[源码解析] PyTorch 分布式 Autograd (2) ---- RPC基础
文章目录
0x00 摘要
前文我们给出了分布式autograd的设计思路,本文开始,我们进行具体源码分析。因为无论是前向传播还是反向传播,都需要依赖 RPC 来完成,所以我们先看看封装于 RPC 之上的一些基本功能,比如初始化,代理(RPC 相关功能都是基于代理完成),消息接受,发送等等。
通过本文,大家可以了解:如何初始化RPC后端,如何生成 RPC 代理,如何使用RPC代理进行发送和接受,如何连接远端 dist.autograd 自动微分引擎。
PyTorch分布式其他文章如下:
[ 源码解析] PyTorch 分布式(1)------历史和概述
源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[ 源码解析] PyTorch 分布式(3) ----- DataParallel(下)
[ 源码解析] PyTorch 分布式(4)------分布式应用基础概念
源码解析] PyTorch 分布式(5) ------ DistributedDataParallel 总述&如何使用
[ 源码解析] PyTorch分布式(6) —DistributedDataParallel – 初始化&store
[ 源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
[源码解析] PyTorch 分布式(8) -------- DistributedDataParallel之论文篇
[ 源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(10)------DistributedDataParallel之Reducer静态架构
[ 源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer和Join操作
源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
源码解析] PyTorch 分布式 Autograd (1) ---- 设计
为了更好的说明,本文代码会依据具体情况来进行相应精简。
0x01 示例
我们从 PyTorch 示例部分之中摘录示例代码并且修改了一些,代码目的是让两个 worker 之间就通过 RPC 进行协作。示例 worker 具体分为两部分:
- RPC操作,构建依赖基础。
- 执行后向传播。
def my_add(t1, t2):
return torch.add(t1, t2)
def worker0():
# On worker 0:
# Setup the autograd context. Computations that take
# part in the distributed backward pass must be within
# the distributed autograd context manager.
with dist_autograd.context() as context_id:
t1 = torch.rand((3, 3), requires_grad=True)
t2 = torch.rand((3, 3), requires_grad=True)
# 第一阶段:RPC操作,构建依赖基础
# Perform some computation remotely.
t3 = rpc.rpc_sync("worker1", my_add, args=(t1, t2))
# Perform some computation locally based on remote result.
t4 = torch.rand((3, 3), requires_grad=True)
t5 = torch.mul(t3, t4)
# Compute some loss.
loss = t5.sum()
# 第二阶段,执行后向传播
# Run the backward pass.
dist_autograd.backward(context_id, [loss])
# Retrieve the gradients from the context.
dist_autograd.get_gradients(context_id)
print(loss)
可以用如下办法来启动了两个 worker,其中使用了 rpc.init_rpc 来初始化 rpc。worker0 会启动,然后利用 RPC 在 worker 1 之上也进行了一些操作。
def run_worker(rank, world_size):
r"""
A wrapper function that initializes RPC, calls the function, and shuts down
RPC.
"""
# We need to use different port numbers in TCP init_method for init_rpc and
# init_process_group to avoid port conflicts.
rpc_backend_options = TensorPipeRpcBackendOptions()
rpc_backend_options.init_method = "tcp://localhost:29501"
# Rank 0 and 1 are trainers.
if rank == 0:
rpc.init_rpc(
"worker0",
rank=rank,
world_size=world_size,
rpc_backend_options=rpc_backend_options,
)
worker0()
elif rank == 1:
rpc.init_rpc(
"worker1",
rank=rank,
world_size=world_size,
rpc_backend_options=rpc_backend_options,
)
# block until all rpcs finish
rpc.shutdown()
0x02 RPC 基础
2.1 初始化
我们从头看看示例代码,当脚本启动时候,会调用到 rpc.init_rpc 来初始化 rpc。从 RPC 注释中可以看到两个概念,就是大家常见的 rank 和 world_size。
rank (int): a globally unique id/rank of this node.
world_size (int): The number of workers in the group.
具体初始化代码是:
def init_rpc(
name,
backend=None,
rank=-1,
world_size=None,
rpc_backend_options=None,
):
dist_autograd._init(rank) # 我们后续会讨论分布式自动微分引擎
_set_profiler_node_id(rank)
# Initialize RPC.
_init_rpc_backend(backend, store, name, rank, world_size, rpc_backend_options)
其中我们关心的是:_init_rpc_backend 会设定后端。
2.1.1 初始化后端
_init_rpc_backend 这里会依据配置来看看最后生成什么 Agent,然后把这个代理设定到当前上下文。RPC有两种后端,TENSORPIPE 和 PROCESS_GROUP,其中PROCESS_GROUP已经被废弃,会逐渐迁移到TENSORPIPE。
def _init_rpc_backend(
backend=BackendType.TENSORPIPE, # 默认后端是TENSORPIPE
store=None,
name=None,
rank=-1,
world_size=-1,
rpc_backend_options=None,
):
_validate_rpc_args(backend, store, name, rank, world_size, rpc_backend_options)
if _is_current_rpc_agent_set():
raise RuntimeError("RPC is already initialized")
