[源码解析] PyTorch 分布式 Autograd (6) ---- 引擎(下)
文章目录
0x00 摘要
上文我们介绍了引擎如何获得后向计算图的依赖,本文我们就接着看看引擎如何依据这些依赖进行后向传播。通过本文的学习,大家可以:
- 了解 RecvRpcBackward 如何给对应的下游节点发送 RPC 消息,可以再次梳理一下worker之间后向传播的交互流程。
- 了解 AccumulateGrad 如何在上下文累积梯度。
PyTorch分布式其他文章如下:
[ 源码解析] PyTorch 分布式(1)------历史和概述
源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[ 源码解析] PyTorch 分布式(3) ----- DataParallel(下)
[ 源码解析] PyTorch 分布式(4)------分布式应用基础概念
源码解析] PyTorch 分布式(5) ------ DistributedDataParallel 总述&如何使用
[ 源码解析] PyTorch分布式(6) —DistributedDataParallel – 初始化&store
[ 源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
[源码解析] PyTorch 分布式(8) -------- DistributedDataParallel之论文篇
[ 源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(10)------DistributedDataParallel之Reducer静态架构
[ 源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer和Join操作
源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
源码解析] PyTorch 分布式 Autograd (1) ---- 设计
源码解析] PyTorch 分布式 Autograd (2) ---- RPC基础
源码解析] PyTorch 分布式 Autograd (3) ---- 上下文相关
[源码解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
[源码解析] PyTorch 分布式 Autograd (5) ---- 引擎(上)
为了更好的说明,本文代码会依据具体情况来进行相应精简。
0x01 回顾
我们首先回顾FAST模式算法算法如下,本文需要讨论后面若干部分。
- 我们从具有反向传播根的worker开始(所有根都必须是本地的)。
- 查找当前Distributed Autograd Context 的所有
send函数 。 - 从提供的根和我们检索到的所有
send函数开始,我们在本地计算依赖项 。 - 计算依赖项后,使用提供的根来启动本地 autograd 引擎。
- 当 autograd 引擎执行该
recv函数时,该recv函数通过 RPC 将输入梯度发送到适当的worker。每个recv函数都知道目标 worker id,因为它被记录为前向传播的一部分。通过autograd_context_id和autograd_message_id该recv函数被发送到远程主机。 - 当远程主机收到这个请求时,我们使用
autograd_context_id和autograd_message_id来查找适当的send函数。 - 如果这是worker第一次收到对给定
autograd_context_id的请求,它将按照上面的第 1-3 点所述在本地计算依赖项。 - 然后将在第6点接受到的
send方法插入队列,以便在该worker的本地 autograd 引擎上执行。 - 最后,我们不是在 Tensor的
.grad之上累积梯度,而是在每个Distributed Autograd Context之上分别累积梯度 。梯度存储在Dict[Tensor, Tensor]之中 ,Dict[Tensor, Tensor]基本上是从 Tensor 到其关联梯度的映射,并且可以使用 get_gradients() API检索该映射 。
其次,我们看看总体执行代码,总体执行是在 DistEngine::execute 之中完成,具体分为如下步骤:
- 使用 contextId 得到前向的上下文。
- 使用 validateRootsAndRetrieveEdges 进行验证。
- 构造一个GraphRoot,用它来驱动后向传播,可以认为是一个虚拟根。
- 使用 computeDependencies 计算依赖。
- 使用 runEngineAndAccumulateGradients 进行反向传播计算。
- 使用 clearAndWaitForOutstandingRpcsAsync 等待 RPC 完成。
void DistEngine::execute(
int64_t contextId,
const variable_list& roots,
bool retainGraph) {
// Retrieve the context for the given context_id. This will throw if the
// context_id is invalid.
auto autogradContext =
DistAutogradContainer::getInstance().retrieveContext(contextId);
// Perform initial pre-processing.
edge_list rootEdges;
variable_list grads;
validateRootsAndRetrieveEdges(roots, rootEdges, grads);
// 构造一个GraphRoot,用它来驱动后向传播,可以认为是一个虚拟根
std::shared_ptr<Node> graphRoot =
std::make_shared<GraphRoot>(rootEdges, grads);
edge_list outputEdges;
// Compute dependencies locally, starting from all roots and all 'send'
// functions.
{
std::lock_guard<std::mutex> guard(initializedContextIdsLock_);
// Context should not have been initialized already.
TORCH_INTERNAL_ASSERT(
initializedContextIds_.find(autogradContext->contextId()) ==
initializedContextIds_.end());
// 计算依赖
computeDependencies(
autogradContext, rootEdges, grads, graphRoot, outputEdges, retainGraph);
// Mark the autograd context id as initialized.
initializedContextIds_.insert(autogradContext->contextId());
}
BackwardPassCleanupGuard guard(autogradContext);
// This needs to be blocking and as a result we wait for the future to
// complete.
runEngineAndAccumulateGradients(autogradContext, graphRoot, outputEdges)
->waitAndThrow(); // 反向传播计算
// Wait for all of the outstanding rpcs to complete.
autogradContext->clearAndWaitForOutstandingRpcsAsync()->waitAndThrow();
}
再次,从前文我们知道,依赖项已经在 computeDependencies 之中处理完毕,所有需要计算的函数信息都位于 GraphTask.exec_info_ 之上。我们接下来就看看如何计算,就是 runEngineAndAccumulateGradients 和 clearAndWaitForOutstandingRpcsAsync 这两个方法。
0x02 执行GraphTask
我们首先看看如何使用 runEngineAndAccumulateGradients 进行反向传播计算,累积梯度。
2.1 runEngineAndAccumulateGradients
引擎之中,首先调用了 runEngineAndAccumulateGradients。主要是封装了一个 NodeTask,然后以此调用 execute_graph_task_until_ready_queue_empty。其中使用 at::launch 来启动线程。
c10::intrusive_ptr<c10::ivalue::Future> DistEngine::
runEngineAndAccumulateGradients(
const ContextPtr& autogradContext,
const std::shared_ptr<Node>& graphRoot,
const edge_list& outputEdges,
bool incrementOutstandingTasks) {
// Cleanup previous state for outstanding RPCs. Outstanding RPCs could be
// lingering if we're running backward multiple times and some of the
// passes ran into errors.
autogradContext->clearOutstandingRpcs();
// 得到GraphTask
auto graphTask = autogradContext->retrieveGraphTask();
// 启动了一个线程来运行 execute_graph_task_until_ready_queue_empty
at::launch([this, graphTask, graphRoot, incrementOutstandingTasks]() {
execute_graph_task_until_ready_queue_empty(
/*node_task*/ NodeTask(graphTask, graphRoot, InputBuffer(0)),
/*incrementOutstandingTasks*/ incrementOutstandingTasks);
});
// Use a reference here to avoid refcount bump on futureGrads.
