数据分析的四阶段
-
提出需求:确定目标
-
准备数据:数据搜集和规整,最花时间(公司内部:办公室相关人员;系统、网站管理员找数据库)(公开信息:互联网爬虫)
-
分析数据
-
描述性分析:指标计算和可视化
-
探索性分析:建模,预测 (设计建模,基础含量高,市场上绝大报告没有)
-
-
总结和建议
1 需求
数据情况
数据由3个单元表组成:
- 订单信息表:
- 订单ID
- 客户ID
- 订单状态
- 1表示正常完成订单
- 0表示未完成订单
- 优惠类型
- 0表示无优惠
- 1表示优惠
- 货物信息表:
- 订单ID
- 货物ID
- 货物名称
- 优惠额度
- 分组显示优惠额度
- 顾客信息表:
- 客户ID
- 登陆次数
- 注册时间(距1970-1-1的秒数)
- 本次购买时间(距1970-1-1的秒数)
- 经验值
- 订单数
需求
-
核心需求:分离在本电商平台购物的无价值用户
- 将平台购物的用户分为正常用户和无价值用户,
- 无价值用户一般指很少购买正常价格商品,大多购买优惠和促销商品的用户
-
其他综合需求:
- 分析下平台的订单情况、商品情况
- 分离正常用户和无价值用户后,进一步分析二者在网站上的行为差异
-
针对性需求1:货物信息表
- 不同优惠额度的订单数量
- 能否根据优惠额度分组可视化产品销量情况
- 能否输出正常价格下销量最好的前10个产品
- 能否输出优惠价格下销量最好的前10个产品
-
针对性需求2:订单信息表
- 能否根据订单状态筛选出已完成订单
- 能否根据客户id和优惠类型分出 正常客户和无价值客户
-
针对性需求3:顾客信息表
- 能否将订单信息表得出的 正常客户和无价值客户列,合并到本表中
- 能否通过客户id列,和正常、无效客户列,得出正常和无效客户分别在:
- 登陆次数,注册时间,本次购买时间,经验值,订单数,等指标下的对比差异?
- 注册和登录时间间隔的对比差异?
产出
要求:根据给定数据和需求,从头完成一个完整版的数据分析报告
并产出下列文档:
- Jupyter-Notebook版
- 综合:用于数据分析项目代码实现和演讲、传播
- HTML网页版
自动生成,用于传播交流 - PDF版
自动生成,用于传播交流
- PPT版
- 手动制作,用于演讲展示
可以使用Jupyter快速导出HTML和PDF版本(chrme打印网页),但效果一般。
如果对效果要求较高,建议导出md格式,自行编辑,再使用markdown导出HTML和PDF
2 数据规整(数据预处理,数据清洗,数据重构)
数据规整是数据分析的预操作,数据分析报告中不体现
# 导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
plt.style.use('seaborn') # 改变图像风格
plt.rcParams['font.family'] = ['Arial Unicode MS', 'Microsoft Yahei', 'SimHei', 'sans-serif'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # simhei黑体字 负号乱码 解决
- 读取文件
shop = pd.read_excel('data\\shop.xlsx',None)
shop
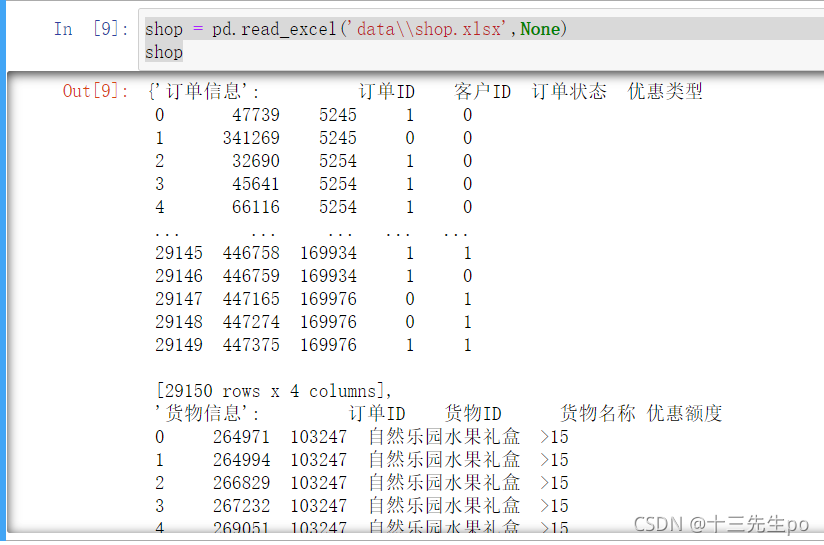
- 对不同表格赋予实参
dingdan = shop['订单信息']
huowu = shop['货物信息']
guke = shop['顾客信息']
dingdan
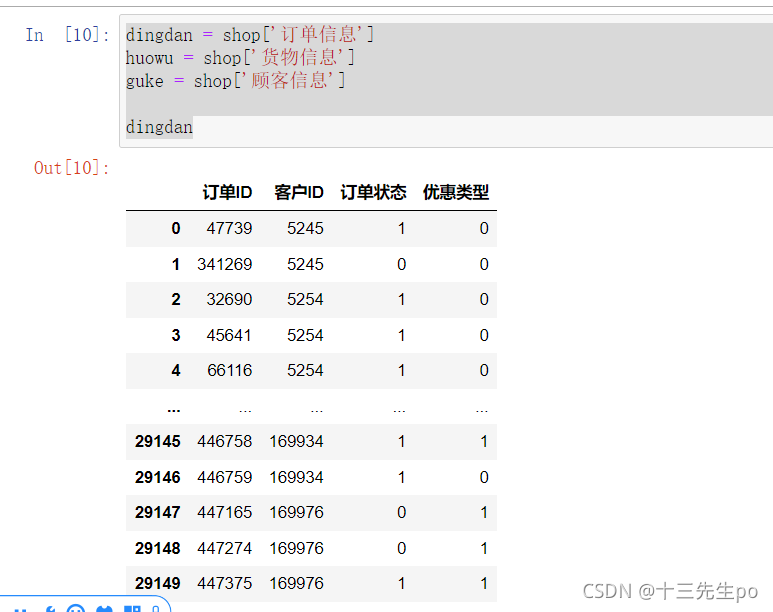
成功读取
2.1 数据预处理
检查数据是否有缺失值和异常列类型
提前自己判断一下每张表每列数据的一般数据类型,如果有异样就检查,例如一列只有数字的,却是object字符串类型(只要有一个字符画,整列都算字符串类型)
# 数据预处理
# 检查数据是否有缺失值和异常列类型
# 提前自己判断一下每张表每列数据的一般数据类型,如果有异样就检查,例如一列只有数字的,却是object字符串类型
dingdan.info()
huowu.info()
guke.info()
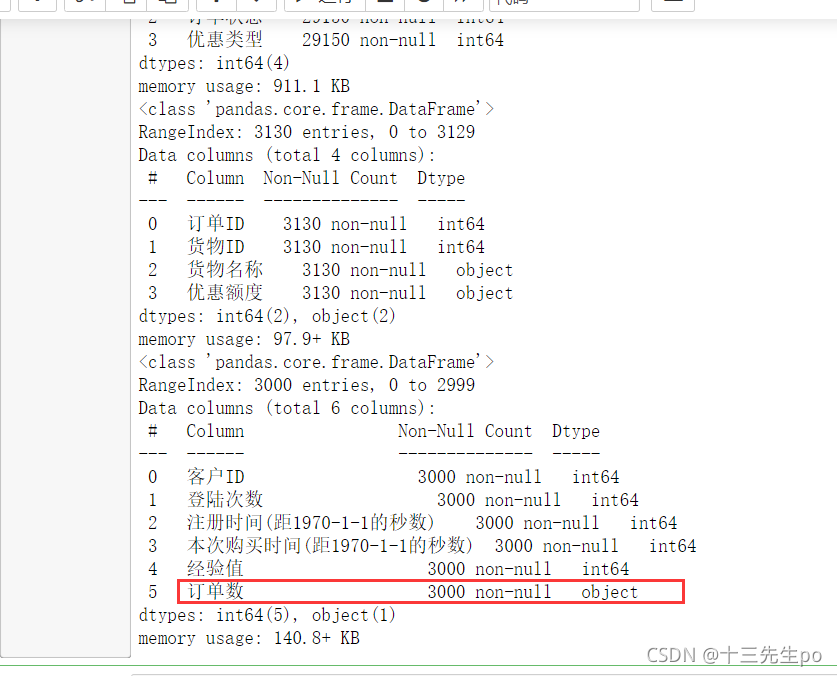
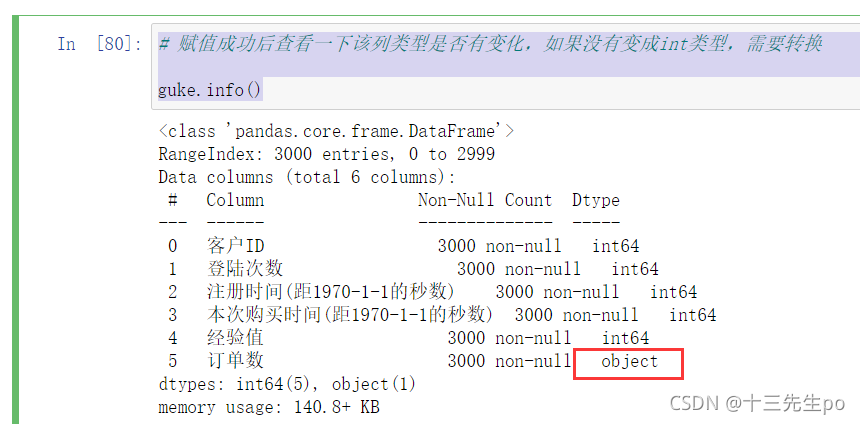
发现顾客信息的订单数一列,通常只有数字值,却是object字符串类型
2.1.1 发现错误的对策
随机找一个值看看有没有问题
# 随机找一个值看看有没有问题
type(guke.loc[0,'订单数']) # 写法1
type(guke.loc[0,'订单数']) == int # 写法2 布尔判断
type(guke.loc[0,'订单数']) == np.int # 写法3 正规写法,这里的int类型不是普通的int类型

如果没有
- 方法1:使用遍历方式找到错误值
# 使用遍历方式找到错误值
for index,row in guke.iterrows():
# print(index) # 表格的行号
# print(row) # 表格的行
# print(type(row)) # <class 'pandas.core.series.Series'>
# print(row['订单数']) # 每行中订单数对应的值
if type(row['订单数']) != np.int:
# 如果不是int类型,输出行号和该行订单数对应的值
print(index,'--',row['订单数'])
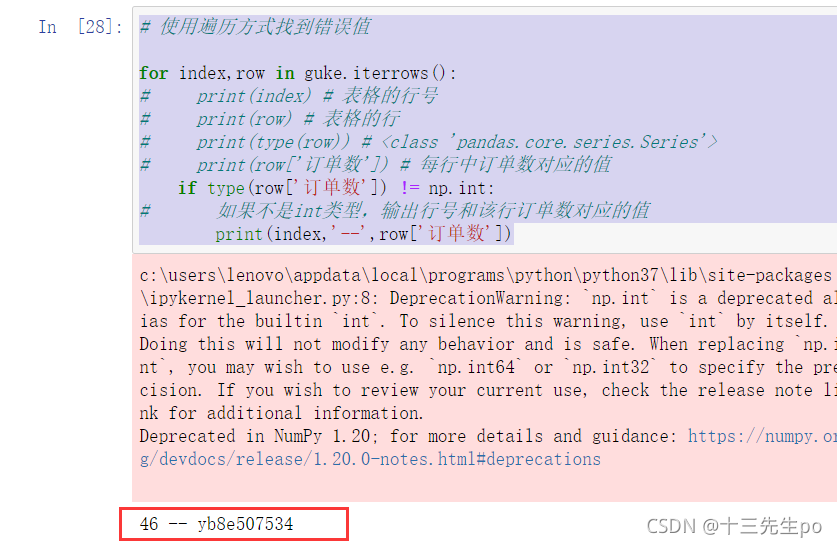
使用索引方法loc查看一下
guke.loc[46]

找到了错误值
- 方法2:使用Pandas自定义函数实现
在自定义函数中遍历对应值,并对判断正确的值返回False值,对判断错误的值返回True值,利用pandas数据结构默认输出True值的特点锁定错误值
# 使用Pandas自定义函数实现
def check(x):
# print(x['订单数']) # 我们发现可以用传入的参数锁定到‘订单数’列
if type(x['订单数']) == np.int:
# 布尔值True和False调转输出,
# 我们可以直接锁定输出True的值,而输出True的值恰恰是错误的值
return False
else:
return True
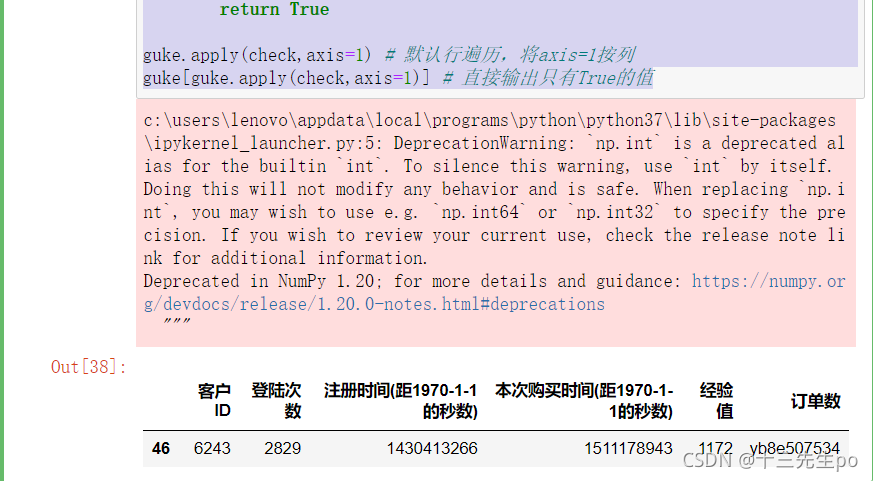
guke.apply(check,axis=1) # 默认行遍历,将axis=1按列
guke[guke.apply(check,axis=1)] # 直接输出只有True的值
- 写法3:自定义函数的匿名函数写法
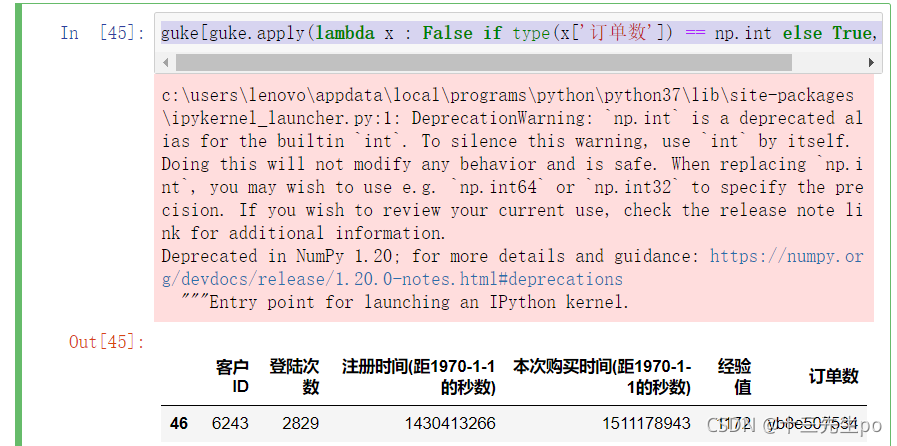
#匿名函数写法
guke[guke.apply(lambda x : False if type(x['订单数']) == np.int else True,axis=1)]
2.1.2 修正缺失值
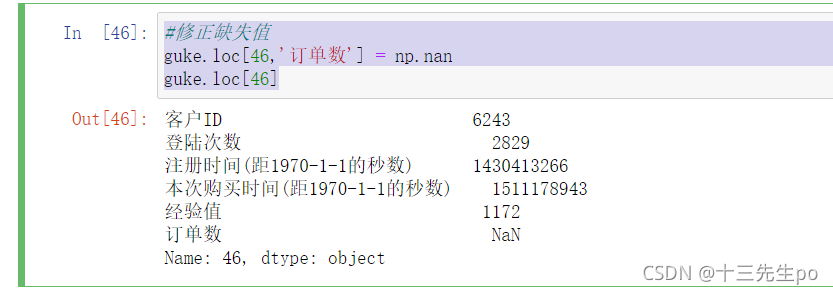
#修正缺失值
guke.loc[46,'订单数'] = np.nan
guke.loc[46]
2.2 修正错误数据
方法1:取平均值/中位数
用经验值列判断错误订单数数据大致范围,取平均值/中位数
特点:通用,套路,无脑操作
# 修正错误数据
# 方法1
# 查看订单数和经验值的关系
guke['订单数'].mean() # 所有客户平均订单数8.448
guke['经验值'].mean() # 所有客户经验值672.35
# 该错误数据的经验值为1172,我们检查一下相似经验值的客户的订单数
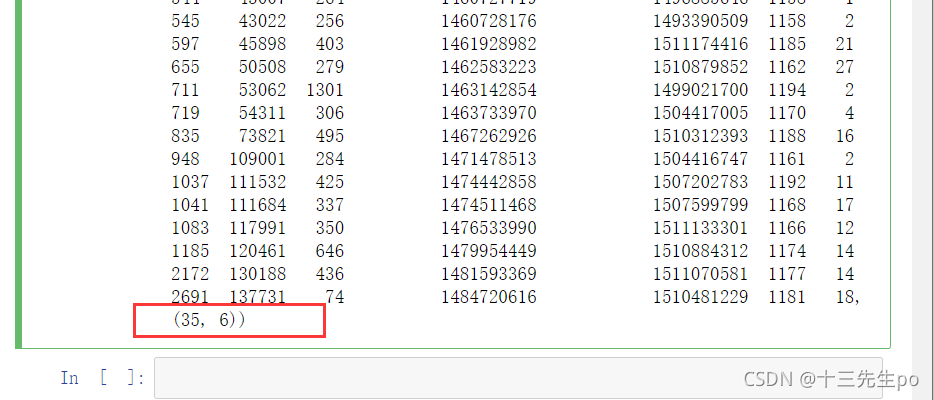
# 发觉区间定在1100-1200之间订单数差距较大,改小范围
# si = guke[(guke['经验值']>1100) & (guke['经验值']<1200)]
si = guke[(guke['经验值']>1150) & (guke['经验值']<1200)]
si,si.shape
# 查询该区间最大值,最小值,平均值
si['订单数'].min(),si['订单数'].max(),si['订单数'].mean(),si['订单数'].median() # 写法1
si.订单数.min(),si.订单数.max(),si.订单数.mean(),si.订单数.median() # 写法2

方法2:从其他表数据设法得出本客户ID订单数据
可能不完全对,但准确率超过自行求值
优点:最精确
缺点:对数据有要求。仅在部分情况下能够使用
需要超凡的洞察力,大力研究已有表格数据
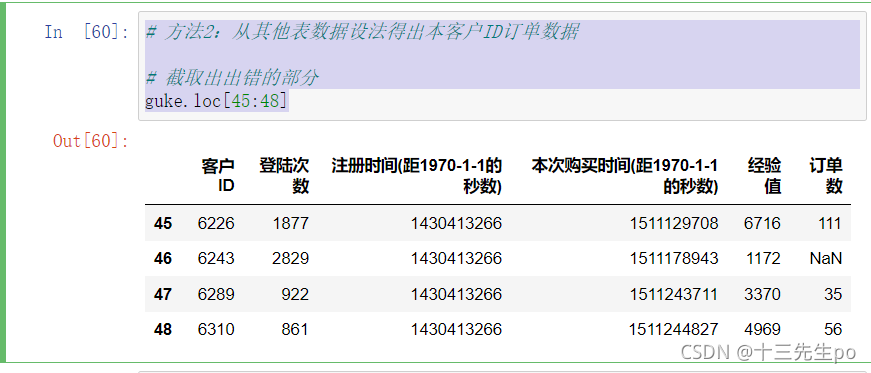
-截取出出错的部分
# 方法2:从其他表数据设法得出本客户ID订单数据
# 截取出出错的部分
guke.loc[45:48]
- 对比一下其他表格
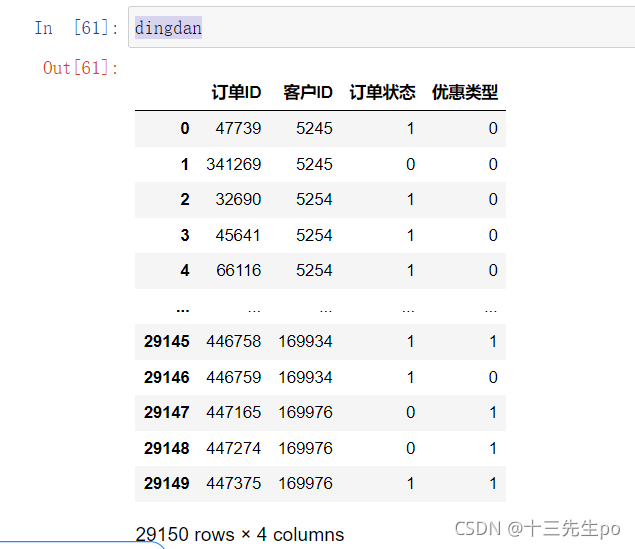
订单表格中的客户id有重合,而且有订单状态计数,尝试将客户id=6226有记录的数据找出来,两个表格对比数据对比一下
# 客户ID 6226 对应的订单数
guke.loc[45, '订单数'] # 111
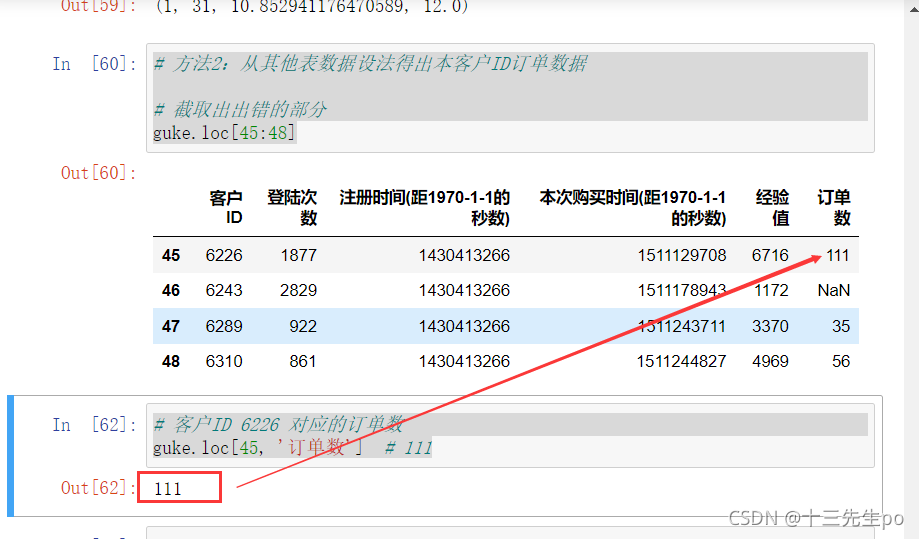
查看客户ID 6226 在订单表格中对应的订单数,发觉数据比较相似
# 客户ID 6226 在订单表格中对应的订单数
dingdan[dingdan['客户ID'] == 6226].shape[0] ## 104

再缩小范围,检索一下其成交的订单数,数值减小,说明所有的订单数加起来才和客户表中的订单数值比较相似
# 客户ID 6226 在订单表格中对应的订单数
dingdan[dingdan['客户ID'] == 6226].shape[0] ## 104
# 再缩小范围,检索一下其成交的订单数,数值减小,说明所有的订单数加起来才和客户表中的订单数值比较相似
dingdan[(dingdan['客户ID'] == 6226) & (dingdan['订单状态'] == 1)].shape[0] # 97
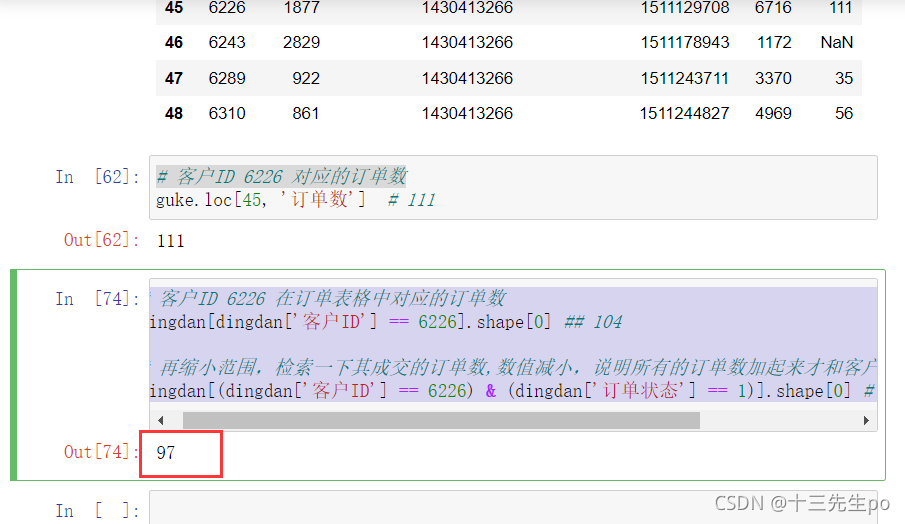
我们选择所有的订单状态加起来的值,来找到那位缺失订单数的客户6243的大致订单数
# 选择所有的订单状态加起来的值,
# 来找到那位缺失订单数的客户6243的大致订单数
dingdan[(dingdan['客户ID'] == 6243)].shape[0] # 146
# dingdan[(dingdan['客户ID'] == 6243) & (dingdan['订单状态'] == 1)].shape[0] # 124

- 赋值
# 赋值
guke.loc[46,'订单数'] = dingdan[(dingdan['客户ID'] == 6243)].shape[0]
guke.loc[46:48] # 赋值成功
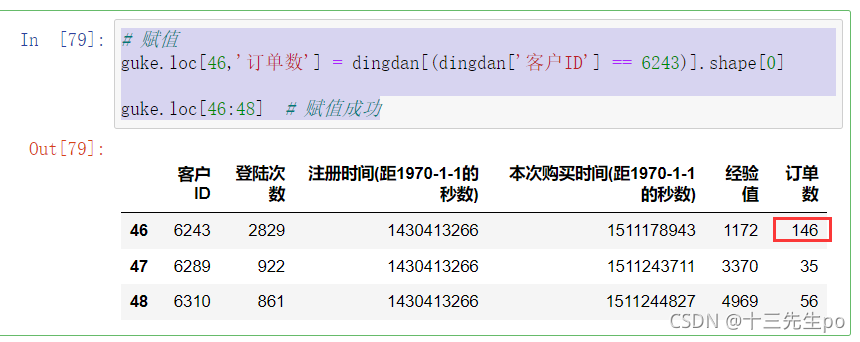
赋值成功后查看一下该列类型是否有变化,如果没有变成int类型,需要转换
# 赋值成功后查看一下该列类型是否有变化,如果没有变成int类型,需要转换
guke.info()
- 进行转换
# 修改类型
# 备份一份防止改错
guke2 = guke
# 在备份数据中修改
guke2['订单数'] = guke2['订单数'].astype(np.int)
guke2.info()
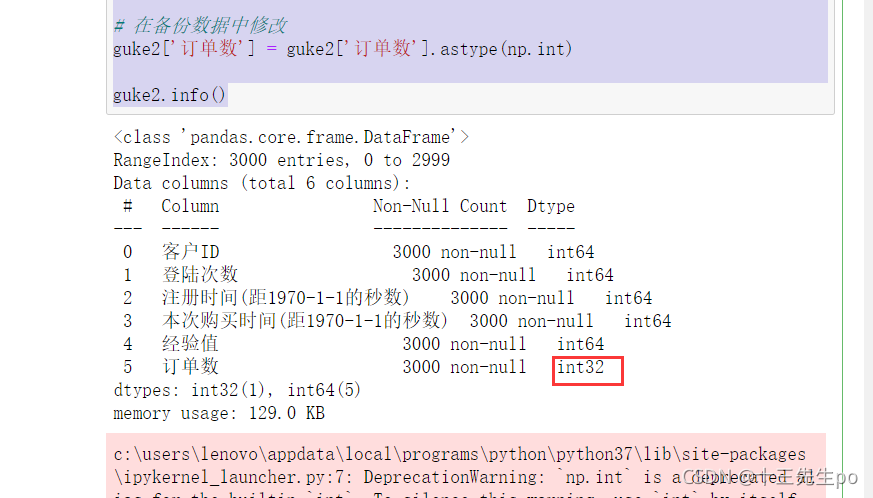
修改成功
- 输出平均值
guke2['订单数'].mean()

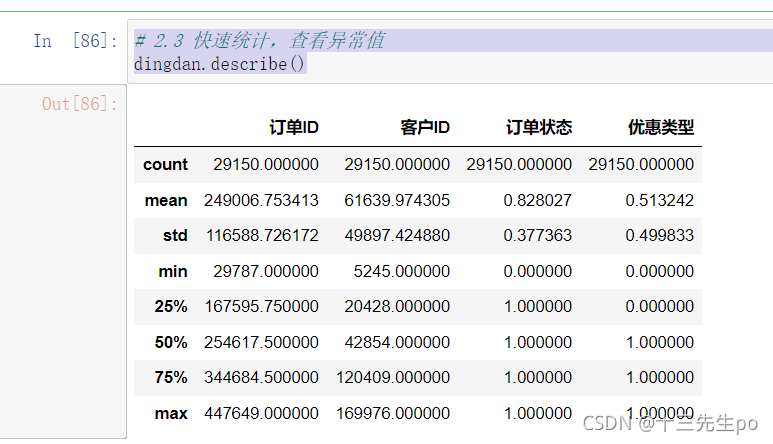
2.3 快速统计,查看异常值
# 2.3 快速统计,查看异常值
dingdan.describe()
huowu.describe()
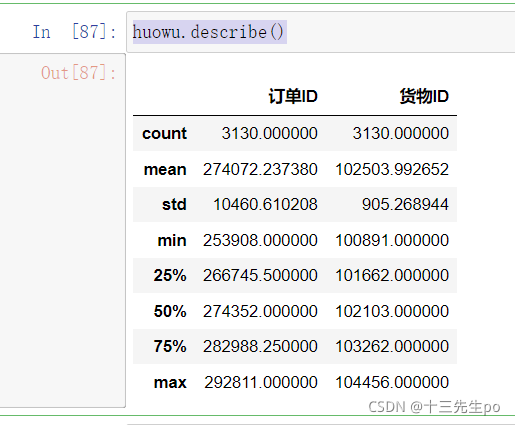
guke2.describe()
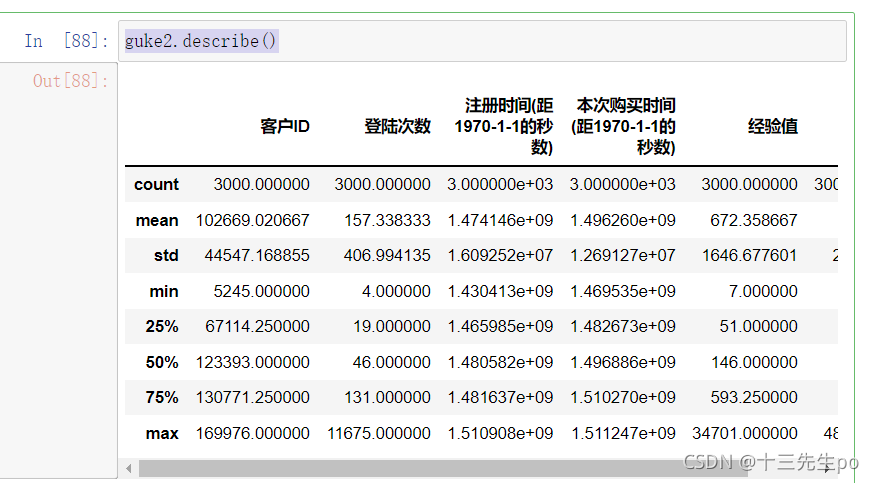
排序
# 按登陆次数排序用户
guke2.sort_values(by='登陆次数',ascending=False)[:10]
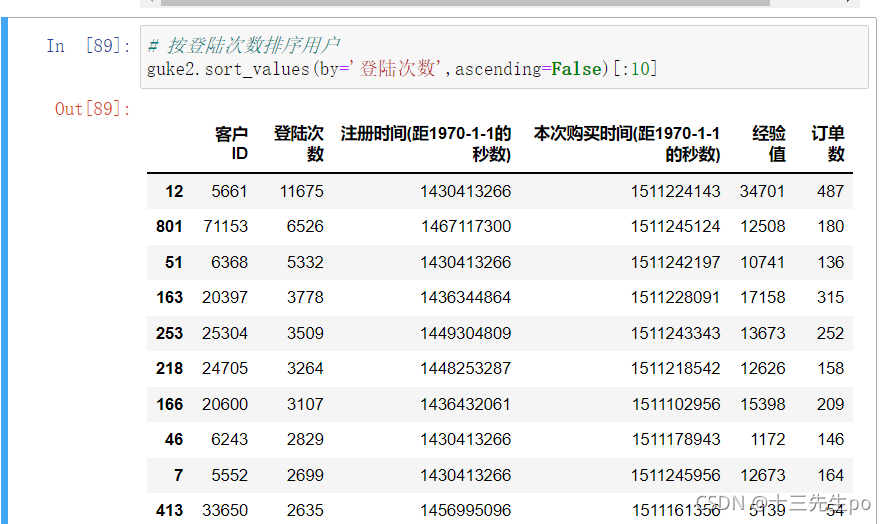
# 按订单数排序用户
guke2.sort_values(by='订单数',ascending=False)[:10]
- 订单数为0的所有用户
# 订单数为0的所有用户
guke2[guke2['订单数'] == 0]
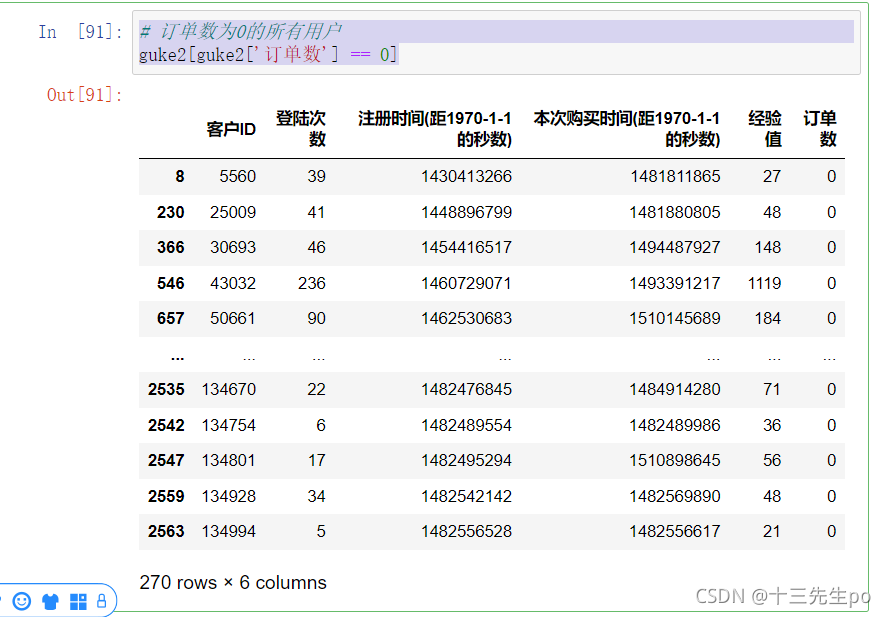
- 订单数为0的所有用户 按登陆次数排序
# 订单数为0的所有用户 按登陆次数排序
guke2[guke2['订单数'] == 0].sort_values(by='登陆次数',ascending=False)[:10]
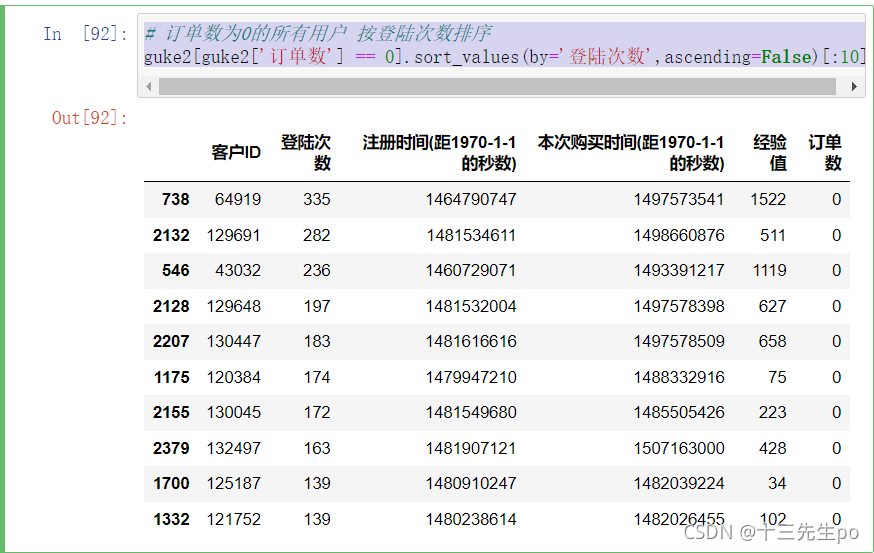
- 删掉订单数为0的用户,因为这部分客户暂时没有用处
# 可以删掉订单数为0的用户,因为这部分客户暂时没有用处
guke3 = guke2
guke3[guke3['订单数'] == 0].index
# drop方法只对本行操作的数据有效,并不会对目标造成实际操作
# 将改好的数据传给另外一个实参对象guke4
guke4 = guke3.drop(guke3[guke3['订单数'] == 0].index)
guke4
删除成功
- 对改好的数据重新赋值
# 对改好的数据重新赋值
guke = guke4
guke
- 结论:数据整体查看,没有特别异常的数据
2.4 数据保存
# 2.4 数据保存
writer = pd.ExcelWriter('2 电子商务平台数据分析实战1 - 数据规整和分析思路\long_new\shop2.xlsx')
dingdan.to_excel(
writer, # 写入数据
'订单信息', # 工作表标签
index=False # 不存入行索引
)
huowu.to_excel(
writer, # 写入数据
'货物信息', # 工作表标签
index=False # 不存入行索引
)
guke.to_excel(
writer, # 写入数据
'顾客信息', # 工作表标签
index=False # 不存入行索引
)
writer.save()
保存成功
2.5 描述性分析:指标计算、可视化
2.5.1 案例
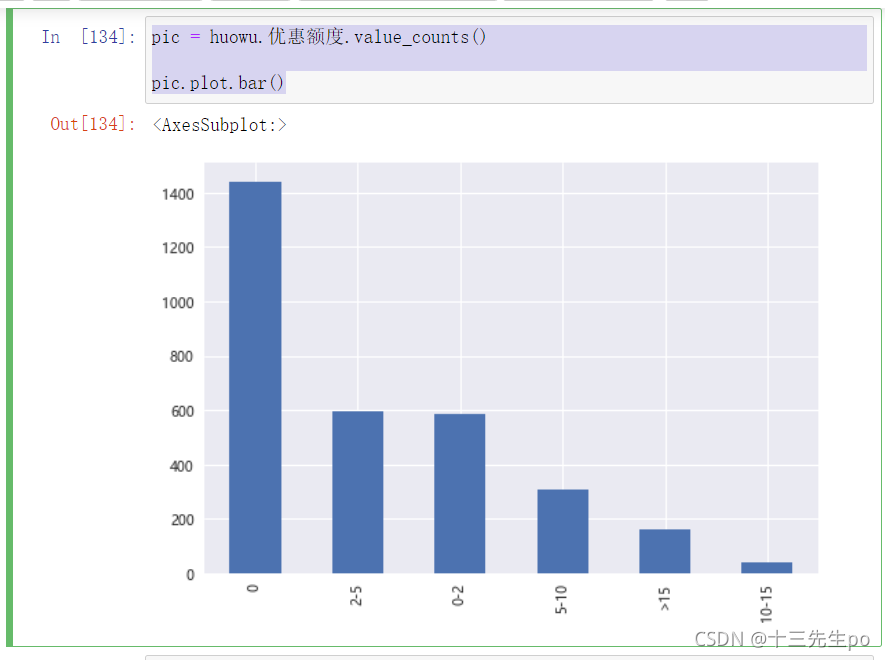
- 共有多少种优惠额度
- 每个优惠额度下有多少订单
# 查看优惠额度种类
huowu.优惠额度.value_counts() # 写法1 对列直接聚合
huowu.groupby('优惠额度').size().sort_values(ascending=False) # 写法2 groupby聚合函数后size查看
- 可视化
pic = huowu.优惠额度.value_counts()
pic.plot.bar()
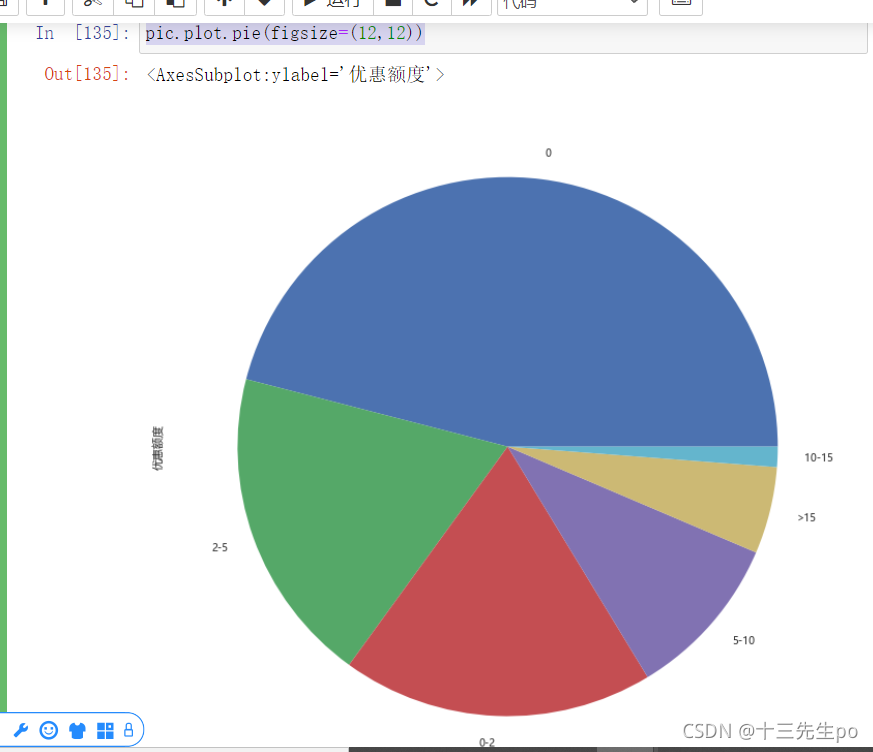
pic.plot.pie(figsize=(12,12))
2.5.2 指标计算思路
- 如果你精通要分析的业务,那么不需要套路,你会自己根据业务知识寻找计算指标
- 如果你完全不懂你要分析的业务
- 把有价值的列(离散数据列,如果是连续数据需要先离散化),每个单提出来,做交叉表分析(分组聚合,单列,乞丐版交叉表)
- 例子:优惠额度订单排名,销量前10商品排名,销量倒数10商品排名
- 将有价值的列,两两组合/三列组合(多列组合,不常用),做分组聚合(透视表,交叉表)
- 离散数据可以直接做分组基准,连续数据不能直接做分组基准,可以做分组后聚合的列(求平均值等指标)
- 连续数据需要先离散化,再做分组操作(pd.cut(), pd.qcut(),分位数分析)
- 两列或多列交换分组聚合的列的顺序,可以得到更多指标
- 例子:打折商品销量排名前10,不打折商品销量排名前10
- 把有价值的列(离散数据列,如果是连续数据需要先离散化),每个单提出来,做交叉表分析(分组聚合,单列,乞丐版交叉表)
2.5.3 实战过程1:指标创建
- 引入问题
有一类客户基本只购买优惠促销商品,很少购买正价商品,这类客户对企业没有价值,只会增加营销成本
企业想要将无价值客户识别出来,同正常客户做区分,以便针对性的改变营销策略
- 问题:和正常客户相比,无价值客户有什么特征?
- 读取数据
# 2.5.3 实战
shop2 = pd.read_excel('2 电子商务平台数据分析实战1 - 数据规整和分析思路\data_new\shop2.xlsx',None)
dingdan = shop['订单信息']
huowu = shop['货物信息']
guke = shop['顾客信息']
# 初步检查
dingdan.info()
huowu.info()
guke.info()
- 上一节过程把错误都找出来了,指标创建:不同优惠额度的订单数量
# 指标创建:不同优惠额度的订单数量
huowu.head()
- 分组
# 分组
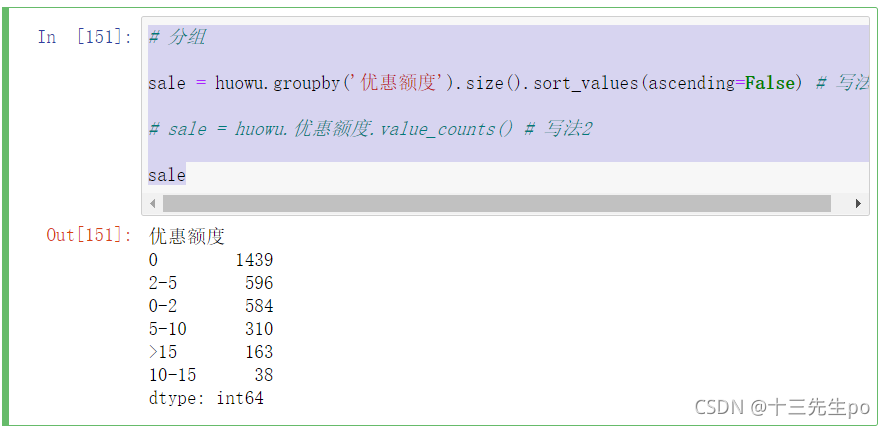
sale = huowu.groupby('优惠额度').size().sort_values(ascending=False) # 写法1
# sale = huowu.优惠额度.value_counts() # 写法2
sale
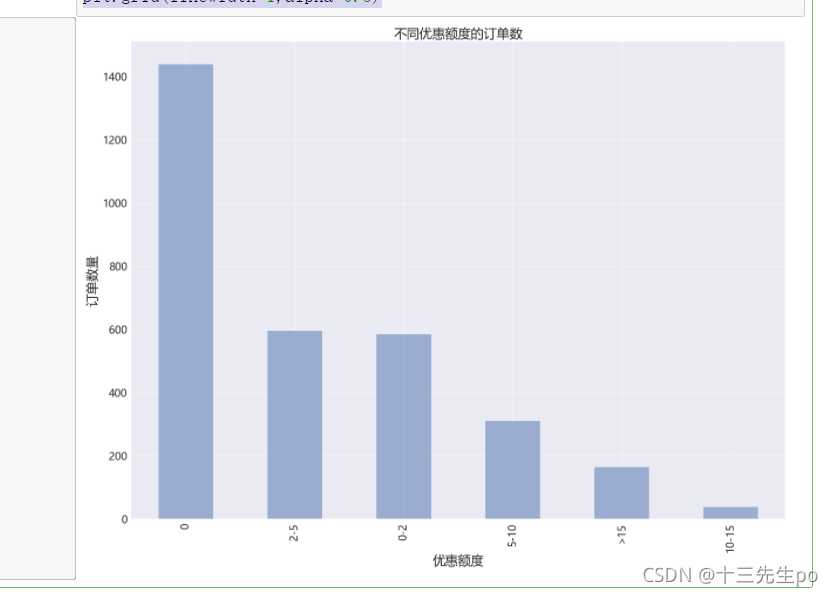
- 可视化
# 可视化
sale.plot.bar(figsize=(20,15),alpha=0.5,fontsize=18)
# 辅助显示
plt.title('不同优惠额度的订单数',fontsize=22 )
plt.xlabel('优惠额度',fontsize=22)
plt.ylabel('订单数量',fontsize=22)
plt.grid(linewidth=1,alpha=0.5)
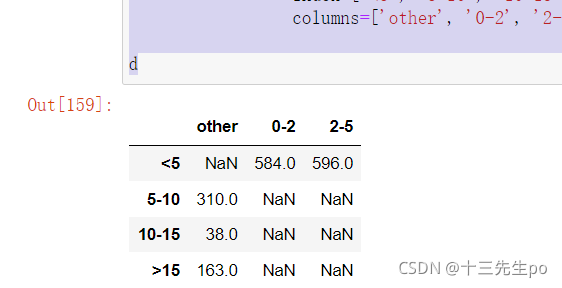
- 使用上面得出的数据重新做一份数据(分类种类比较少,直接手写输入)
- 对优惠额度再一次精简,分成4种
# 重新做一份数据
d = pd.DataFrame([[np.nan, 584, 596],
[310, np.nan, np.nan],
[38, np.nan, np.nan],
[163, np.nan, np.nan]],
index=['<5', '5-10', '10-15', '>15'],
columns=['other', '0-2', '2-5'])
d
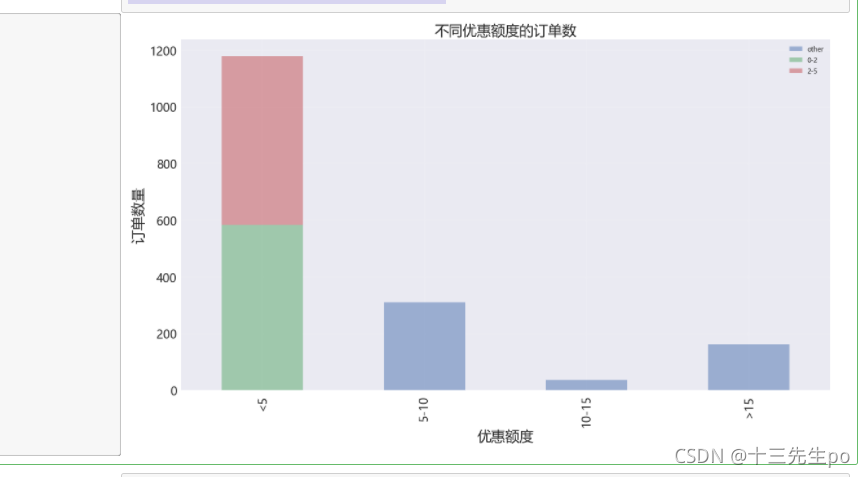
- 可视化
- bar方法的stacked将想用x值的y值数据合并
# 可视化
d.plot.bar(figsize=(18,10),alpha=0.5,fontsize=18,stacked=True)
#辅助显示
plt.title('不同优惠额度的订单数',fontsize=22 )
plt.xlabel('优惠额度',fontsize=22)
plt.ylabel('订单数量',fontsize=22)
plt.grid(linewidth=0.4,alpha=0.5)
-
结论
- 优惠额度小于5元的商品销售最多
- 优惠额度在10-15元的商品销售最小
-
分析订单商品排行
- 指标:原价商品销量前10排名
huowu.head()
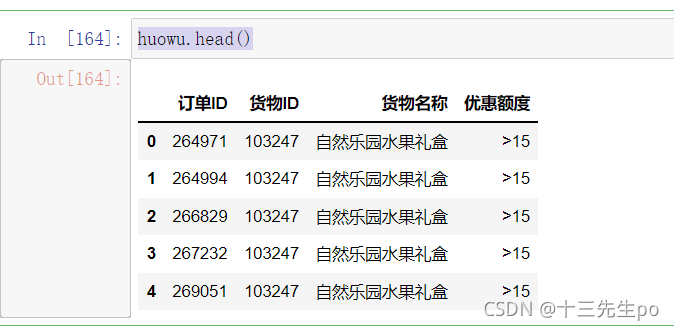
# 优惠额度为0时的商品排行
# 销量前十
huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size().sort_values(ascending=False)[:10]
# 输出的是Series值:pandas.core.series.Series
# type(huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size().sort_values(ascending=False)[:10])