# Initialize RPC.
rpc_agent = backend_registry.init_backend( # 生成一个agent
backend,
store=store,
name=name,
rank=rank,
world_size=world_size,
rpc_backend_options=rpc_backend_options,
)
api._init_rpc_states(rpc_agent) # 设定代理到当前上下文
可以看到,默认会生成 TensorPipeAgent。
2.1.2 生成代理
我们接下来看看如何生成 TensorPipeAgent,具体是在 torch/csrc/distributed/rpc/init.cpp。当这里生成 TensorPipeAgent 时候,把 RequestCallbackImpl 配置为回调函数。代理内部就用这个回调函数用来处理接收到的请求。
shared_ptr_class_<TensorPipeAgent>(module, "TensorPipeAgent", rpcAgent)
.def(
py::init([](const c10::intrusive_ptr<::c10d::Store>& store,
std::string selfName,
worker_id_t selfId,
int worldSize,
c10::intrusive_ptr<::c10d::ProcessGroup> processGroup,
TensorPipeRpcBackendOptions opts) {
return std::shared_ptr<TensorPipeAgent>(
new TensorPipeAgent(
store,
std::move(selfName),
selfId,
worldSize,
std::move(processGroup),
std::move(opts),
std::make_unique<RequestCallbackImpl>()), // RequestCallbackImpl 被配置到 Agent 之上
impl::destroy_without_gil<TensorPipeAgent>);
})
具体如下:
+-----------------+ +-----------------------+
| TensorPipeAgent | | RequestCallbackImpl |
| | | |
| cb_ +----------> | |
| | | |
+-----------------+ +-----------------------+
2.1.3 设置代理
_init_rpc_states 会把代理设置在PyTorch环境之中,其定义在 torch/distributed/rpc/api.py 之中有。
def _init_rpc_states(agent):
worker_infos = agent.get_worker_infos()
global _ALL_WORKER_NAMES
_ALL_WORKER_NAMES = {
worker_info.name for worker_info in worker_infos}
# NB: backend implementation might have already set the rpc_agent.
if not _is_current_rpc_agent_set():
_set_and_start_rpc_agent(agent)
接下来就要进入了C++世界。在 torch/csrc/distributed/rpc/init.cpp 中有 _set_and_start_rpc_agent,其作用是:
- RpcAgent::setCurrentRpcAgent 设定了代理。
- 调用 rpcAgent->start() 来启动代理。
module.def(
"_set_and_start_rpc_agent",
[](const std::shared_ptr<RpcAgent>& rpcAgent) {
RpcAgent::setCurrentRpcAgent(rpcAgent); // 这里设定了 Agent
// Initializing typeResolver inside RpcAgent constructor will make
// RpcAgent have python dependency. To avoid RpcAgent to have python
// dependency, setTypeResolver() here.
std::shared_ptr<TypeResolver> typeResolver =
std::make_shared<TypeResolver>([&](const c10::QualifiedName& qn) {
auto typePtr = PythonRpcHandler::getInstance().parseTypeFromStr(
qn.qualifiedName());
return c10::StrongTypePtr(
PythonRpcHandler::getInstance().jitCompilationUnit(),
std::move(typePtr));
});
rpcAgent->setTypeResolver(typeResolver);
rpcAgent->start(); // 启动代理
},
py::call_guard<py::gil_scoped_release>());
setCurrentRpcAgent 定义在 torch/csrc/distributed/rpc/rpc_agent.cpp 之中。
2.1.4 静态类变量
在 RpcAgent 之中,有一个静态成员变量 currentRpcAgent_。
class TORCH_API RpcAgent {
// 我们省略了其他成员变量和函数
private:
static std::shared_ptr<RpcAgent> currentRpcAgent_;
}
在 C++ 之中,静态成员变量有如下特点:
- 其属于整个类所有。
- 其生命期不依赖于任何对象,为程序的生命周期。
- 可以通过类名直接访问公有静态成员变量。
- 可以通过对象名访问一个类的公有静态成员变量。
- 类的所有派生对象共享该类的静态成员变量。
- 静态成员变量需要在该类外单独分配空间。
- 静态成员变量在程序内部位于全局数据区。
所以,我们可知RpcAgent::currentRpcAgent_ 可以认为就是全局变量,rpc 统一使用这个变量进行协调。具体通过 RpcAgent 的一些公有成员函数来完成这些功能。
std::shared_ptr<RpcAgent> RpcAgent::currentRpcAgent_ = nullptr;
bool RpcAgent::isCurrentRpcAgentSet() {
return std::atomic_load(¤tRpcAgent_) != nullptr;
}
std::shared_ptr<RpcAgent> RpcAgent::getCurrentRpcAgent() {
std::shared_ptr<RpcAgent> agent = std::atomic_load(¤tRpcAgent_);
return agent;
}
void RpcAgent::setCurrentRpcAgent(std::shared_ptr<RpcAgent> rpcAgent) {
if (rpcAgent) {
std::shared_ptr<RpcAgent> previousAgent;
// Use compare_exchange so that we don't actually perform the exchange if
// that would trigger the assert just below. See:
// https://en.cppreference.com/w/cpp/atomic/atomic_compare_exchange
std::atomic_compare_exchange_strong(
¤tRpcAgent_, &previousAgent, std::move(rpcAgent));
} else {
// We can't use compare_exchange (we don't know what value to expect) but we
// don't need to, as the only case that would trigger the assert is if we
// replaced nullptr with nullptr, which we can just do as it has no effect.
