员工职位与薪资多项式回归模型
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/121458428(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
3 多项式回归
案例四:员工职位与薪资多项式回归模型
以上的三个案例都是属于线性回归,模型最后出来的结果也就是y = mx+b一条直线的形式。接下来介绍多项式回归,即研究一个因变量与一个或多个自变量间多项式的回归分析。这种分析方法的有点在于可以通过增加x的高次项对实测点进行逼近,直至满意为止。
3.1.1 模块加载与数据读入
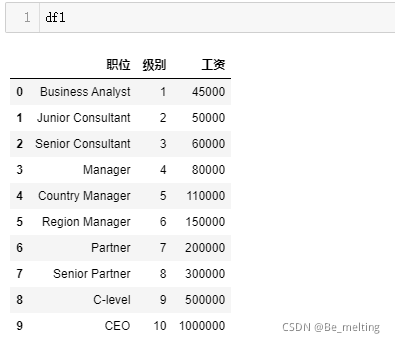
新建一个python3文件,命名为多项式回归模型.ipynb。数据集中只有三个字段,分别为职位,等级和薪资,数据量仅有10条。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#对于中文的数据,如果报错可以尝试指定编码为gbk
df1 = pd.read_csv('./data/Position_Salaries.csv',encoding = 'gbk')
df1
输出结果如下。(数据量仅有10条,读取时候注意编码格式)
3.1.2 数据可视化
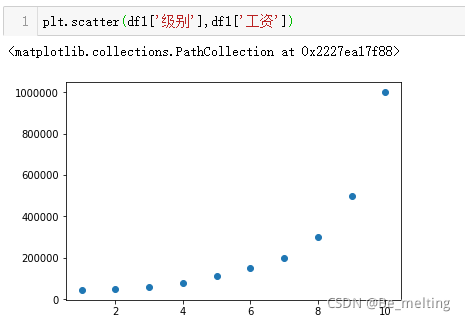
通过观察数据,第一列和第二列数据是一一对应的,在绘制图形时候任意选择一列即可,但是为了防止x轴的信息字段过长,采用第二列和第三列的数据进行绘制图形会比较好,代码及输出结果如下。
3.1.3 模型创建与应用
(1)构建数据集。这里的数据很简单,可以直接看到没有缺失数据要进行处理,但是特征数据和标签数据先要进行划分,代码操作如下。
#构建特征数据和标签数据
features = df1['级别'].values
labels = df1['工资'].values
#创建模型并拟合
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(features,labels)
此时输出的结果会报错,具体结果如下。(提示特征数据应该是一个二维数据结构,但是传递的数据却是一维)
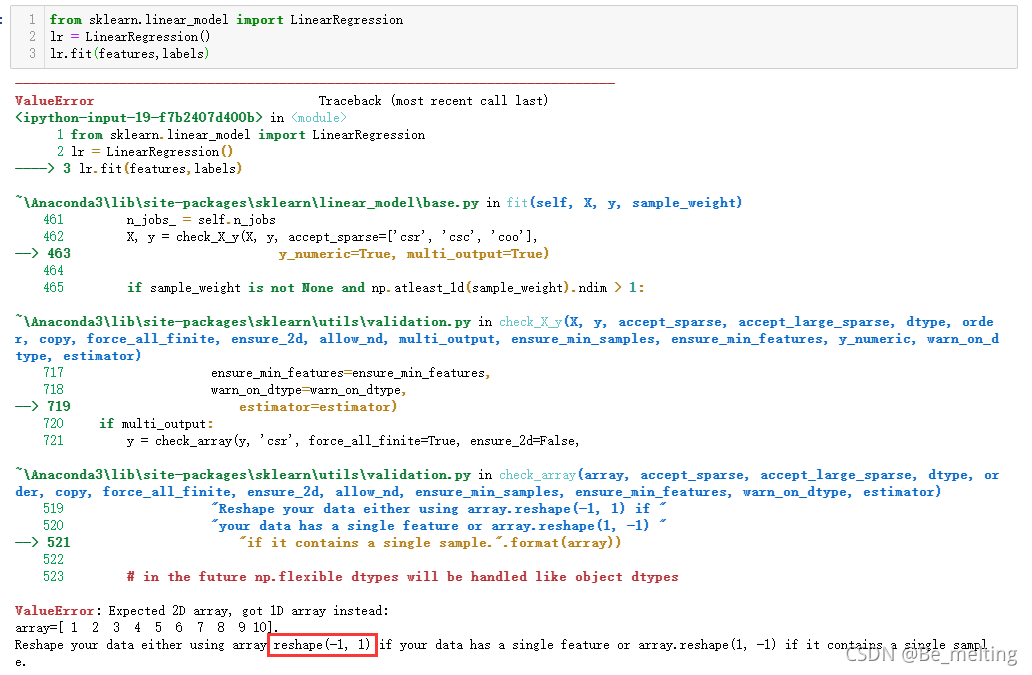
特征数据的维度,可以通过ndim/shape方法查看,结果核实属于一维结构。

