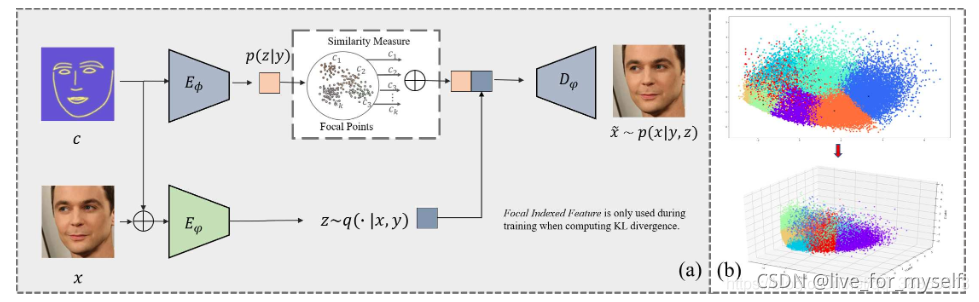
介绍
单词deepfake其实由deep learning和fake组合而成, 有太多这项技术的应用了, 比如国外电影的配音, education through the reanimation of historical figures, virtually trying on clothes while shopping, 这篇文章主要讲了一下四个方面的内容:
- 理解deepfake如何产生和 被检测的
- 告诉读者最近的成果,趋势,以及面临的挑战
- 作为deepfake架构的向导, 起引领作用
- 确定下一步使坏的人要干啥
论文中给deepfake是这样定义的:
“ B e l i e v a b l e m e d i a g e n e r a t e d b y a d e e p n e u r a l n e t w o r k ” “Believable\ media\ generated\ by\ a\ deep\ neural\ network” “Believable media generated by a deep neural network”
莫名觉得很酷hhh
在人类视觉的范围内, 作者定义了4个deepfake的子任务:
1. reenactment
2. replacement
3. editing
4. synthesis
1. Reenactment
- A reenactment deepfake is where x s x_s xs is used to drive the expression, mouth, gaze, pose, or body of x t x_t xt.
Reecactment, 我看字典翻译为重演, 重演就是说用某个 x s x_s xs 来驱动 x t x_t xt的内容, 驱动的可以是嘴部, 表情, 身体姿态等.
Mouth
对嘴部reenactment, 就类似dubbling配音一样, 就是目标的嘴换了其他地方没动, 可以被音频驱动, 像是Wav2lip就属于这类
Gaze
这个像是可以用在采访中保持眼睛专注
Pose
指头部姿态可以被驱动, 一开始用于face frontalization, 也可以改善面部识别
Expression
这是很常见的一种重演, 因为对表情的驱动也往往驱动人物的嘴和pose
重演是说没有的东西驱动形成
Body
又名pse transfer or human pose synthesis, 它是身体被驱动, 和pose不太一样, pose指头的比较多

2. Replacment
- A replacement deepfake is where the content of x t x_t xt is replaced with that of x s x_s xs , preserving the identity of s s s.
deepfake中的替换是指一部分target的内容被替换为source的内容了
Transfer
Transfer比较常见的是衣服被替换了, 挺时尚啊
Swap
这个以face swap 而出名, 常用于把一个明星的脸换到动作片上(不是, 哈哈哈哈哈), 当然也可以模糊化, 就是检测出脸部然后模糊.
替换是说换成现有的东西
3&4. Editing & Synthesis
- An enchantment deepfake is where the attributes of x t x_t xt are added, altered, or removed.
Editing指的是target的部分属性被添加,修改, 或者去除, 比如年龄, 头发, 衣服, 体重, 种族.之前很火的给定一张照片去掉衣服就属于此列.
- Synthesis is where the deepfake x g x_g xg is created with no target as a basis.
现在很多GAN网络都可以创造出清晰的但是世界上不存在的人像, 下图就可以很好的理解editing和synthesis的区别.

中间表示
许多deepfake工作采取中间表示捕捉source和target之间的关系.
- 一种方式使用**facial action coding system (FACS)**来测量面部的taxonomized action units (AU)
- 还有的使用monocular reconstruction从2D image获得3D morphable model (3DMM), 然后使用表情和pose等参数去渲染
- Some use a UV map of the head or body to give the network a better understanding of the shape’s orientation, 这应该是辅助3DMM的
- 另一种大类是使用landmark, 有的工作把landmarks按通道分开, 使网络更容易识别和关联它们
- 还有的使用 facial boundaries and body skeletons
- 音频往往使用MFCC, 也有使用神经网络学习特征的
Deepfake基础
为了生成 x g x_g xg, reenactment 和 face swap一般遵循下面的流程, 具体肯定会有所变化:
- 检测并裁剪人脸区域
- 提取中间表示
- 生成基于驱动的新人脸
- 把新的人脸帧融合到原视频中
整体步骤如下图:
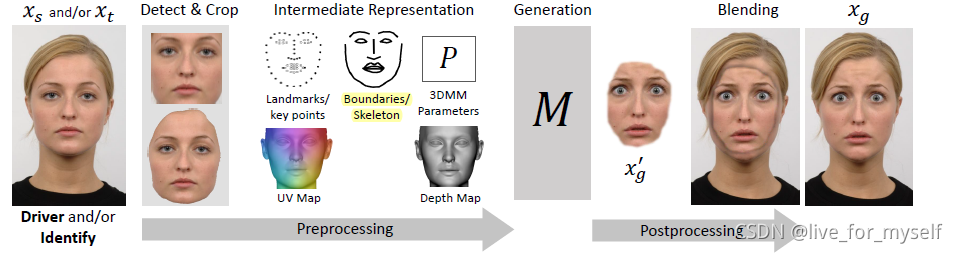
驱动一张照片有6种方法:
- 让神经网络直接对照片执行仿射变换
- 训练编码解码网络, 从表情中解耦出身份, 然后modify/swap 目标的编码,然后送入解码器
- 送入解码器前使用额外的编码, 例如AU或者embedding
- 在生成前, 把中间的面部表达转换到所需要的表达方式, 例如把渲染3d model, 或者使用boundaries
- 使用source video中的光流驱动视频
- 把原始的内容(头发, 场景等)和3D model, warped image或生成的内容相结合, 创建一个复合体, 然后把复合体经过另一个网络(如pix2pix)来细化真实性
任务的难点
1. training data依赖性
生成网络是数据驱动的, 输出反映了输入, 因此一个改进的方向是用比较少的训练数据能够在新的目标上(training data没有的)执行
2. 数据成对性
假如我有landmark, 那么一般说来我要有对应的输出才可以, 所以这就是输入输出是一对一的成对的, 但是这个过程挺费劲.为了解决这个问题现在一般有三种方法:
(1). 从同一个视频中选择的帧来进行自监督训练
(2). 使用非配对网络如Cycle gan
(3). 利用encoder decoder网络中的encodings
3. Identity Leakage (身份泄露)
有时驱动者的身份会被转移到target上, 你比如说我只想转移一个人的表情, 结果把他的脸的样子也转过来了.
这发生在对单一输入身份进行训练时, 或者当网络对许多身份进行训练但是数据配对是用同一身份进行的 (这个我目前还没有遇到, 因为做的实践不多)
目前一些解决方法有注意力机制, few-shot learning, 解耦, boundary conversions, AdaIN或者skip connections to carry the relevant information to the generator
4. Occlusions
遮挡很常见, 比如脸被头发挡住了, 还有种类型的像是眼睛还有嘴部区域闭合了或者动态变化. 这有可能造成伪影啊, 模糊啊, 比如你只有一张嘴巴闭合的人脸, 你牙齿就没法很好的生成.
为了克服这些,有些人在被遮挡区域用了segmentation和in-painting
5. 时序连贯性 (Temporal Coherence)
假如是逐帧生成的那么一晃一晃的可太常见了, 有些研究者提供上下文给G和D, 使用时间一致性损失(temporal coherence losses)约束, 或者使用RNNs, 或者使用它们的组合
REENACTMENT (重演)
全面的总结可看下面这张图

这部分分为5个来讲述, 分别是表情,嘴部, 头部姿态, 眼睛注视, 身体姿态
1. Expression Reenectment
One-to-One(identity to identity)
18 年的论文 Recycle-gan: Unsupervised video retargeting 建立在Cycle GAN的基础上, 叫Recycle-gan, 提升了数据不配对带来的时间连贯性, 减弱了伪影, 但是注意这是一对一的, 意味着你的输入只能是一个人说话的视频帧,输出是另一个人的视频帧, 换个人就得重训一遍,用处不大。
Many-to-One (Multiple Identities to a Single Identity)
有VAEGAN加上条件变成CVAE-GAN的, 有使用ReenactGAN, 也就是使用Cycle gan把人脸boundary从源变到target, 然后通过pix2pix类似的生成器。
考虑时间连续性的例子
MoCoGAN, Vid2Vid(这个是用face boundaries生成的), Deep video portraits是一篇使用3d很厉害的文章, 具体方法如下:

Many-to-Many (Multiple IDs to Multiple IDs)
论文Photorealistic facial expression synthesis by the conditional difference adversarial autoencoder还有Generative adversarial talking head: Bringing portraits to
life with a weakly supervised neural network. 试图从表情中解耦身份
Star Gan是做表情编辑做的挺好的, 还有这个表情数据集

Self-Attention Modeling
Triple consistency loss for pairing distributions in GAN-based face synthesis, 这篇论文里使用了GANimation的self-attention, 同时使用了triple consistency loss
3D Parametric Approaches
Deep video portraits是个很厉害的论文, FaceID-GAN在对抗中集成了识别分类器。 分类器具有 2N 输出,如果输入是真实的,则激活第一个 N 输出(对应于培训集标识),如果输入是假的,则激活其余输出。
后来FaceID-GAN的作者升级了FaceID-GAN叫做FaceFeat-GAN,
目的: 合成丰富多样且身份不便的人脸.
方法: 两阶段合成法, 第一阶段生成不同特征, 第二阶段为特征到图像渲染.
paGAN 技术能够仅使用单幅照片生成人像视频, 并以 1000 帧每秒的速度对人脸进行跟踪。 相对之前的视频对视频的换脸技术,
paGAN 技术的提出进一步降低了人脸视频伪造的技术门槛。 该方法先制作合理的3D网格, 然后对输入图像和 3D 形状执行形状匹配和角度变换, 接着使用他们自己开发的脸部追踪器 VGPT 追踪人脸的位置和细节状态。 其最显著的特点就是速度非常惊人, 在搭载 1080P 的个人电脑上, 该追踪器的最高帧数可达1000; 即使在手机端, 也可以达到 60~90 每秒传输帧数(Frames Per Second, FPS) , 满足手机摄像头拍摄视频的帧数要求, 即可以对视频人脸进行实时追踪和伪造。
Using Multi-Modal Sources
这个是说用其他模态的信息重演x_t, 比如在2018年的X2Face中, 人脸的图像生成的研究主要有两类分支,一类是显式建模,另一类是基于学习的方法。传统的3DMM方法受到相应形变模型部分的限制,可能无法建模所需的全部表达式/变形和更高层次的细节,X2Face具有自监督的效果,而且能够在无需显式建模的条件下根据其他模态控制生成过程。
2019年的时候, 几乎所有的工作都追求身份不可知模型
Facial Landmark & Boundary Conversion
这是FaceSwapNet的一张图, 这里面也使用了AdaIn, 这里也提到使用三元组损失是必要的(The authors found that it is
crucial to use triplet perceptual loss with an external VGG network.
)
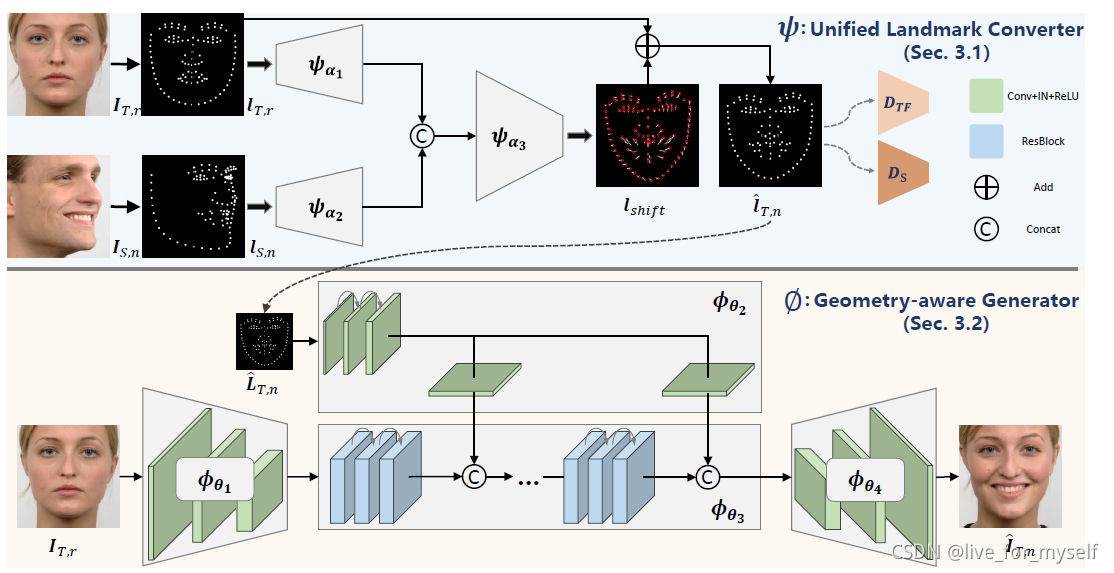
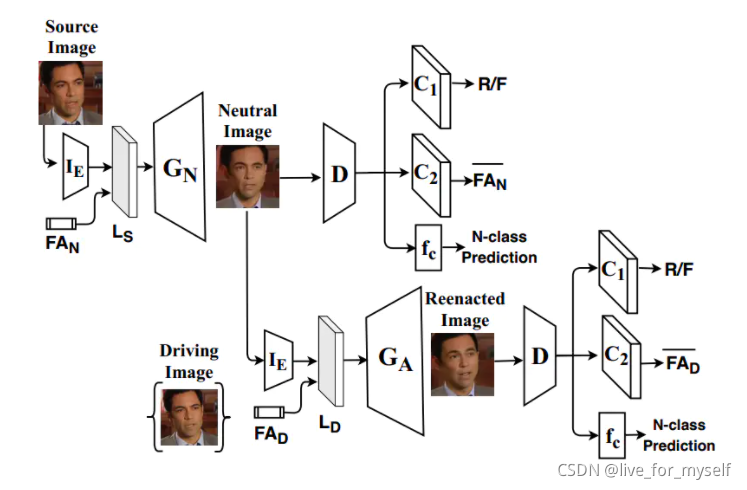
《FSGAN: Subject Agnostic Face Swapping and Reenactment》是ICCV19的一篇文章,这篇论文的亮点之一就是同时cover了人脸生成领域常见的两个任务,面部身份变换和表情迁移。给定源人脸和目标人脸,面部身份变换将源人脸贴合到目标人脸上,生成的人脸图像的背景、表情都是目标人脸的,但是身份是源人脸的。表情迁移生成的人脸图像的表情信息是目标人脸的,但是其他信息都是源人脸的。

论文 High Fidelity Face Manipulation with Extreme Poses and Expressions网络框架如下, 使用了 半监督:
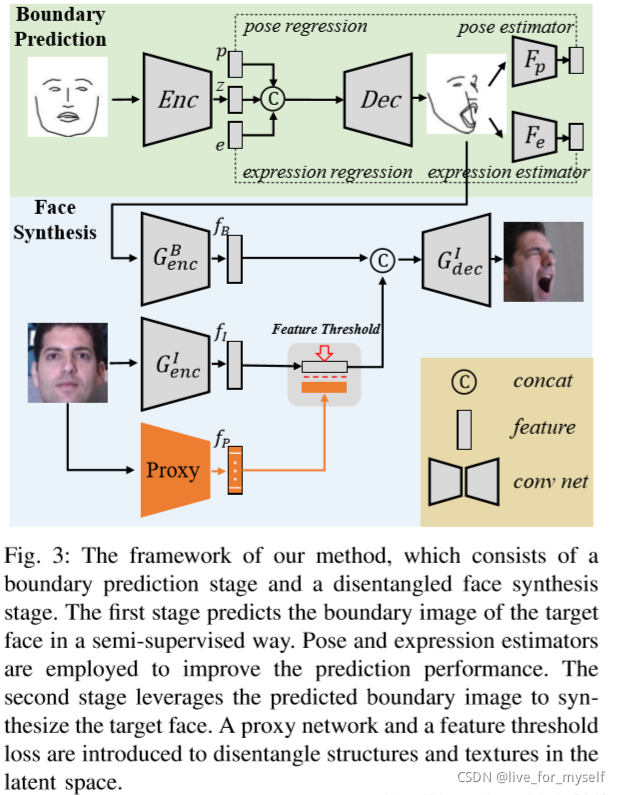
本文先是得到预测的人脸边界轮廓图,然后提取到这个轮廓图的特征fB。之后,使用预训练好的人脸识别网络LightCNN作为Proxy来提取输入人脸图像的结构不变的特征和语义特征,然后结合feature threshold 损失,对编码器提取到的特征fi进行约束。由下列公式可知,特征阈值损失是用来控制编码器和Proxy提取到的特征之间的距离。特征阈值损失的作用是通过训练好的Proxy对编码器进行有监督的训练,使其拥有从人脸特征中提取结构和语义特征的能力。当特征阈值损失很小时,表明编码器已经具有从人脸图像中提取人脸结构和语义特征的能力了。
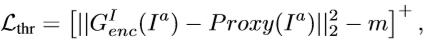
Latent Space Manipulation
这部分是说从encoded的部分可以指导decoder的部分, 有篇论文ICface: Interpretable and Controllable Face Reenactment Using GANs, 结构图如下。可以使用源表情驱动目标的任务, 这个架构有些像cyclegan (Both generators are conditioned on the target AU.)
论文Make a Face: Towards Arbitrary High Fidelity Face Manipulation是可以操作单个人脸的表情, 结构如下: