文章目录
引言
学过一点点有关python的数据分析的知识后,稍稍有些坐不住,便找来一数据集进行练手,找点成就感。笔者的主要研究内容:通过一个赛事数据,利用数学方法,分析影响裁判判罚有哪些因素;如种族歧视、国籍歧视、球员因素等。
数据集链接赛事数据
数据集内容
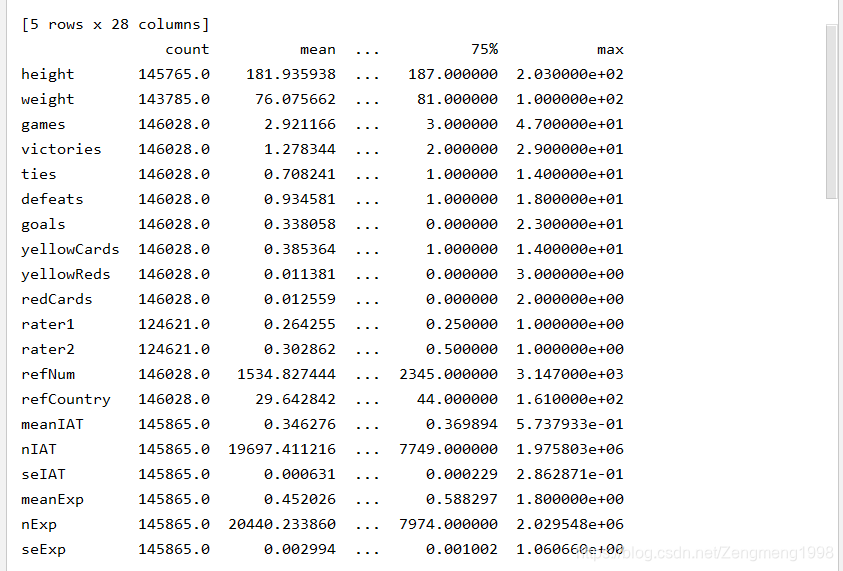
这个数据集主要是关于足球赛事的一个数据集,2012_2013的赛事数据,包括2053名球员,3147名裁判的数据,数据内容如下图。

数据集特征表:
| series | 我的翻译 |
|---|---|
| playershort | ID |
| player | (name) |
| club | 俱乐部 |
| leagueCuonty | 俱乐部国籍 |
| height\weight | 身高体重 |
| position | 所踢位置 |
| rater1、2 | 值越大肤色越黑 |
| yellowcard | 黄牌数 |
| yellowred | 黄转红数 |
| redcard | 红牌数 |
| goals | 进球数 |
| defeats\victores\tie | 输胜平 |
| games | 上场数 |
| refNum\County | 裁判的ID国籍 |
| IAT/Exp | 内应测试??(用于判定该国是否有种族歧视倾向) |
数据集预览
df=pd.read_csv("redcard.csv")
print(df.shape)
print(df.head())
#对数据预览
a=df.describe().T
print(a)
#查看特征
all_columns=df.columns.tolist()
print(all_columns)
#查看一些统计数据
print(df['height'].mean())
print(df['weight'].mean())实现结果:
数据大小与前五行内容:

简单的预览:
对数据数据预处理
实现思路
数据集的有效数据有1344万多条的数据,每行数据包含28列信息,因此在实现研究问题是时,需要对其进行一定的清洗处理(以数据切割(tidy data)为主)。这里笔者分别将裁判、球员、俱乐部、赛事情况信息分别进行提取、建表,便于后期数据分析。具体思路如下脑图所示: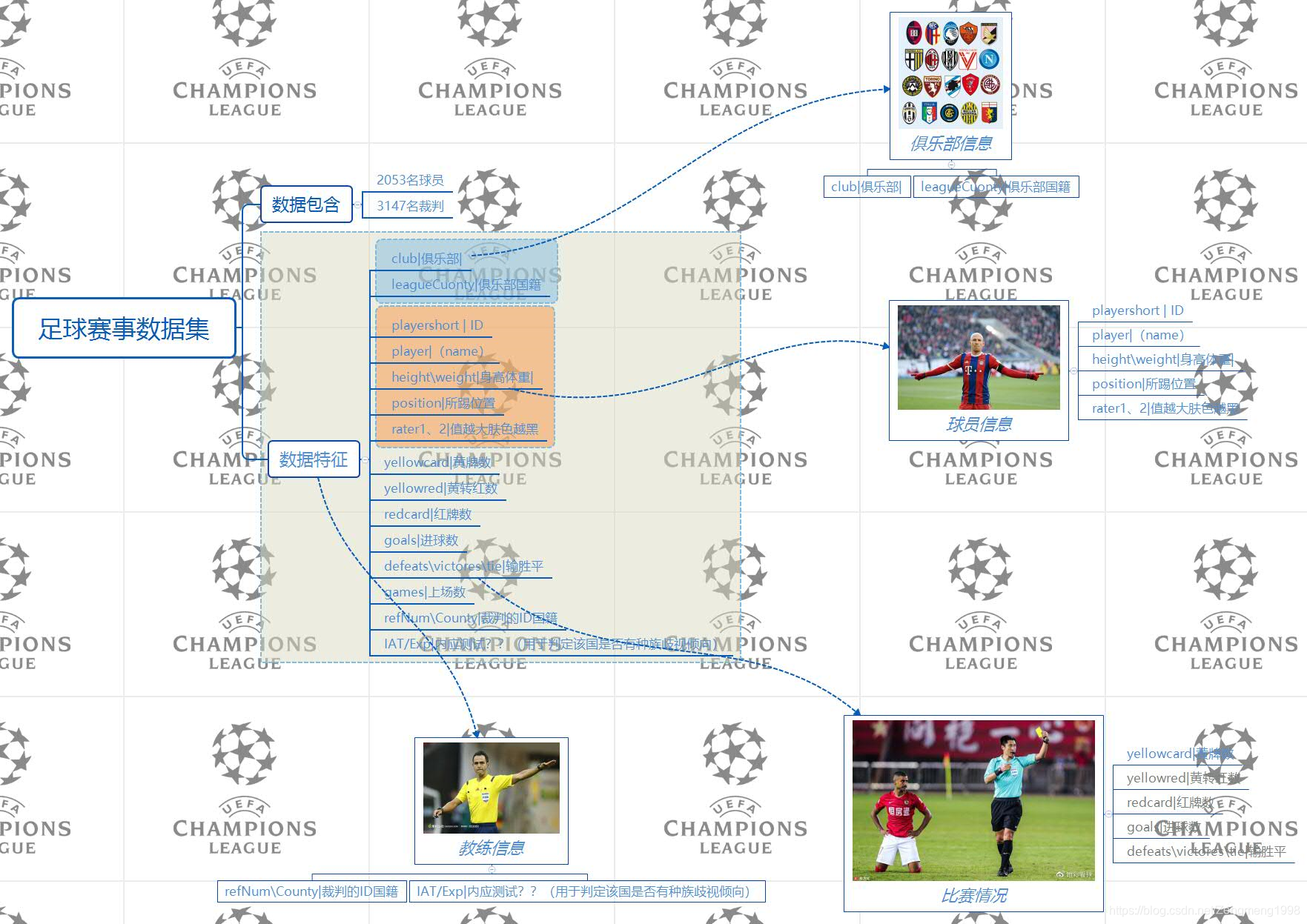
预处理程序与结果
引用约定
#from __future__ import absolute_import, division, print_function
import matplotlib as mpl
# from matplotlib import pyplot as plt
# from matplotlib.pyplot import GridSpec
# import seaborn as sns
import numpy as np
import pandas as pd
import os, sys
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
#sns.set_context("poster", font_scale=1.3)
import missingno as msno
#可用于统计缺失的情况
import pandas_profiling
from sklearn.datasets import make_blobs
import time
#2012-2013年的足球比赛数据共计球员2053名,裁判3147名建表(dataframe)与生表的函数
#对数据进行切割划分Tidy Data并生成处理好了的数据集
def get_subgroup(dataframe, g_index, g_columns):
"""Helper function that creates a sub-table from the columns and runs a quick uniqueness test."""
g = dataframe.groupby(g_index).agg({col: 'nunique' for col in g_columns})
if g[g > 1].dropna().shape[0] != 0:
print("Warning: you probably assumed this had all unique values but it doesn't.")
return dataframe.groupby(g_index).agg({col: 'max' for col in g_columns})
#定义一个以g_index为键值,g_column为series的table
def save_subgroup(dataframe, g_index, subgroup_name, prefix='raw_'):
save_subgroup_filename = "".join([prefix, subgroup_name, ".csv"])
dataframe.to_csv(save_subgroup_filename, encoding='UTF-8')
test_df = pd.read_csv(save_subgroup_filename, index_col=g_index, encoding='UTF-8')
# Test that we recover what we send in
if dataframe.equals(test_df):
print("Test-passed: we recover the equivalent subgroup dataframe.")
else:
print("Warning -- equivalence test!!! Double-check.")
#将table以csv文件形式存储建立球员(raw_players)数据集
#生成关于运动员的数据集
player_index='playerShort'
player_cols=['birthday',
'height',
'weight',
'position',
'photoID',
'rater1',
'rater2',
]
all_cols_unique_players=df.groupby('playerShort').agg({col:'nunique'for col in player_cols})#相当于对其进行计数,运动员一共出现了多少次
print(all_cols_unique_players.head())
players=get_subgroup(df,player_index,player_cols)
print(players.head())
players = get_subgroup(df, player_index, player_cols)
print(players.head())
save_subgroup(players, player_index, "players")
建立俱乐部(raw_clubs)数据集
#生成关于俱乐部(Clubs)的数据集
club_index = 'club'
club_cols = ['leagueCountry']
clubs = get_subgroup(df, club_index, club_cols)
print(clubs.head())
print(clubs['leagueCountry'].value_counts())
save_subgroup(clubs,club_index,"clubs")
建立裁判(raw_referees)数据集
#生成关于教练的数据集
referee_index = 'refNum'
referee_cols = ['refCountry']
referees = get_subgroup(df, referee_index, referee_cols)
print(referees.head())
print(referees['refCountry'].value_counts())
print(referees.refCountry.nunique())#教练分别来自于哪些国家
print(referees.shape)
save_subgroup(referees, referee_index, "referees")建立赛事情况(raw_dyads)的数据集
dyad_index = ['refNum', 'playerShort']
dyad_cols = ['games',
'victories',
'ties',
'defeats',
'goals',
'yellowCards',
'yellowReds',
'redCards',
]
dyads = get_subgroup(df, g_index=dyad_index, g_columns=dyad_cols)
save_subgroup(dyads, dyad_index, "dyads")
print(dyads[dyads.redCards > 1].head(10))建立国籍种族歧视调查(raw_countrys)数据集
#生成关于国家的数据
country_index = 'refCountry'
country_cols = ['Alpha_3', # rename this name of country
'meanIAT',
'nIAT',
'seIAT',
'meanExp',
'nExp',
'seExp',
]
countries = get_subgroup(df, country_index, country_cols)
#countries.head()
save_subgroup(countries, country_index, "countries")实现结果
烦si
对于数据集处理时主要用到的pandas包有了进一步的了解理解,现阶段认为其是建模时的数据库处理,可以尝试用其进行操作。
一段段子
一年级的小明对语文课上老师布置的造句作业是百思不得其解啊,(老师要求大家用词语:党、祖国、社会、人民进行造句。)于是跑去向找下班回来的爸爸求助。明爸:“儿子啊,这个简单嘛,你这样,就把祖国当做你奶奶、把党当做你老爸我,社会当做你老妈、这人民嘛,自然就是你啦。”
到了晚上,小明依旧没有完成自己的造句作业,于是跑去房间找爸爸,来到爸爸房间,只见房门虚掩,明爸明妈正在房中造明第,这可小明吓得不轻,于是跑回到楼上找奶奶,小明哭着叫奶奶,但是奶奶房门紧闭已然睡熟,没有听见。小明只好又哭着回到自己的房间,说巧不巧,来了灵感,一下纸就把句子照完了。
第二天,在语文课上,语文老师王娇兰夸小明的句子造的好那是一个好啊,小小年纪就有忧国忧民的思想,还当着全班同学的面把它读了一遍:党欺负着社会,祖国在沉睡,人民在哭泣。。。
帮了大忙的参考:程序源自