// 处理结果
auto& futureGrads = graphTask->future_result_;
// Build a future that waits for the callbacks to execute (since callbacks
// execute after the original future is completed). This ensures we return a
// future that waits for all gradient accumulation to finish.
auto accumulateGradFuture =
c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get());
futureGrads->addCallback(
[autogradContext, outputEdges, accumulateGradFuture](c10::ivalue::Future& futureGrads) {
if (futureGrads.hasError()) {
// 省略错误处理部分
return;
}
try {
const variable_list& grads =
futureGrads.constValue().toTensorVector();
// 标识已经结束
accumulateGradFuture->markCompleted(c10::IValue());
} catch (std::exception& e) {
accumulateGradFuture->setErrorIfNeeded(std::current_exception());
}
});
return accumulateGradFuture;
}
at::launch 位于 aten/src/ATen/ParallelThreadPoolNative.cpp,这里会在线程之中调用传入的 func。
void launch(std::function<void()> func) {
internal::launch_no_thread_state(std::bind([](
std::function<void()> f, ThreadLocalState thread_locals) {
ThreadLocalStateGuard guard(std::move(thread_locals));
f();
},
std::move(func),
ThreadLocalState()
));
}
namespace internal {
void launch_no_thread_state(std::function<void()> fn) {
#if AT_EXPERIMENTAL_SINGLE_THREAD_POOL
intraop_launch(std::move(fn));
#else
get_pool().run(std::move(fn));
#endif
}
}
我们接下来一一看看内部这几个方法如何执行。
2.2 execute_graph_task_until_ready_queue_empty
此函数类似 Engine::thread_main,通过一个 NodeTask 来完成本 GraphTask的执行,其中 evaluate_function 会不停的向 cpu_ready_queue 插入新的 NodeTask。engine_.evaluate_function 方法会:
- 首先,初始化原生引擎线程。
- 其次,每个调用建立一个 cpu_ready_queue,用来从root_to_execute开始遍历graph_task,这允许用不同的线程来对GraphTask并行执行,这是一个CPU相关的queue。
- 把传入的 node_task 插入到 cpu_ready_queue。
- 沿着反向计算图从根部开始,一直计算到叶子节点。
-
-
这里叶子节点都是 AccumulateGrad 或者 RecvRpcBackward。
-
如果是中间节点,则正常计算。
-
如果是 RecvRpcBackward 则会给对应的下游节点发送 RPC 消息。
-
如果是 AccumulateGrad,则在上下文累积梯度。
-
具体代码如下:
void DistEngine::execute_graph_task_until_ready_queue_empty(
NodeTask&& node_task,
bool incrementOutstandingTasks) {
// 初始化原生引擎线程
engine_.initialize_device_threads_pool();
// Create a ready queue per call to traverse the graph_task from
// root_to_execute This allow concurrent execution of the same GraphTask from
// different threads
// 每个调用建立一个 ready queue,用来从root_to_execute开始遍历graph_task,这允许用不同的线程来对GraphTask并行执行,这是一个CPU相关的queue
std::shared_ptr<ReadyQueue> cpu_ready_queue = std::make_shared<ReadyQueue>();
auto graph_task = node_task.base_.lock();
if (graph_task == nullptr) {
LOG(ERROR) << "GraphTask has expired for NodeTask: "
<< node_task.fn_->name() << ", skipping execution.";
return;
}
cpu_ready_queue->push(std::move(node_task), incrementOutstandingTasks);
torch::autograd::set_device(torch::autograd::CPU_DEVICE);
graph_task->owner_ = torch::autograd::CPU_DEVICE;
while (!cpu_ready_queue->empty()) {
std::shared_ptr<GraphTask> local_graph_task;
{
// Scope this block of execution since NodeTask is not needed after this
// block and can be deallocated (release any references to grad tensors
// as part of inputs_)
NodeTask task = cpu_ready_queue->pop(); // 取出一个NodeTask
if (!(local_graph_task = task.base_.lock())) {
continue;
}
if (task.fn_ && !local_graph_task->has_error_.load()) {
AutoGradMode grad_mode(local_graph_task->grad_mode_);
try {
GraphTaskGuard guard(local_graph_task);
engine_.evaluate_function( // 这里会调用具体Node对应的函数
local_graph_task, task.fn_.get(), task.inputs_, cpu_ready_queue);
} catch (std::exception& e) {
engine_.thread_on_exception(local_graph_task, task.fn_, e);
// break the loop in error so that we immediately stop the execution
// of this GraphTask, mark it completed if necessary and return the
// future with proper ErrorMessage
break;
}
}
}
// Decrement the outstanding task.
--local_graph_task->outstanding_tasks_; // 处理了一个NodeTask
}
// Check if we've completed execution.
if (graph_task->completed()) {
// We don't need to explicitly notify the owner thread, since
// 'mark_as_completed_and_run_post_processing' would mark the Future as
// completed and this would notify the owner thread that the task has been
// completed.
graph_task->mark_as_completed_and_run_post_processing();
}
}
另外,一共有三个地方调用 execute_graph_task_until_ready_queue_empty。
- runEngineAndAccumulateGradients 会调用,这里就是用户主动调用 backward 的情形,就是本节介绍的。
- executeSendFunctionAsync 会调用,这里对应了某节点从反向传播上一节点接受到梯度之后的操作,我们会在下一节介绍。
- globalCpuThread 会调用,这是CPU工作专用线程,我们马上会介绍。
- 在 Engine.evaluate_function 之中,会针对 AccumulateGrad 来累积梯度。
- 在 Engine.evaluate_function 之中,会调用 RecvRpcBackward 来向反向传播下游发送消息。
我们总结一下几个计算梯度的流程,分别对应下面三个数字。
User Training Script RPC BACKWARD_AUTOGRAD_REQ
+ +
| |
| 1 | 2
v v
backward RequestCallbackNoPython.processRpc
+ +
| |
| |
v v
DistEngine.execute RequestCallbackNoPython.processBackwardAutogradReq
+ +
| |
| |
| v
| +----------+ DistEngine.executeSendFunctionAsync
| | +
| | |
v v |
DistEngine.computeDependencies |
| |
| |
v |
DistEngine.runEngineAndAccumulateGradients | DistEngine.globalCpuThread
+ | +
| +------------------+ |
| | | 3
| | +------------------------+
| | |
| | |
v v v
DistEngine.execute_graph_task_until_ready_queue_empty
+
|
|
v
DistEngine.evaluate_function
+
|
+--------------------------------------------------------------+
| |
| 4 AccumulateGrad | 5 RecvRpcBackward
v v
(*hook)(captured_grad) call_function(graph_task, func, inputs)
2.3 evaluate_function
上面代码之中,实际上会调用原生引擎的 evaluate_function 来完成操作。
我们看看如何使用 exec_info_,如果没有设置为需要执行,则就不处理。在此处,我们可以看到 上文提到的recvBackwardEdges 如何与 exec_info_ 交互。
遍历 recvBackwardEdges,对于每个 recvBackward,在 GraphTask.exec_info_ 之中对应项之上设止为需要执行。
具体代码如下,这里会:
- 针对 AccumulateGrad 来累积梯度。
- 调用 RecvRpcBackward 来向反向传播下游发送消息。
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
auto& fn_info = exec_info_.at(func);
if (auto* capture_vec = fn_info.captures_.get()) {
// Lock mutex for writing to graph_task->captured_vars_.
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto& capture : *capture_vec) {
auto& captured_grad = graph_task->captured_vars_[capture.output_idx_];
captured_grad = inputs[capture.input_idx_];
for (auto& hook : capture.hooks_) {
captured_grad = (*hook)(captured_grad); //这里调用 hook,就是 DistAccumulateGradCaptureHook 的 operator(),captured_grad 就是累积的梯度
}
}
}
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return; // 如果没有设置需要执行,则直接返回。recvBackward 会设置需要执行
}
}
// 这里就是调用 recvBackward
auto outputs = call_function(graph_task, func, inputs);
// 后续代码省略
2.4 globalCpuThread
globalCpuThread 可以参见上文的 [GPU to CPU continuations] 一节,globalCpuThread是工作线程,其就是从 ready queue 里面弹出 NodeTask,然后执行。
对于globalCpuThread,其参数 ready_queue 是 global_cpu_ready_queue_
void DistEngine::globalCpuThread(
const std::shared_ptr<ReadyQueue>& ready_queue) {
while (true) {
NodeTask task = ready_queue->pop();
if (task.isShutdownTask_) {
// Need to shutdown this thread.
break;
}
auto graphTask = task.base_.lock();
if (graphTask == nullptr) {
// GraphTask has expired, ignore and continue processing.
continue;
}
// Launch the execution on a JIT thread.
at::launch([this,
graphTask,
graphRoot = task.fn_,
variables =
InputBuffer::variables(std::move(task.inputs_))]() mutable {
InputBuffer inputs(variables.size());
for (size_t i = 0; i < variables.size(); i++) {
inputs.add(i, std::move(variables[i]), c10::nullopt, c10::nullopt);
}
execute_graph_task_until_ready_queue_empty( // 这里会调用
/*node_task*/ NodeTask(graphTask, graphRoot, std::move(inputs)),
/*incrementOutstandingTasks*/ false);
});
}
}
对于普通引擎也会设置一个 cpu 专用 queue。
auto graph_task = std::make_shared<GraphTask>(
/* keep_graph */ keep_graph,
/* create_graph */ create_graph,
/* depth */ not_reentrant_backward_call ? 0 : total_depth + 1,
/* cpu_ready_queue */ local_ready_queue);
2.5 小结
对于分布式引擎,与普通引擎在计算部分主要不同之处为:
-
如果是 RecvRpcBackward 则会给对应的下游节点发送 RPC 消息。
-
如果是 AccumulateGrad,则在上下文累积梯度。
所以我们接下来看看具体这两部分如何处理。
0x03 RPC调用
在之前文章中,我们看到了接受方如何处理反向传播 RPC 调用,我们接下来看看引擎如何发起反向传播 RPC 调用,就是如何调用 recv 方法。
这里就适用于下面worker 0 调用 recv ,执行来到 worker 1 这种情况,对应设计文档中如下。
当 autograd 引擎执行该
recv函数时,该recv函数通过 RPC 将输入梯度发送到适当的worker。每个recv函数都知道目标 worker id,因为它被记录为前向传播的一部分。通过autograd_context_id和autograd_message_id该recv函数被发送到远程主机。
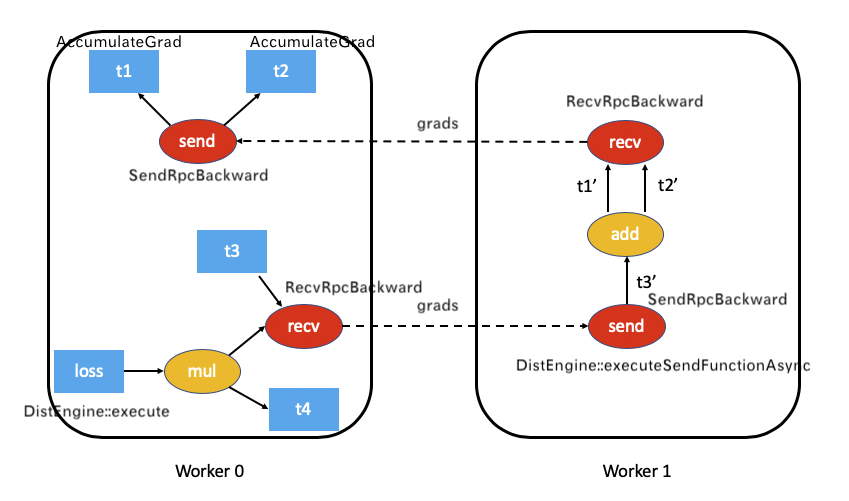
我们就看看如何执行 recv 函数。
具体结合到分布式引擎,就是当引擎发现某一个 Node 是 RecvRpcBackward,就调用其 apply 函数。
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
// 省略了梯度累积部分代码,具体可以参见上面章节
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return; // 如果没有设置需要执行,则直接返回。recvBackward 会设置需要执行
}
}
// 这里就是调用 recvBackward.apply 函数
auto outputs = call_function(graph_task, func, inputs);
// 后续代码省略
3.1 RecvRpcBackward
3.1.1 定义
RecvRpcBackward 定义如下,
class TORCH_API RecvRpcBackward : public torch::autograd::Node {
public:
explicit RecvRpcBackward(
const AutogradMetadata& autogradMetadata,
std::shared_ptr<DistAutogradContext> autogradContext,
rpc::worker_id_t fromWorkerId,
std::unordered_map<c10::Device, c10::Device> deviceMap);
torch::autograd::variable_list apply(
torch::autograd::variable_list&& grads) override;
private:
const AutogradMetadata autogradMetadata_;
// Hold a weak reference to the autograd context to avoid circular
// dependencies with the context (since it holds a reference to
// RecvRpcBackward).
std::weak_ptr<DistAutogradContext> autogradContext_;
// The worker id from which the RPC was received. During the backward pass,
// we need to propagate the gradients to this workerId.
rpc::worker_id_t fromWorkerId_;
// Device mapping for tensors sent over RPC.
const std::unordered_map<c10::Device, c10::Device> deviceMap_;
};
3.1.2 构建
构造函数如下。
RecvRpcBackward::RecvRpcBackward(
const AutogradMetadata& autogradMetadata,
ContextPtr autogradContext,
rpc::worker_id_t fromWorkerId,
std::unordered_map<c10::Device, c10::Device> deviceMap)
: autogradMetadata_(autogradMetadata),
autogradContext_(std::move(autogradContext)),
fromWorkerId_(fromWorkerId),
deviceMap_(std::move(deviceMap)) {
}
3.1.3 apply
torch/csrc/distributed/autograd/functions/recvrpc_backward.cpp 定义了其 apply 函数,其作用就是:
- 把传入的梯度 grads 放入outputGrads,因为要输出给下一环节。
- 构建 PropagateGradientsReq,这就是 BACKWARD_AUTOGRAD_REQ。
- 发送 RPC 给下一环节。
variable_list RecvRpcBackward::apply(variable_list&& grads) {
std::vector<Variable> outputGrads;
for (size_t i = 0; i < grads.size(); i++) {
// 下面就是把传入的梯度 grads 放入outputGrads
const auto& grad = grads[i];
if (grad.defined()) {
outputGrads.emplace_back(grad);
} else {
// Put in zeros for a tensor with no grad.
outputGrads.emplace_back(input_metadata(i).zeros_like());
}
}
auto sharedContext = autogradContext_.lock();
// Send the gradients over the wire and record the future in the autograd
// context.
PropagateGradientsReq gradCall( // 构建 PropagateGradientsReq
autogradMetadata_,
outputGrads,
sharedContext->retrieveGraphTask()->keep_graph_);
// Send the gradients over to the appropriate node.
auto rpcAgent = rpc::RpcAgent::getCurrentRpcAgent();
auto jitFuture = rpcAgent->send( // 发送 RPC
rpcAgent->getWorkerInfo(fromWorkerId_),
std::move(gradCall).toMessage(), // 调用了toMessageImpl
rpc::kUnsetRpcTimeout,
deviceMap_);
// Record the future in the context.
sharedContext->addOutstandingRpc(jitFuture);
// 'recv' function sends the gradients over the wire using RPC, it doesn't
// need to return anything for any downstream autograd function.
return variable_list();
}
因为这里发送了 PropagateGradientsReq,所以我们接着看。
3.2 PropagateGradientsReq
3.2.1 定义
PropagateGradientsReq 扩展了 RpcCommandBase。
// Used to propagate gradients from one node to another during a distributed
// backwards pass. This RPC call is invoked when we hit a `recv` autograd
// function during backward pass execution.
class TORCH_API PropagateGradientsReq : public rpc::RpcCommandBase {
public:
PropagateGradientsReq(
const AutogradMetadata& autogradMetadata,
std::vector<torch::autograd::Variable> grads,
bool retainGraph = false);
const AutogradMetadata& getAutogradMetadata();
const std::vector<torch::autograd::Variable>& getGrads();
// Serialization and deserialization methods.
rpc::Message toMessageImpl() && override;
static std::unique_ptr<PropagateGradientsReq> fromMessage(
const rpc::Message& message);
// Whether or not to retain the autograd graph.
bool retainGraph();
private:
AutogradMetadata autogradMetadata_;
std::vector<torch::autograd::Variable> grads_;
bool retainGraph_;
};
其 toMessageImpl 指明了本消息是 BACKWARD_AUTOGRAD_REQ。
Message PropagateGradientsReq::toMessageImpl() && {
std::vector<at::IValue> ivalues;
// Add all the grad tensors.
for (const auto& grad : grads_) {
ivalues.emplace_back(grad);
}
// Now add autograd metadata.
ivalues.emplace_back(autogradMetadata_.autogradContextId);
ivalues.emplace_back(autogradMetadata_.autogradMessageId);
// Add retain graph.
ivalues.emplace_back(retainGraph_);
// Now pickle using JIT pickler.
std::vector<torch::Tensor> tensorTable;
std::vector<char> payload =
jit::pickle(c10::ivalue::Tuple::create(std::move(ivalues)), &tensorTable);
return Message(
std::move(payload),
std::move(tensorTable),
MessageType::BACKWARD_AUTOGRAD_REQ); // 这里指明了消息类型。
}
3.3 接受方
为了论述完整,我们接下来看看接收方如何处理反向传播。
3.3.1 接受消息
在生成 TensorPipeAgent 时候,把 RequestCallbackImpl 配置为回调函数。这是 agent 的统一响应函数。前面关于代理接收逻辑时候,我们也提到了,会进入 RequestCallbackNoPython::processRpc 函数。其中可以看到有对 BACKWARD_AUTOGRAD_REQ 的处理逻辑。
这种是 RPC 的正常流程。
void RequestCallbackNoPython::processRpc(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
switch (messageType) {
case MessageType::BACKWARD_AUTOGRAD_REQ: {
processBackwardAutogradReq(rpc, messageId, responseFuture); // 这里调用
return;
};
3.3.2 processBackwardAutogradReq
在 processBackwardAutogradReq 之中会:
- 获取 DistAutogradContainer。
- 获取 上下文。
- 调用 executeSendFunctionAsync 进行引擎处理。
由此,我们可以看到有两个途径进入引擎:
- 一个是示例代码显式主动调用 backward,进而调用到 DistEngine::getInstance().execute,就是 worker 0。
- 一个是被动调用 DistEngine::getInstance().executeSendFunctionAsync,就是 worker 1。
void RequestCallbackNoPython::processBackwardAutogradReq(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const {
auto& gradientsCall = static_cast<PropagateGradientsReq&>(rpc);
const auto& autogradMetadata = gradientsCall.getAutogradMetadata();
// Retrieve the appropriate autograd context.
auto autogradContext = DistAutogradContainer::getInstance().retrieveContext(
autogradMetadata.autogradContextId); // 得到发送者的context id
// Lookup the appropriate 'send' function to enqueue.
std::shared_ptr<SendRpcBackward> sendFunction = // 依据发送者context id和消息id得到sendFunction
autogradContext->retrieveSendFunction(autogradMetadata.autogradMessageId);
// Attach the gradients to the send function.
sendFunction->setGrads(gradientsCall.getGrads()); // 设置梯度
// Now execute the autograd graph using the "distributed engine."
auto execFuture = DistEngine::getInstance().executeSendFunctionAsync( // 调用引擎
autogradContext, sendFunction, gradientsCall.retainGraph());
// Our response is satisfied when the rpcs come back.
execFuture->addCallback([responseFuture, messageId](JitFuture& execFuture) {
if (!execFuture.hasError()) {
Message m = std::move(PropagateGradientsResp()).toMessage();
m.setId(messageId);
responseFuture->markCompleted(
IValue(c10::make_intrusive<Message>(std::move(m))));
} else {
responseFuture->setError(execFuture.exception_ptr());
}
});
}
3.3.3 executeSendFunctionAsync
executeSendFunctionAsync 这里开始进入了引擎,注意,这里是接收方也进入了引擎,在接收方上进行计算。executeSendFunctionAsync 会直接调用 execute_graph_task_until_ready_queue_empty,也可能先计算依赖然后继续执行。此处可以参考设计之中的:
- 6)当远程主机收到这个请求时,我们使用
autograd_context_id和autograd_message_id来查找适当的send函数。 - 7)如果这是worker第一次收到对给定
autograd_context_id的请求,它将按照上面的第 1-3 点所述在本地计算依赖项。 - 8)然后将在第6点接受到的
send方法插入队列,以便在该worker的本地 autograd 引擎上执行。
具体代码如下:
c10::intrusive_ptr<c10::ivalue::Future> DistEngine::executeSendFunctionAsync(
const ContextPtr& autogradContext,
const std::shared_ptr<SendRpcBackward>& sendFunction,
bool retainGraph) {
// Typically the local autograd engine ensures stream synchronizations between
// nodes in the graph. However, for distributed autograd the sendFunction
// inputs might have been retrieved over the wire on a separate stream and the
// sendFunction itself runs on a different stream. As a result, we need to
// manually synchronize those two streams here.
const auto& send_backward_stream = sendFunction->stream(c10::DeviceType::CUDA);
if (send_backward_stream) {
// 拿到本次执行对应的Stream
for (const auto& grad : sendFunction->getGrads()) {
const auto guard = c10::impl::VirtualGuardImpl{
c10::DeviceType::CUDA};
const auto default_stream = guard.getStream(grad.device());
if (send_backward_stream != default_stream) {
auto event = c10::Event{
c10::DeviceType::CUDA};
event.record(default_stream);
send_backward_stream->wait(event); // 需要同步,保证当前操作完成
}
}
}
std::unique_lock<std::mutex> lock(initializedContextIdsLock_);
if (initializedContextIds_.find(autogradContext->contextId()) ==
initializedContextIds_.end()) {
// 遍历,查找sendFunction对应的上下文是否在本节点之中已经记录
// 没有找到上下文,需要计算依赖
edge_list outputEdges;
// Pass in a dummy graphRoot since all send functions are the roots.
auto dummyRoot = std::make_shared<GraphRoot>(edge_list(), variable_list());
computeDependencies( // 计算依赖
autogradContext, {
}, {
}, dummyRoot, outputEdges, retainGraph);
// Mark the autograd context id as initialized and unlock.
initializedContextIds_.insert(autogradContext->contextId());
lock.unlock();
// Enqueue the current send function.
auto graphTask = autogradContext->retrieveGraphTask();
// Run the autograd engine.
auto accumulateGradFuture = runEngineAndAccumulateGradients( // 计算梯度
autogradContext,
sendFunction,
outputEdges,
/*incrementOutstandingTasks=*/false);
// Build the 'uber' future that waits for everything.
auto callbackFuture =
c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get());
// 注册回调
accumulateGradFuture->addCallback([autogradContext,
callbackFuture](c10::ivalue::Future& accumulateGradFuture) {
try {
if (accumulateGradFuture.hasError()) {
// Perform cleanup at the end of the backward pass (before we mark
// the future as completed).
DistEngine::getInstance().cleanupBackwardPass(autogradContext);
// Skip any further processing on errors.
callbackFuture->setError(accumulateGradFuture.exception_ptr());
return;
}
// Wait for all RPCs after the autograd engine is done.
auto rpcFuture = autogradContext->clearAndWaitForOutstandingRpcsAsync();
rpcFuture->addCallback([callbackFuture, autogradContext](c10::ivalue::Future& rpcFuture) {
try {
// Perform cleanup at the end of the backward pass (before
// we mark the future as completed).
DistEngine::getInstance().cleanupBackwardPass(autogradContext);
} catch (std::exception& e) {
callbackFuture->setErrorIfNeeded(std::current_exception());
return;
}
// Finally mark the 'uber' future as completed.
if (!rpcFuture.hasError()) {
callbackFuture->markCompleted(c10::IValue());
} else {
callbackFuture->setError(rpcFuture.exception_ptr());
}
});
} catch (std::exception& e) {
callbackFuture->setErrorIfNeeded(std::current_exception());
}
});
// Return the future which waits for all async processing to be done.
return callbackFuture;
} else {
// 可以在当前Node找到上下文
lock.unlock();
auto graphTask = autogradContext->retrieveGraphTask();
at::launch([this, graphTask, sendFunction]() {
execute_graph_task_until_ready_queue_empty(
/*node_task*/ NodeTask(graphTask, sendFunction, InputBuffer(0)),
/*incrementOutstandingTasks*/ false);
});
auto fut = c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get());
fut->markCompleted(c10::IValue());
return fut;
}
}
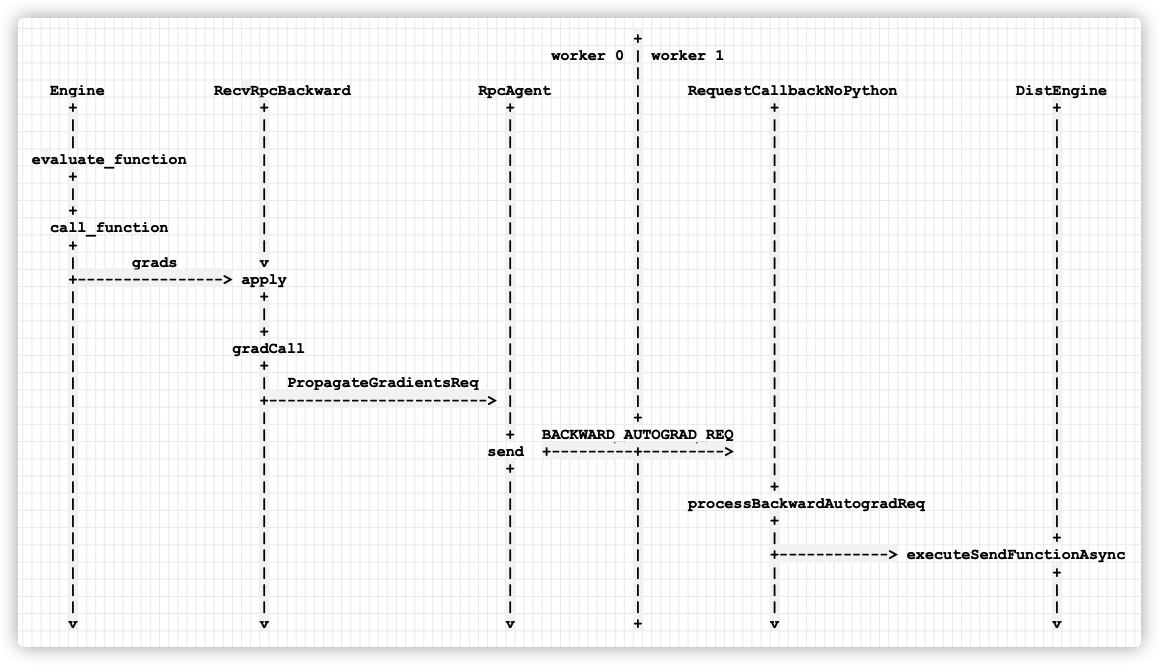
具体如下图:
+
worker 0 | worker 1
|
Engine RecvRpcBackward RpcAgent | RequestCallbackNoPython DistEngine
+ + + | + +
| | | | | |
| | | | | |
evaluate_function | | | | |
+ | | | | |
| | | | | |
+ | | | | |
call_function | | | | |
+ | | | | |
| grads v | | | |
+----------------> apply | | | |
| + | | | |
| | | | | |
| + | | | |
| gradCall | | | |
| + | | | |
| | PropagateGradientsReq | | | |
| +------------------------> | | | |
| | | + | |
| | + BACKWARD_AUTOGRAD_REQ | |
| | send +---------+---------> | |
| | + | | |
| | | | + |
| | | | processBackwardAutogradReq |
| | | | + |
| | | | | +
| | | | +------------> executeSendFunctionAsync
| | | | | +
| | | | | |
| | | | | |
v v v + v v
手机如下:
0x04 DistAccumulateGradCaptureHook
目前看起来总体逻辑已经完成了,但是实际上缺了一块,对应了设计文档中的:
最后,我们不是在 Tensor的
.grad之上累积梯度,而是在每个Distributed Autograd Context之上分别累积梯度 。梯度存储在Dict[Tensor, Tensor]之中 ,Dict[Tensor, Tensor]基本上是从 Tensor 到其关联梯度的映射,并且可以使用 get_gradients() API检索该映射 。
就是把异地/本地的梯度累积到本地上下文之中,所以我们再分析一下 DistAccumulateGradCaptureHook。
4.1 定义
DistAccumulateGradCaptureHook 有三个作用:
-
调用原始AccumulateGrad的 pre hooks 来修改输入梯度。
-
将 grad 累积到RPC上下文。
-
调用原始AccumulateGrad的 post hooks。
其定义如下:
// This hook does 3 things:
// 1. Call pre hooks of the original AccumulateGrad to modify the input grad.
// 2. Accumuate the gard to RPC context.
// 3. Call post hooks of the original AccumulateGrad.
class DistAccumulateGradCaptureHook
: public GraphTask::ExecInfo::Capture::GradCaptureHook {
public:
DistAccumulateGradCaptureHook(
std::shared_ptr<AccumulateGrad> accumulateGrad,
ContextPtr autogradContext)
: accumulateGrad_(std::move(accumulateGrad)),
autogradContext_(std::move(autogradContext)) {
}
at::Tensor operator()(const at::Tensor& grad) override {
ThreadLocalDistAutogradContext contextGuard{
ContextPtr(autogradContext_)};
variable_list inputGrads = {
grad};
// It's intended that pre/post hooks are still called even if the grad is
// undenfined here.
for (const auto& hook : accumulateGrad_->pre_hooks()) {
inputGrads = (*hook)(inputGrads); // 调用 pre-hooks
}
// It is possible that the grad is not defined since a separate
// invocation of the autograd engine on the same node might actually
// compute this gradient.
if (inputGrads[0].defined()) {
// There are 3 internal references to 'inputGrads[0]' at this moment:
// 1. 'inputGrads[0]' in this function.
// 2. 'graph_task->captured_vars_' on the callsite in the local engine.
// 3. 'InputBuffer& inputs' on the callsite as the inputs of the
// function node.
autogradContext_->accumulateGrad( // 累积梯度
accumulateGrad_->variable, inputGrads[0], 3 /* num_expected_refs */);
}
const variable_list kEmptyOuput;
for (const auto& hook : accumulateGrad_->post_hooks()) {
(*hook)(kEmptyOuput, inputGrads); // 调用 post-hooks
}
return inputGrads[0];
}
private:
std::shared_ptr<AccumulateGrad> accumulateGrad_; // 这就是需要累积的目标向量,后续操作在其之上
ContextPtr autogradContext_;
};
4.2 生成
如何生成 DistAccumulateGradCaptureHook?计算依赖时候生成 DistAccumulateGradCaptureHook,但是记录在 capture.hooks_.push_back 之中。
这里是为了处理 AccumulateGrad。
-
AccumulateGrad 一定是叶子节点,不需执行,而需要在其上积累梯度,但是RecvRpcBackward需要执行。
-
AccumulateGrad 就保存在 DistAccumulateGradCaptureHook 之中。
void DistEngine::computeDependencies(
const ContextPtr& autogradContext,
const edge_list& rootEdges,
const variable_list& grads,
const std::shared_ptr<Node>& graphRoot,
edge_list& outputEdges,
bool retainGraph) {
if (!outputEdges.empty()) {
// Compute 'needed execution' starting from all 'send' functions and the
// original graphRoot.
edge_list edges;
// Create some dummy edges (input_nr not important for init_to_execute).
for (const auto& mapEntry : sendFunctions) {
edges.emplace_back(mapEntry.second, 0);
}
// Add the original graphRoot as an edge.
edges.emplace_back(graphRoot, 0);
// Create a dummy GraphRoot and run init_to_execute with it.
GraphRoot dummyRoot(edges, {
});
graphTask->init_to_execute(dummyRoot, outputEdges, /*accumulate_grad=*/false, /*min_topo_nr=*/0);
for (auto& mapEntry : graphTask->exec_info_) {
auto& execInfo = mapEntry.second;
if (!execInfo.captures_) {
continue;
}
auto fn = mapEntry.first;
// There may be nodes other than 'AccumulateGrad', e.g. RecvRPCBackward,
// to be captured.
if (auto accumulateGradFn = dynamic_cast<AccumulateGrad*>(fn)) {
for (auto& capture : *execInfo.captures_) {
capture.hooks_.push_back( // 这里会生成
std::make_unique<DistAccumulateGradCaptureHook>(
std::dynamic_pointer_cast<AccumulateGrad>( // 会保存 AccumulateGrad
accumulateGradFn->shared_from_this()),
autogradContext));
}
}
}
// Mark all 'RecvRPCBackward' as needing execution.
for (const auto& recvBackwardEdge : recvBackwardEdges) {
graphTask->exec_info_[recvBackwardEdge.function.get()].needed_ = true;
}
}
}
4.3 使用
代码是缩减版。
首先,execute_graph_task_until_ready_queue_empty 会调用到原始引擎 engine_.evaluate_function。
void DistEngine::execute_graph_task_until_ready_queue_empty(
NodeTask&& node_task,
bool incrementOutstandingTasks) {
while (!cpu_ready_queue->empty()) {
std::shared_ptr<GraphTask> local_graph_task;
{
NodeTask task = cpu_ready_queue->pop();
if (task.fn_ && !local_graph_task->has_error_.load()) {
AutoGradMode grad_mode(local_graph_task->grad_mode_);
GraphTaskGuard guard(local_graph_task);
engine_.evaluate_function( // 调用原始引擎
local_graph_task, task.fn_.get(), task.inputs_, cpu_ready_queue);
}
}
// Decrement the outstanding task.
--local_graph_task->outstanding_tasks_;
}
}
其次,原始引擎代码之中,会调用hooks。
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
auto& fn_info = exec_info_.at(func);
if (auto* capture_vec = fn_info.captures_.get()) {
// Lock mutex for writing to graph_task->captured_vars_.
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto& capture : *capture_vec) {
auto& captured_grad = graph_task->captured_vars_[capture.output_idx_];
captured_grad = inputs[capture.input_idx_];
for (auto& hook : capture.hooks_) {
captured_grad = (*hook)(captured_grad); // 这里调用 hook,就是 DistAccumulateGradCaptureHook 的 operator(),captured_grad 就是累积的梯度
}
}
}
}
// 后续省略
DistAccumulateGradCaptureHook 的 operator() 方法之中,会调用下面来累积梯度。
autogradContext_->accumulateGrad(
accumulateGrad_->variable, inputGrads[0], 3 /* num_expected_refs */);
4.4 累积梯度
4.4.1 上下文累积
void DistAutogradContext::accumulateGrad(
const torch::autograd::Variable& variable, // variable就是目标变量
const torch::Tensor& grad, // grad就是梯度,需要累积到variable之上
size_t num_expected_refs) {
std::lock_guard<std::mutex> guard(lock_);
auto it = accumulatedGrads_.find(variable);
at::Tensor old_grad;
if (it != accumulatedGrads_.end()) {
// Accumulate multiple grads on the same variable.
old_grad = it->value();
}
// Gradients are computed using the forward streams. Local autograd
// engine uses AccumulateGrad function to retrieve and apply forward
// stream during the backward computation. In distributed autograd,
// we directly call AccumulateGrad::accumulateGrad, and skip the
// CUDA stream restoration from autograd function. Hence, we manually
// call it here to get the streams correct.
auto forward_stream =
torch::autograd::impl::grad_accumulator(variable)->stream(
grad.device().type());
c10::OptionalStreamGuard stream_guard(forward_stream);
// No higher order gradients supported in distributed autograd.
AutoGradMode grad_mode(false);
at::Tensor new_grad = AccumulateGrad::callHooks(variable, grad); // 计算
AccumulateGrad::accumulateGrad( // 调用算子函数来累积梯度
variable,
old_grad,
new_grad,
// Add +1 here since we can't std::move(grad) when call
// AccumulateGrad::callHooks, since it is a const ref, and that incurs a
// refcount bump for the new_grad.
num_expected_refs + 1,
[this, &variable](at::Tensor&& grad_update) {
auto device = grad_update.device();
accumulatedGrads_.insert(variable, std::move(grad_update));
recordGradEvent(device);
});
}
4.4.2 算子累积
代码位于 torch/csrc/autograd/functions/accumulate_grad.h。AccumulateGrad 的定义如下:
struct TORCH_API AccumulateGrad : public Node {
explicit AccumulateGrad(Variable variable_);
variable_list apply(variable_list&& grads) override;
static at::Tensor callHooks(
const Variable& variable,
at::Tensor new_grad) {
for (auto& hook : impl::hooks(variable)) {
new_grad = (*hook)({
new_grad})[0];
}
return new_grad;
}
// Given a variable with its current grad as variable_grad, accumulates
// new_grad into variable_grad if in place accumulation is possible.
// Otherwise, uses 'update_grad' to update the grad for the variable.
// "Gradient Layout Contract"
//
// AccumulateGrad tries to stash strided (non-sparse) grads with memory layout
// (strides) such that variables and grads interact efficiently in later
// optimizer kernels, and grads interact efficiently with c10d::Reducer.cpp.
//
// Specifically, AccumulateGrad tries to ensure the following
// (cf torch/csrc/autograd/utils/grad_layout_contract.h):
// (1) if variable.is_non_overlapping_and_dense(), the stashed grad's
// strides match variable.
// (2) else, stashed grad is rowmajor contiguous.
// If variable's grad does not exist (!variable_grad.defined())
// AccumulateGrad steals new_grad if it's stealable and obeys the contract
// already, otherwise it deep copies new_grad into an obedient clone.
//
// If variable's grad already exists (variable_grad.defined()), new_grad must
// be added to variable_grad. If we aren't setting up for double backward
// (!GradMode::is_enabled()), AccumulateGrad performs "variable_grad += new_grad"
// in-place, which keeps variable_grad's layout. We assume (hope) variable_grad
// was created obeying (1) or (2) at some point in the past.
//
// If we are setting up for double backward, AccumulateGrad updates the grad
// out-of-place via "variable_grad + new_grad." TensorIterator operator+ decides
// result's layout. Typically TensorIterator matches strides of the first arg,
// so we once again assume (hope) variable_grad was originally created obeying
// (1) or (2).
//
// AccumulateGrad does not enforce the contract with 100% certainty. Examples:
// - If a user manually permutes a param or its grad, then runs a fwd+bwd,
// variable_grad += new_grad keeps variable_grad's layout without rechecking
// the contract.
// - If TensorIterator changes its corner cases about operator+'s result
// (for example, giving more or less priority to channels_last inputs, see
// https://github.com/pytorch/pytorch/pull/37968) the result may not obey.
//
// Fortunately, if a given grad doesn't satisfy (1) or (2), the penalty is
// degraded performance in Reducer.cpp or optimizer kernels, not death by
// assert or silently bad numerics.
// variable: the variable whose grad we're accumulating.
// variable_grad: the current grad for the variable.
// new_grad: new grad we want to acummulate for the variable.
// num_expected_refs: the number of refs we expect to hold internally
// such that it is safe to avoid cloning the grad
// if use_count() of the grad is less than or equal
// to this value (in addition to post_hooks).
// update_grad: Function that is used to update grad for the variable.
// The argument to the function is a Tensor which
// is used to set a new value for the grad.
template <typename T>
static void accumulateGrad( // 这里会进行具体的累积梯度
const Variable& variable,
at::Tensor& variable_grad,
const at::Tensor& new_grad,
size_t num_expected_refs,
const T& update_grad) {
if (!variable_grad.defined()) {
if (!GradMode::is_enabled() &&
!new_grad.is_sparse() &&
new_grad.use_count() <= num_expected_refs &&
(new_grad.is_mkldnn() || utils::obeys_layout_contract(new_grad, variable))) {
// we aren't setting up for double-backward
// not sparse
// no other user-visible tensor references new_grad
// new_grad obeys the "Gradient Layout Contract", there has a special case,
// For MKLDNN tensor, which is a opaque tensor, assuming it obeys layout_contract.
// Under these conditions, we can steal new_grad without a deep copy.
update_grad(new_grad.detach());
} else if (
!GradMode::is_enabled() && new_grad.is_sparse() &&
new_grad._indices().is_contiguous() &&
new_grad._values().is_contiguous() &&
// Use count for indices and values should always be <=1 since the
// SparseTensor should be the only one holding a reference to these.
new_grad._indices().use_count() <= 1 &&
new_grad._values().use_count() <= 1 &&
new_grad.use_count() <= num_expected_refs) {
// Can't detach sparse tensor (since metadata changes are not allowed
// after detach), so just create a new one for the grad which is a
// shallow copy. We need a shallow copy so that modifying the original
// grad tensor doesn't modify the grad we accumulate.
// We only skip clone if indices and values themselves are contiguous
// for backward compatiblity reasons. Since without this optimization,
// earlier we would clone the entire SparseTensor which cloned indices
// and values.
// For details see https://github.com/pytorch/pytorch/issues/34375.
update_grad(at::_sparse_coo_tensor_unsafe(
new_grad._indices(),
new_grad._values(),
new_grad.sizes(),
new_grad.options()));
} else {
if (new_grad.is_sparse()) {
update_grad(new_grad.clone());
} else {
if (new_grad.is_mkldnn()) {
update_grad(new_grad.clone());
} else {
// Deep copies new_grad according to the "Gradient Layout Contract."
update_grad(utils::clone_obey_contract(new_grad, variable));
}
}
}
} else if (!GradMode::is_enabled()) {
// This case is not strictly necessary, but it makes the first-order only
// case slightly more efficient.
if (variable_grad.is_sparse() && !new_grad.is_sparse()) {
// If `variable_grad` is sparse and `new_grad` is not sparse, their
// sum is not sparse, and we must change the TensorImpl type of
// `variable_grad` for it to store the result. However, changing the
// TensorImpl type of a tensor requires changing the tensor itself, and
// thus in this case we have to change the grad tensor.
auto result = new_grad + variable_grad;
CHECK_RESULT(result, variable);
update_grad(std::move(result));
} else if (!at::inplaceIsVmapCompatible(variable_grad, new_grad)) {
// Ideally we'd perform an in-place operation to avoid changing
// the grad tensor. However, if that's impossible because the grads
// are vmap-incompatible (See NOTE: [vmap-incompatible in-place operations]),
// then we just add them out-of-place.
auto result = variable_grad + new_grad;
CHECK_RESULT(result, variable);
update_grad(std::move(result));
} else {
// In this case we can avoid changing the grad tensor. There are three
// scenarios when we'll hit this case:
//
// 1. `variable_grad` is sparse, and `new_grad` is sparse.
// 2. `variable_grad` is dense, and `new_grad` is sparse.
// 3. `variable_grad` is dense, and `new_grad` is dense.
// 4. `variable_grad` is mkldnn, and `new_grad` is mkldnn.
//
// In all of these four cases, `variable_grad += new_grad` is a
// valid operation which adds `new_grad` to `variable_grad` in
// place. `variable_grad` is thus still referring to the same tensor
// after the operation.
// Also DistributedDataParallel(DDP) package relies on grad being
// mutated in place for saving peak memory usage. DDP will still
// work correctly if it is mutated out of place here, but DDP will
// maintain one extra copy of grad tensors in buffer and thus
// increase peak memory usage.
variable_grad += new_grad;
CHECK_RESULT(variable_grad, variable);
// ^ We could enforce the contract more aggressively here by writing:
// if (variable_grad.is_sparse() || new_grad.is_sparse()) {
// variable_grad += new_grad;
// } else if (obeys_layout_contract(variable_grad, variable)) {
// variable_grad += new_grad;
// } else {
// result = at::empty_strided(variable.sizes(), variable.strides(),
// variable.options().memory_format(c10::nullopt));
// update_grad(at::native::add_out(result, variable_grad, new_grad, 1.0);
// }
// However, that accumulation is sometimes in place and sometimes not,
// which may break user code.
}
} else {
at::Tensor result;
if (variable_grad.is_sparse() && !new_grad.is_sparse()) {
// CPU backend throws an error on sparse + dense, so prefer dense + sparse here.
result = new_grad + variable_grad;
} else {
// Assumes operator+ result typically matches strides of first arg,
// and hopes variable_grad was originally created obeying layout contract.
result = variable_grad + new_grad;
}
CHECK_RESULT(result, variable);
update_grad(std::move(result));
// ^ We could enforce the contract more aggressively here by saying
// if (obeys_layout_contract(new_grad, variable)) {
// update_grad(new_grad + variable_grad);
// } else {
// update_grad(variable_grad + new_grad);
// }
// such that the stashed grad is likely to have the right strides if
// either variable_grad or new_grad already has the right strides.
// We could enforce the contract with certainty by saying
// auto result = variable_grad + new_grad (or vice versa), checking result's
// layout, and copying to an obedient clone if necessary before update_grad.
// The copy would require another gmem pass. We can't create empty result with
// the right layout then add_out into it with a single kernel, because GradMode
// is enabled in this branch, and add_out isn't differentiable.
// Maybe more trouble than it's worth.
}
}
Variable variable;
};
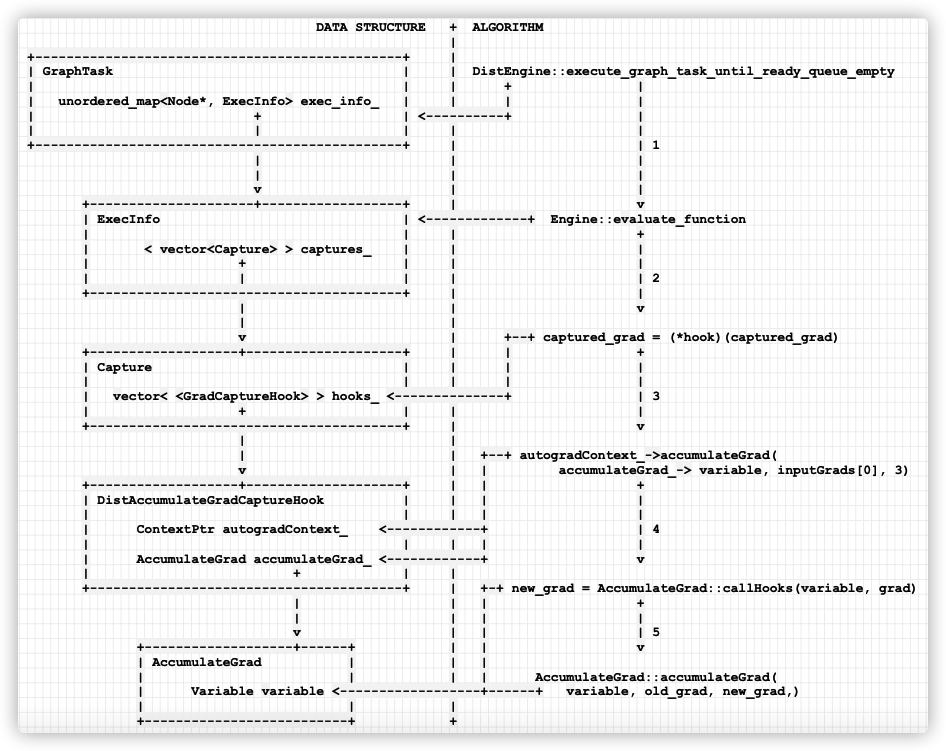
具体可以如下图所示,左边是数据结构,右面是算法流程,右面的序号表示执行从上至下,执行过程之中会用到左边的数据结构,算法与数据结构的调用关系由横向箭头表示。
- 分布式引擎调用execute_graph_task_until_ready_queue_empty来执行具体的 GraphTask。
- Engine::evaluate_function 会调用 GraphTask 之中的 ExecInfo。
- 然后会访问 GradCaptureHook,调用hook,hook 的 operator函数会调用到 autogradContext_->accumulateGrad。
- autogradContext_ 会执行 accumulateGrad,对 hook(DistAccumulateGradCaptureHook)之中保存的 accumulateGrad_ 做操作。
- AccumulateGrad::accumulateGrad 会完成最终的梯度更新操作。
DATA STRUCTURE + ALGORITHM
|
+-----------------------------------------------+ |
| GraphTask | | DistEngine::execute_graph_task_until_ready_queue_empty
| | | + |
| unordered_map<Node*, ExecInfo> exec_info_ | | | |
| + | <----------+ |
| | | | |
+-----------------------------------------------+ | | 1
| | |
| | |
v | |
+---------------------+------------------+ | v
| ExecInfo | <-------------+ Engine::evaluate_function
| | | +
| < vector<Capture> > captures_ | | |
| + | | |
| | | | | 2
+----------------------------------------+ | |
| | v
| |
v | +--+ captured_grad = (*hook)(captured_grad)
+-------------------+--------------------+ | | +
| Capture | | | |
| | | | |
| vector< <GradCaptureHook> > hooks_ <--------------+ | 3
| + | | |
+----------------------------------------+ | v
| |
| | +--+ autogradContext_->accumulateGrad(
v | | accumulateGrad_-> variable, inputGrads[0], 3)
+-------------------+--------------------+ | | +
| DistAccumulateGradCaptureHook | | | |
| | | | |
| ContextPtr autogradContext_ <------------+ | 4
| | | | |
| AccumulateGrad accumulateGrad_ <------------+ v
| + | |
+----------------------------------------+ | +-+ new_grad = AccumulateGrad::callHooks(variable, grad)
| | | +
| | | |
v | | | 5
+-------------------+------+ | | v
| AccumulateGrad | | |
| | | | AccumulateGrad::accumulateGrad(
| Variable variable <------------------+------+ variable, old_grad, new_grad,)
| | |
+--------------------------+ +
手机如下:
0x05 等待完成
最后,分布式引擎会调用 clearAndWaitForOutstandingRpcsAsync 来等待处理完成。
c10::intrusive_ptr<c10::ivalue::Future> DistAutogradContext::
clearAndWaitForOutstandingRpcsAsync() {
std::unique_lock<std::mutex> lock(lock_);
auto outStandingRpcs = std::move(outStandingRpcs_);
lock.unlock();
struct State {
explicit State(int32_t count)
: future(
c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get())),
remaining(count) {
}
c10::intrusive_ptr<c10::ivalue::Future> future;
std::atomic<int32_t> remaining;
std::atomic<bool> alreadySentError{
false};
};
auto state = std::make_shared<State>(outStandingRpcs.size());
if (outStandingRpcs.empty()) {
state->future->markCompleted(c10::IValue());
} else {
for (auto& rpc : outStandingRpcs) {
rpc->addCallback([state](rpc::JitFuture& future) {
if (future.hasError()) {
// If there's an error, we want to setError() on the future,
// unless another error has already been sent - use a CAS to
// guard.
//
// Don't decrement num remaining here! (We don't need to, since
// memory handling is separate). If we simply don't decrement on
// errors, reaching 0 means that there were no errors - and hence,
// we can just markCompleted() without any other checking there.
bool expectedAlreadySent = false;
if (state->alreadySentError.compare_exchange_strong(
expectedAlreadySent, true)) {
state->future->setError(future.exception_ptr());
}
return;
}
if (--state->remaining == 0) {
state->future->markCompleted(c10::IValue());
}
});
}
}
return state->future;
}
支持,分布式 autograd 全部分析完毕,前面说过,分布式处理有四大金刚,我们简介了 RPC,RRef,分析了分布式引擎,从下一篇开始,我们开始分析剩下的分布式优化器,此系列可能包括4~6篇。
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。

0xFF 参考
https://pytorch.org/docs/stable/distributed.html
https://pytorch.apachecn.org/docs/1.7/59.html
https://pytorch.org/docs/stable/distributed.html#module-torch.distributed
https://pytorch.org/docs/master/notes/autograd.html
https://pytorch.org/docs/master/rpc/distributed_autograd.html
https://pytorch.org/docs/master/rpc/rpc.html
https://www.w3cschool.cn/pytorch/pytorch-cdva3buf.html
Getting started with Distributed RPC Framework
Implementing a Parameter Server using Distributed RPC Framework
Combining Distributed DataParallel with Distributed RPC Framework