Datawhale干货
译者:张峰,Datawhale成员
让 EDA 更简单(更美观)的实用指南!
原文链接:https://towardsdatascience.com/practical-tips-for-improving-exploratory-data-analysis-1c43b3484577
介绍
探索性数据分析(EDA)是使用任何机器学习模型前的必经步骤。EDA 过程需要数据分析师和数据科学家的专注和耐心:在从分析数据中获得有意义的见解之前,通常需要花费大量时间主动使用一个或多个可视化库。
在本篇文章中,我将根据个人经验与大家分享一些如何简化 EDA 程序并使其更便捷的技巧。特别是,我将向大家介绍在与 EDA 作“死磕”的过程中学到的三条重要技巧:
1.使用最适合你的任务的非平凡图表;
2.充分利用可视化库的功能;
3.寻找制作相同内容的更快方法。
注:在本篇文章中,我们将使用 Kaggle [2] 提供的风能数据制作信息图表。让我们开始吧!
技巧1:不要害怕使用非平凡图表
我在撰写与风能分析和预测相关的研究论文[1]时,学会了如何应用这一技巧。在为这个项目做 EDA 时,我需要创建一个汇总矩阵来反映风能参数之间的所有关系,以便找出哪些参数对彼此的影响最大。我脑海中浮现的第一个想法是建立一个 “老式” 相关矩阵,我曾在许多数据科学/数据分析项目中看到过这种矩阵。
众所周知,相关矩阵用于量化和总结变量之间的线性关系。在下面的代码片段中,对风能数据的特征列使用了 corrcoef 函数。在这里,我还应用了 Seaborn 的热图函数,将相关矩阵阵列绘制成热力图:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩阵
correlation_matrix = np.corrcoef(data[cols].values.T)
hm = sns.heatmap(correlation_matrix,
cbar=True, annot=True, square=True, fmt='.3f',
annot_kws={'size': 15},
cmap='Blues',
yticklabels=['P', 'Ws', 'Power_curve', 'Wa'],
xticklabels=['P', 'Ws', 'Power_curve', 'Wa'])
# 保存图表
plt.savefig('image.png', dpi=600, bbox_inches='tight')
plt.show()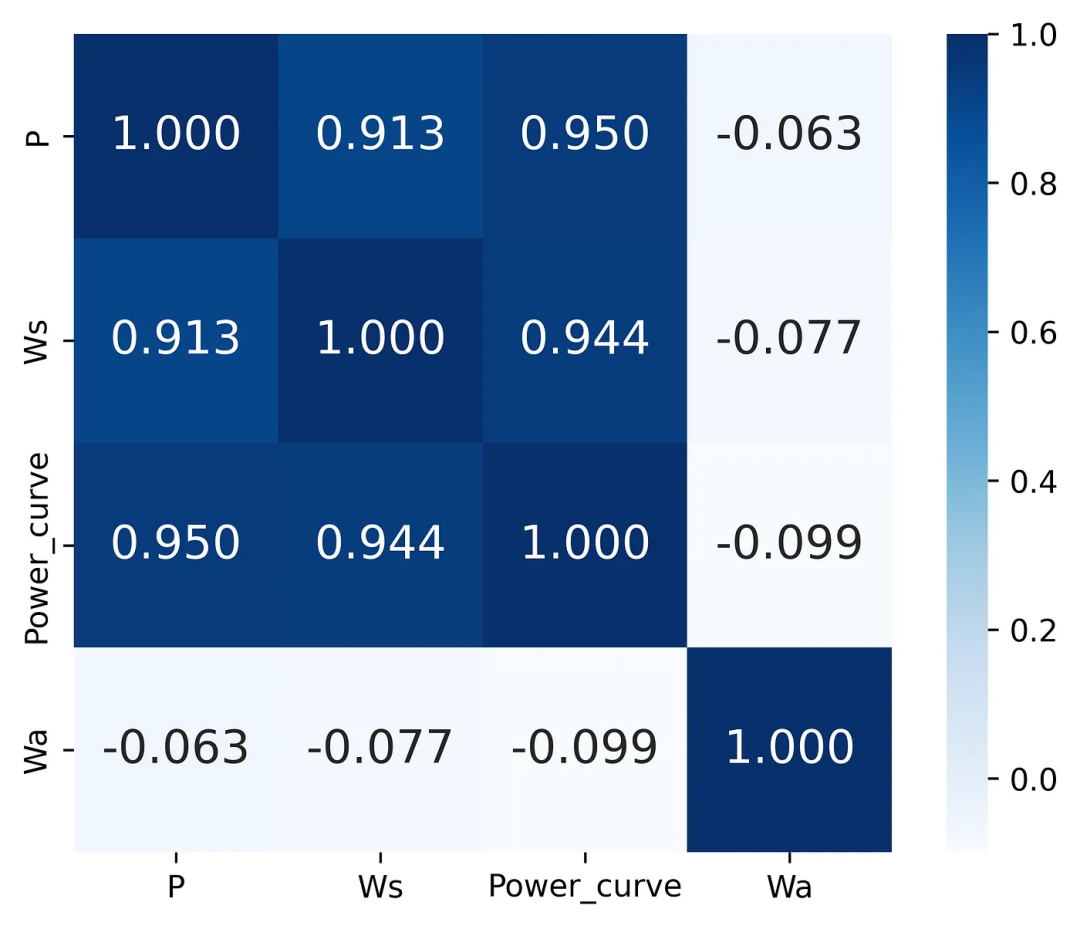
图1 建立的相关矩阵示例
通过对图表结果的分析,我们可以得出结论:风速和有效功率具有很强的相关性,但我想很多人都会同意我的观点,即在使用这种可视化方法时,这并不是一种解释结果的简单方法,因为这里我们只有数字。
散点图矩阵是相关矩阵的一个很好的替代品,它可以让你在一个地方直观地看到数据集不同特征之间的成对相关性。在这种情况下,应使用 sns.pairplot:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩阵
sns.pairplot(data[cols], height=2.5)
plt.tight_layout()
# 保存图表
plt.savefig('image2.png', dpi=600, bbox_inches='tight')
plt.show()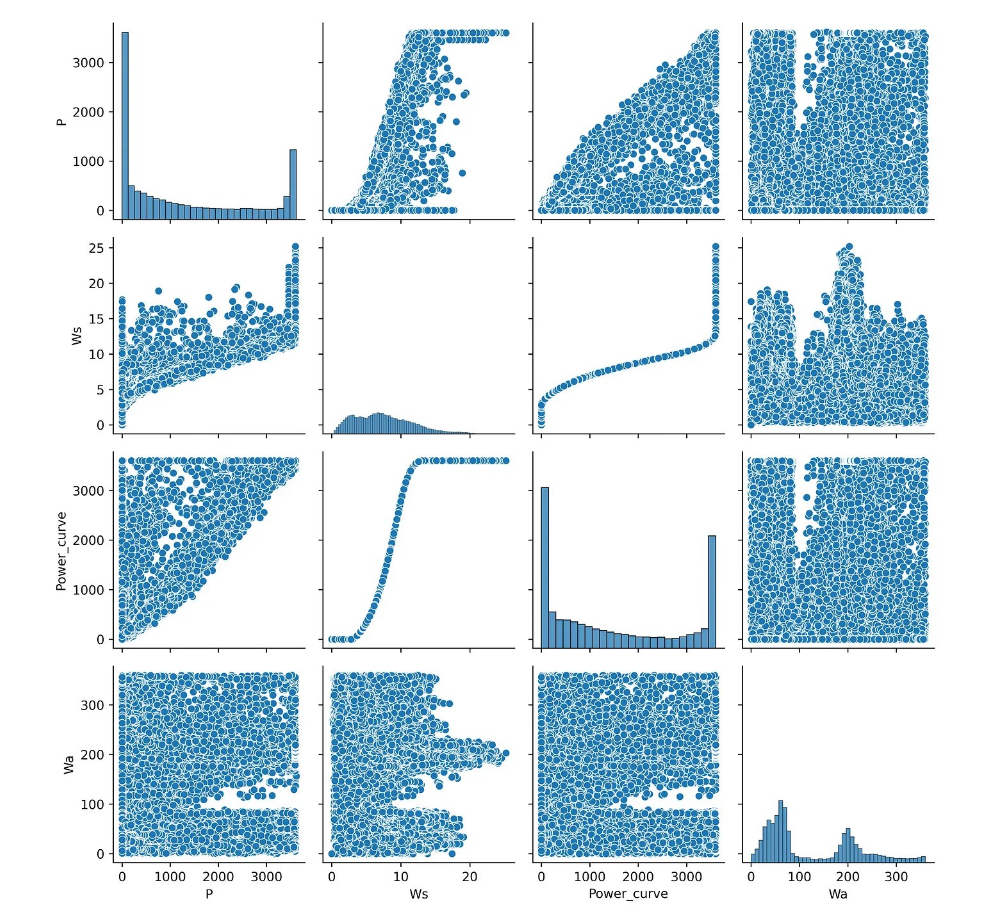
图2 散点图矩阵示例
通过观察散点图矩阵,我们可以快速目测数据的分布情况以及是否包含异常值。不过,这种图表的主要缺点是,由于采用成对方式绘制数据,会出现重复数据。
最后,我决定将上述图表合二为一,其中左下部分将包含所选参数的散点图,右上部分将包含不同大小和颜色的气泡:圆圈越大,表示所研究参数的线性相关性越强。矩阵的对角线将显示每个特征的分布情况:这里的窄峰值表示该特定参数变化不大,而其他特征会发生变化。
构建汇总表的代码如下。这里的地图由三个部分组成:fig.map_lower、fig.map_diag 和 fig.map_upper:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩阵
def correlation_dots(*args, **kwargs):
corr_r = args[0].corr(args[1], 'pearson')
ax = plt.gca()
ax.set_axis_off()
marker_size = abs(corr_r) * 3000
ax.scatter([.5], [.5], marker_size,
[corr_r], alpha=0.5,
cmap = 'Blues',
vmin = -1, vmax = 1,
transform = ax.transAxes)
font_size = abs(corr_r) * 40 + 5
sns.set(style = 'white', font_scale = 1.6)
fig = sns.PairGrid(data, aspect = 1.4, diag_sharey = False)
fig.map_lower(sns.regplot)
fig.map_diag(sns.histplot)
fig.map_upper(correlation_dots)
# 保存图表
plt.savefig('image3.jpg', dpi = 600, bbox_inches = 'tight')
plt.show()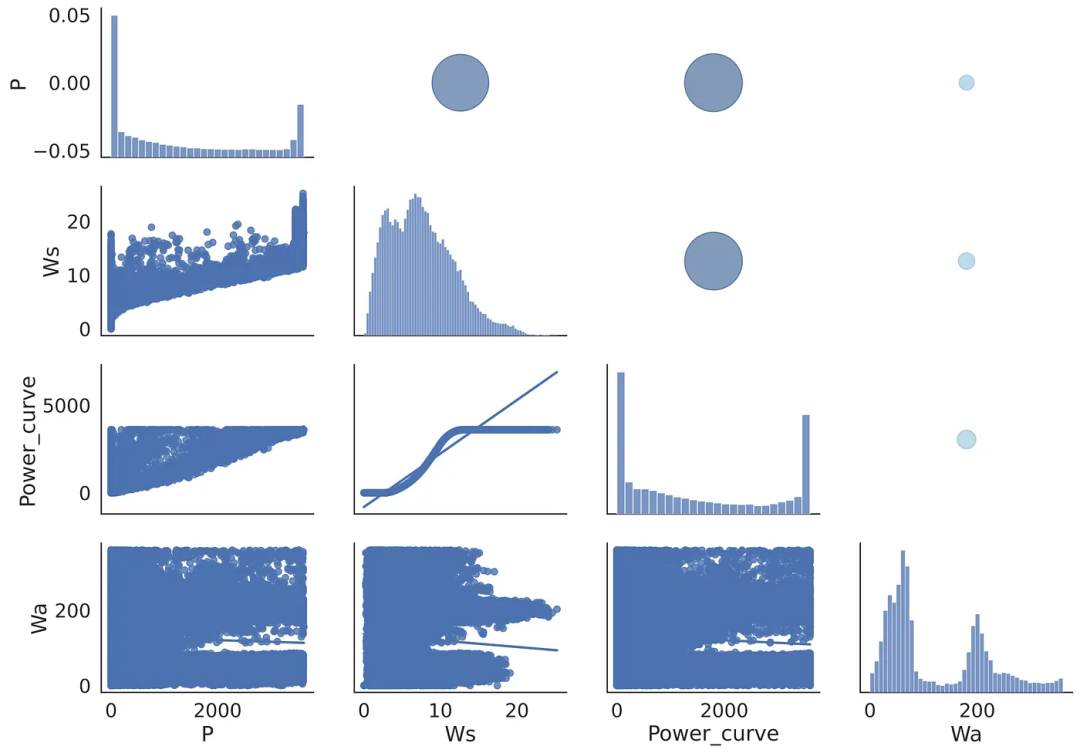
图3 汇总表示例
汇总表结合了之前研究过的两种图表的优点——其下部(左侧)模仿散点图矩阵,其上部(右侧)片段以图形方式反映了相关矩阵的数值结果。
技巧 2:充分利用可视化库的功能
我时常需要向同事和客户介绍 EDA 的成果,因此可视化是我完成这项任务的重要助手。我总是尝试在图表中添加各种元素,如箭头和注释,使图表更具吸引力和可读性。
让我们回到上文讨论的风能项目 EDA 实施案例。说到风能,最重要的参数之一就是功率曲线。风力涡轮机(或整个风电场)的功率曲线是一张显示不同风速下发电量的图表。值得注意的是,涡轮机不会在低风速下运行。它们的启动与切入速度有关,切入速度通常在 2.5-5 米/秒之间。当风速在 12 至 15 米/秒之间时,涡轮机可达到额定功率。最后,每台涡轮机都有一个安全运行的风速上限。一旦达到这个极限,风力涡轮机将无法发电,除非风速降回运行范围内。
所研究的数据集包括理论功率曲线(这是制造商提供的典型曲线,没有任何异常值)和实际曲线(如果我们绘制风力功率与风速的关系曲线)。后者通常包含许多超出理想理论形状的点,这可能是由于风机故障、SCADA 测量错误或计划外维护造成的。
现在,我们将创建一张图片 ,同时显示两种类型的风力曲线——首先,除了图例外,不带任何附加项:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 建立图表
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='actual')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='theoretical')
plt.xlabel('Wind Speed')
plt.ylabel('Power')
plt.legend(loc='best')
# 保存图表
plt.savefig('image4.png', dpi=600, bbox_inches='tight')
plt.show()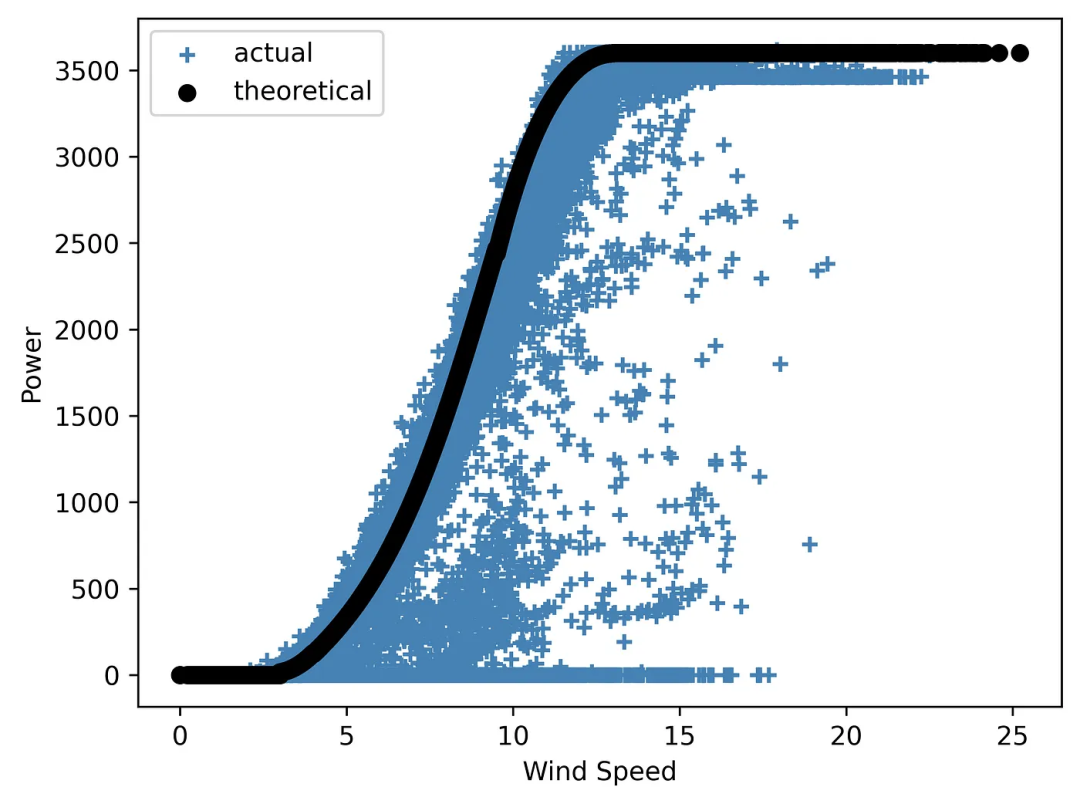
图4 一张 “沉默无语” 的风能曲线图
如你所见,该图需要解释,因为它不包含任何其他细节。
但是,如果我们添加线条来突出显示图表中的三个主要区域,标明切入速度、额定速度和切出速度,并添加带箭头的注释来显示其中一个异常值,又会怎样呢?
让我们来看看这种情况下的图表效果如何:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 建立图表
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='actual')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='theoretical')
# 添加垂直线、文字注释和箭头
plt.vlines(x=3.05, ymin=10, ymax=350, lw=3, color='black')
plt.text(1.1, 355, r"cut-in", fontsize=15)
plt.vlines(x=12.5, ymin=3000, ymax=3500, lw=3, color='black')
plt.text(13.5, 2850, r"nominal", fontsize=15)
plt.vlines(x=24.5, ymin=3080, ymax=3550, lw=3, color='black')
plt.text(21.5, 2900, r"cut-out", fontsize=15)
plt.annotate('outlier!', xy=(18.4,1805), xytext=(21.5,2050),
arrowprops={'color':'red'})
plt.xlabel('Wind Speed')
plt.ylabel('Power')
plt.legend(loc='best')
# 保存图表
plt.savefig('image4_2.png', dpi=600, bbox_inches='tight')
plt.show()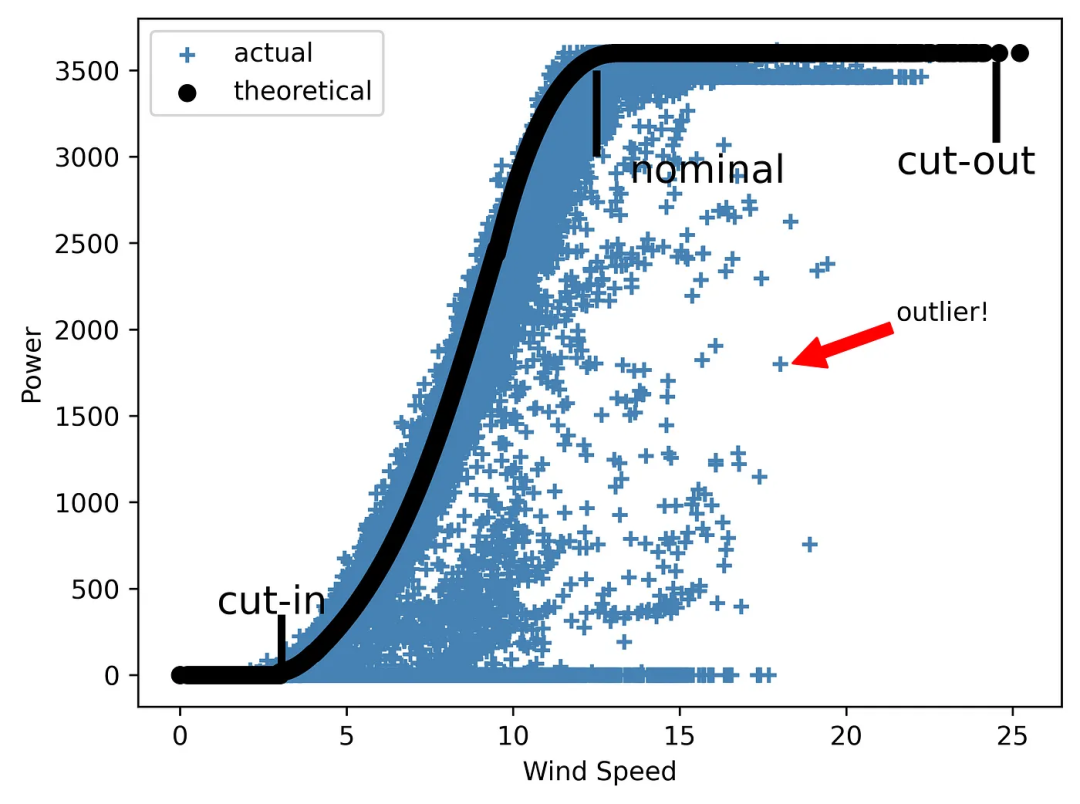
图5 一张 “能说会道” 的风能曲线图
技巧 3:总是能找到更快的制作方法
在分析风能数据时,我们通常希望获得有关风能潜在的全面信息。因此,除了风能的动态变化外,还需要有一个图表来显示风速如何随风向变化。
为了说明风能的变化,可以使用以下代码:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 将 10 分钟数据重采样为每小时测量值
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
# 绘制风能动态图
group_data.plot(kind='line')
plt.ylabel('Power')
plt.xlabel('Date/Time')
plt.title('Power generation (resampled to 1 hour)')
