嗨害大家好鸭!我是小熊猫❤
最近俺扣扣交流裙内总是有人问这个问题:
“Python如何爬取数据保存到Excel中?”
那么我们今天就来康康怎么解决~

开发工具
- Python版本:3.6
- 相关模块:
主要思路:
- 两页的内容
- 抓取每页title和URL
- 根据title创建文件,发送URL请求,提取数据
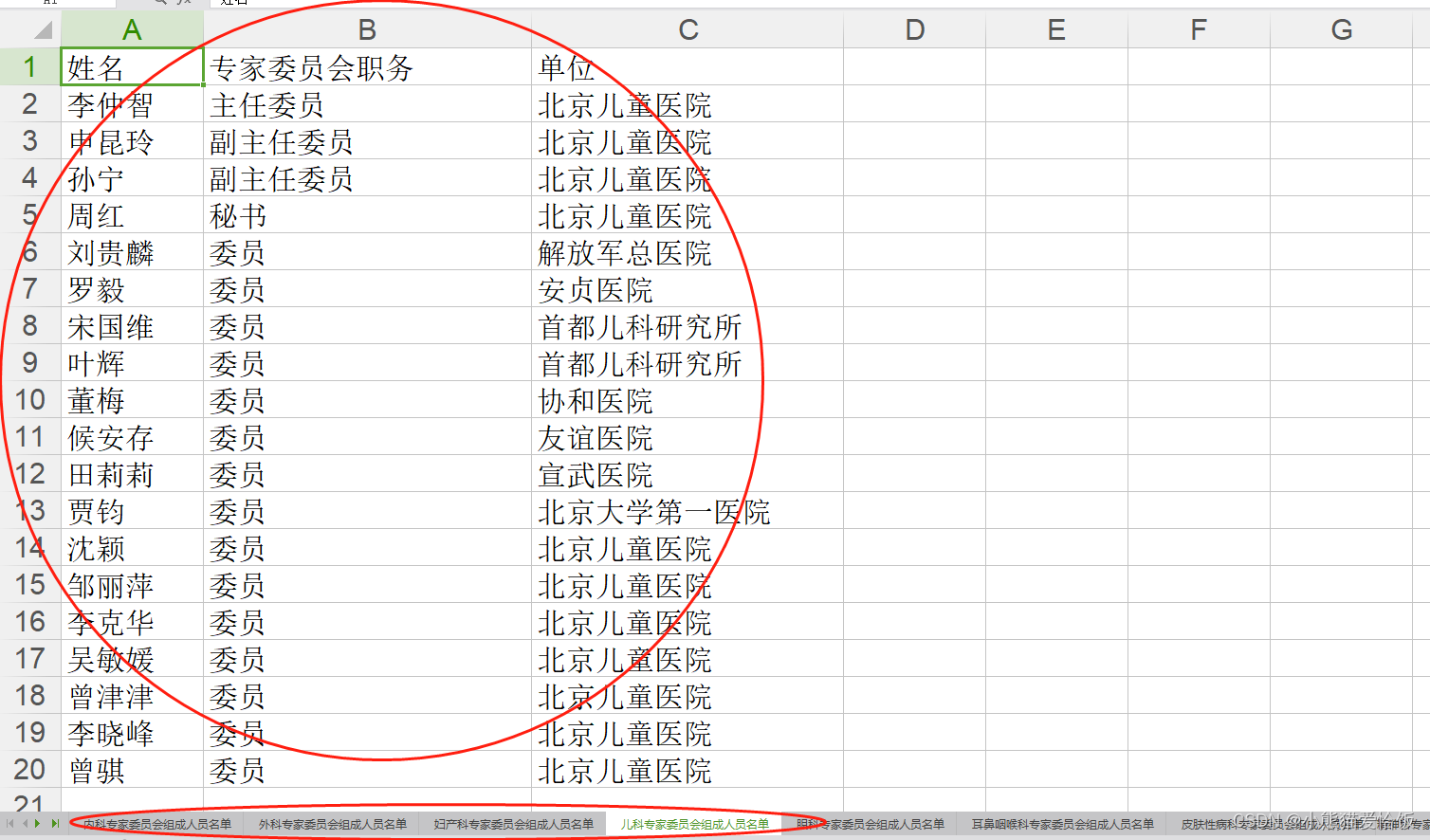
效果展示:

完整代码:
# -*- conding:utf-8 -*-
import requests
from lxml import etree
import time, random, xlwt
'''
遇到不懂的问题?Python学习交流群:660193417满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 专家委员会成员的xpath(‘//tbody//tr[@height='29']’)
class Doc_spider(object):
def __init__(self):
self.base_url = 'http://www.bjmda.com'
self.url = 'http://www.bjmda.com/Aboutus/ShowClass.asp?ClassID=12&page={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}
def get_request(self, url):
'''发送请求,返回html'''
response = requests.get(url, headers=self.headers).content.decode('gbk')
# time.sleep(random.random())
html = etree.HTML(response)
return html
def parse_page_html(self, html, url):
'''提取列表页的专家委员会title和URL'''
url_lists = html.xpath('//tr/td[2]/a[2]/@href')[1:]
temp_lists = html.xpath('//tr/td[2]/a[2]/text()')[1:]
title_lists = [title.rstrip() for title in temp_lists]
urls = []
titles = []
for i in range(len(title_lists)):
url = self.base_url + url_lists[i]
title = title_lists[i]
urls.append(url)
titles.append(title)
return urls, titles
def parse_detail(self, html):
'''详细页的提取数据,返回每组列表信息'''
lists = html.xpath("//td[@id='fontzoom']//tr")
content_list = []
for list in lists:
contents = list.xpath('.//td//text()')
new = []
for i in contents:
new.append(''.join(i.split()))
content_list.append(new)
return content_list
def save_excel(self, sheet_name, contents, worksheet, workbook):
'''保存数据到Excel'''
# 创建一个workbook 设置编码
#workbook = xlwt.Workbook()
# 创建一个worksheet
#worksheet = workbook.add_sheet(sheet_name)
try:
for i in range(len(contents)):
if len(contents[i+1])>1:
content_list = contents[i + 1]
# 写入excel
# 参数对应 行, 列, 值
worksheet.write(i, 0, label=content_list[0])
worksheet.write(i, 1, label=content_list[1])
worksheet.write(i, 2, label=content_list[2])
if len(contents[i+1])>3:
worksheet.write(i, 3, label=content_list[3])
# 保存
#workbook.save(sheet_name + '.xls')
# time.sleep(0.1)
except:
print(sheet_name,'保存OK')
pass
def run(self):
# 1.发送专家委员会列表页请求
urls = [self.url.format(i + 1) for i in range(2)]
# 创建一个workbook 设置编码
workbook = xlwt.Workbook()
for url in urls:
html = self.get_request(url)
# 2.提取委员会的title和URL
list_urls, titles = self.parse_page_html(html, url)
for i in range(len(list_urls)):
url_detail = list_urls[i]
# 每个委员会的名称
title_detail = titles[i]
# 3.创建每个委员会文件,发送每个委员会的请求
html_detail = self.get_request(url_detail)
# 4.提取专家委员会详细页的内容
contents = self.parse_detail(html_detail)
# 保存每个委员会的所有人
# 创建一个worksheet
worksheet = workbook.add_sheet(title_detail)
self.save_excel(title_detail, contents,worksheet,workbook)
workbook.save('专家委员会.xls')
print('保存结束,请查看')
if __name__ == '__main__':
doc = Doc_spider()
doc.run()
# -*- conding:utf-8 -*-
import xlwt
# 创建工作workbook
workbook = xlwt.Workbook()
# 创建工作表worksheet,填入表名
worksheet = workbook.add_sheet('表名')
# 在表中写入相应的数据
worksheet.write(0, 0, 'hello world')
worksheet.write(1, 1, '你好')
# 保存表
workbook.save('hello.xls')
实在是不知道大家想看啥了…
希望大家好好学习吧
报错解答、资料获取可以点击文末名片
我是小熊猫(困得要死版),咱下篇文章再见啦(✿◡‿◡)
