最近写了一个爬虫,爬取知乎用户数据,将爬取的数据保存在一个csv文件和MongoDB数据库。经测试可以一次性爬取数万条数据,而不被ban掉。
代码见:https://github.com/wangjun1996/zhihuUser_spider
(运行项目中 zhihuUser/main.py 即可开始爬虫)
爬虫目标
爬虫要实现的内容有:
1.从一个大V用户开始,通过递归抓取粉丝列表和关注列表,实现知乎所有用户的详细信息的抓取。
2.将爬取的数据保存在一个csv文件和MongoDB数据库
思路分析
每个人都有关注列表和粉丝列表,尤其对于大V来说,粉丝和关注尤其更多。
如果从一个大V开始,首先可以获取他的个人信息,然后获取他的粉丝列表和关注列表,然后遍历列表中的每一个用户,进一步抓取每一个用户的信息还有他们各自的粉丝列表和关注列表,然后再进一步遍历获取到的列表中的每一个用户,进一步抓取他们的信息和关注粉丝列表,循环往复,不断递归,这样就可以做到一爬百,百爬万,万爬百万,通过社交关系自然形成了一个爬取网,这样就可以爬到所有的用户信息了。通过分析知乎的请求就可以得到相关接口,通过请求接口就可以拿到用户详细信息和粉丝、关注列表。
开发环境
Python3
本项目使用的 Python 版本是 Python3.6
Scrapy
Scrapy 是一个强大的爬虫框架
生成的CSV文件
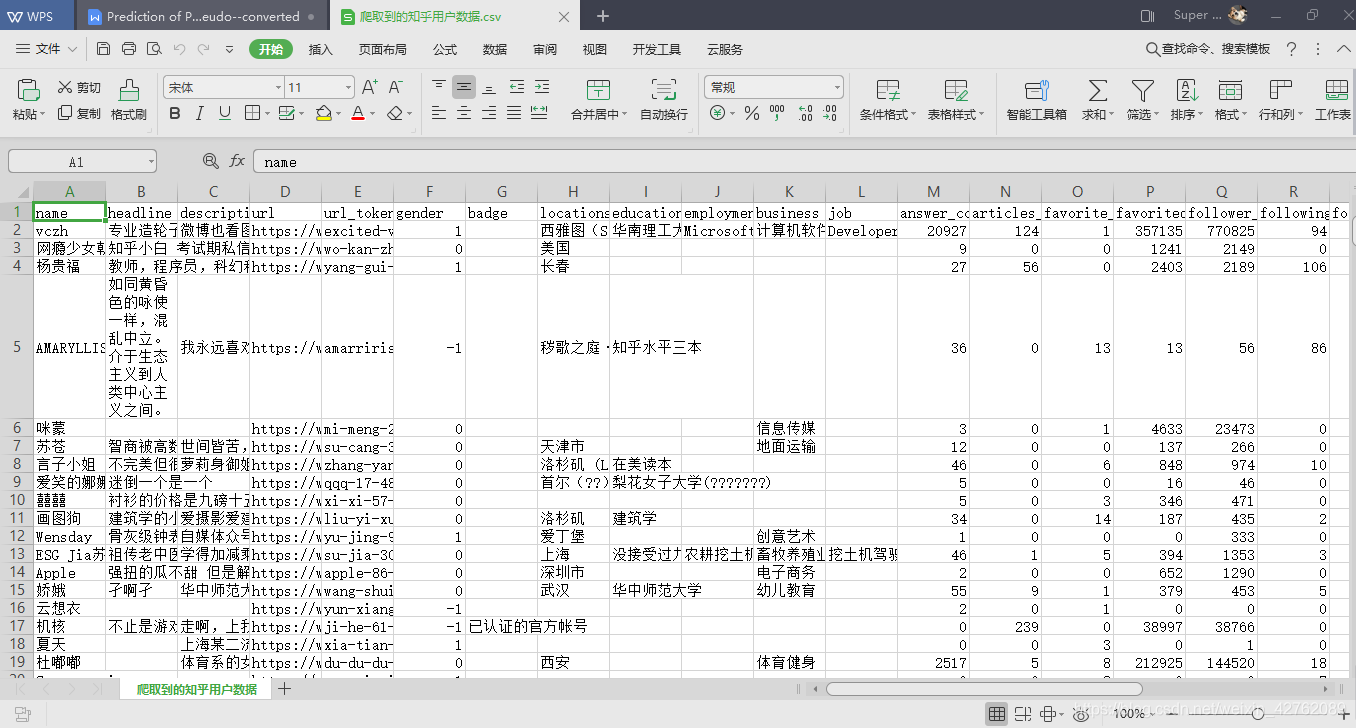
爬虫数据字段说明
name: 用户名
headline:标题
description: 个人简介
url:个人主页
url_token:用来制作url的用户名参数
gender: 性别。“1”表示男,“0”表示女
badge:个人成就
locations: 居住地
educations:教育经历
business: 所在行业
employments:公司
job:工作岗位
answer_count:回答数
articles_count:文章数
favorite_count:收藏数
favorited_count:被收藏数
follower_count:粉丝数
following_columns_count:关注的专栏数
following_count: 该用户关注了多少人
pins_count:想法数
question_count: 提问数
thanked_count:获得感谢数
voteup_count:获赞数
following_favlists_count:关注的收藏夹数
following_question_count:关注的问题数
following_topic_count: 关注的话题数
marked_answers_count:知乎收录的回答数