卷积神经网络:借助卷积核提取特征后,送入全连接网络。
主要模块:一般包括卷积层、BN 层、激活函数、池化层以及全连接层。
一、基本概念
1. 全连接NN
全连接NN特点:每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。
全连接网络参数个数:∑(前层*后层+后层)
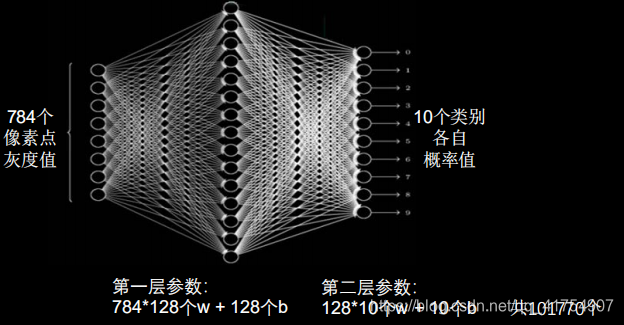
在实际应用中,图像的分辨率远高于此,且大多数是彩色图像。虽然全连接网络一般被认为是分类预测的最佳网络,但待优化的参数过多,容易导致模型过拟合。
为了解决参数量过大而导致模型过拟合的问题,一般不会将原始图像直接输入,而是先对图像进行特征提取,再将提取到的特征输入全连接网络。
2. 卷积(Convolutional)
卷积的概念:卷积可以认为是一种有效提取图像特征的方法。一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点,如下图所示,利用大小为 3×3×1 的卷积核对 5×5×1 的单通道图像做卷积计算得到相应结果。
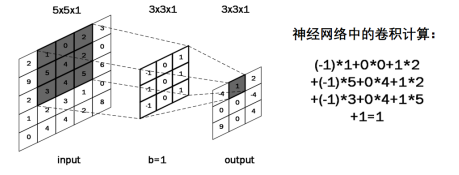
对于彩色图像(多通道)来说,卷积核通道数与输入特征一致,套接后在对应位置上进行乘加和操作,利用三通道卷积核对三通道的彩色特征图做卷积计算。
用多个卷积核可实现对同一层输入特征的多次特征提取,卷积核的个数决定输出层的通道(channels)数,即输出特征图的深度。
3.感受野(Receptive Field)
感受野的概念:卷积神经网络各输出层每个像素点在原始图像上的映射区域大小。
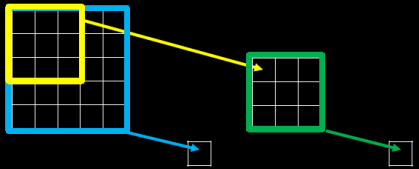
当我们采用尺寸不同的卷积核时,最大的区别就是感受野的大小不同,所以经常会采用多层小卷积核来替换一层大卷积核,在保持感受野相同的情况下减少参数量和计算量,例如十分常见的用 2 层 3 * 3 卷积核来替换 1 层 5 * 5 卷积核的方法。
不妨设输入特征图的宽、高均为 x,卷积计算的步长为 1,显然,两个 3 * 3 卷积核的参数量为 9 + 9 = 18,小于 5 * 5 卷积核的 25,前者的参数量更少。
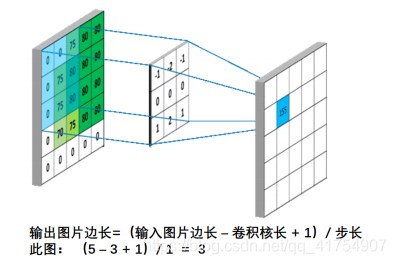
在计算量上,根据下图所示的输出特征尺寸计算公式,对于 5 * 5 卷积核来说,输出特征图共有(x – 5 + 1)^2 个像素点,每个像素点需要进行 5 * 5 = 25 次乘加运算,则总计算量为 25 * (x – 5 + 1)^2 = 25x^2 – 200x + 400;
对于两个 3 * 3 卷积核来说,第一个 3 * 3 卷积核输出特征图共有(x – 3 + 1)^2 个像素点,每个像素点需要进行 3 * 3 = 9 次乘加运算,第二个 3 * 3 卷积核输出特征图共有(x – 3 + 1 – 3 + 1)^2 个像素点,每个像素点同样需要进行 9 次乘加运算,则总计算量为 9 * (x – 3 + 1)^2 + 9 * (x – 3 + 1 – 3 + 1)^2 = 18 x^2 – 108x + 180;
对二者的总计算量(乘加运算的次数)进行对比,18 x^2 – 200x + 400 < 25x^2 – 200x + 400,经过简单数学运算可得 x < 22/7 or x > 10,x 作为特征图的边长,在大多数情况下显然会是一个大于 10 的值(非常简单的 MNIST 数据集的尺寸也达到了 28 * 28),所以两层 3 * 3 卷积核的参数量和计算量,在通常情况下都优于一层 5 * 5 卷积核,尤其是当特征图尺寸比较大的情况下,两层 3 * 3 卷积核在计算量上的优势会更加明显。
输出特征尺寸计算:在了解神经网络中卷积计算的整个过程后,就可以对输出特征图的尺寸进行计算,如图 5-8 所示,5×5 的图像经过 3×3 大小的卷积核做卷积计算后输出特征尺寸为 3×3。
4. 全零填充(padding)
为了保持输出图像尺寸与输入图像一致,经常会在输入图像周围进行全零填充,如图 5-9 所示,在 5×5 的输入图像周围填 0,则输出特征尺寸同为 5×5。
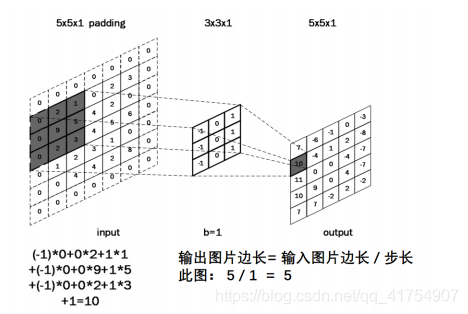
在 Tensorflow 框架中,用参数 padding = ‘SAME’或 padding = ‘VALID’表示是否进行全零填充。

二、tensorflow描述卷积层
1. keras构建CNN中的卷积层
tf.keras.layers.Conv2D(
input_shape = (高, 宽, 通道数), #仅在第一层有
filters = 卷积核个数,
kernel_size = 卷积核尺寸,
strides = 卷积步长,
padding = ‘SAME’ or ‘VALID’,
activation = ‘relu’ or ‘sigmoid’ or ‘tanh’ or ‘softmax’等 #如有 BN 则此处不用写
)
model = tf.keras.models.Sequential([
Conv2D(6, 5, padding='valid', activation='sigmoid'),
MaxPool2D(2, 2),
Conv2D(6, (5, 5), padding='valid', activation='sigmoid'),
MaxPool2D(2, (2, 2)),
Conv2D(filters=6, kernel_size=(5, 5),padding='valid', activation='sigmoid'),
MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(10, activation='softmax')
])
使用此函数应注意:
① 输入图像的信息,即宽高和通道数;
② 卷积核的个数以及尺寸,如 filters = 16, kernel_size = (3, 3)代表采用 16 个大小为 3×3 的卷积核;
③ 卷积步长,即卷积核在输入图像上滑动的步长,纵向步长与横向步长通常是相同的,默认值为 1; D)是否进行全零填充,全零填充的具体作用上文有描述;
④ 采用哪种激活函数,例如 relu、softmax 等,各种函数的具体效果在前面章节中有详细描述;
2. 批标准化(Batch Normalization, BN)
标准化:使数据符合0均值,1为标准差的分布。
批标准化:对一小批数据(batch),做标准化处理 。常用于卷积操作和激活操作之间。
批标准化后,第 k个卷积核的输出特征图(feature map)中第 i 个像素点
利用 Tensorflow 框架构建卷积网络时,一般会利用 BatchNormalization 函数来构建 BN 层,进行批归一化操作,所以在 Conv2D 函数中经常不写 BN。
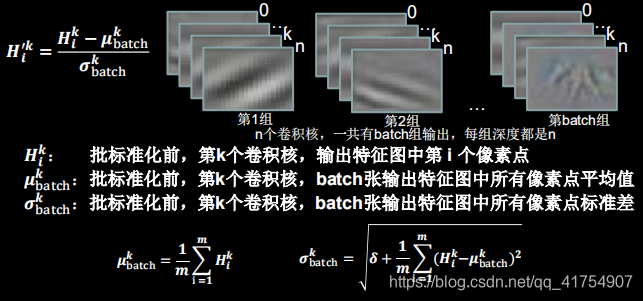
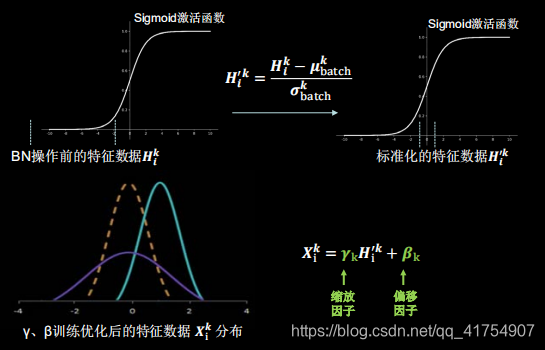
BN操作将原本偏移的特征数据重新拉回到0均值,使进入激活函数的数据分布在激活函数线性区,使得输入数据的微小变化更明显的体现到激活函数的输出,提升了激活函数对输入数据的区分力,但这种简单的特征数据标准化,使特征数据完全满足标准正态分布,集中在激活函数中心的线性区域,使得激活函数丧失了非线性特性,因此在BN操作中为每个卷积核引入了两个可训练参数(缩放因子γ,偏移因子β)。反向传播时γ和β会与其他待训练参数一同被训练优化,使标准正态分布后的特征数据通过γ和β优化了特征数据分布的宽窄和偏移量,保证了网络的非线性表达力。
BN层位于卷积层之后,激活层之前。
TensorFlow提供了BN操作的函数: tf.keras.layers.BatchNormalization()
在调用此函数时,需要注意的一个参数是 training,此参数只在调用时指定,在模型进行前向推理时产生作用,当 training = True 时,BN 操作采用当前 batch 的均值和标准差;当training = False 时,BN 操作采用滑动平均(running)的均值和标准差。在 Tensorflow 中,通常会指定 training = False,可以更好地反映模型在测试集上的真实效果。
model = tf.keras.models.Sequential([
Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2), # dropout层
])
滑动平均(running)的解释:滑动平均,即通过一个个 batch 历史的叠加,最终趋向数据集整体分布的过程,在测试集上进行推理时,滑动平均的参数也就是最终保存的参数。
此外,Tensorflow 中的 BN 函数其实还有很多参数,其中比较常用的是 momentum,即动量参数,与 sgd 优化器中的动量参数含义类似但略有区别,具体作用为滑动平均 running = momentum * running + (1 – momentum) * batch,一般设置一个比较大的值,在 Tensorflow 框架中默认为 0.99。
3. 池化层(Pooling)
池化的作用是减少特征数量(降维)。
最大值池化可提取图片纹理,均值池化可保留背景特征。

在 Tensorflow 框架下,可以利用 Keras 来构建池化层,使用的是 tf.keras.layers.MaxPool2D函数和 tf.keras.layers.AveragePooling2D 函数,具体的使用方法如下:
tf.keras.layers.MaxPool2D(
pool_size = 池化核尺寸, #正方形写核长整数,或(核高h,核宽w)
strides = 池化步长, #步长整数, 或(纵向步长h,横向步长w),默认为pool_size
padding = ‘SAME’ or ‘VALID’ #使用全零填充是“same”,不使用是“valid”(默认)
)
# 均值池化
tf.keras.layers.AveragePooling2D(
pool_size=池化核尺寸, #正方形写核长整数,或(核高h,核宽w)
strides=池化步长, #步长整数, 或(纵向步长h,横向步长w),默认为pool_size
padding=‘valid’or‘same’ #使用全零填充是“same”,不使用是“valid”(默认)
)
model = tf.keras.models.Sequential([
Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2), # dropout层
])
4. 舍弃(Dropout)
在神经网络的训练过程中,将一部分神经元按照一定概率从神经网络中暂时舍弃,使用时被舍弃的神经元恢复链接。
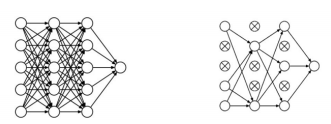
在 Tensorflow 框架下,利用 tf.keras.layers.Dropout 函数构建 Dropout 层,参数为舍弃的概率(大于 0 小于 1)。
model = tf.keras.models.Sequential([
Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2), # dropout层
])
5. 构建神经网络
卷积是什么? 卷积就是特征提取器,就是卷积Convolutional、批标准化BN、激活Activation、池化Pooling、舍弃Dropout
A)import 引入 tensorflow 及 keras、numpy 等所需模块。
B)读取数据集,课程中所利用的 MNIST、cifar10 等数据集比较基础,可以直接从 sklearn 等模块中引入,但是在实际应用中,大多需要从图片和标签文件中读取所需的数据集。
C)搭建所需的网络结构,当网络结构比较简单时,可以利用 keras 模块中的 tf.keras.Sequential 来搭建顺序网络模型;但是当网络不再是简单的顺序结构,而是有其它特殊结构出现时(例如 ResNet 中的跳连结构),便需要利用 class 来定义自己的网络结构。前者使用起来更加方便,但实际应用中往往需要利用后者来搭建网络。
D)对搭建好的网络进行编译(compile),通常在这一步指定所采用的优化器(如 Adam、sgd、RMSdrop 等)以及损失函数(如交叉熵函数、均方差函数等),选择哪种优化器和损失函数往往对训练的速度和效果有很大的影响。
E)将数据输入编译好的网络来进行训练(model.fit),在这一步中指定训练轮数 epochs 以 及 batch_size 等信息,由于神经网络的参数量和计算量一般都比较大,训练所需的时间也会比较长,尤其是在硬件条件受限的情况下,所以在这一步中通常会加入断点续训以及模型参数保存等功能,使训练更加方便,同时防止程序意外停止导致数据丢失的情况发生。
F)将神经网络模型的具体信息打印出来(model.summary),包括网络结构、网络各层的参数等,便于对网络进行浏览和检
三、Cifar10构建卷积神经网络实例
1.Cifar10数据集
该数据集共有 60000 张彩色图像,每张尺寸为 32 * 32,分为 10 类,每类 6000 张。训练集 50000 张,分为 5 个训练批,每批 10000 张;从每一类随机取 1000张构成测试集,共 10000 张,剩下的随机排列组成训练集。

# 数据集下载
cifar10 = tf.keras.datasets.cifar10
# 导入训练集和测试集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
cifar10 是一个用于图像分类的数据集,共分 10 类,相较于 mnist 数据集会更复杂一些,训练难度也更大,但是图像尺寸较小,仅为 32 * 32,仍然属于比较基础的数据集,利用一些 CNN 经典网络结构(如 VGGNet、ResNet 等)进行训练的话准确率很容易就能超过 90%,很适合初学者用来练习。目前学术界对于 cifar10 数据集的分类准确率已经达到了相当高的水准。
利用 tf.keras.Sequential模型以及 class 定义两种方式都可以构建出基础 CNN 网络,前者看起来会更简洁一些,但后者在实际应用中更加常用,因为这仅仅是一个非常基础的网络,而一些复杂的网络经常会有 Sequential 模型无法表达的结构或设计。
搭建卷积神经网络
C(6个5*5的卷积核,步长为1,全零填充‘same’)
B(使用批标准化Yes)
A(使用relu激活函数)
P(使用最大池化,池化核2*2,步长为2,全零填充‘same’)
D(休眠20%的神经元)
Flatten(把卷积送过来的数据拉直)
Dense(神经元:128,激活函数:relu,Dropout:0.2)
Dense(神经元:10,激活函数:softmax)
class Baseline(Model):
def __init__(self):
super(Baseline, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5), padding='same') # 卷积层
self.b1 = BatchNormalization() # BN层
self.a1 = Activation('relu') # 激活层
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') # 池化层
self.d1 = Dropout(0.2) # dropout层
self.flatten = Flatten()
self.f1 = Dense(128, activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y