书的类型标签

代码
import csv
import time
import urllib
import requests
from lxml import etree
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
start = time.time()
# 输入你要爬取豆瓣书籍的类型
book_type = input('请输入你要查询的豆瓣图书标签:')
# 文字解码得到部分url
url_decode = urllib.parse.quote(book_type)
# 打印文字解码内容
print("输入文字的编码:",url_decode)
# 定义i为-20 从0开始 然后逐个增加20
i = -20
# 定义一个列表
list = []
# csv储存的标题
tou = ['书名', '书的相关信息', '评分', '图片地址']
# 最大最大i的大小 其实可以定的很大不能太小,只要在后面设置break
while i < 10000:
i += 20
proxies = {
'http':'139.224.46.41:8080'
}
# 最终的url
url = 'https://book.douban.com/tag/%s?start=%s&type=S' % (url_decode, i)
# 伪装请求头
headers = {
'User-Agent': 'User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Cookie': 'll="118215"; bid=ask-G90u_HE; douban-fav-remind=1; _ga=GA1.2.1177142141.1614836215; __utmv=30149280.20149; __gads=ID=27d68813352d4005-22f8a052cdc800d4:T=1621591233:RT=1621591233:S=ALNI_MYc5zR6NFKDHdv9kHgM5ev2PoJUSQ; __utmz=30149280.1625015934.13.8.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=30149280; __utma=30149280.1177142141.1614836215.1624948157.1625015934.13; __utmt_douban=1; __utmc=81379588; __utma=81379588.1177142141.1614836215.1625015934.1625015934.1; __utmz=81379588.1625015934.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmt=1; ap_v=0,6.0; gr_user_id=a0f16629-d22e-44e9-9304-bd21cf7917f0; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03=96a47f9a-458c-41c9-b6ac-308fd60d44b5; gr_cs1_96a47f9a-458c-41c9-b6ac-308fd60d44b5=user_id%3A0; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03_96a47f9a-458c-41c9-b6ac-308fd60d44b5=true; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1; _pk_ref.100001.3ac3=%5B%22%22%2C%22%22%2C1625015945%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DeWps2gVl-tjbmqkH4XZCmQwjD391kZ6YAri4CweJBidyzJIK7W3x3SH3XZGA4mZt%26wd%3D%26eqid%3D8d86bdf9000d18870000000460dbc67b%22%5D; _pk_ses.100001.3ac3=*; _vwo_uuid_v2=D73A08BB8BBCA7628E0F8957146581B11|e7614233902040a30831130dff196dd4; ct=y; __utmb=30149280.23.10.1625015934; __utmb=81379588.23.10.1625015934; _pk_id.100001.3ac3=4af506d77bd0698e.1625015945.1.1625016319.1625015945.'}
r = requests.get(url=url, headers=headers,proxies=proxies).text
# print(r)
html = etree.HTML(r)
# print(html)
# XPath使用路径表达式来选取
# 书的名字
book_name = html.xpath('(//div[@class="info"]//h2/a/text())')
# 因为里面取到的数据多了 '\n\n ' ,如果有就删除
while '\n\n ' in book_name:
book_name.remove('\n\n ')
# 如果没有书名了,直接结束
if not book_name:
break
# print(book_name)
print(url)
# 书籍信息
book_info = html.xpath("//div[@class='info']/div[@class='pub']/text()")
# print(type(book_info))
# 因为里面取到的数据多了 '\n\n ' ,如果有就删除
while '\n\n ' in book_info:
book_info.remove('\n\n ')
# print(book_info)
# 书籍评分
book_score = html.xpath("//div[@class='star clearfix']/span[@class='rating_nums']/text()")
while '\n\n ' in book_score:
book_score.remove('\n\n ')
# print(book_score)
# 书籍图片的地址
book_img_url = html.xpath("//div[@class='pic']/a[@class='nbg']/img/@src")
# 因为里面取到的数据多了 '\n\n ' ,如果有就删除
while '\n\n ' in book_img_url:
book_img_url.remove('\n\n ')
# print(book_img_url)
# for循环下标,把一本书的信息弄到一起
for q in range(len(book_score)):
# 装进列表里面
list.append([book_name[q].strip(), book_info[q].strip(), book_score[q].strip(), book_img_url[q].strip()])
print(list)
# 保存到csv
with open('豆瓣读书—%s.csv' % book_type, 'w', encoding='utf-8') as f:
f_csv = csv.writer(f)
f_csv.writerow(tou)
f_csv.writerows(list)
# 为了不被封,设置延时
time.sleep(1)
end=time.time()
finally_timme=end-start
print("一共花费了%s秒"%finally_timme)
温馨提示
建议用热点或者代理ip爬取,ip很容易被封掉
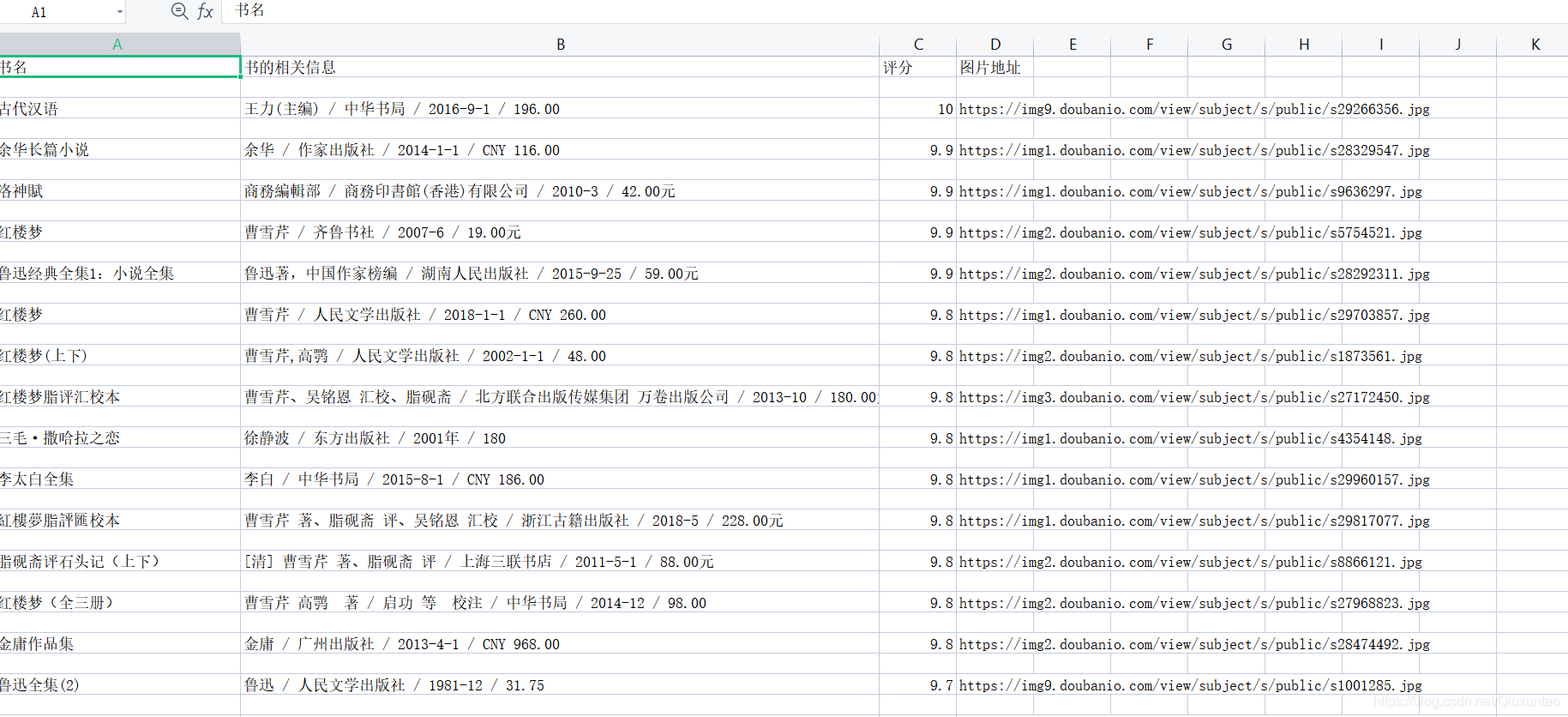
效果