abstract
风格控制TTS的常见做法:(1)style-index控制,但是只能合成预设风格的语音,无法拓展;(2)reference encoder提取不可解释的style embedding用于风格控制。
本文参考语言模型的方法,使用自然语言提示,控制提示语义下的风格。为此,专门构建一个数据集,speech+text,以及对应的自然语言表示的风格描述。
related work
Cross-modal Representation Learning
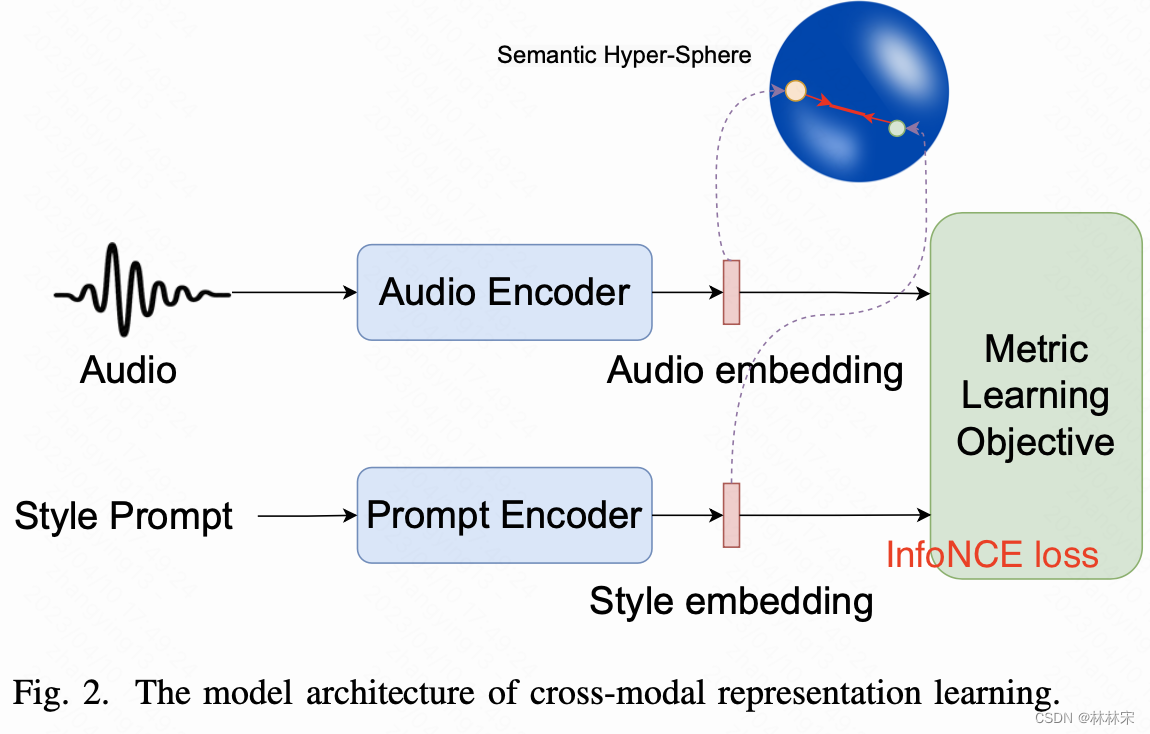
不同模态的特征映射到同一表征空间。本文希望通过自然语言控制声学特征(pitch./emotion/speed)的合成。
Vector Quantization
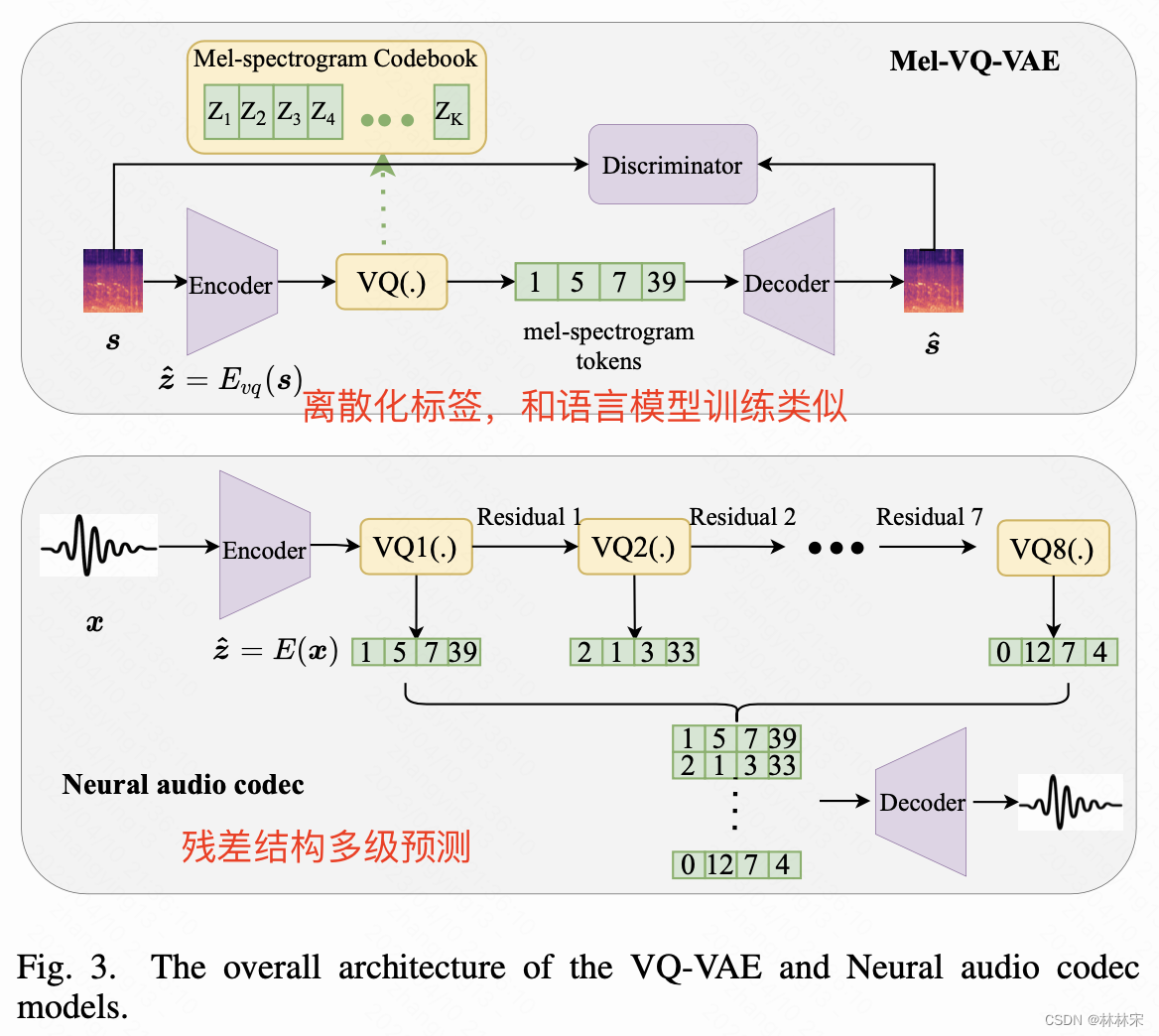
VQ-VAE对音频进行编解码。本文用encoder预测vector-quantized acoustic representation(可学习),认为相比于mel能够减少ground truth和预测值的gap。
Expressive Text-to-speech
同期的工作:
- Style-Tagging-TTS:用短语或者单词(emotion, intention, and tone of voice)控制合成的风格。
- PromptTTS :用5个不同的方面(gender, pitch, speaking speed, volume, and emotion)控制合成,这5方面有很强的风格指示 (low-pitch, high-speaking speech)。
- ours:本文用更长的句子,且句式比较随意,并且是在中文数据上进行的style- prompt-controllable expressive TTS.