- 输出的是Series值:pandas.core.series.Series,不太好看,对筛选出来的数据重新整理
# 重新整理
# reset_index()重新设置索引,可以变成好看的pd结构
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index()

- set_index(‘货物名称’) 将货物名称列设置成索引列,此时索引列名(货物名称)靠近商品名称
# 重新整理
# reset_index()重新设置索引,可以变成好看的pd结构
# set_index('货物名称') 将货物名称列设置成索引列,此时索引列名靠近商品名称
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index().set_index('货物名称')
- 重新设置列名
# 重新整理
# reset_index()重新设置索引,可以变成好看的pd结构
# set_index('货物名称') 将货物名称列设置成索引列,此时索引列名靠近商品名称
# rename(columns={0:'销量'}) 重置列名
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index().set_index('货物名称').rename(columns={0:'销量'})

- 想把索引统称(货物名称)放到和列名称一行的位置,毕竟‘货物名称’也是列名
# 重新整理
# reset_index()重新设置索引,可以变成好看的pd结构
# set_index('货物名称') 将货物名称列设置成索引列,此时索引列名靠近商品名称
# rename(columns={0:'销量'}) 重置列名
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index().set_index('货物名称').rename(columns={0:'销量'})
# 把索引统称(货物名称)放到和列名称一行的位置,毕竟‘货物名称’也是列名
# sort.index.name = '' 将索引名去掉
sort.index.name = ''

- 打印一下column的所有元素,只有销量,并没有把索引列的统称变成列名
print(sort.columns)
print(sort.columns)
print(sort.columns.name) # None,并没有设置列索引的统称

- columns.name 设置一下列的统称
# 重新整理
# reset_index()重新设置索引,可以变成好看的pd结构
# set_index('货物名称') 将货物名称列设置成索引列,此时索引列名靠近商品名称
# rename(columns={0:'销量'}) 重置列名
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index().set_index('货物名称').rename(columns={0:'销量'})
# 把索引统称(货物名称)放到和列名称一行的位置,毕竟‘货物名称’也是列名
# sort.index.name = '' 将索引名去掉
# sort.columns.name 设置一下列的统称
sort.index.name = ''
# print(sort.columns)
# print(sort.columns.name) # None,并没有设置列索引的统称
sort.columns.name = '货物名称'
sort

- 检查一下
sort.columns.name = '货物名称'
print(sort.columns)
print(sort.columns.name)
print('空格===',sort.index.name+',空格')
print(sort.index)

- 销量最差商品排名前10
# 销量最差商品排名前10
# reset_index()重新设置索引,可以变成好看的pd结构
# set_index('货物名称') 将货物名称列设置成索引列,此时索引列名靠近商品名称
# rename(columns={0:'销量'}) 重置列名
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=True)[:10].reset_index().set_index('货物名称').rename(columns={0:'销量'})
# 把索引统称(货物名称)放到和列名称一行的位置,毕竟‘货物名称’也是列名
# sort.index.name = '' 将索引名去掉
# sort.columns.name 设置一下列的统称
sort.index.name = ''
# print(sort.columns)
# print(sort.columns.name) # None,并没有设置列索引的统称
sort.columns.name = '货物名称'
sort
- 结论:销量前十有、、、销量倒数有、、、、
- 筛选打折商品 销量前十
#打折商品 销量前十
dz = huowu[huowu['优惠额度'] != '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index().set_index('货物名称').rename(columns={0:'销量'})
# 把索引统称(货物名称)放到和列名称一行的位置,毕竟‘货物名称’也是列名
# sort.index.name = '' 将索引名去掉
# sort.columns.name 设置一下列的统称
dz.index.name = ''
# print(sort.columns)
# print(sort.columns.name) # None,并没有设置列索引的统称
dz.columns.name = '货物名称'
dz
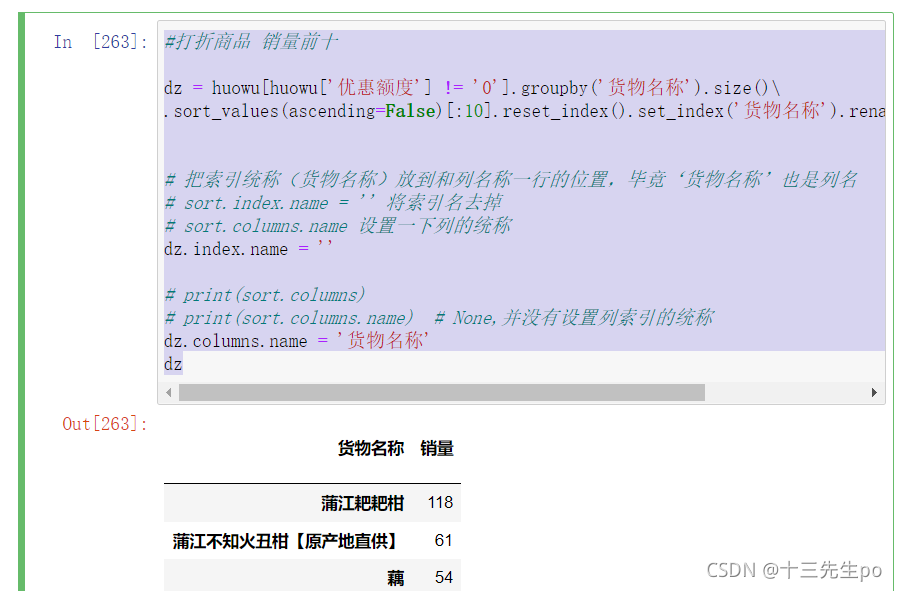
- 筛选打折商品 销量倒数前十
#打折商品 销量倒数前十
dz = huowu[huowu['优惠额度'] != '0'].groupby('货物名称').size()\
.sort_values(ascending=True)[:10].reset_index().set_index('货物名称').rename(columns={0:'销量'})
# 把索引统称(货物名称)放到和列名称一行的位置,毕竟‘货物名称’也是列名
# sort.index.name = '' 将索引名去掉
# sort.columns.name 设置一下列的统称
dz.index.name = ''
# print(sort.columns)
# print(sort.columns.name) # None,并没有设置列索引的统称
dz.columns.name = '货物名称'
dz
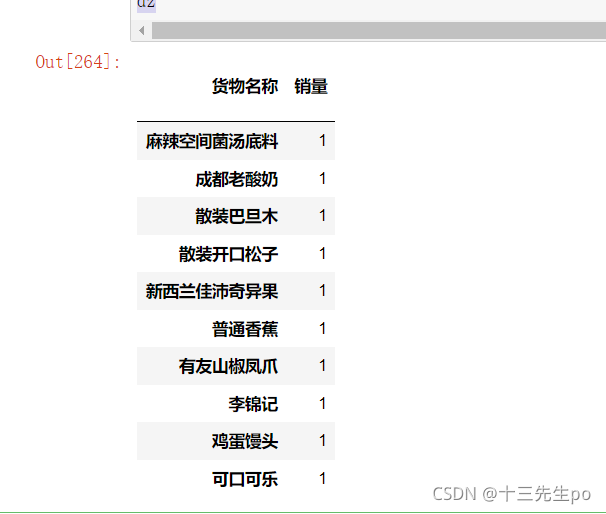
- 结论:打折商品中,销量前十有。。。,倒数前十有。。。
2.5.4 实战过程2:客户匹配
- “无价值客户”指标量化定义
- 设定指标:当客户已成交订单中,优惠商品的订单比例大于等于75%时,定义客户为无价值客户
- 分离正常客户和无价值客户
# 2.5.4 实战过程2:客户匹配
# 设定指标:当客户已成交订单中,
# 优惠商品的订单比例大于等于75%时,定义客户为无价值客户
dingdan.head()
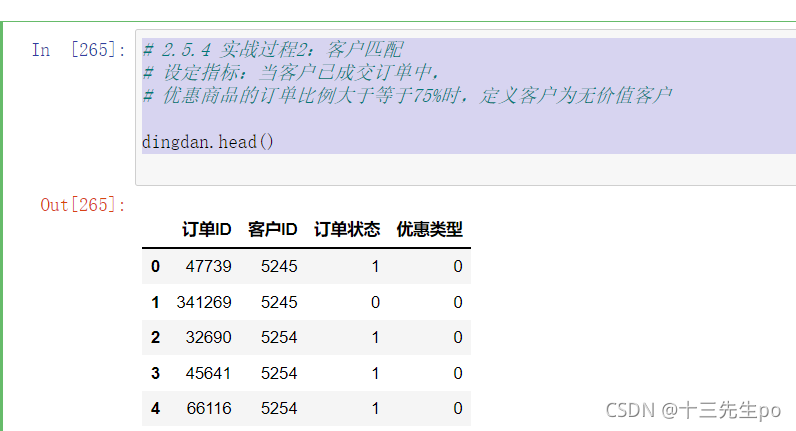
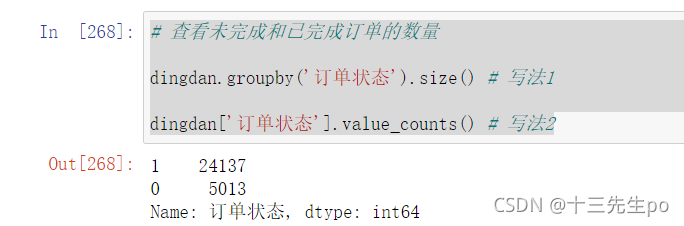
- 查看未完成和已完成订单的数量
# 查看未完成和已完成订单的数量
dingdan.groupby('订单状态').size() # 写法1
dingdan['订单状态'].value_counts() # 写法2
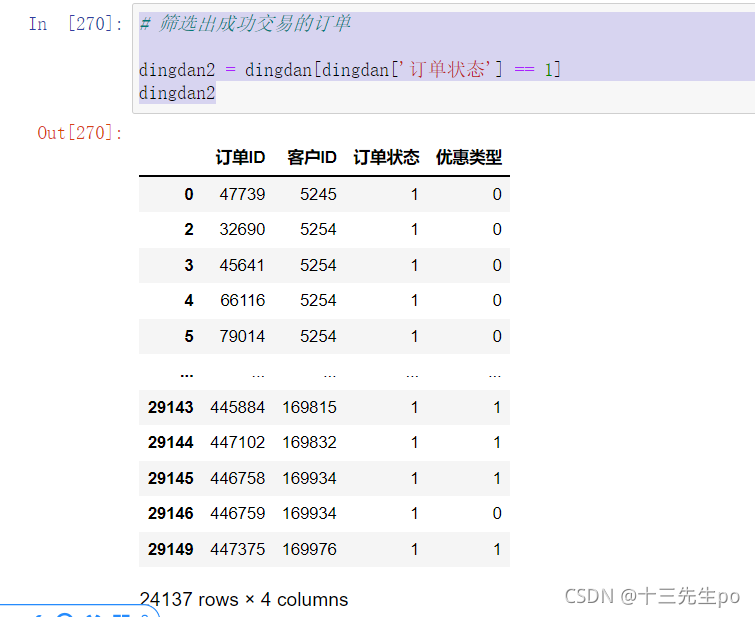
- 筛选出成功交易的订单
# 筛选出成功交易的订单
dingdan2 = dingdan[dingdan['订单状态'] == 1]
dingdan2
- 客户ID对应的正常和优惠订单的数量
- 计算数量,就和每个客户交易的频率有关,使用交叉表
- 详细解答看我主页的pandas笔记
python使用pandas模块介绍以及使用
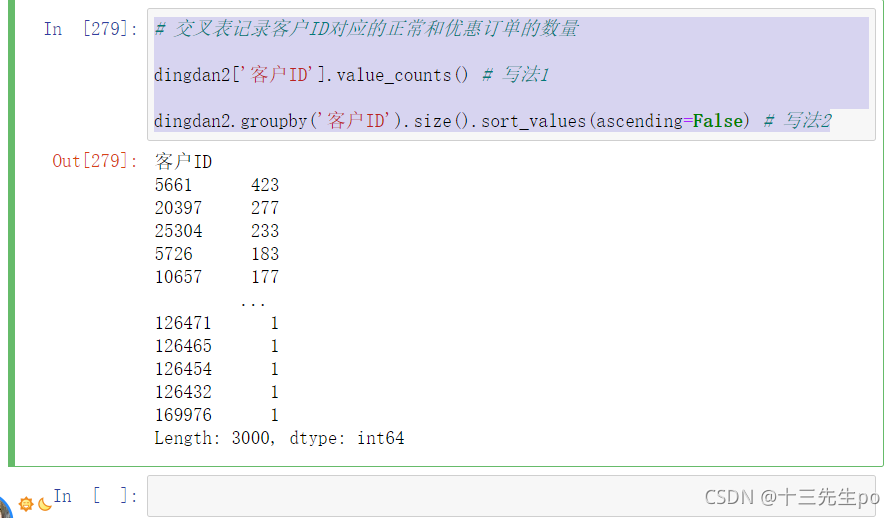
# 交叉表记录客户ID对应的正常和优惠订单的数量
dingdan2['客户ID'].value_counts() # 写法1
dingdan2.groupby('客户ID').size().sort_values(ascending=False) # 写法2
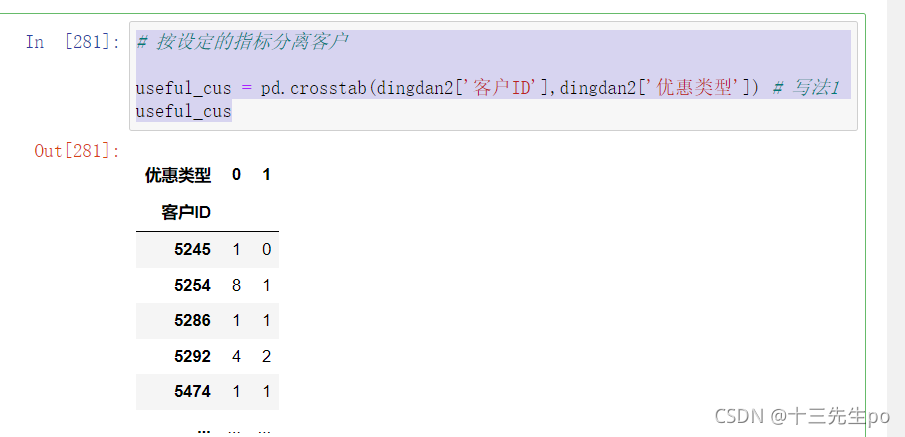
- 按设定的指标(设定指标:当客户已成交订单中,优惠商品的订单比例**大于等于75%**时,定义客户为无价值客户)分离客户
- 使用交叉表crosstab
写法1
# 按设定的指标分离客户
useful_cus = pd.crosstab(dingdan2['客户ID'],dingdan2['优惠类型']) # 写法1
useful_cus
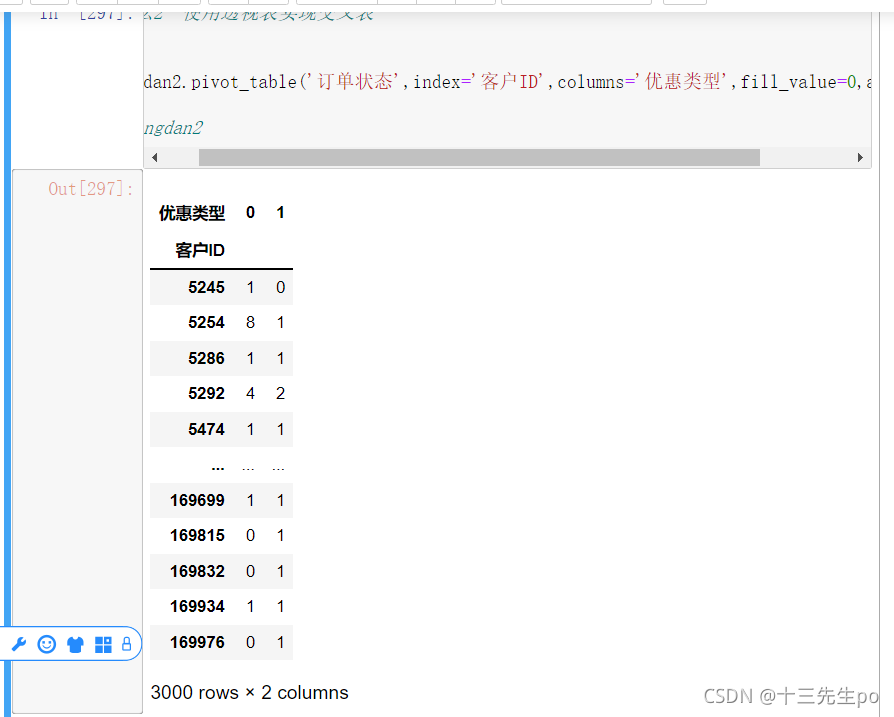
写法2:使用透视表实现交叉表,详细方法使用过程看
python使用pandas模块介绍以及使用
中的透视表方法
#写法2 使用透视表实现交叉表
dingdan2.pivot_table('订单状态',index='客户ID',columns='优惠类型',aggfunc=len)
# dingdan2
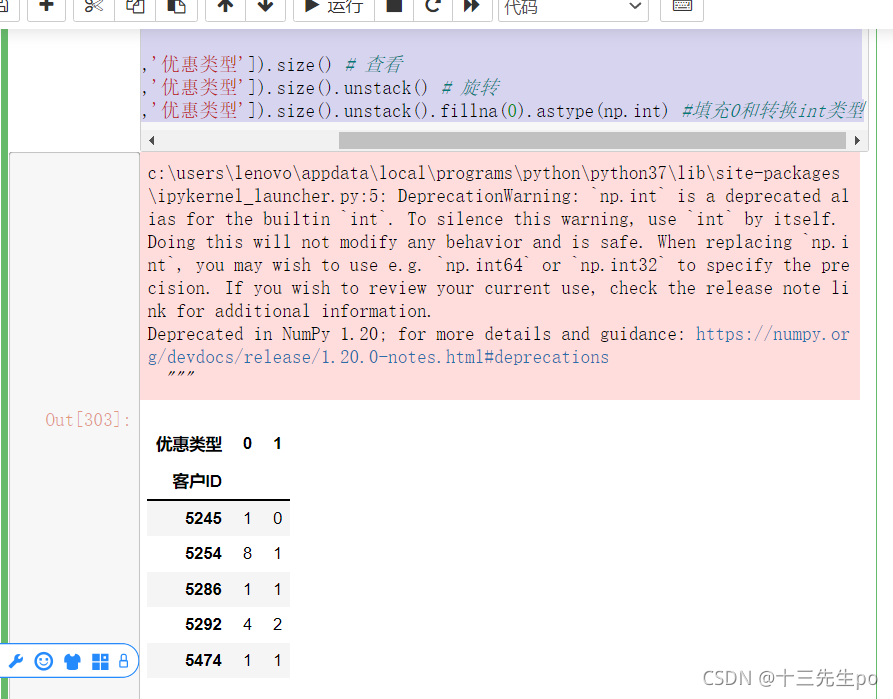
写法3:分组聚合旋转实现交叉表
# 写法3:分组聚合旋转实现交叉表
dingdan2.groupby(['客户ID','优惠类型']).size() # 查看
dingdan2.groupby(['客户ID','优惠类型']).size().unstack() # 旋转
dingdan2.groupby(['客户ID','优惠类型']).size().unstack().fillna(0).astype(np.int) #填充0和转换int类型
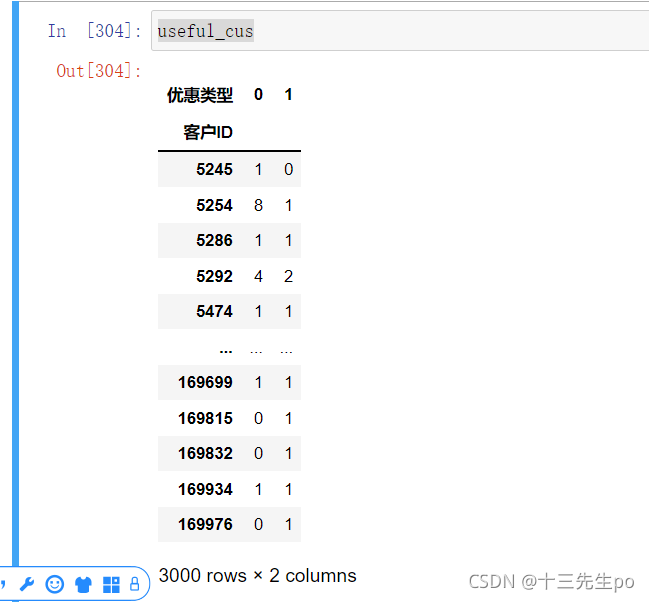
- 计算优惠订单大于等于75%的数据
- 8/(8+1) # 正常订单占所有订单的比例
- 1/(8+1) # 优惠订单占所有订单的比例
- 最终目的:获取无价值客户的客户ID
看一下现阶段获得的数据
useful_cus
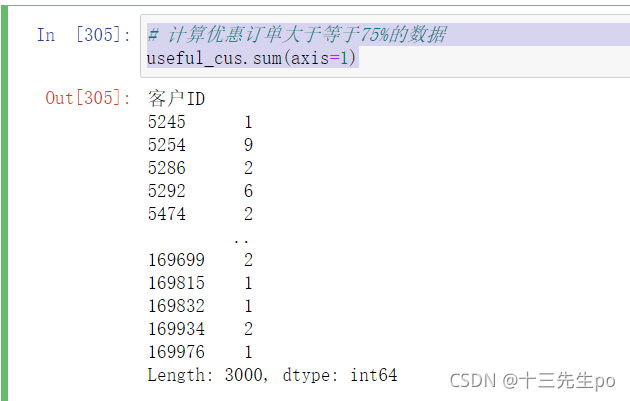
- 将两列值相加
# 计算优惠订单大于等于75%的数据
useful_cus.sum(axis=1)
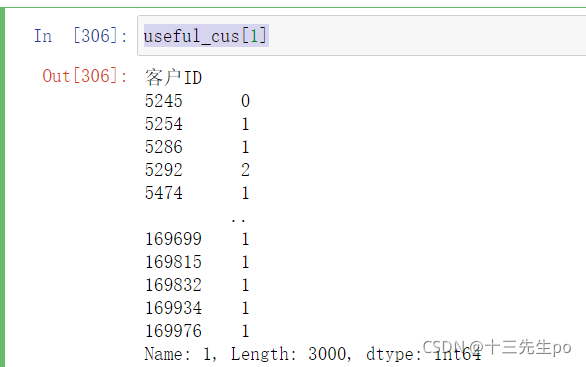
- 第一列值为使用优惠的数量,将总量和第一列相除,可以得到一个比例
useful_cus[1]
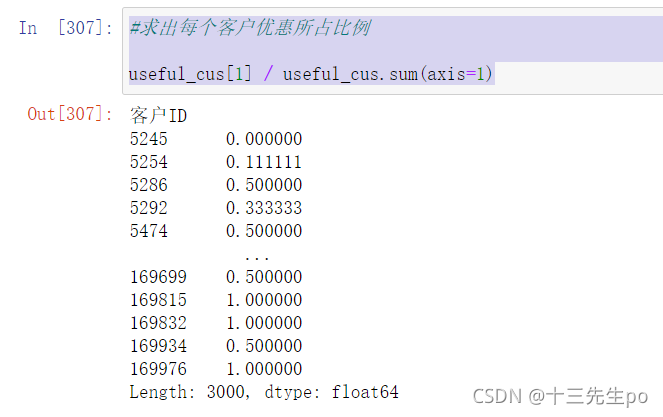
- 相除
#求出每个客户优惠所占比例
useful_cus[1] / useful_cus.sum(axis=1)
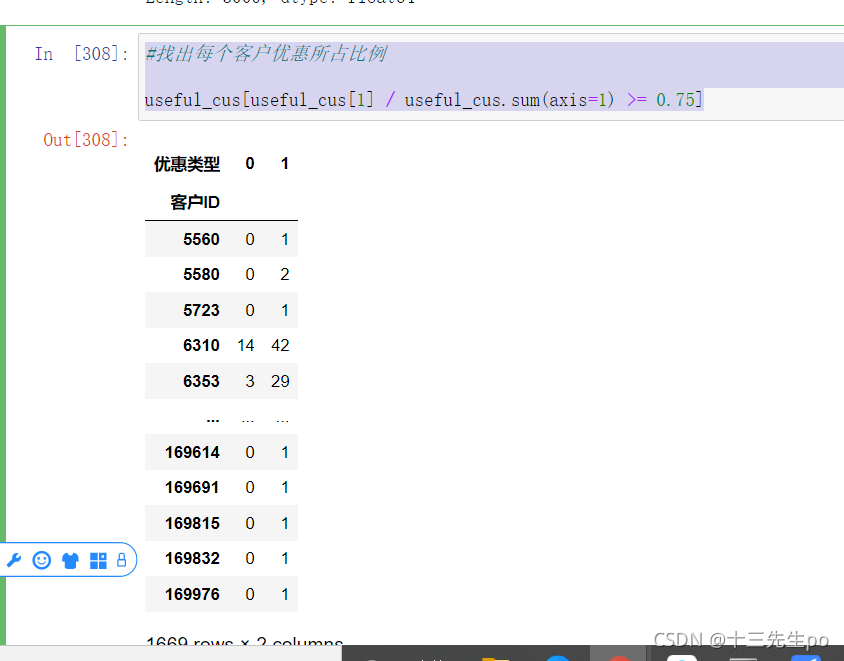
- 找出优惠比例大于0.75的顾客
#找出每个客户优惠所占比例
useful_cus[useful_cus[1] / useful_cus.sum(axis=1) >= 0.75]
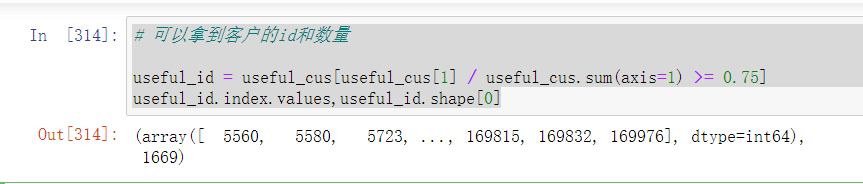
- 拿到客户的id和数量
# 可以拿到客户的id和数量
useful_id = useful_cus[useful_cus[1] / useful_cus.sum(axis=1) >= 0.75]
useful_id.index.values,useful_id.shape[0]
- 分离 正常客户 和 无价值客户
# 分离 正常客户 和 无价值客户
# 新增一列
useful_cus['客户类别'] = 1
useful_cus.head()
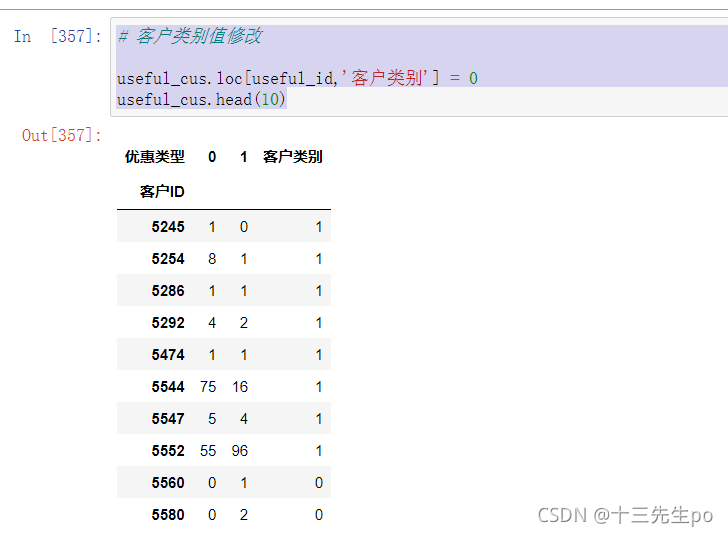
- 使用刚刚得到的id数据,再使用loc检索到对应id,将客户类别值修改
# 客户类别值修改
useful_cus.loc[useful_id,'客户类别'] = 0
useful_cus.head(10)
- 将筛选出来的顾客列表插入 顾客信息 表中
目前数据的情况
# 将筛选出来的顾客列表插入 顾客信息 表中
useful_cus.head(10)
顾客表的数据情况
guke.head()
-
对数据合并也要找到对应的行并把值添加进去,而此时的guke表只有默认行索引,没有行索引的话就不能找到对应的值进行添加

-
置行索引并将该修改的过的数据传给新的实参guke2
# 置行索引
guke2 = guke.set_index('客户ID')
guke2.head()
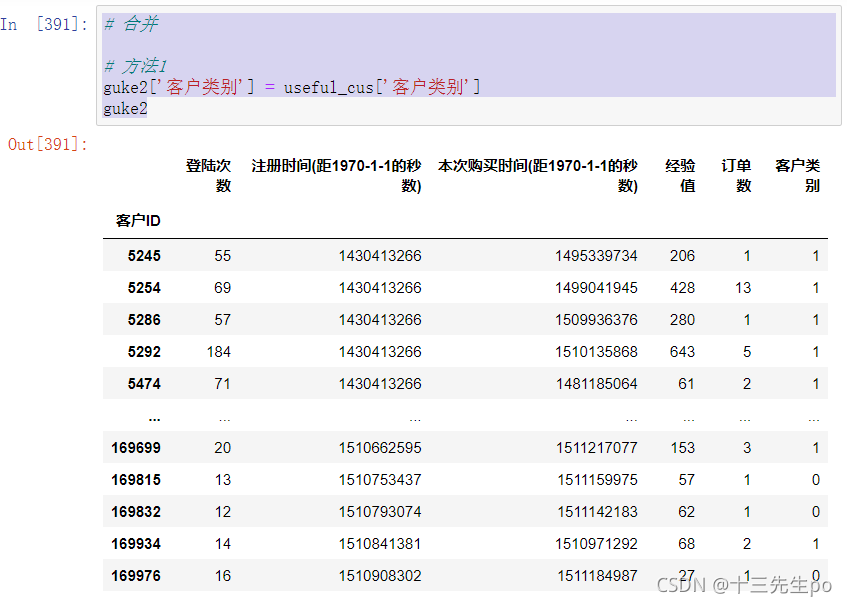
- 合并
方法1 直接相等
# 合并
# 方法1
guke2['客户类别'] = useful_cus['客户类别']
guke2
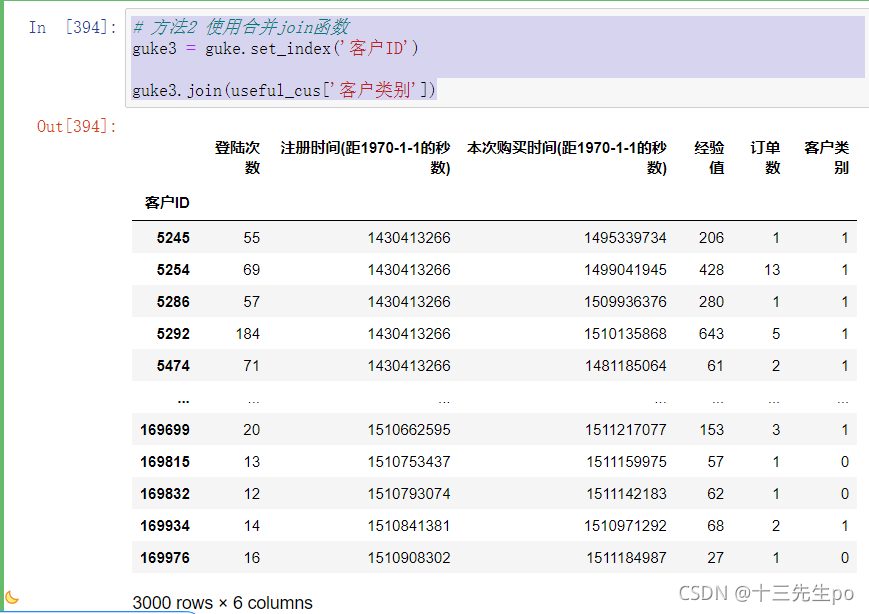
方法2 使用合并join函数
# 方法2 使用合并join函数
guke3 = guke.set_index('客户ID')
guke3.join(useful_cus['客户类别'])
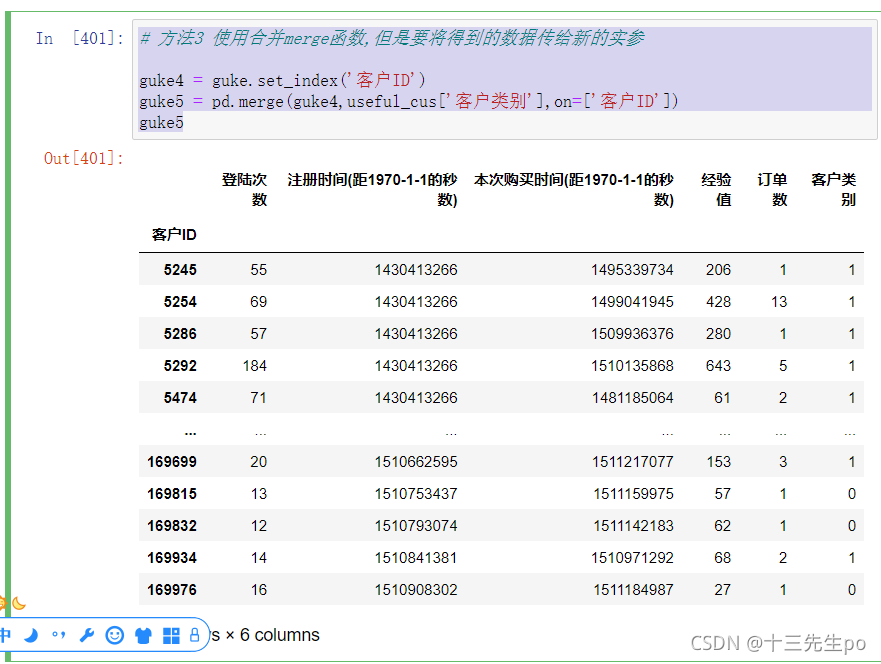
方法3 使用合并merge函数,但是要将得到的数据传给新的实参
# 方法3 使用合并merge函数,但是要将得到的数据传给新的实参
guke4 = guke.set_index('客户ID')
guke5 = pd.merge(guke4,useful_cus['客户类别'],on=['客户ID'])
guke5
- 看看目前表的情况
guke2

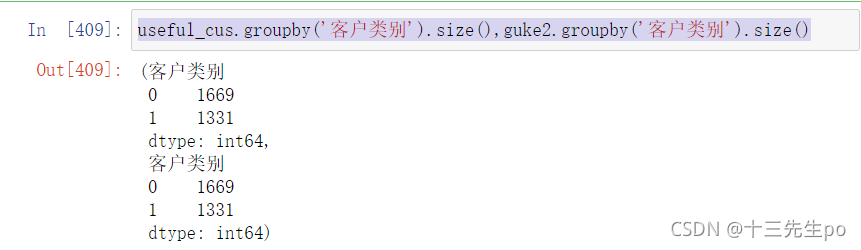
- 检查新列是否正常
# 检查新列是否正常
useful_cus.shape,guke2.shape

useful_cus.groupby('客户类别').size(),guke2.groupby('客户类别').size()
相等,没有问题
- 查看guke2表的数据类型
guke2.info()
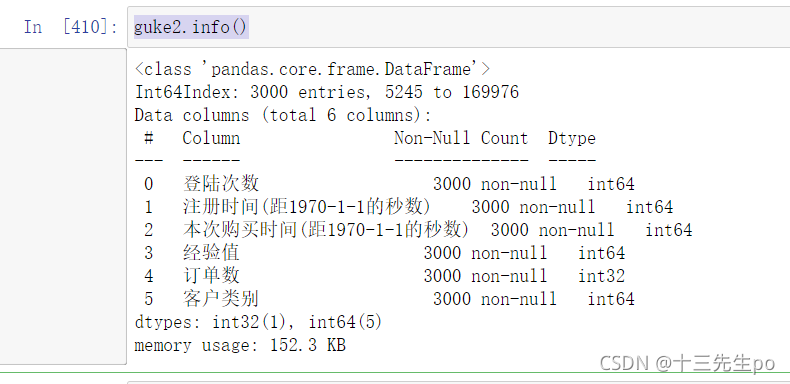
2.5.5 实战过程3:客户特征分析
- 分析正常客户和无价值客户的特征和行为差异
- 举例:正常客户的平均登陆次数多少,无价值客户的平均登陆次数多少。。。。
- 目前数据情况
# 客户特征分析(用户画像)
guke2.head(10)
- 正常客户和无价值客户比例
- 聚合客户列表,对0和1重新赋值改名为无价值客户和正常客户
# 正常客户和无价值客户比例
# 聚合客户列表,对0和1重新赋值改名为无价值客户和正常客户
useful_cus.groupby('客户类别').size() # 聚合
pic = useful_cus.groupby('客户类别').size().rename({0:'无价值客户',1:'正常客户'}) # 重命名
pic
- 数据可视化
# 可视化
pic.plot.pie(figsize=(8,8),labels=pic.index,explode=(0,0.03),startangle=90,autopct='%1.1f%%')
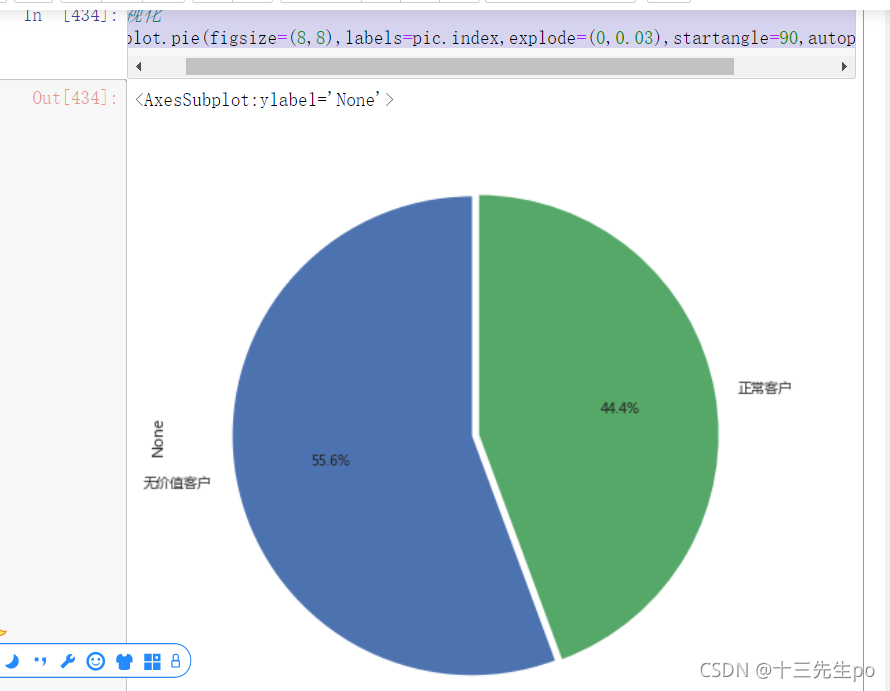
结论:无价值客户的数量略大于正常客户
2.5.6 实战过程4:比较各列数据在不同客户类别下的差异
- 客户类别分类聚合,重新命名0和1
# 2.5.6 实战过程4:比较各列数据在不同客户类别下的差异
# 客户类别分类聚合,重新命名0和1
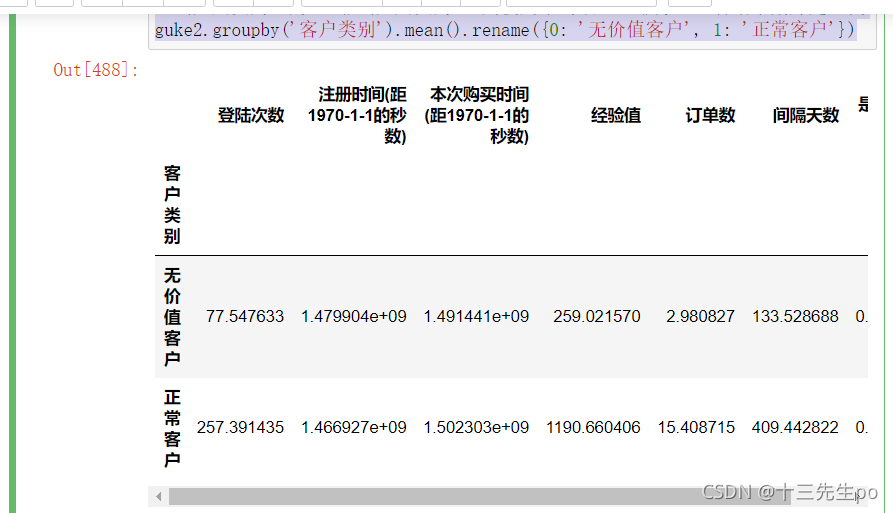
guke_mean = guke2.groupby('客户类别').mean().rename({0:'无价值客户',1:'正常客户'})
guke_mean
- 平均登陆次数差异
# 平均登陆次数差异
guke_mean['登陆次数']
guke_mean['登陆次数'].plot.bar()
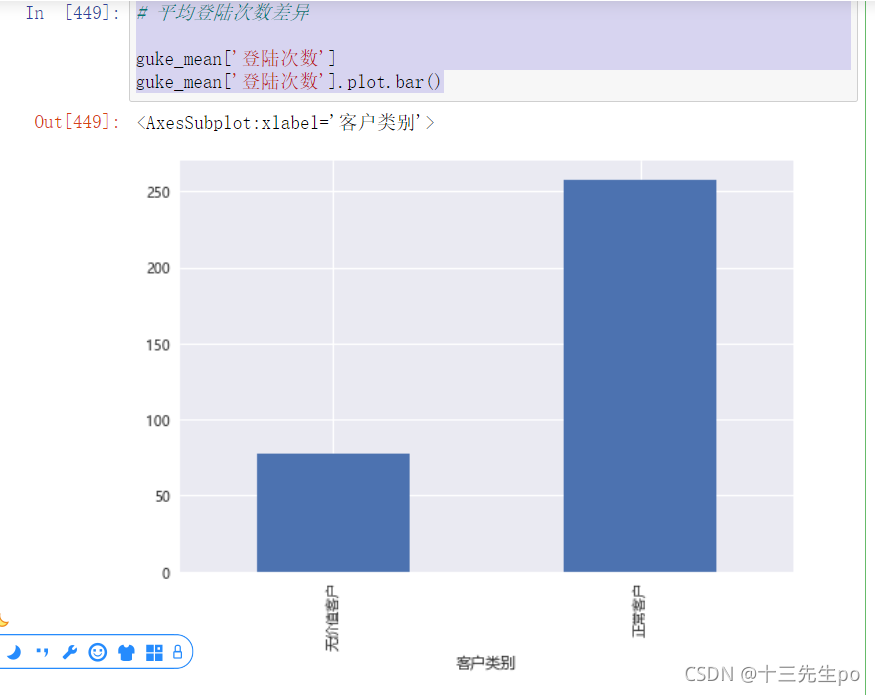
结论:正常客户的平均登陆次数远大于无价值客户
- 客户会员经验平均值差异
# 客户会员经验平均值差异
guke_mean['经验值']
guke_mean['经验值'].plot.bar()
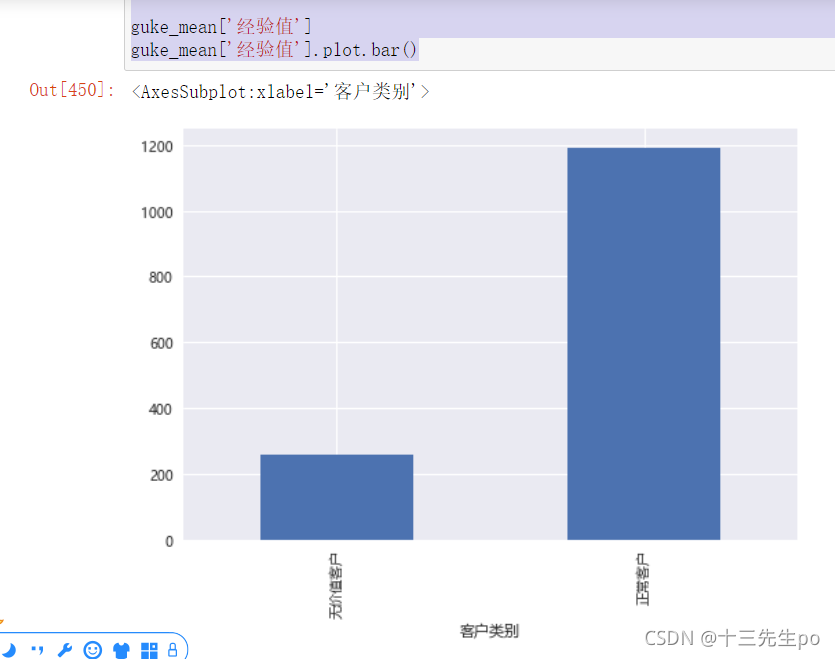
结论:正常客户的客户会员经验平均值远大于无价值客户
- 客户平均订单数差异
# 客户平均订单数差异
guke_mean.订单数.plot.bar()
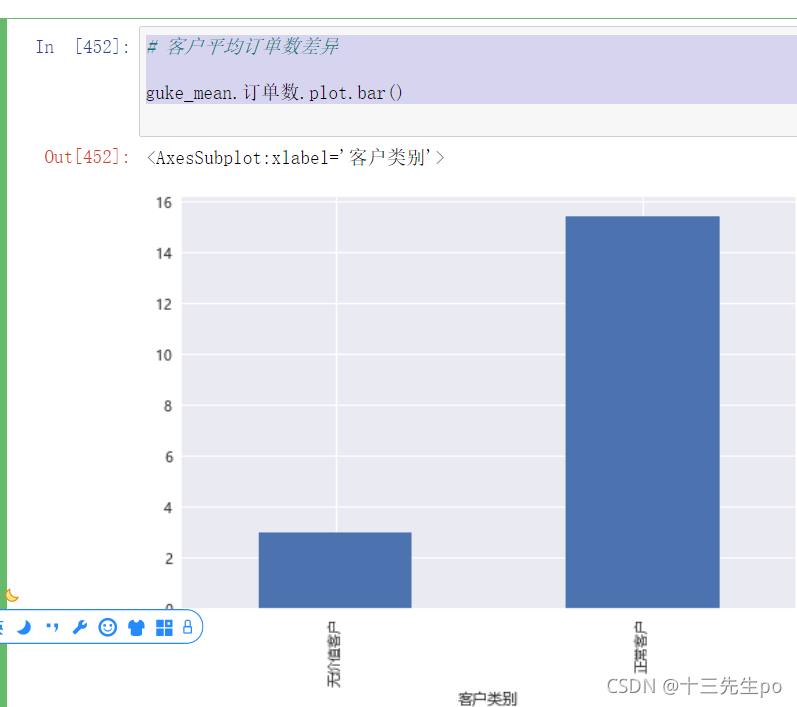
结论:正常客户订单数远大于无价值客户
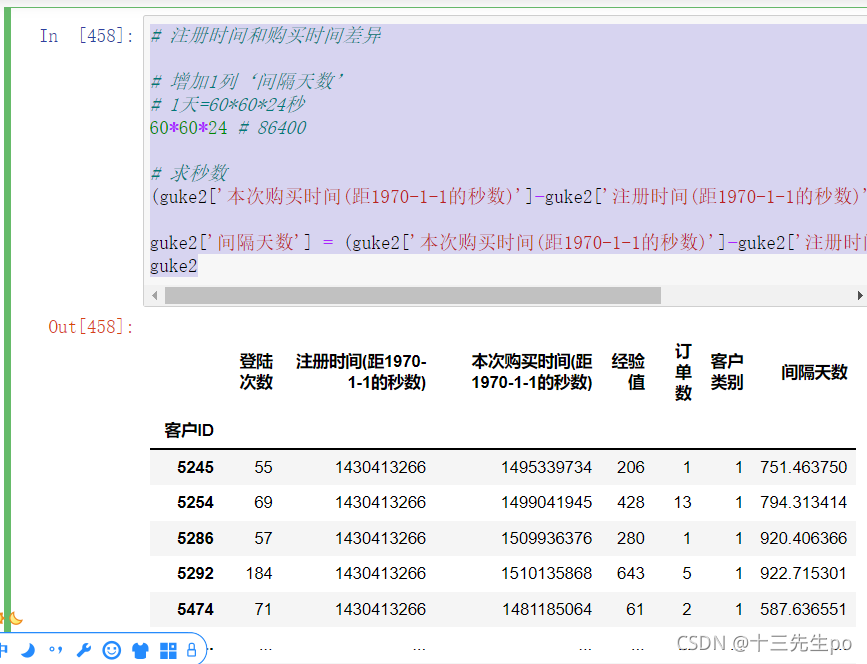
- 注册时间和购买时间差异
# 注册时间和购买时间差异
# 增加1列‘间隔天数’
# 1天=60*60*24秒
60*60*24 # 86400
# 求秒数
(guke2['本次购买时间(距1970-1-1的秒数)']-guke2['注册时间(距1970-1-1的秒数)'])/86400
guke2['间隔天数'] = (guke2['本次购买时间(距1970-1-1的秒数)']-guke2['注册时间(距1970-1-1的秒数)'])/86400
guke2
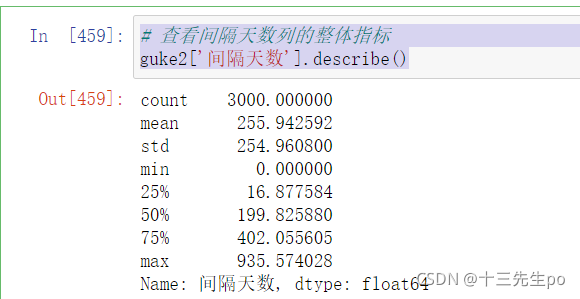
- 查看间隔天数列的整体指标
# 查看间隔天数列的整体指标
guke2['间隔天数'].describe()
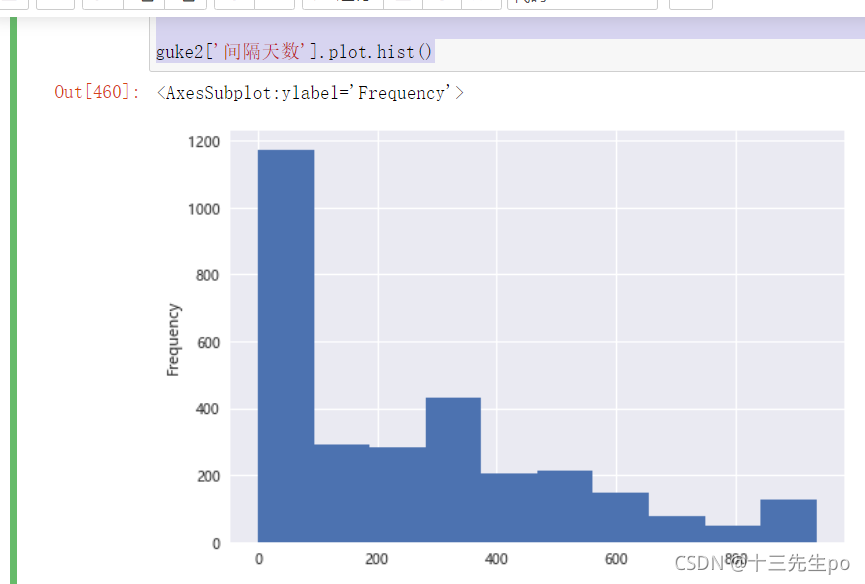
- 间隔天数列的整体指标可视化
# 间隔天数列的整体指标可视化
guke2['间隔天数'].plot.hist()
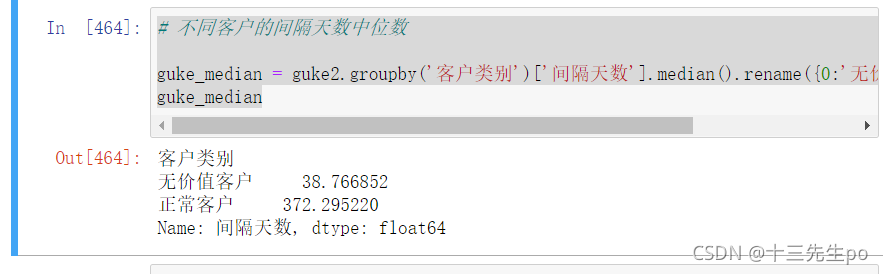
- 不同客户的间隔天数中位数
# 不同客户的间隔天数中位数
guke_median = guke2.groupby('客户类别')['间隔天数'].median().rename({0:'无价值客户',1:'正常客户'})
guke_median
可视化
guke_median.plot.bar()
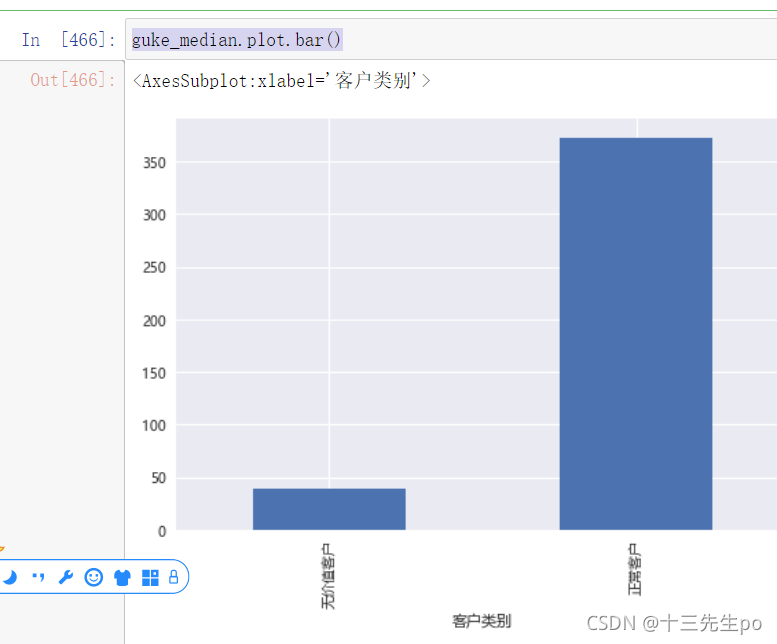
结论:无价值客户购买和注册时间间隔显著小于正常客户
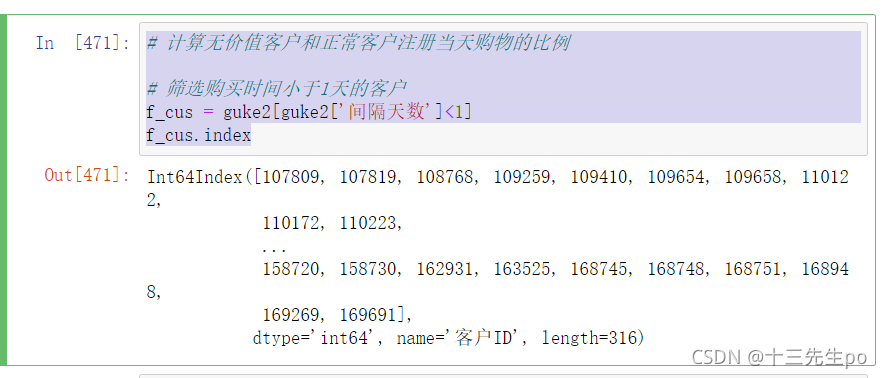
- 计算无价值客户和正常客户注册当天购物的比例
# 计算无价值客户和正常客户注册当天购物的比例
# 筛选购买时间小于1天的客户
f_cus = guke2[guke2['间隔天数']<1]
f_cus.index
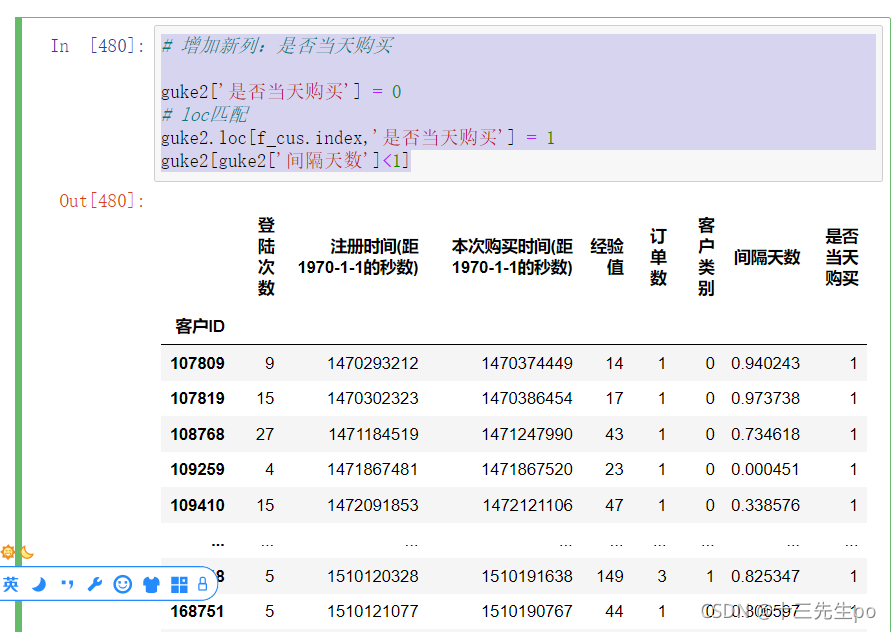
- 增加新列:是否当天购买;将筛选出来的人匹配进新列
# 增加新列:是否当天购买
guke2['是否当天购买'] = 0
# loc匹配
guke2.loc[f_cus.index,'是否当天购买'] = 1
guke2[guke2['间隔天数']<1]
匹配成功
可视化
# 可视化
guke2.groupby('是否当天购买').size().plot.bar()
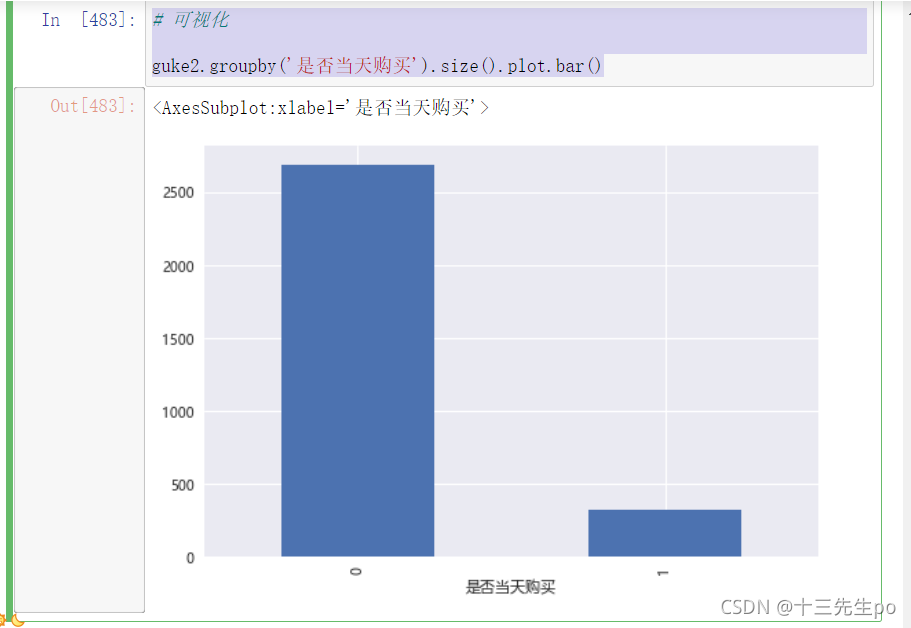
结论:注册后当天就购物的比例,很大概率是无价值客户,而经常买东西的客户很大概率是正常客户
- 正常客户或无价值客户注册以后当天购物的比例
写法1:按客户类别分组聚合,抓住关键字是找出不用类别客户在当天是否有购物,当天购买为记为1,非当天购买为0,则使用平均数mean()方法查看结果刚好是比例
# 正常客户或无价值客户注册以后当天购物的比例
# 写法1
# 按客户类别分组聚合,抓住关键字是找出不用类别客户在当天是否有购物
# 当天购买为记为1,非当天购买为0,则使用平均数mean()方法查看结果刚好是比例
first_day_shopping = guke2.groupby('客户类别').是否当天购买.mean().rename({0: '无价值客户', 1: '正常客户'})
first_day_shopping*100
写法2:value_counts()分类聚合,逐一筛选手动计算
# 正常客户或无价值客户注册以后当天购物的比例
# 写法2
# value_counts()分类聚合
guke2.客户类别.value_counts().rename({0:'无价值客户',1:'正常客户'})
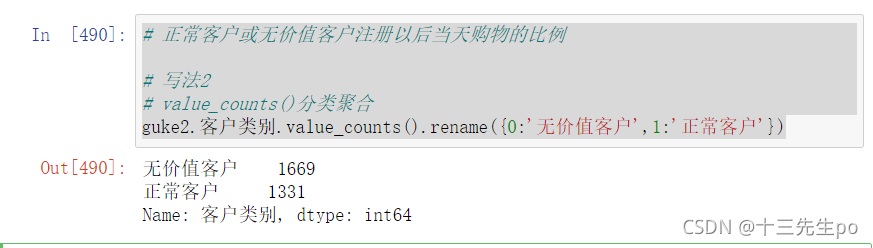
# 无价值客户当天购买的
guke2[(guke2.客户类别 == 0) & (guke2.是否当天购买 == 1)].shape # 306
# 正常客户当天购买的
guke2[(guke2.客户类别 == 1) & (guke2.是否当天购买 == 1)].shape # 10
306/1669,10/1331 # 结果一样
计算结果一样
可视化
first_day_shopping.plot.bar()
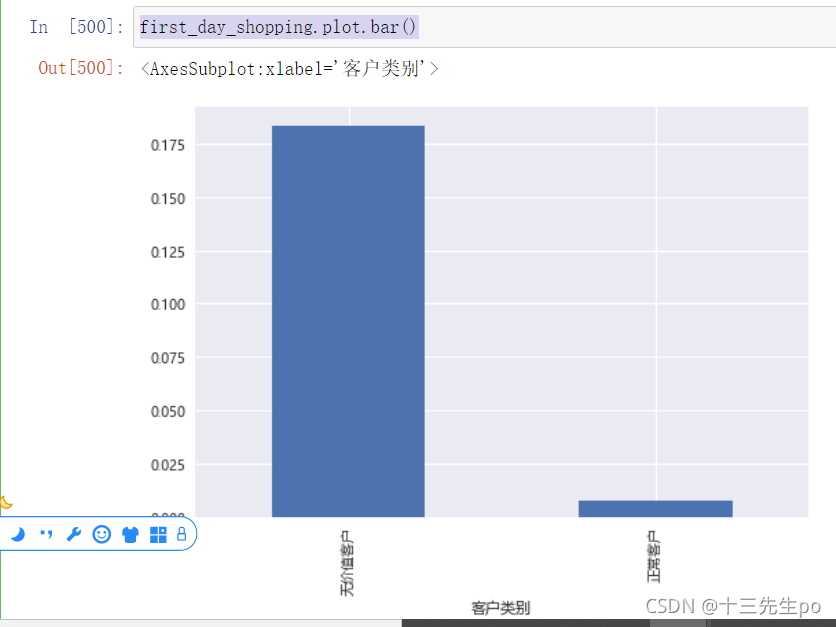
- 结论:
无价值客户注册当天购物的比例为18.3%
正常客户注册当天购物的比例为0.75%
- 保存最终版顾客信息表
# 保存最终版顾客信息表
guke2.to_csv('2 电子商务平台数据分析实战1 - 数据规整和分析思路/data_new/20211019guke_new.csv')
2.5.7 实战过程5:客户信息进阶分析,略
如果要进一步分析顾客信息,可以将 登陆次数/经验值/订单数/间隔天数 连续值列离散化,然后和所有离散值列/连续值列进行 单列/2列/3列 相互组合做透视表和交叉表分析
如
- 不同登陆次数区间的客户人数(丐版交叉表)
- 不同订单数区间/不同客户类别的人数(交叉表)
- 不同登陆次数区间/不同订单数区间的平均经验值(透视表)
等等。。。
此处略,建议自行尝试迭代本分析报告
2.6 探索性分析 建模
- 数据分析报告什么情况下使用建模预测
- 侧重预测未来(未知)
- 侧重加深了解已知
- 正常和无价值客户区分主要受哪些因素影响?
哪些因素(特征)影响了客户类别区分?影响的方向(正面负面)和程度如何?
- 登陆次数?
- 经验值?
- 注册时间?
- 间隔天数?
- 。。。
使用线性回归/逻辑回归预测特征对标签的影响程度
-
离散值:值和值之间没有其他值
-
连续值:值和值之间有无数其他值
- 分类(逻辑回归)
预测结果(标签)是离散值
预测降雨量:小雨,中雨,大雨,暴雨 - 回归(线性回归)
标签是连续值
预测降雨量:10mm,20mm, 30mm…
- 分类(逻辑回归)
线性回归算法原理
- 各种特征对最终标签的影响程度,一种非常重要的指标,可以由提高特征来提高标签效果
- 通晓业务的老司机,一般对各个特征对目标的影响会做定性分析,知道谁重要谁不重要,但无法进行定量分析,重要程度是多少?
- 多变量线性回归可以对各个特征对最终目标的影响做定量分析(重要程度)
世界上数据分析师用的最多的建模算法:
- 逻辑回归(线性回归)
- 原因:
简单:y = a1x1 + a2x2 + … + az*xz + b
结果具有可解释性
实战
- 载入数据
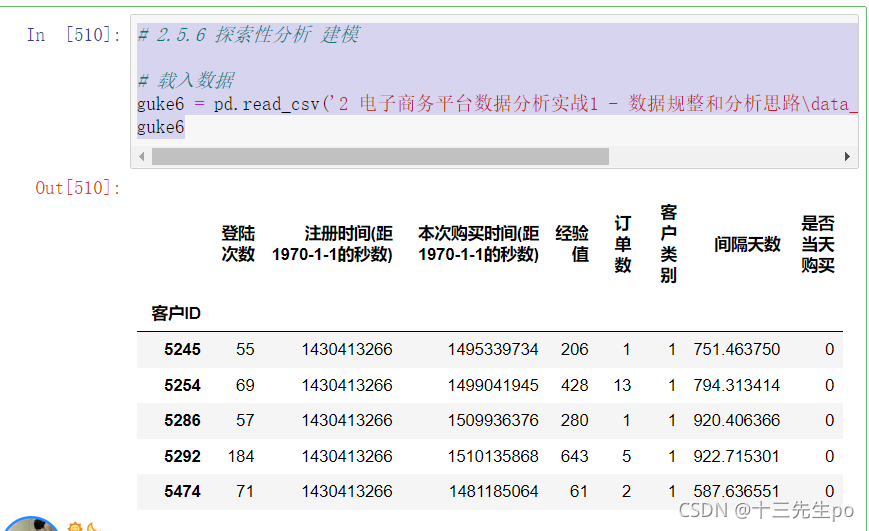
# 2.5.6 探索性分析 建模
# 载入数据
guke6 = pd.read_csv('2 电子商务平台数据分析实战1 - 数据规整和分析思路\data_new\guke_new.csv',index_col='客户ID')
guke6
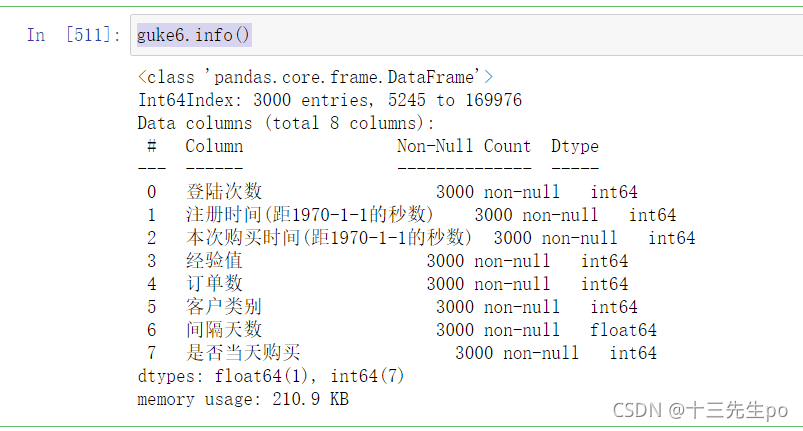
- 检查数据类型
guke6.info()
- 机器学习算法建模:特征和标签
建立标签
# 机器学习算法建模:特征和标签
# 建立标签并使用values属性获得数据
y = guke6.客户类别.values
y

特征是除客户以外的购买间隔天数、订单数等等列
# 特征是除客户以外的购买间隔天数、订单数等等列
# 删除注册时间和购买时间(没什么用),还会对后面的数据造成影响
# 删除客户列表,因为是标签
# 查看values提取数值
X = guke6.drop(['注册时间(距1970-1-1的秒数)','本次购买时间(距1970-1-1的秒数)','客户类别'],axis=1).values
X

目前的数据情况
y.shape,X.shape
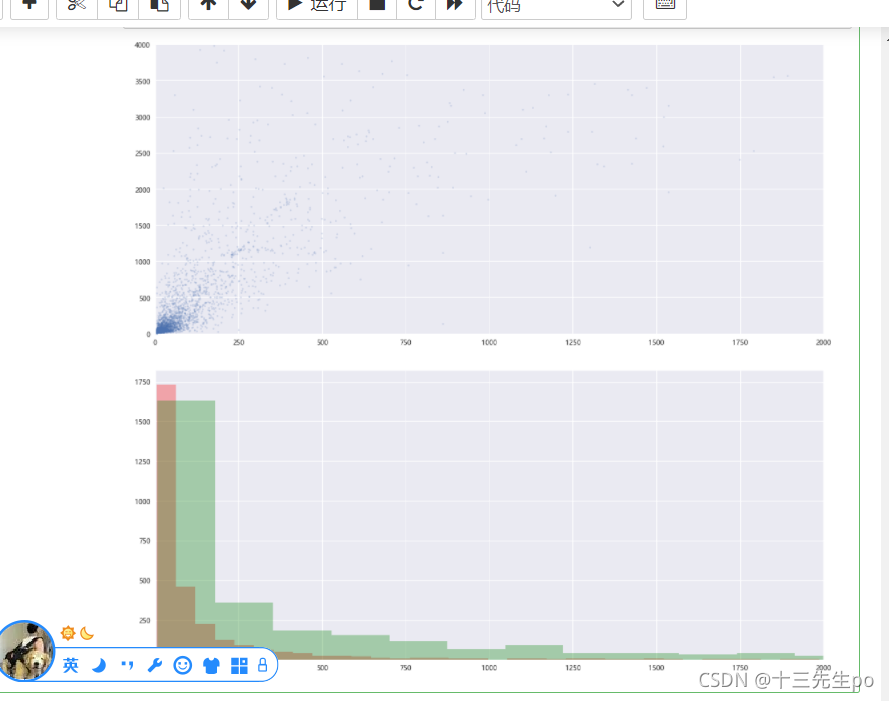
- 原始特征数据分布情况
# 原始特征数据分布情况
# 散点图
# X[0]是登陆次数,X[1]是经验值
plt.figure(figsize=(18,8))
plt.scatter(X[:,0],X[:,1],s=5,alpha=0.2)
plt.xlim(0,2000)
plt.ylim(0,4000)
plt.show()
# 直方图
plt.figure(figsize=(18,8))
plt.hist(X[:,0],bins=200,color='r',alpha=0.3)
plt.hist(X[:,1],bins=200,color='g',alpha=0.3)
plt.xlim(0,2000)
plt.show()
- 数据正规化,将特征量纲统一到统一范围
详细用法preprocessing模块的sklearn.preprocessing.scale()方法
# 数据正规化,将特征量纲统一到统一范围
from sklearn import preprocessing
X = preprocessing.scale(X)
X

重新画散点图和直方图
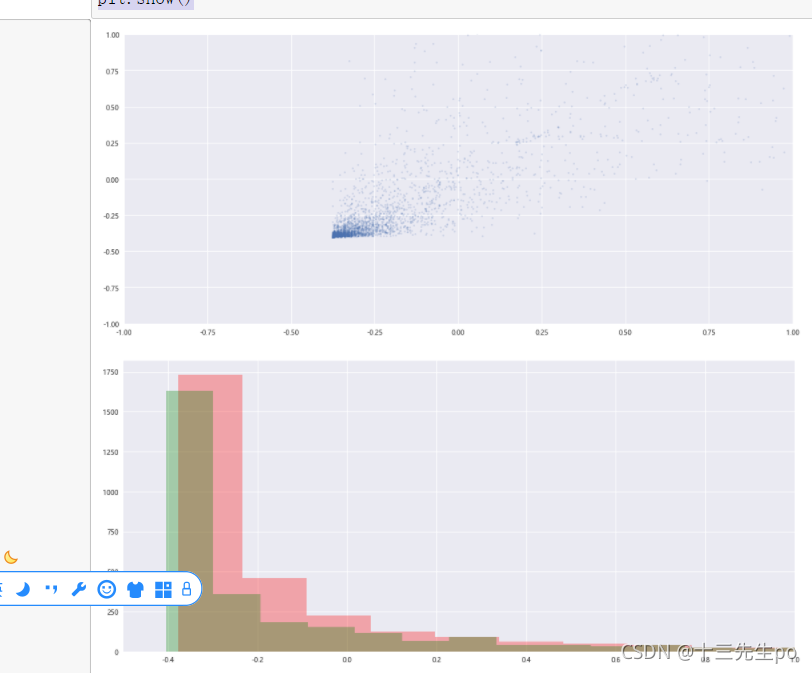
# 重新画散点图和直方图
# 散点图
# X[0]是登陆次数,X[1]是经验值
plt.figure(figsize=(18,8))
plt.scatter(X[:,0],X[:,1],s=5,alpha=0.2)
plt.xlim(-1,1)
plt.ylim(-1,1)
plt.show()
# 直方图
plt.figure(figsize=(18,8))
plt.hist(X[:,0],bins=200,color='r',alpha=0.3)
plt.hist(X[:,1],bins=200,color='g',alpha=0.3)
plt.xlim(-0.5,1)
plt.show()
- 机器学习算法建模
- 线性回归:连续数据建模
- 逻辑回归:离散数据建模
逻辑回归
# 机器学习算法建模——逻辑回归
from sklearn.linear_model import LogisticRegression as LR # 逻辑回归
# 创建空模型
clf = LR()
# 训练,因为不需要预测,需要权重,所以使用全数据
clf.fit(X,y)
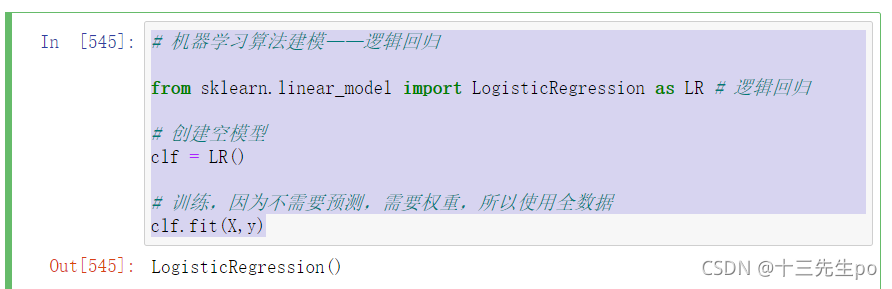
查看模型拟合程度(准确率)
# 查看模型拟合程度(准确率)
clf.score(X,y)
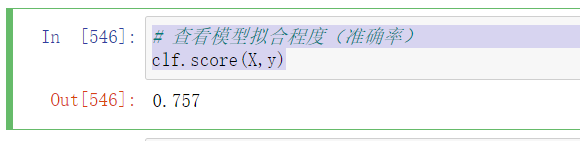
- 查看各特征相对标签影响大小(权重,斜率),和模型误差(截距)
y = a1x1 + a2x2 + … + az*xz + b
# 查看各特征相对标签影响大小(权重,斜率),和模型误差(截距)
# y = a1x1 + a2x2 + ... + az*xz + b
# 模型误差
clf.intercept_ # 截距
特征影响
# 特征影响
clf.coef_ #斜率
# 正负代表特征和结果是正相关还是负相关
# 绝对值大小代表相关程度,特征对结果的影响程度

将特征名称和特征系数组合为Series数据
# 之前模型用的特征列
guke2.drop(['注册时间(距1970-1-1的秒数)',\
'本次购买时间(距1970-1-1的秒数)', '客户类别'], axis=1).head()
# 特征影响的值
clf.coef_[0]
# 将特征名称和特征系数组合为Series数据
impact = pd.Series(clf.coef_[0],index=['登陆次数','经验值','订单数','间隔天数','是否当天购买'])
impact
- 按特征对标签的影响力排名
# 按特征对标签的影响力排名
sort = impact.sort_values(ascending=False)
sort

可视化
sort.plot.bar()
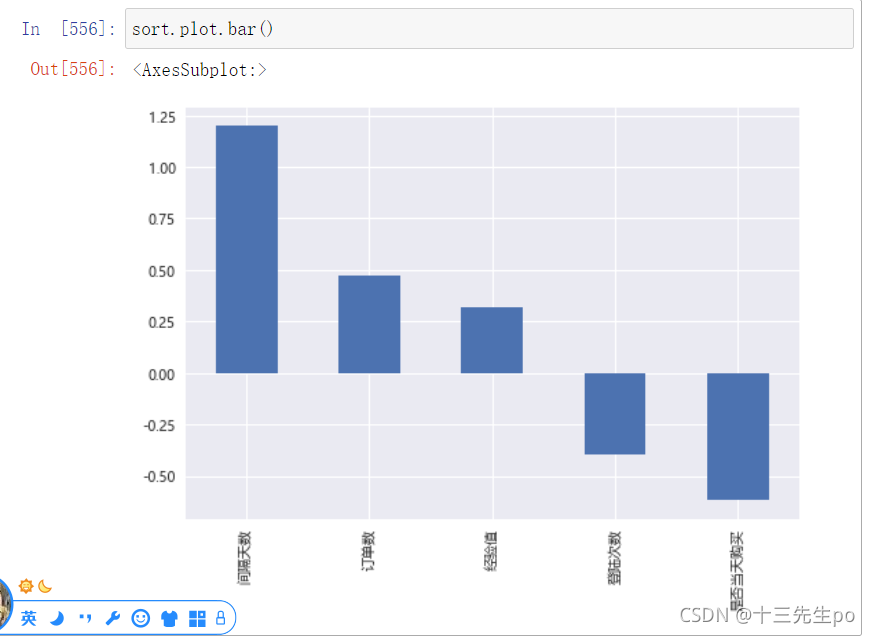
- 结论
通过查看特征对标签的正负相关情况:- 间隔天数,订单数,经验值对结果正相关
- 登陆次数,是否当天购买都结果负相关
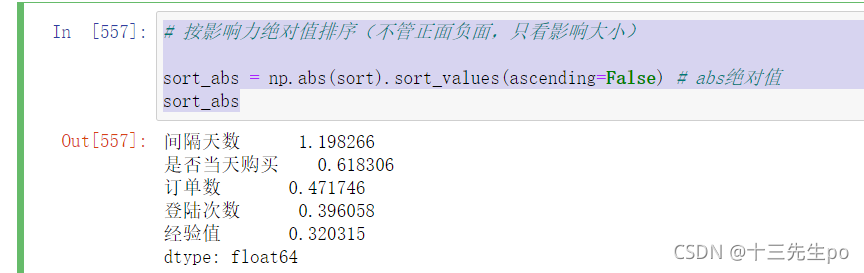
- 按影响力绝对值排序(不管正面负面,只看影响大小)
# 按影响力绝对值排序(不管正面负面,只看影响大小)
sort_abs = np.abs(sort).sort_values(ascending=False) # abs绝对值
sort_abs
可视化
sort_abs.plot.bar()
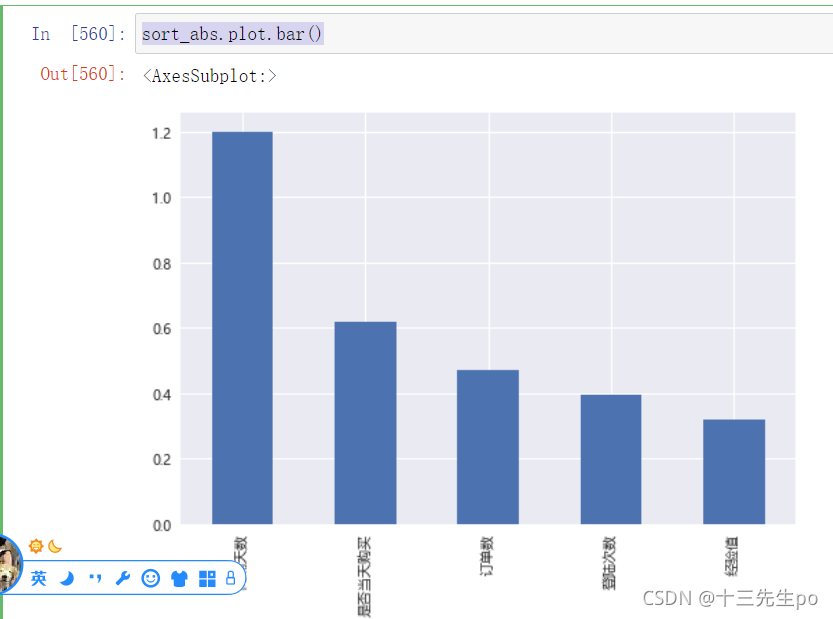
- 结论
- 间隔天数对客户分类的影响最大,权重达到1.2
- 是否当天购买排名第二,对结果的影响是间隔天数的一半
- 订单数在影响程度排名里只排第三,只有间隔天数的1/3,值得思考
- 经验值是所有特征里,对结果影响最小的特征,0.3, 相当于间隔天数的1/4
- 意见建议
-
间隔天数和是否当天购买,对最终结果的影响最大,为了增加正常客户比例,可以进行一些对应的客户营销措施
-
其他特征是客户自动生成的,无法改变,只有经验值是网站根据公式自行计算的,而这里计算的经验值完全无法分类正常客户和无价值客户,所有经验值作为一个重要指标,实际上无效
-
建议更新经验值计算公式,按照我们的特征重要性排名和权重重新设计经验值公式,以使其更贴合实际用户情况,做到看经验值就能区分两类客户建议更新经验值计算公式,按照我们的特征重要性排名和权重重新设计经验值公式,以使其更贴合实际用户情况,做到看经验值就能区分两类客户
-
结论加深:模型解读
对用户是正常用户还是无价值用户,特征影响情况:
正面影响特征
间隔天数 1.198293
订单数 0.472228
经验值 0.320515
负面影响特征
是否当天购买 -0.617567
登陆次数 -0.396311 #登陆越少,越有价值??
间隔天数越大,订单数越多,经验值越大,(注册当天不购买,登录次数越少)越有可能是正常用户,反之亦然
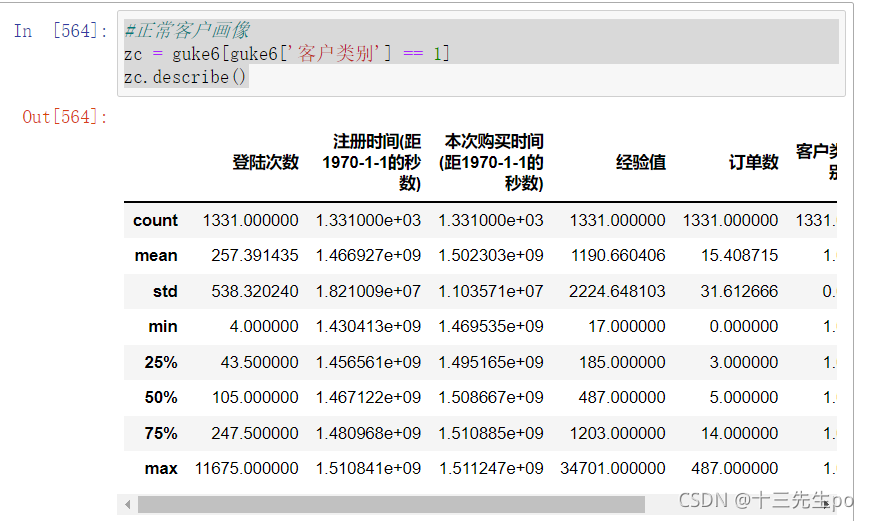
- 查看客户画像
正常客户画像
#正常客户画像
zc = guke6[guke6['客户类别'] == 1]
zc.describe()
无价值客户画像
#无价值客户画像
fzc = guke6[guke6['客户类别'] == 0]
fzc.describe()
- 用户画像
一个典型正常用户(自行计算,平均值,中位数(极端值))
间隔天数:平均409天 中位数372天
订单数:平均15个 中位数5个
经验值:平均1190 中位数487
登录次数:平均257次 中位数247次
一个典型无价值用户
间隔天数:平均133天 中位数38天
订单数:平均2个 中位数1
经验值:平均259 中位数62
登录次数:平均77次 中位数26次
3 总结和建议
研究总结
正常客户:
- 年平均登陆x次
- x%的客户在注册当天购买
- 注册时间与本次购买时间相隔x天
- 会员经验平均值
- 平均订单
无价值客户:
- 年平均登陆 次
- x%的客户在注册当天购买
- 注册时间与本次购买时间相隔x天
- 会员经验平均值
- 平均订单
总体差异:
-
相对于正常客户,无价值客户:
- 登陆次数更少
- 会员经验更少
- 购买订单数更少
- 注册和购买间隔时间更短
整体看优惠商品的优惠幅度不大,主要集中在5元以下, 最受欢迎的优惠商品主要是:柑橘、藕、青椒、龙眼等常见蔬菜水果
相关建议
下订单“稳准狠”的无价值客户,不会在正价商品上过多停留,不会花时间去关注除优惠商品以外的其他商品。 为了节省优惠营销费用、提高盈利,给出以下建议:
- 差异化推广(价格歧视)
- 向正常客户推广优质商品
- 向无价值客户推广高性价比商品
- 关联推广
- 在优惠商品处增加原价商品广告,引导客户顺便购买
- 打包销售
- 将优惠商品与原价商品打包组合销售
分析流程建议
数据分析报告书写基本套路:
- 背景介绍
- 情况介绍(公司情况,接单情况。。。)
- 数据介绍
- 需求(分析什么)
- 数据工程
- 数据获取:找人,SQL,爬虫
- 数据预处理:清洗,重构
- 数据分析
- 描述性分析
- 指标计算(分组聚合旋转(重塑)(这也是描述性分析的三种操作)、透视表、交叉表)(反复迭代)
- 可视化(反复迭代)
- 探索性分析(建模预测),可选
- 描述性分析
- 结论
- 总结分析结果
- 提出意见建议