std::shared_ptr<RpcAgent> previousAgent =
std::atomic_exchange(¤tRpcAgent_, std::move(rpcAgent));
}
}
于是目前拓展如下,以后进行 RPC 操作,都会通过 RpcAgent::currentRpcAgent_ 这个全局变量进行。
RpcAgent::currentRpcAgent_
+
|
|
|
v
+-----+-----------+ +-----------------------+
| TensorPipeAgent | | RequestCallbackImpl |
| | | |
| cb_ +----------> | |
| | | |
+-----------------+ +-----------------------+
2.2 RPC 代理
dist.autograd 的相关功能都是基于 RPC 代理完成,所以我们需要仔细看看代理。
2.2.1 RpcAgent
这是用来传递RPC的代理,是收发 RPC消息的代理基类,其:
- 提供了
sendAPI用来处理request 和 response。 - 也配置了 cb_ 用来处理接收到的请求。
WorkerInfo 是代理实例所在 worker 的全局唯一标示,包括name_和id_这两个成员变量。name_是全局唯一名字,id_是全局唯一ID。
class TORCH_API RpcAgent {
public:
RpcAgent(
WorkerInfo id,
std::unique_ptr<RequestCallback> cb,
std::chrono::milliseconds rpcTimeout);
// 给 to.id 代表的其他 RpcAgengt 发送一个消息,返回一个JitFuture,这个实现是异步的。
virtual c10::intrusive_ptr<JitFuture> send(
const WorkerInfo& to.id,
Message&& message,
const float rpcTimeoutSeconds = kUnsetRpcTimeout,
const std::unordered_map<c10::Device, c10::Device>& deviceMap = {
}) = 0;
protected:
const WorkerInfo workerInfo_; // 代理实例的全局唯一标示
const std::unique_ptr<RequestCallback> cb_; // 回调函数
std::atomic<std::chrono::milliseconds> rpcTimeout_;
std::atomic<bool> profilingEnabled_;
std::shared_ptr<TypeResolver> typeResolver_;
std::atomic<bool> rpcAgentRunning_;
private:
static std::shared_ptr<RpcAgent> currentRpcAgent_; // 全局代理
// Add GIL wait time data point to metrics
virtual void addGilWaitTime(const std::chrono::microseconds gilWaitTime) = 0;
friend class PythonRpcHandler;
// Condition Variable to signal when the rpcRetryMap_ has been populated.
std::condition_variable rpcRetryMapCV_;
// Mutex to protect RpcRetryMap_.
std::mutex rpcRetryMutex_;
};
2.2.2 ProcessGroupAgent
ProcessGroupAgent 是 RpcAgent 的派生类。这是之前使用的,但是 PyTorch 提供了更优秀的 TensorAgent。我们只选取了部分成员变量。
class TORCH_API ProcessGroupAgent : public RpcAgent {
public:
c10::intrusive_ptr<::c10d::ProcessGroup> pg_;
// worker name -> rank
std::unordered_map<std::string, worker_id_t> nameMap_;
std::vector<WorkerInfo> allWorkerInfo_;
MessageCounter sendCounts_;
MessageCounter recvCounts_;
std::atomic<int64_t> nextId_;
std::thread listenerThread_;
std::thread futureTimeoutThread_;
c10::intrusive_ptr<c10d::ProcessGroup::Work> recvWork_;
std::unordered_map<
worker_id_t,
std::set<c10::intrusive_ptr<c10d::ProcessGroup::Work>>>
currentPendingSends_;
ThreadPool threadPool_;
// Mapping of request id to FutureInfo struct.
std::unordered_map<int64_t, FutureInfo> futures_;
};
2.2.3 TensorPipeAgent
TensorPipeAgent 定义在 torch/csrc/distributed/rpc/tensorpipe_agent.h,这是目前和未来使用的。TensorPipeAgent利用TensorPipe在可用传输或通道之中透明地移动张量和数据。它就像一个混合的RPC传输,提供共享内存(linux)和TCP(linux&mac)支持。PyTorch 正在开发其支持CUDA版本。
我们只选取了部分成员变量。
// TensorPipeAgent leverages TensorPipe (https://github.com/pytorch/tensorpipe)
// to transparently move tensors and payloads through the fastest available
// transport or channel. It acts like a hybrid RPC transport, providing shared
// memory (linux) and TCP (linux & mac) support. CUDA support is in progress.
class TensorPipeAgent : public RpcAgent {
public:
TensorPipeAgent(
const c10::intrusive_ptr<::c10d::Store>& store,
std::string selfName,
worker_id_t selfId,
int worldSize,
c10::intrusive_ptr<::c10d::ProcessGroup> processGroup,
TensorPipeRpcBackendOptions opts,
std::unique_ptr<RequestCallback> cb);
const TensorPipeRpcBackendOptions opts_;
std::unordered_map<std::string, DeviceMap> reverseDeviceMaps_;
std::vector<c10::Device> devices_;
ThreadPool threadPool_;
std::shared_ptr<tensorpipe::Context> context_;
std::shared_ptr<tensorpipe::Listener> listener_;
mutable std::mutex connectedPipesMutex_;
std::unordered_map<worker_id_t, ClientPipe> connectedPipes_;
// Maps keyed on name and id for easy WorkerInfo lookup.
std::unordered_map<worker_id_t, WorkerInfo> workerIdToInfo_;
std::unordered_map<std::string, WorkerInfo> workerNameToInfo_;
std::unordered_map<std::string, std::string> workerNameToURL_;
::c10d::PrefixStore rankToNameStore_;
::c10d::PrefixStore nameToAddressStore_;
const int worldSize_;
// The join method is required to behave like a barrier and perform collective
// operations. For simplicity and reliability, we offload this to a process
// group, but probably one day we might want to re-implement them using RPCs.
const c10::intrusive_ptr<::c10d::ProcessGroup> processGroup_;
std::atomic<uint64_t> nextMessageID_{
0};
// Thread that will poll the timeoutMap_ for timed out messages and mark them
// with an error accordingly
std::thread timeoutThread_;
// Function run by the timeoutThread_ to check for timed out RPCs
void pollTimeoutRpcs();
};
2.2.4 回调函数
Agent 在收到消息时候,会调用回调函数。而 RequestCallbackImpl 实现了回调逻辑。RequestCallbackImpl 是派生类,我们先来看看基类 RequestCallbackNoPython,结果找到了RequestCallback 这个接口,所以 RequestCallback 才是这个派生体系的基础。
class TORCH_API RequestCallbackNoPython : public RequestCallback
class TORCH_API RequestCallbackImpl : public RequestCallbackNoPython
2.2.4.1 RequestCallback
RequestCallback 是处理 RPC 消息的接口,是一个抽象类。
// Functor which is invoked to process an RPC message. This is an abstract class
// with some common functionality across all request handlers. Users need to
// implement this interface to perform the actual business logic.
class TORCH_API RequestCallback {
public:
// Invoke the callback.
c10::intrusive_ptr<JitFuture> operator()(
Message& request,
std::shared_ptr<LazyStreamContext> ctx) const;
// NOLINTNEXTLINE(modernize-use-equals-default)
virtual ~RequestCallback() {
}
protected:
// RpcAgent implementation should invoke ``RequestCallback`` to process
// received requests. There is no restriction on the implementation's
// threading model. This function takes an rvalue reference of the Message
// object. It is expected to return the future to a response message or
// message containing an exception. Different rpc agent implementations are
// expected to ensure delivery of the response/exception based on their
// implementation specific mechanisms.
virtual c10::intrusive_ptr<JitFuture> processMessage(
Message& request,
std::shared_ptr<LazyStreamContext> ctx) const = 0;
};
2.2.4.2 RequestCallbackNoPython
RequestCallbackNoPython 的定义在 torch/csrc/distributed/rpc/request_callback_no_python.h,其实现了一些处理机制,因为其包含太多方法,我们只能摘录部分,如果有兴趣的朋友请深入研究。
// RequestCallback implementation with no Python dependencies.
class TORCH_API RequestCallbackNoPython : public RequestCallback {
public:
c10::intrusive_ptr<JitFuture> processMessage(
Message& request,
std::shared_ptr<LazyStreamContext> ctx) const override;
protected:
void processForwardAutogradReq(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const;
void processBackwardAutogradReq(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const;
void processRpc(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const;
virtual void processRpcWithErrors(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const;
virtual void processRRefBackward(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const;
};
我们会在后续分析接受逻辑时候,看到如何调用到回调函数。
0x03 发送逻辑
我们先来看看发送逻辑。也就是 rpc.rpc_sync 的作用:建立 root,添加 send等。
3.1 Python
我们从 python 部分开始。
# Perform some computation remotely.
t3 = rpc.rpc_sync("worker1", my_add, args=(t1, t2))
首先来到 rpc_sync,发现其调用了_invoke_rpc。
@_require_initialized
def rpc_sync(to, func, args=None, kwargs=None, timeout=UNSET_RPC_TIMEOUT):
fut = _invoke_rpc(to, func, RPCExecMode.SYNC, args, kwargs, timeout)
return fut.wait()
其次来到_invoke_rpc,可以看到此函数依据调用类型不同(内置操作,script,udf这三种),选择了不同路径。
def _invoke_rpc(to, func, rpc_type, args=None, kwargs=None, rpc_timeout=UNSET_RPC_TIMEOUT):
qualified_name = torch.jit._builtins._find_builtin(func)
dst_worker_info = _to_worker_info(to)
should_profile = torch.autograd._profiler_enabled()
ctx_manager = _enable_rpc_profiler(should_profile, qualified_name, func, rpc_type, dst_worker_info)
with ctx_manager as rf:
args = args if args else ()
kwargs = kwargs if kwargs else {
}
is_async_exec = hasattr(func, "_wrapped_async_rpc_function")
if is_async_exec:
wrapped = func._wrapped_async_rpc_function
if isinstance(wrapped, torch.jit.ScriptFunction):
func = wrapped
if qualified_name is not None:
fut = _invoke_rpc_builtin( # 内置rpc
dst_worker_info,
qualified_name,
rpc_timeout,
*args,
**kwargs
)
elif isinstance(func, torch.jit.ScriptFunction): # 脚本
fut = _invoke_rpc_torchscript(
dst_worker_info.name,
torch._jit_internal._qualified_name(func),
args,
kwargs,
rpc_timeout,
is_async_exec
)
else:
(pickled_python_udf, tensors) = _default_pickler.serialize(
PythonUDF(func, args, kwargs)
)
fut = _invoke_rpc_python_udf( # 用户udf
dst_worker_info,
pickled_python_udf,
tensors,
rpc_timeout,
is_async_exec
)
if should_profile:
fut = rf._call_end_callbacks_on_future(fut)
return fut
从这里开始就进入到了C++世界,torch/csrc/distributed/rpc/init.cpp。
3.2 C++
这里可以看到_invoke_rpc_builtin 对应了 pyRpcBuiltin,_invoke_rpc_python_udf 对应了 pyRpcPythonUdf。
PyObject* rpc_init(PyObject* _unused, PyObject* noargs) {
module.def(
"_invoke_rpc_builtin",
[](const WorkerInfo& dst,
const std::string& opName,
const float rpcTimeoutSeconds,
const py::args& args,
const py::kwargs& kwargs) {
return std::make_shared<jit::PythonFutureWrapper>(
pyRpcBuiltin(dst, opName, args, kwargs, rpcTimeoutSeconds)); # 内置函数
},
py::call_guard<py::gil_scoped_acquire>());
module.def(
"_invoke_rpc_python_udf",
[](const WorkerInfo& dst,
std::string& pickledPythonUDF,
std::vector<torch::Tensor>& tensors,
const float rpcTimeoutSeconds,
const bool isAsyncExecution) {
return std::make_shared<jit::PythonFutureWrapper>(pyRpcPythonUdf(
dst,
pickledPythonUDF, # 对应了udf
tensors,
rpcTimeoutSeconds,
isAsyncExecution));
},
py::call_guard<py::gil_scoped_release>());
# 省略其他
}
我们选用 _invoke_rpc_builtin 对应的 pyRpcBuiltin 来看看。
3.2.1 pyRpcBuiltin
在 torch/csrc/distributed/rpc/python_functions.cpp可以看到,pyRpcBuiltin 会调用到 sendMessageWithAutograd。
c10::intrusive_ptr<JitFuture> pyRpcBuiltin(
const WorkerInfo& dst,
const std::string& opName,
const py::args& args,
const py::kwargs& kwargs,
const float rpcTimeoutSeconds) {
DCHECK(PyGILState_Check());
Stack stack;
auto op = matchBuiltinOp(opName, args, kwargs, stack);
// Release GIL since args and kwargs processing is done.
py::gil_scoped_release release;
auto scriptCall = std::make_unique<ScriptCall>(op, std::move(stack));
auto agent = RpcAgent::getCurrentRpcAgent(); // 获取当前agent
return toPyJitFuture(sendMessageWithAutograd( // 发送请求
*agent,
dst,
std::move(*scriptCall).toMessage(),
false,
rpcTimeoutSeconds));
}
3.2.2 sendMessageWithAutograd
在 torch/csrc/distributed/autograd/utils.cpp 这里利用 agent 来进行发送 FORWARD_AUTOGRAD_REQ。
后面在接收方,我们将会看到处理 FORWARD_AUTOGRAD_REQ 消息,因此发送和接受大致可以联系起来。
c10::intrusive_ptr<JitFuture> sendMessageWithAutograd(
RpcAgent& agent,
const WorkerInfo& dst,
torch::distributed::rpc::Message&& wrappedRpcMsg,
bool forceGradRecording,
const float rpcTimeoutSeconds,
bool forceDisableProfiling) {
auto msg = getMessageWithAutograd( // 这里会与上下文交互,构建了 FORWARD_AUTOGRAD_REQ
dst.id_,
std::move(wrappedRpcMsg),
MessageType::FORWARD_AUTOGRAD_REQ,
forceGradRecording,
agent.getDeviceMap(dst));
c10::intrusive_ptr<JitFuture> fut;
// If profiler is enabled, wrap this message with profiling metadata that will
// tell the remote end to process this request with the profiler enabled.
if (!forceDisableProfiling && torch::autograd::profiler::profilerEnabled()) {
auto profilerConfig = torch::autograd::profiler::getProfilerConfig();
auto msgWithProfiling = getMessageWithProfiling(
std::move(msg),
rpc::MessageType::RUN_WITH_PROFILING_REQ, //构建消息
std::move(profilerConfig));
// 发送消息
fut = agent.send(dst, std::move(msgWithProfiling), rpcTimeoutSeconds);
} else {
fut = agent.send(dst, std::move(msg), rpcTimeoutSeconds);
}
return fut;
}
发送流程如下,其中 sendMessageWithAutograd 会使用 RpcAgent::getCurrentRpcAgent() 得到 RpcAgent::currentRpcAgent_,就是得到了全局设置的代理,然后通过代理进行发送。
rpc.rpc_sync
+
|
|
v
_invoke_rpc_builtin
+
| Python
+---------------------------------------------------------------+
| C++
|
v
pyRpcBuiltin
+
|
|
v
sendMessageWithAutograd(RpcAgent::getCurrentRpcAgent())
+
|
|
| RpcAgent::currentRpcAgent_
| +
| |
| |
| v
| +-----+-----------+
| | TensorPipeAgent | +-----------------------+
| | | | RequestCallbackImpl |
| | cb_ +------------> | |
| | | +-----------------------+
| | |
| | |
+-----------> send +-----------> Will send message to other worker
| |
| |
+-----------------+
0x04 接受逻辑
4.1 回调
当Agent接受到消息之后,会调用到RequestCallback::operator()。就是我们前面所说的回调函数。代码位于 torch/csrc/distributed/rpc/tensorpipe_agent.cpp。
void TensorPipeAgent::respond(std::shared_ptr<tensorpipe::Pipe>& pipe) {
pipeRead(
pipe,
[this, pipe](
const tensorpipe::Error& error,
Message&& requestMessage,
std::shared_ptr<LazyStreamContext> ctx) mutable {
// Arm for next read
respond(pipe);
uint64_t messageId = requestMessage.id();
increaseCallCount(serverActiveCalls_);
// Defer user RPC UDF run to thread pool
threadPool_.run([this,
pipe,
messageId,
requestMessage{
std::move(requestMessage)},
ctx{
std::move(ctx)}]() mutable {
c10::intrusive_ptr<JitFuture> futureResponseMessage;
try {
// 这里会调用 RequestCallback 来进行回调逻辑处理
futureResponseMessage = cb_->operator()(requestMessage, ctx);
} catch (const std::exception& /* unused */) {
futureResponseMessage =
c10::make_intrusive<JitFuture>(at::AnyClassType::get());
futureResponseMessage->setError(std::current_exception());
}
// Shortcut if immediately done
if (futureResponseMessage->completed()) {
decreaseCallCount(serverActiveCalls_);
sendCompletedResponseMessage(
pipe, *futureResponseMessage, messageId, std::move(ctx));
} else {
// Not complete yet
increaseCallCount(serverActiveAsyncCalls_);
futureResponseMessage->addCallback(
[this, pipe, messageId, ctx{
std::move(ctx)}](
JitFuture& futureResponseMessage) mutable {
decreaseCallCount(serverActiveCalls_);
decreaseCallCount(serverActiveAsyncCalls_);
sendCompletedResponseMessage(
pipe, futureResponseMessage, messageId, std::move(ctx));
});
}
});
});
}
4.2 operator()
operator() 之中会调用 processMessage 处理消息。
c10::intrusive_ptr<JitFuture> RequestCallback::operator()(
Message& request,
std::shared_ptr<LazyStreamContext> ctx) const {
// NB: cannot clear autograd context id here because the processMessage method
// might pause waiting for all RRefs in the arguments to be confirmed by their
// owners and resumne processing in a different thread. Hence, the
// thread_local context id needs to be set and cleared in the thread that
// indeed carries out the processing logic.
return processMessage(request, std::move(ctx));
}
随后,会调用到 RequestCallbackNoPython::processMessage 之中。
- 先调用 RequestCallbackImpl 中实现的 deserializePythonRpcCommand 来对 PythonUDF 反序列化。
- 然后调用 processRpcWithErrors 来处理消息。
c10::intrusive_ptr<JitFuture> RequestCallbackNoPython::processMessage(
Message& request,
std::shared_ptr<LazyStreamContext> ctx) const {
// We need two futures here because it could pause twice when processing a
// RPC message:
// 1) waiting for all RRefs in the arguments to become confirmed;
// 2) waiting for processRpc to finish.
auto retFuture = c10::make_intrusive<JitFuture>(at::AnyClassType::get());
auto& rrefContext = RRefContext::getInstance();
try {
rrefContext.recordThreadLocalPendingRRefs();
// Deserialize PythonUDF here to trigger RRef unpickling
// 调用 RequestCallbackImpl 中实现的 deserializePythonRpcCommand 来对 PythonUDF 反序列化
std::unique_ptr<RpcCommandBase> rpc = deserializePythonRpcCommand(
deserializeRequest(request), request.type()); // 解析请求
auto rrefsReadyFuture = rrefContext.waitForThreadLocalPendingRRefs();
rrefsReadyFuture->addCallback(
[this,
retFuture,
// std::function must be copyable, hence hae to cast the unique_ptr to
// a shared_ptr here.
rpc = (std::shared_ptr<RpcCommandBase>)std::move(rpc),
messageType = request.type(),
id = request.id(),
ctx = std::move(ctx)](JitFuture& /* unused */) mutable {
c10::MultiStreamGuard guard(
ctx ? ctx->getReservedStreams() : ArrayRef<Stream>({
}));
// The cost of pre-request check is minimal thanks to
// std::shared_lock. The cost is in magnitude
// of 10us.
auto serverProcessGlobalProfilerStateStackEntryPtr =
profiler::processglobal::StateStackEntry::current();
// If server global profiler is enabled, we futher pay the
// cost of thread local profiler state initialization.
if (serverProcessGlobalProfilerStateStackEntryPtr) {
// Initialize thread-local profiler state from process-global
// profiler state.
::torch::autograd::profiler::enableProfilerLegacy(
serverProcessGlobalProfilerStateStackEntryPtr->statePtr()
->config());
}
// 在这里
processRpcWithErrors(
*rpc, messageType, id, retFuture, std::move(ctx));
// Response message has been sent at this moment, this post-response
// work doesn't affect RPC trip time.
if (serverProcessGlobalProfilerStateStackEntryPtr) {
// Restore thread-local profiler state.
::torch::autograd::profiler::thread_event_lists event_lists =
::torch::autograd::profiler::disableProfilerLegacy();
// Put thread_local event_lists into the process-global profiler
// state.
profiler::processglobal::pushResultRecursive(
serverProcessGlobalProfilerStateStackEntryPtr, event_lists);
}
});
} catch (std::exception& e) {
retFuture->markCompleted(handleError(e, request.type(), request.id()));
rrefContext.clearRecordedPendingRRefsOnError();
}
return retFuture;
}
然后调用到 processRpcWithErrors。
void RequestCallbackNoPython::processRpcWithErrors(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
try {
processRpc(rpc, messageType, messageId, responseFuture, std::move(ctx));
} catch (std::exception& e) {
responseFuture->markCompleted(handleError(e, messageType, messageId));
}
}
接下来是 processRpc。这里能够看到处理 FORWARD_AUTOGRAD_REQ。
void RequestCallbackNoPython::processRpc(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
case MessageType::FORWARD_AUTOGRAD_REQ: {
// 这里就和之前发送的对应上了
processForwardAutogradReq(rpc, messageId, responseFuture, std::move(ctx));
return;
}
case MessageType::BACKWARD_AUTOGRAD_REQ: {
processBackwardAutogradReq(rpc, messageId, responseFuture);
return;
};
}
具体如下:
TensorPipeAgent RequestCallback RequestCallbackNoPython RequestCallbackImpl
+ + + +
| | | |
| | | |
v | | |
respond | | |
+ | | |
| | | |
| | | |
v v v |
cb_->operator() +--> operator() +--> processMessage |
+ |
| |
| v
+---------------> deserializePythonRpcCommand
|
|
|
v
processRpcWithErrors
+
|
|
v
processRpc
+
|
|
v
processForwardAutogradReq
4.3 RequestCallbackImpl
这时候,读者会有疑问,之前 TensorPipeAgent 明明设置了 RequestCallbackImpl 作为回调函数,怎么只调用了其 deserializePythonRpcCommand呢,deserialXXX 看起来是序列化相关的,按说应该调用一些业务处理函数,比如processXXXX 之类的。我们接下来就看看 RequestCallbackImpl。
RequestCallbackImpl 定义在 torch/csrc/distributed/rpc/request_callback_impl.h。
class TORCH_API RequestCallbackImpl : public RequestCallbackNoPython {
public:
std::unique_ptr<RpcCommandBase> deserializePythonRpcCommand(
std::unique_ptr<RpcCommandBase> rpc,
const MessageType& messageType) const override;
void processPythonCall(
RpcCommandBase& rpc,
const std::function<void(Message)>& markComplete,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const override;
void processScriptCall(
RpcCommandBase& rpc,
const std::function<void(Message)>& markComplete,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const override;
void processScriptRemoteCall(
ScriptRemoteCall& scriptRemoteCall,
const std::function<void(void)>& postProcessing,
std::vector<at::IValue>& stack,
const c10::intrusive_ptr<OwnerRRef>& ownerRRef) const override;
void processPythonRemoteCall(
RpcCommandBase& rpc,
const std::function<void(Message)>& markComplete,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const override;
void processRpcWithErrors(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const override;
void processRRefBackward(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const override;
};
因为最终生成的是 RequestCallbackImpl,所以实际上,上图中间有一步 processRpcWithErrors 实际调用的是 RequestCallbackImpl 这里的函数 processRpcWithErrors,其就是增加了一些异常处理逻辑。
void RequestCallbackImpl::processRpcWithErrors(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
try {
processRpc(rpc, messageType, messageId, responseFuture, std::move(ctx));
} catch (py::error_already_set& e) {
responseFuture->markCompleted(handleError(e, messageType, messageId));
py::gil_scoped_acquire acquire;
e.restore(); // Release ownership on py::objects and also restore
// Python Error Indicator.
PyErr_Clear(); // Clear the Python Error Indicator as we has
// recorded the exception in the response message.