解决的方式可以有两种,一种是按照提示,在特征数据后面添加reshape(-1,1),再次运行程序,直接使用以往的线性回归模型进行训练,输出结果如下。(这种方式不仅要在模型训练时候改变数据结构,在预测时候也需要改变结构)

还有一种处理方式就是在整理特征数据时候就已经把数据整成二维数据,比较推荐使用的方式就是为使用坐标的方式进行DataFrame数据的筛选。
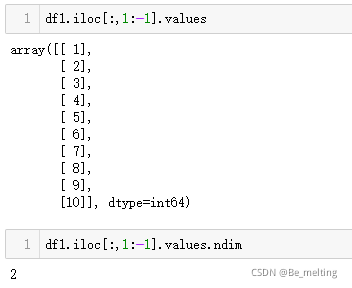
对于特征数据推荐使用坐标切片的方式进行数据的获取,标签数据获取更为简单,直接将中间索引逗号的部分换成-1即可,一般标签数据都是在最后一列。

然后就是和前面的操作过程一样,代码及输出结果如下。(这种方式比较推荐,不用再多次写reshape(-1,1),代码简洁)
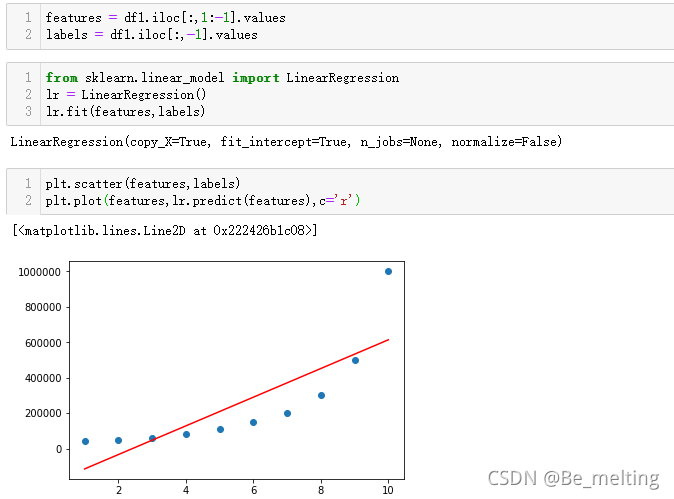
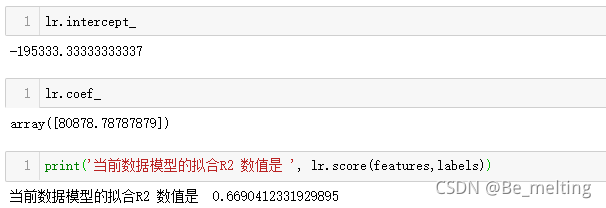
通过线性回归模型的结果分析,最后生成的直线并没有很好的拟合原始数据,评估模型的R方指标仅有0.669,只能说不高不低,效果不是很明显。
3.1.4 模型对比
尝试进行多项式回归建模,数据处理好后,建模过程相对比较简单,代码如下。
from sklearn.preprocessing import PolynomialFeatures
#创建四个多项式回归模型,degree=1相当于线性回归模型
polynomial_reg1 = PolynomialFeatures(degree=1)
polynomial_reg2 = PolynomialFeatures(degree=2)
polynomial_reg3 = PolynomialFeatures(degree=3)
polynomial_reg4 = PolynomialFeatures(degree=4)
#转化特征数据
polynomial_features1 = polynomial_reg1.fit_transform(features)
polynomial_features2 = polynomial_reg2.fit_transform(features)
polynomial_features3 = polynomial_reg3.fit_transform(features)
polynomial_features4 = polynomial_reg4.fit_transform(features)
#进行模型拟合
lr1 = LinearRegression()
lr1.fit(polynomial_features1,labels)
lr2 = LinearRegression()
lr2.fit(polynomial_features2,labels)
lr3 = LinearRegression()
lr3.fit(polynomial_features3,labels)
lr4 = LinearRegression()
lr4.fit(polynomial_features4,labels)
最后进行模型的预测及绘制图形,对比不同模型的拟合效果,直接通过对比图查看差别。
plt.figure(figsize=(12,8))
plt.scatter(features,labels)
plt.plot(features,lr1.predict(polynomial_features1),c='y',label = 'degree1')
plt.plot(features,lr2.predict(polynomial_features2),c='b',label = 'degree2')
plt.plot(features,lr3.predict(polynomial_features3),c='r',label = 'degree3')
plt.plot(features,lr4.predict(polynomial_features4),c='g',label = 'degree4')
plt.legend()
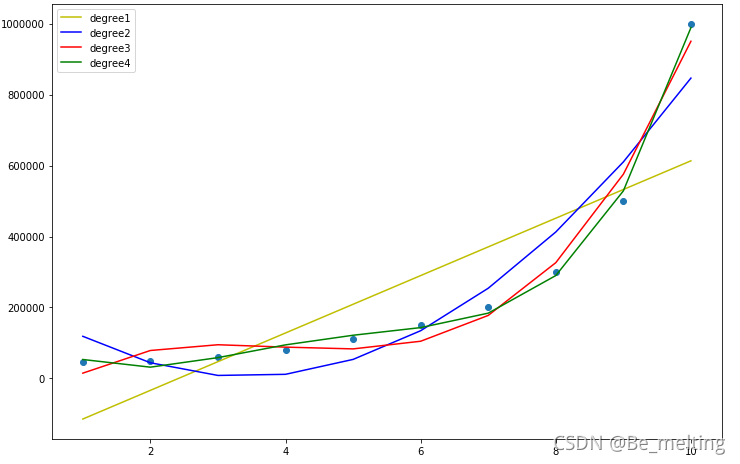
输出结果如下。(黄色代表着一次多项式也就是直接进行线性回归的结果,蓝色的是二次多项式,红色的为三次多项式,绿色的为四次多项式,凭借着肉眼就可以发现随着项次的增多,图线拟合的数据就越完美)
借助R方来进一步确定各个模型的拟合程度,代码及输出结果如下。(结果也证明最后多项式的次数越大,模型的拟合能力越强)


3.1.5 模型过拟合
当模型为了追求高拟合度时候,就会想尽办法满足每个点的误差最小,最终训练出的模型会对已有的数据有着非常优秀的拟合能力,但是对于未见过的数据模型就会表现的一塌糊涂,比如将数据划分训练集和测试集,比例为8:2。
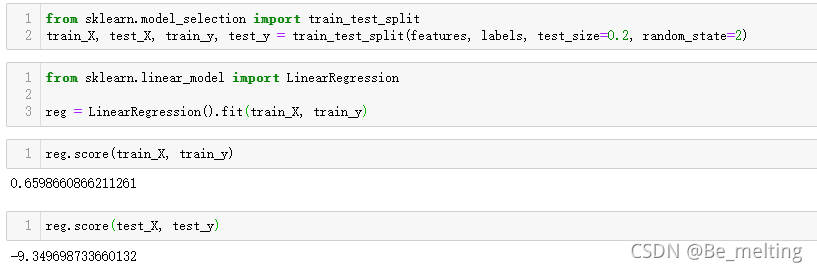
输出结果中可以发现,模型在训练完成后,对于训练数据集上的拟合度为0.659,还算一般,但是对于未见过的测试数据,拟合度却小于0,说明模型对于未见过的数据无法做出正确的预测,偏离正常数据值非常巨大,模型存在着过拟合现象。
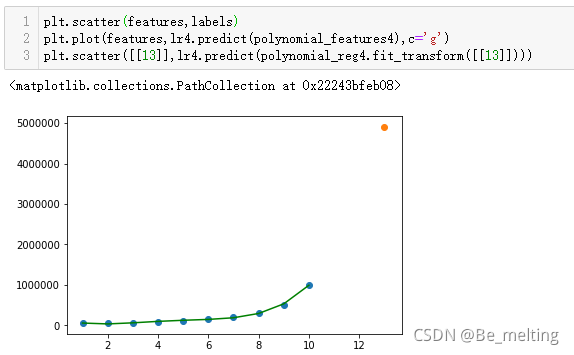
换一种展示的方式,用四次多项式模型来预测一个未见过的数据,通过图形更能体会到这种过拟合现象。