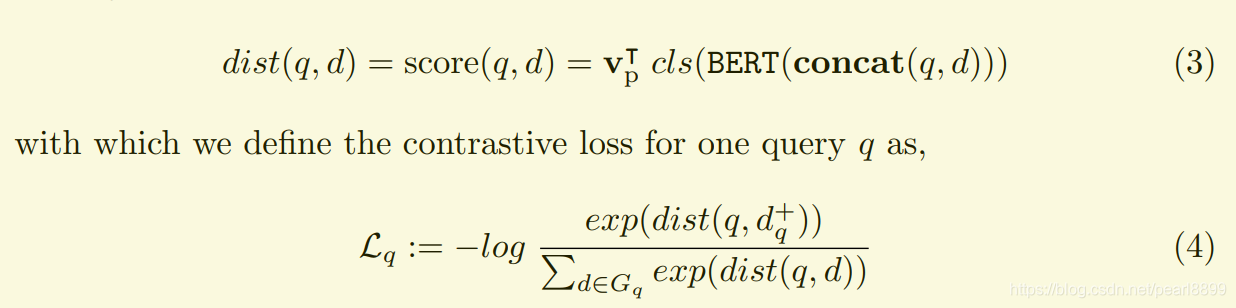
参考:
1.作者代码:https://github.com/luyug/Reranker
2.论文:https://arxiv.org/abs/2101.08751
3.Vanilla method: