卷积神经网络名字听着挺吓人,本文用通俗易懂的方式解释。人人都能看懂。
文章目录
卷积是什么
卷积神经网络就是传统神经网络运用了矩阵卷积的技术。
二维线性卷积:
矩阵举例:

(部分内容摘抄自此文)
现在有一张图片(下图左) 和一个kernel核(下图中间)。通过卷积可以得到下图右的结果。
我们知道,图片实际上就是一个巨大的数值矩阵,也就是我们常说的像素。一张灰色图片就是一个巨大的二维矩阵,矩阵中每个元素表示黑白的程度,可以理解为就是一个数学矩阵。
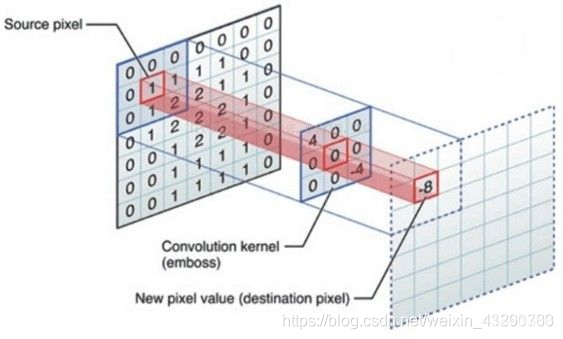
二维卷积:从二维矩阵中拿到第一个值,即图示中的标红框1,1所在的位置对上卷积核kernel 中心位置,即图示中的红色框(卷积核就是一个矩阵),对应位置的值与矩阵元素相乘最后求和,得到的值便是新的值-8(计算方法见上文矩阵求卷积运算),以此类推,取得所有位置的新值,最后图片的最外层填上0就可以了。二维卷积得到的大小取决与卷积核,而卷积核大小一般是奇数大小(例3×3, 5×5),表示取像素值取决周围一圈的像素值,取决的权重由卷积核决定,提取该区域特定特征。
一、卷积神经网络介绍
卷积神经网络(CNN)可用于使机器可视化事物并执行诸如图像分类,图像识别,对象检测,实例分割等任务。这是CNN最常见的领域,如字迹识别等。
卷积层–提取局部图片特征

图片有RGB三个颜色通道,因此输入是3层,由于3个输入通道(红色R,绿色G和蓝色B),我们看到的任何图像都是3通道图像。可以理解为3层,因此卷积核也是3层,相当于两个3*3的魔方对应的9个元素相乘,最后9个乘积相加。因此,卷积核相当于使用3层二维(长和宽)过滤器,图像的通道数(层数)和过滤器层数相同。
与2D卷积操作类似,我们将在水平方向上滑动过滤器。每次移动过滤器时,我们都将获取整个图片三个通道(3层)的加权平均值,即RGB值的加权邻域。由于我们仅在两个维度上滑动内核-从左到右,从上到下,此操作的输出将是2D输出。
假设我们有大小为7x7的2D输入,并且正在从图像的左上角开始在图像上应用3x3的滤镜。当我们从左到右,从上到下在图像上滑动内核时,很明显,输出小于输入,即5x5。

如果我们希望输出与输入大小相同怎么办?
如果原始输入的大小为7x7,我们也希望输出大小为7x7。因此,在那种情况下,我们可以做的是在输入周围均匀添加一个人工填充(值为零),这样我们就可以将过滤器K(3x3)放置在图像像素点上,并计算邻居的加权平均值。
一个卷积核就是提取一个特征,因此,为了充分提取图片的特征,我们需要多个卷积核对图片进行特征提取,这就叫卷积核的深度,得到的结果就是多个2D输出,堆叠在一起,就有多层输出。如图:
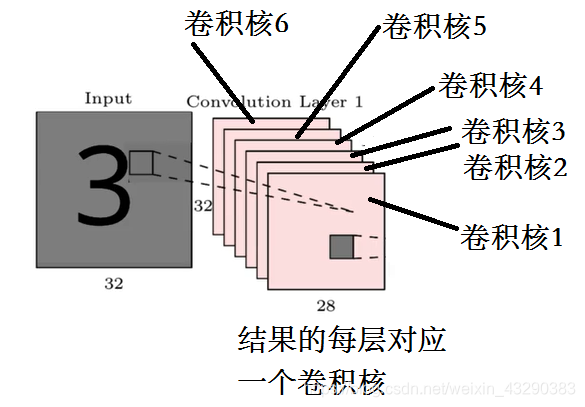
理解了这个图,才能理解最后那个卷积神经网络的架构图。多层卷积会导致这种彩色的层数增加。
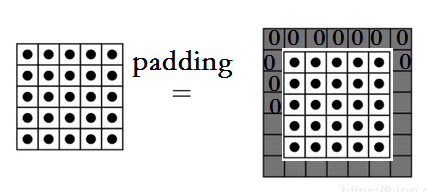
扩充–padding,保持卷积后图片的长和宽保持不变
通过在输入周围添加一圈(零)这种人工填充,我们可以将输出的形状与输入保持相同。如果我们有一个更大的过滤器K(5x5),那么我们需要应用零填充的数量也会增加,这样我们就可以保持相同的输出大小。在此过程中,输出的大小与输出的大小相同,因此命名为Padding。原文见此链接
池化层—降低维度,降低模型复杂度和计算量
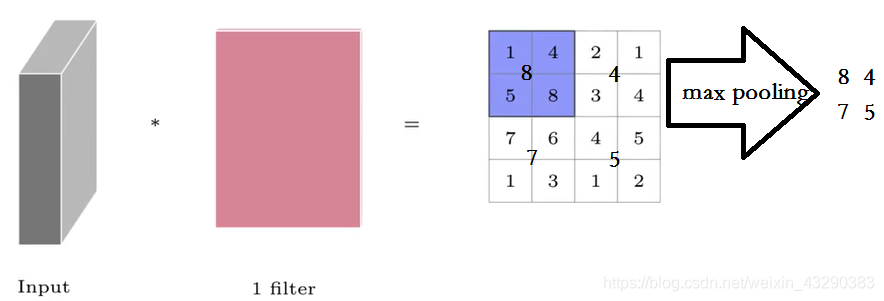
获得了特征图,通常我们将执行一个称为Pooling operation的操作。由于学习图像中存在的复杂关系所需的隐藏层数将很大。我们应用池化操作来减少输入特征的表示,从而降低网络所需的计算能力。
一旦获得输入的特征图,我们将在特征图上应用确定形状的过滤器,以从特征图的该部分获得最大值。这称为最大池化。这也称为子采样,因为从内核覆盖的特征图的整个部分中,我们正在对一个最大值进行采样。

flatten展平–让多维数据变成一个巨大的一维向量
我们得到了多个粉色的卷积结果,是个多维的,如卷积层那节最后的那个图所示。
可是我们预测的结果是一维的,比如二分类,不是0就是1,多维的数据怎么得到一维的输出呢?
简单嘛,把多维的数据全部摊平,成一个一维的数组,就像你把很多个魔方,一个个的掰下来,排成一排。魔方就是多维的啊,你不就是把多个多维的数组,变成一维的数组了吗?


全连接层–输出结果
一旦我们对图像的特征表示进行了一系列的卷积和pooling操作(最大合并或平均合并,也称下采样)。我们将最终池化层的输出展平为一个向量,并将其通过具有不同数量隐藏层的全连接层(前馈神经网络)传递,最后经过多层的深度神经网络进行拟合。
最后,完全连接层的输出将通过所需大小的Softmax层。Softmax层输出概率分布的向量,这有助于执行图像分类任务。在数字识别器问题(如上所示)中,输出softmax层具有10个神经元,可将输入分类为10个类别之一(0–9个数字)。如果是个二分类问题,则Softmax层就是2个神经元,分别输出0,1,所以最后的Softmax层是根据最终结果需要分多少类来确定的。

如果是2分类,最后那个softmax成就是只有两个神经元,表示2类输出。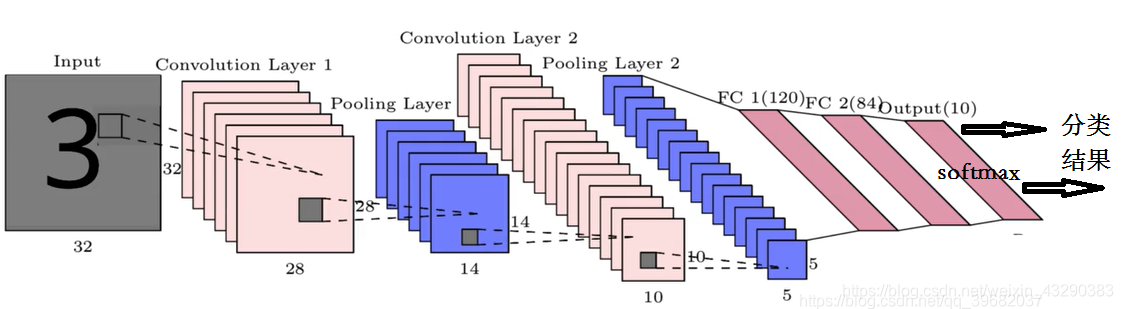
二、TensorFlow2代码实现
1.导入数据
我们用TensorFlow2自带的mnist测试手写的0-9数字,然后判定他具体写的是哪个数字。
向导入数据,新建一个MNISTLoader的类。
代码如下(命名为testData.py):
import numpy as np
import tensorflow as tf
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data,self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道RGB,如果没有这个维度就是灰度的图片,没有彩色。
self.train_data = np.expand_dims(self.train_data.astype(np.float)/255.0,axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0] #60000,10000
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, self.num_train_data, batch_size) #可以重复取某条数据
return self.train_data[index, :], self.train_label[index]
# mnist = MNISTLoader()
# batch_size = 1
# train_data,train_label = mnist.get_batch(batch_size)
# print(train_data*255)
# print(train_label)
# print(train_data[0,:,1])
2.用TensorFlow2构建一个CNN网络
代码结构如下:
1、定义超参数
2、定于模型结构
3、对模型进行训练
4、预测测试集并测试准确度
import numpy as np
import tensorflow as tf
from testData import *
import time
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1= tf.keras.layers.Conv2D(
filters=32, #卷积核的数目32,提取32维特征
kernel_size=[5,5], #感觉野,卷积核的长和宽
padding='same', #padding 策略 (vaild、same)
activation= tf.nn.relu #激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2,2],strides=2) #池化层一般用2X2矩阵
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2,2],strides=2) #池化层一般用2X2矩阵
self.flatten = tf.keras.layers.Reshape(target_shape=(7*7*64,)) #把二维的矩阵展平为1维
self.dense1 = tf.keras.layers.Dense(units=1024,activation=tf.nn.relu) #第一层全连接层,1024个神经元
self.dense2 = tf.keras.layers.Dense(units=10) #最后一层全连接层,激活函数要用softmax,神经元数量为分类数量
def call(self,inputs):
x = self.conv1(inputs) #经过第一个卷积层
x = self.pool1(x) #经过第一个池化层,下采样
x = self.conv2(x) #经过第二个卷积层
x = self.pool2(x) #经过第二个池化层,下采样
x = self.flatten(x) #把中间结果拉平成一个大的一维向量
x = self.dense1(x) #经过第一个全连接层
x = self.dense2(x) #结果第二个全连接层,也是最后一层,叫softmax层
output = tf.nn.softmax(x)
return output
#主控程序,调用数据并训练模型
#定义超参数
num_epochs = 5 #每个元素重复训练的次数
batch_size = 50
learning_rate = 0.001
print('now begin the train, time is ')
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
model = CNN()
data_loader = MNISTLoader()
optimier = tf.keras.optimizers.Adam(learning_rate=learning_rate)
num_batches = int(data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range(num_batches):
X,y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y,y_pred=y_pred)
loss = tf.reduce_sum(loss)
print("batch %d: loss %f"%(batch_index,loss.numpy()))
grads = tape.gradient(loss,model.variables)
optimier.apply_gradients(grads_and_vars=zip(grads,model.variables))
print('now end the train, time is ')
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
#模型的评估
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches_test = int(data_loader.num_test_data//batch_size) #把测试数据拆分成多批次,每个批次50张图片
for batch_index in range(num_batches_test):
start_index,end_index = batch_index*batch_size,(batch_index+1)*batch_size
y_pred = model.predict(data_loader.test_data[start_index:end_index])
sparse_categorical_accuracy.update_state(
y_true = data_loader.test_label[start_index:end_index],
y_pred=y_pred
)
print('test accuracy: %f'%sparse_categorical_accuracy.result())
print('now end the test, time is ')
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
运行的预测准确率能达到99.15%。太不可思议了。
输出结果:
batch 5999: loss 0.094517
now end the train, time is
2021-03-18 17:15:46
test accuracy: 0.991500
now end the test, time is
2021-03-18 17:16:05
总结
搭建一个卷积神经网络只需要满足:确定层数、按照卷积、激活、池化等流程定义每一层、层与层之间输入输出匹配,要输出结果,就需要把2维甚至多维的矩阵展平成一个大的1维矩阵,然后用全连接又可以构建输出端的多层神经网络,最后输出的那层用到了softmax函数进行分类,输出的概率最大的那个结果,就是我们的预测结果。
因此实现一个卷积神经网络的搭建。准确率已经相当不错了。