# 保存图表
plt.savefig('wind_power.png', dpi=600, bbox_inches='tight')
plt.show()下图是绘制的结果:
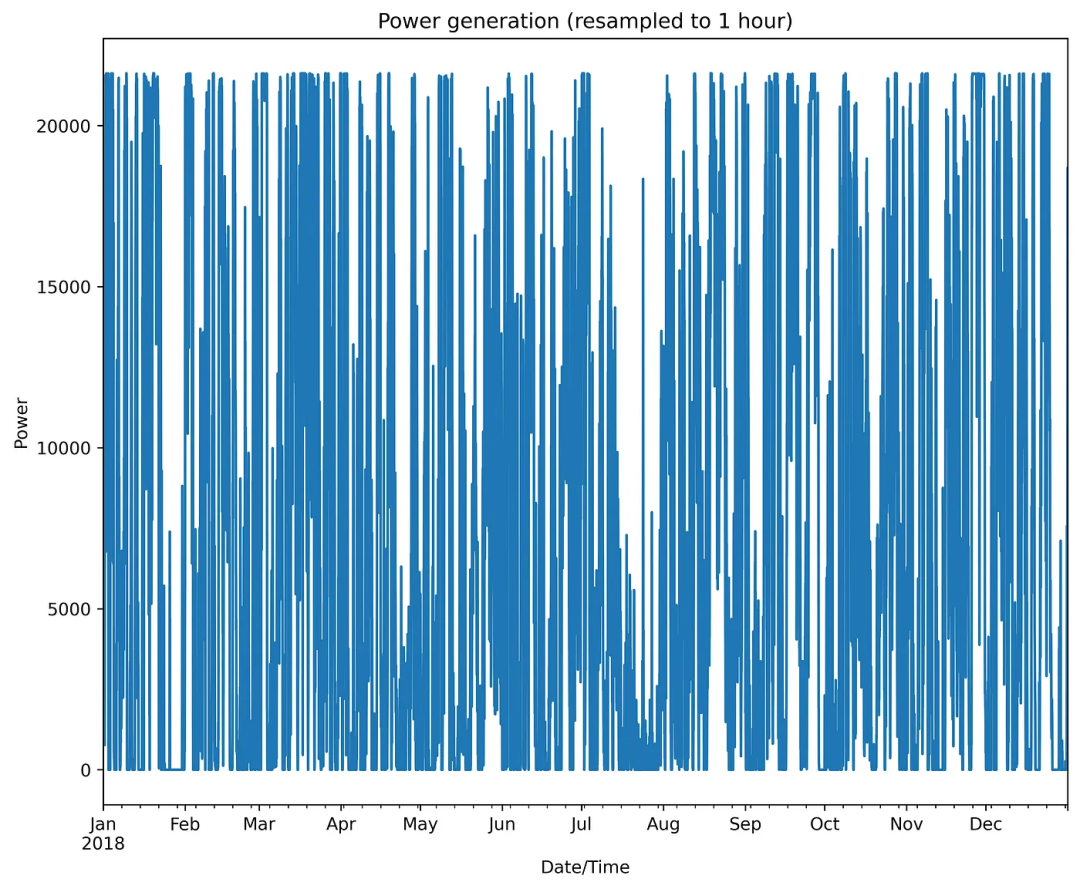
图6 风能的动态变化
正如人们可能注意到的那样,风能的动态轮廓具有相当复杂的不规则形状。
风玫瑰图(windrose)或极玫瑰图(polar rose plot)是一种特殊的图表,用于表示气象数据的分布,通常是风速的方向分布[3]。matplotlib 库中有一个简单的模块 windrose,可以轻松构建这类可视化图,例如:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from windrose import WindroseAxes
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
#为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
wd = data['Wa']
ws = data['Ws']
# 以堆叠直方图的形式绘制正态化风玫瑰图
ax = WindroseAxes.from_ax()
ax.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')
ax.set_legend()
# 保存图表
plt.savefig('windrose.png', dpi = 600, bbox_inches = 'tight')
plt.show()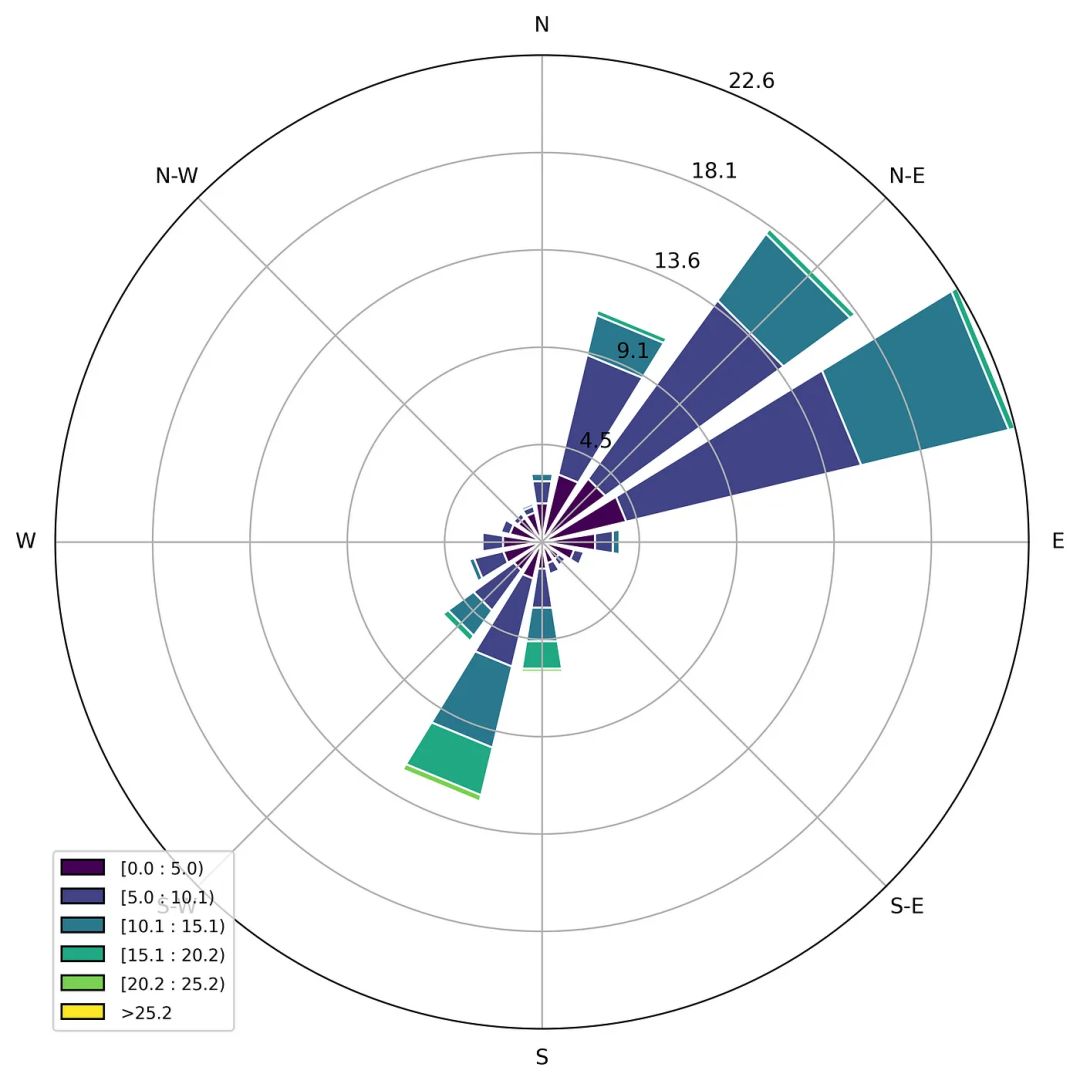
图7 根据现有数据得出的风玫瑰图
观察风玫瑰图,可以发现有两个主要风向——东北风和西南风。
但如何将这两张图片合并成一张呢?最明显的办法是使用 add_subplot。但由于 windrose 库的特殊性,这并不是一项简单的任务:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from windrose import WindroseAxes
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
# 将两个图都绘制为子图
ax1 = fig.add_subplot(211)
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
group_data.plot(kind='line')
ax1.set_ylabel('Power')
ax1.set_xlabel('Date/Time')
ax1.set_title('Power generation (resampled to 1 hour)')
ax2 = fig.add_subplot(212, projection='windrose')
wd = data['Wa']
ws = data['Ws']
ax = WindroseAxes.from_ax()
ax2.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')
ax2.set_legend()
# 保存图表
plt.savefig('image5.png', dpi=600, bbox_inches='tight')
plt.show()在这种情况下,结果是这样的:
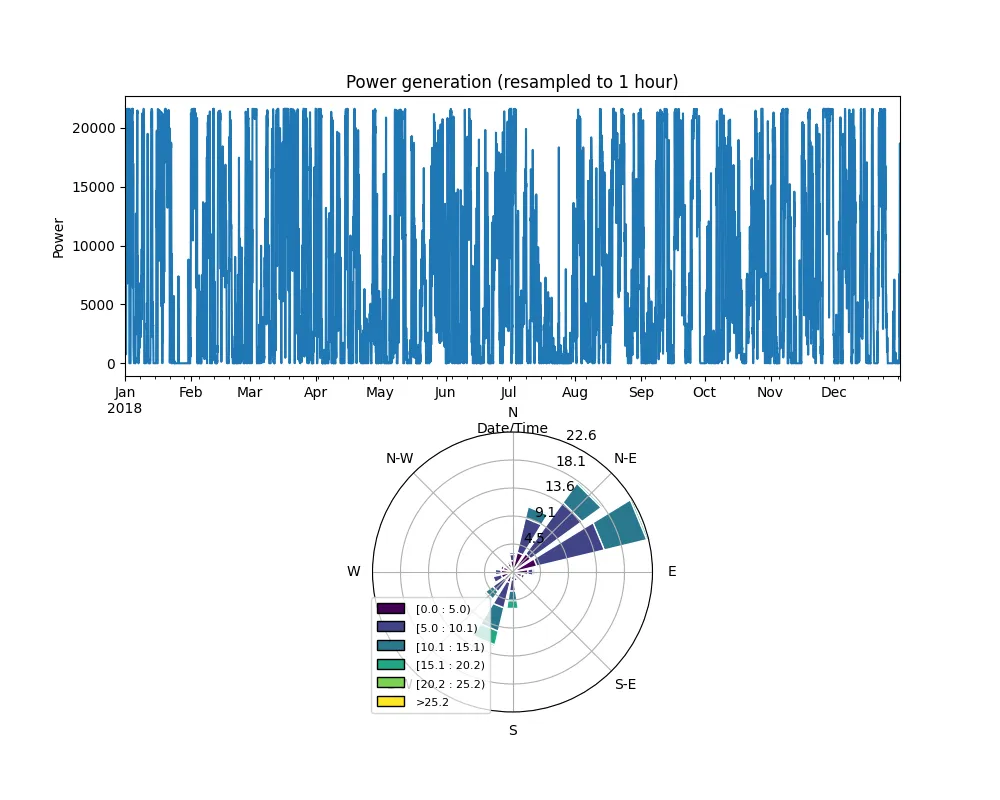
图8 单张图片 显示风能动态和风玫瑰图
这样做的主要缺点是两个子图的大小不同,因此风玫瑰图周围有很多空白。
为了方便起见,我建议采用另一种方法,使用 Python Imaging Library (PIL) [4],只需十几行代码:
import numpy as np
import PIL
from PIL import Image
# 列出需要合并的图片
list_im = ['wind_power.png','windrose.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 调整所有图片的大小,使其与最小图片相匹配
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
# 对于垂直堆叠,我们使用 vstack
images_comb = np.vstack((np.asarray(i.resize(min_shape)) for i in imgs))
images_comb = PIL.Image.fromarray(imgs_comb)
# 保存图表
imgages_comb.save('image5_2.png', dpi=(600,600))这里的输出看起来更漂亮一些,两张图片的尺寸相同,这是因为代码选择最小的图片,并重新缩放其他图片来进行匹配:
使用 PIL 获取的包含风能动力和风玫瑰图的单一图片
顺便说一下,在使用 PIL 时,我们还可以使用水平堆叠法,例如,我们可以将 “沉默无语” 和 “能说会道” 的风力曲线图进行比较和对比:
import numpy as np
import PIL
from PIL import Image
list_im = ['image4.png','image4_2.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 选取最小的图片 ,并调整其他图片 的大小以与之匹配(此处可任意调整图片形状)
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
imgs_comb = np.hstack((np.asarray(i.resize(min_shape)) for i in imgs))
# 保存图表
imgs_comb = PIL.Image.fromarray(imgs_comb)
imgs_comb.save('image4_merged.png', dpi=(600,600))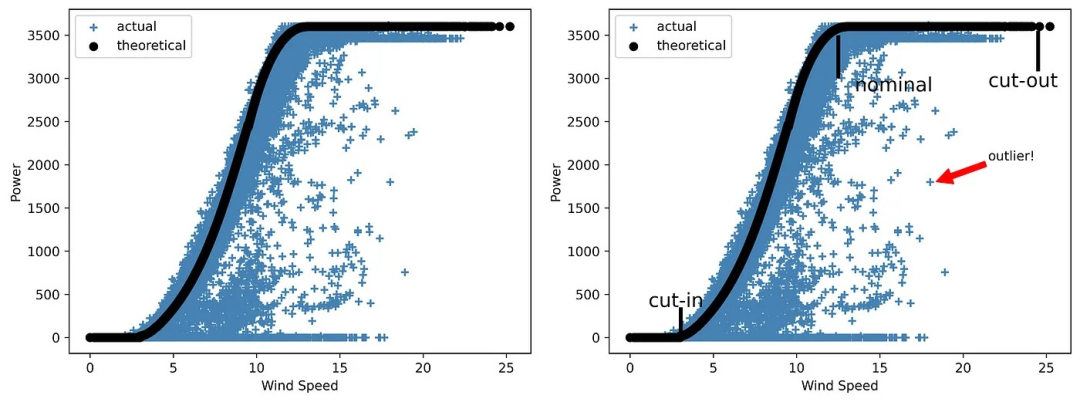
图9 比较和对比两张风力曲线图
结论
在这篇文章中,我与大家分享了如何让 EDA 流程更轻松的三个技巧。我希望这些建议对学习者有用,并开始将它们应用到你的数据任务中。
这些技巧完全符合我在进行 EDA 时一直尝试应用的公式:定制 → 逐项 → 优化。
你可能会问,这到底有什么关系呢?我可以说,这其实很重要,因为:
根据当前的特定需求定制图表非常重要。例如,与其制作大量的信息图表,不如考虑如何将几个图表合并成一个,就像我们在制作汇总矩阵时所做的那样,它结合了散点图和相关图的优点。
所有图表都应该为自己代言。因此,你需要知道如何在图表中逐项列出重要内容,使其详细易读。比较 “沉默无语” 和 “能说会道” 的功率曲线之间的差别有多大。
最后,每一位数据专家都应该学习如何优化 EDA 流程,使工作更便捷(生活更轻松)。如果需要将两幅图片合并成一幅,不必总是使用 add_subplot 选项。
还有什么?我可以肯定地说,在处理数据的过程中,EDA 是一个非常有创意和有趣的步骤(更何况它还超级重要)。
让你的信息图表像钻石一样闪闪发光,别忘了享受这个过程!
参考文献列表
风能分析和预测的数据驱动应用:The case of “La Haute Borne” wind farm. https://doi.org/10.1016/j.dche.2022.100048
风能数据:https://www.kaggle.com/datasets/bhavikjikadara/wind-power-generated-data?resource=download
关于 windrose 库的教程:https://windrose.readthedocs.io/en/latest/index.html
PIL 库:https://pillow.readthedocs.io/en/stable/index.html

整理不易,点赞三连↓