Diffusion Probabilistic Models
dataset
- 自己标注一个数据集:包含44hours speech, 7speakers(5 female/2 male)
- 标注要求:
- 一个词描述一句话的情感
- 一个词描述情感程度;
- 一句完成的话描述句子的风格

- 和其他两个任务的数据集进行比较,本文构建的数据集更贴近真实场景。
method
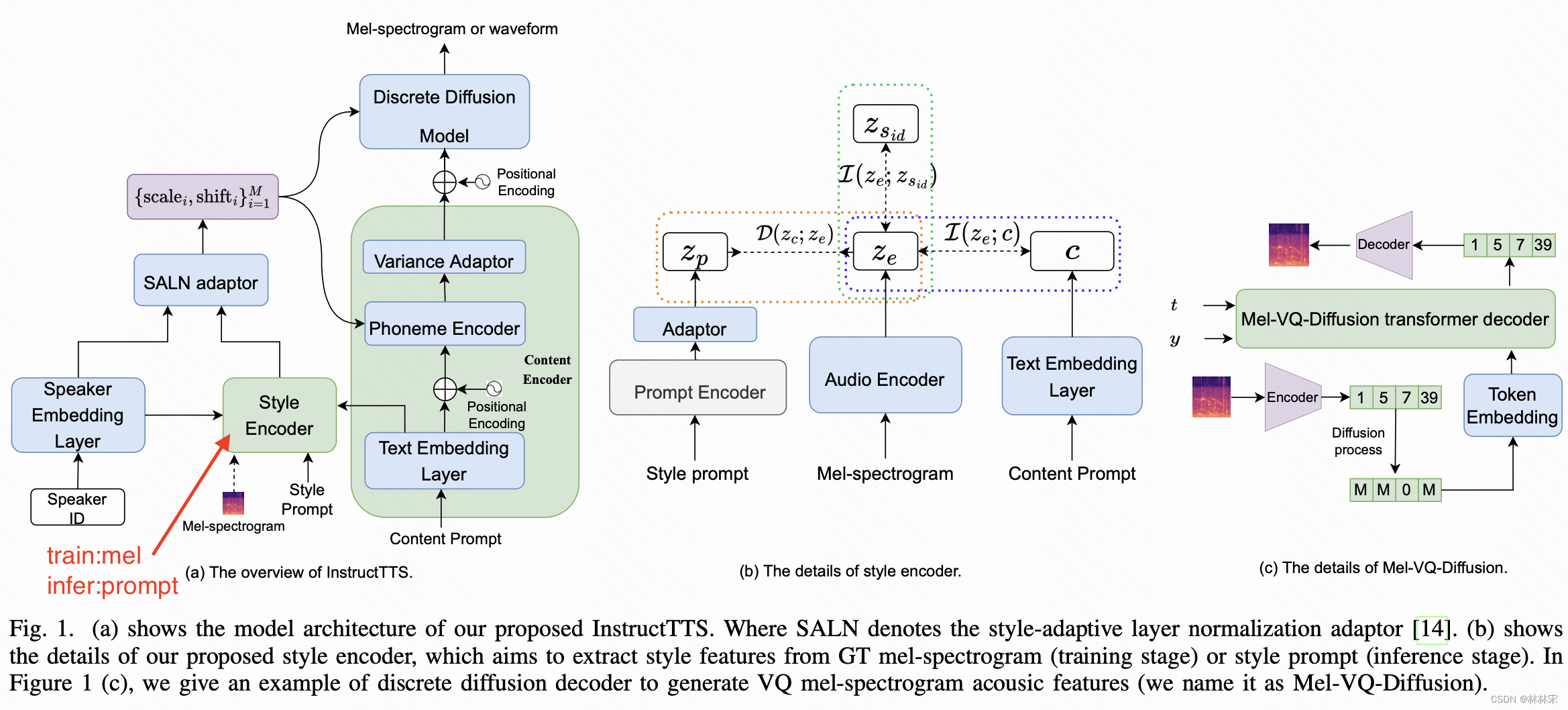
Style Prompt Embedding Model
- 使用RoBERTa作为prompt model,输入prompt seq: [ C L S ] [ S 1 , S 2 , . . . , S M ] [CLS] [S_1, S_2,...,S_M] [CLS][S1,S2,...,SM],将[CLS] 的representation作为句子的风格表征;
- prompt embedding的要求:(1)prompt space 可以表达语义完整性;(2)embedding空间分布relatively uniform and smooth, 对于unseen数据泛化良好;
- 训练步骤:
- 基于中文数据训练RoBERTa (语言模型)
- 基于本文使用的风格标签数据finetune预训练的RoBERTa,引入InfoNCE loss
- txt prompt embedding和audio style embedding要映射到同一空间,audio- text retrieval task,构造N-1个负样本和1个正样本,使用对比学习和InfoNCE loss (更有效果)