} catch (std::exception& e) {
responseFuture->markCompleted(handleError(e, messageType, messageId));
}
}
逻辑图修改如下:
TensorPipeAgent RequestCallback RequestCallbackNoPython RequestCallbackImpl
+ + + +
| | | |
| | | |
v | | |
respond | | |
+ | | |
| | | |
| | | |
v v v |
cb_->operator() +--> operator() +--> processMessage |
+ |
| |
| v
+----------------> deserializePythonRpcCommand
| +
| |
| |
| v
|
+----------------> processRpcWithErrors
| +
| |
| |
| <------------------------+
|
|
v
processRpc
+
|
|
v
processForwardAutogradReq
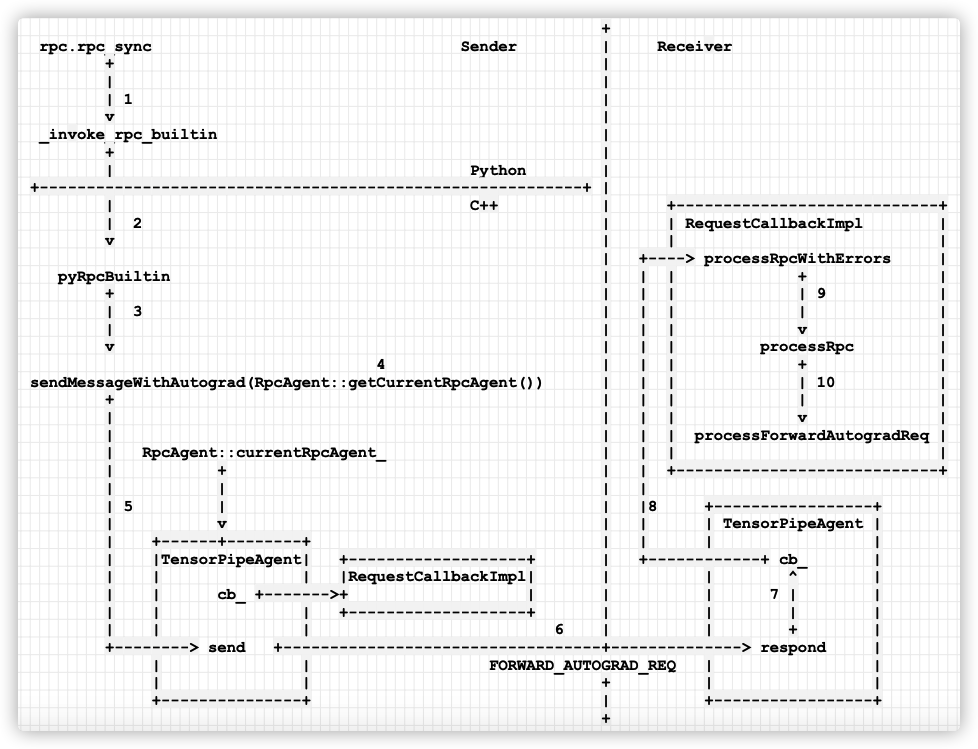
如果结合之前的发送,我们拓展图例如下:
- 当发送者需要在远端运行自动梯度计算时候,调用 rpc.rpc_sync。
- 从 Python 调用到 C++ 世界,函数为 pyRpcBuiltin。
- 调用 sendMessageWithAutograd,以此通知Receiver。
- 会调用 RpcAgent::getCurrentRpcAgent() 来得到本地的 Agent。
- 调用 current Agent 的 send 函数。
- send 函数发送 FORWARD_AUTOGRAD_REQ给 Receiver worker。
- respond 函数会调用 Receiver 之中 Agent 的回调函数 cb_。
- 调用到 RequestCallbackImpl 的 processRpcWithErrors。
- 然后调用 processRpc。
- 最后调用到 processForwardAutogradReq,完成了基于RPC的分布式autograd的启动过程。
+
rpc.rpc_sync Sender | Receiver
+ |
| |
| 1 |
v |
_invoke_rpc_builtin |
+ |
| Python |
+----------------------------------------------------------+ |
| C++ | +----------------------------+
| 2 | | RequestCallbackImpl |
v | | |
| +----> processRpcWithErrors |
pyRpcBuiltin | | | + |
+ | | | | 9 |
| 3 | | | | |
| | | | v |
v | | | processRpc |
4 | | | + |
sendMessageWithAutograd(RpcAgent::getCurrentRpcAgent()) | | | | 10 |
+ | | | | |
| | | | v |
| | | | processForwardAutogradReq |
| RpcAgent::currentRpcAgent_ | | | |
| + | | +----------------------------+
| | | |
| 5 | | |8 +-----------------+
| v | | | TensorPipeAgent |
| +------+--------+ | | | |
| |TensorPipeAgent| +-------------------+ | +------------+ cb_ |
| | | |RequestCallbackImpl| | | ^ |
| | cb_ +------->+ | | | 7 | |
| | | +-------------------+ | | | |
| | | 6 | | + |
+--------> send +----------------------------------+--------------> respond |
| | FORWARD_AUTOGRAD_REQ | |
| | + | |
+---------------+ | +-----------------+
+
手机如下:
至此,RPC介绍完毕,我们下一篇介绍上下文相关等管理类,敬请期待。
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。
