一、咱们先找到豆瓣主页,
地址:https://movie.douban.com/chart
二、分析网页属性,按F12或者鼠标右击检查即可进入开发者模式:
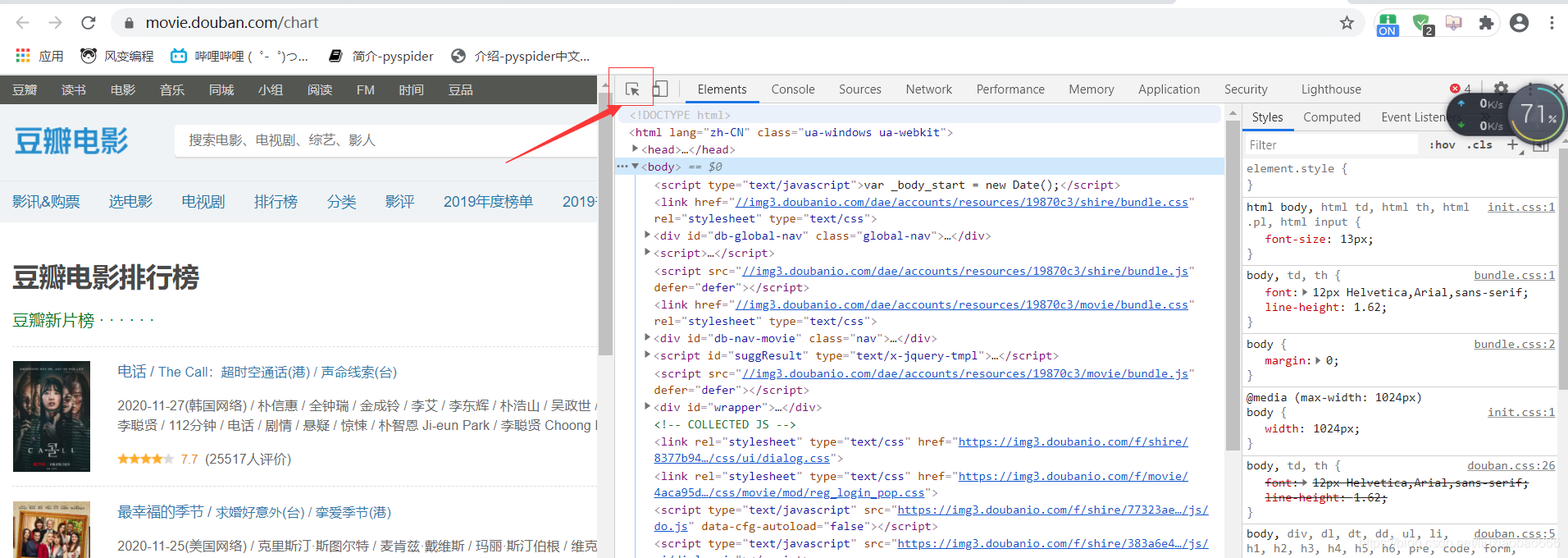
三、鼠标点击右上角的小箭头
四、找到我们想要的内容然后点击即可在右边的代码中定位,比如我这里点击到第一部电影的位置:
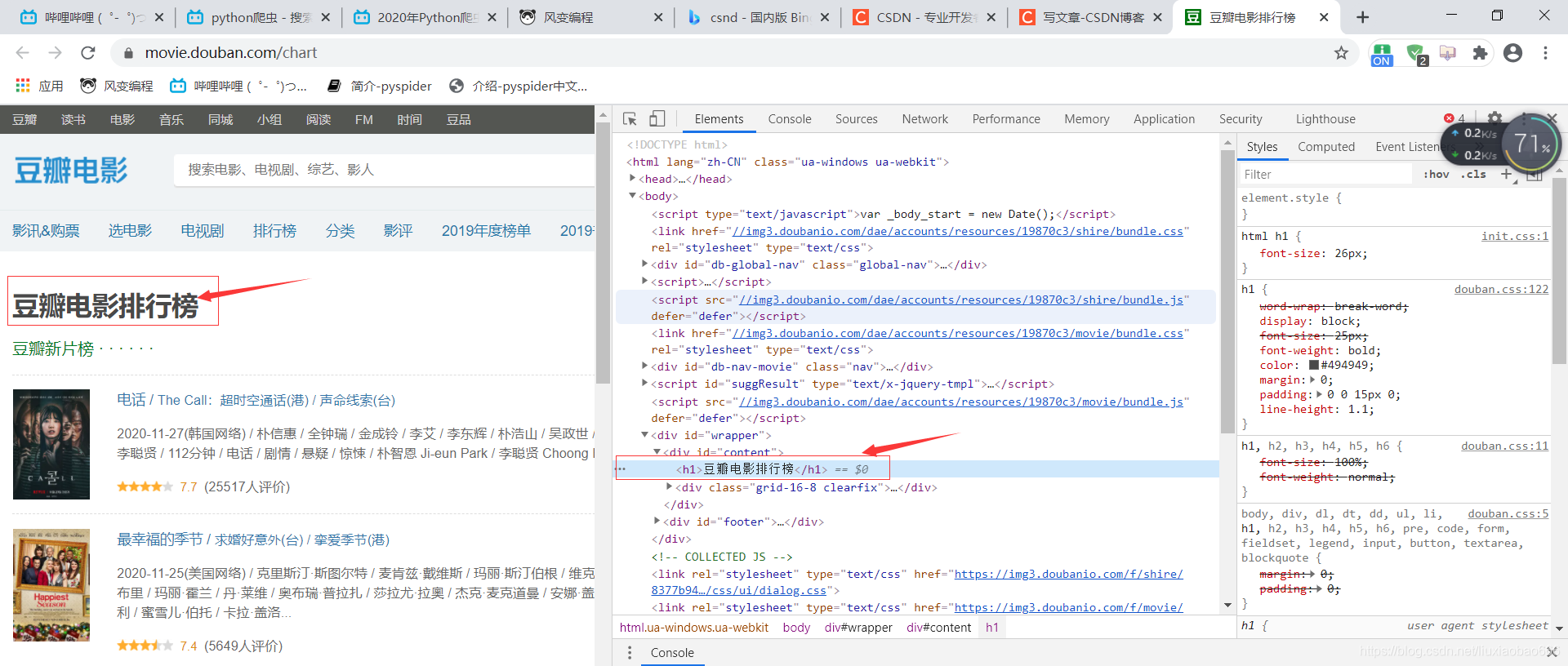
五、分析网页
,
我们需要找到电影的属性,属性自然包括电影序号、电影名称、评分、评论(推荐语)、电影链接等大概就是下面框内的属性,然后我们根据前面的方法定位到这些属性

六、书写代码
import requests
from bs4 import BeautifulSoup
#写一个循环来遍历每页的电影
for x in range(10):
url='https://movie.douban.com/top250?start='+str(x*25)+'&filter='
headers={
'User-Agent':'Mozilla/5.0(Windows NT 10.0;WOW64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400'
}#注意头部信息必不可少,不然爬不到想要的信息,我们要习惯使用头部文件
res=requests.get(url,headers=headers)
bs=BeautifulSoup(res.text,'html.parser')
# print(bs)
#查找序列号,电影名称,电影连接的标签
tag_num=bs.find_all('div',class_='item')
tag_comment=bs.find_all('div',class_='star')
#查找包含评分的div标签
tag_word=bs.find_all('span',class_='inq')
list_all=[]
for x in range(len(tag_num)):
if tag_num[x].text[2:5]=='' or tag_num[x].text[2:5]=='' or x>=len(tag_word):
list_movie = [tag_num[x].text[2:5], tag_num[x].find('img')['alt'], tag_comment[x].text[2:5],
tag_num[x].find('a')['href']]
else:
list_movie = [tag_num[x].text[2:5], tag_num[x].find('img')['alt'], tag_comment[x].text[2:5],
tag_word[x].text, tag_num[x].find('a')['href']]
list_all.append(list_movie)
print(list_all)
#此处引号内填写没有序列号的电影
七、运行代码
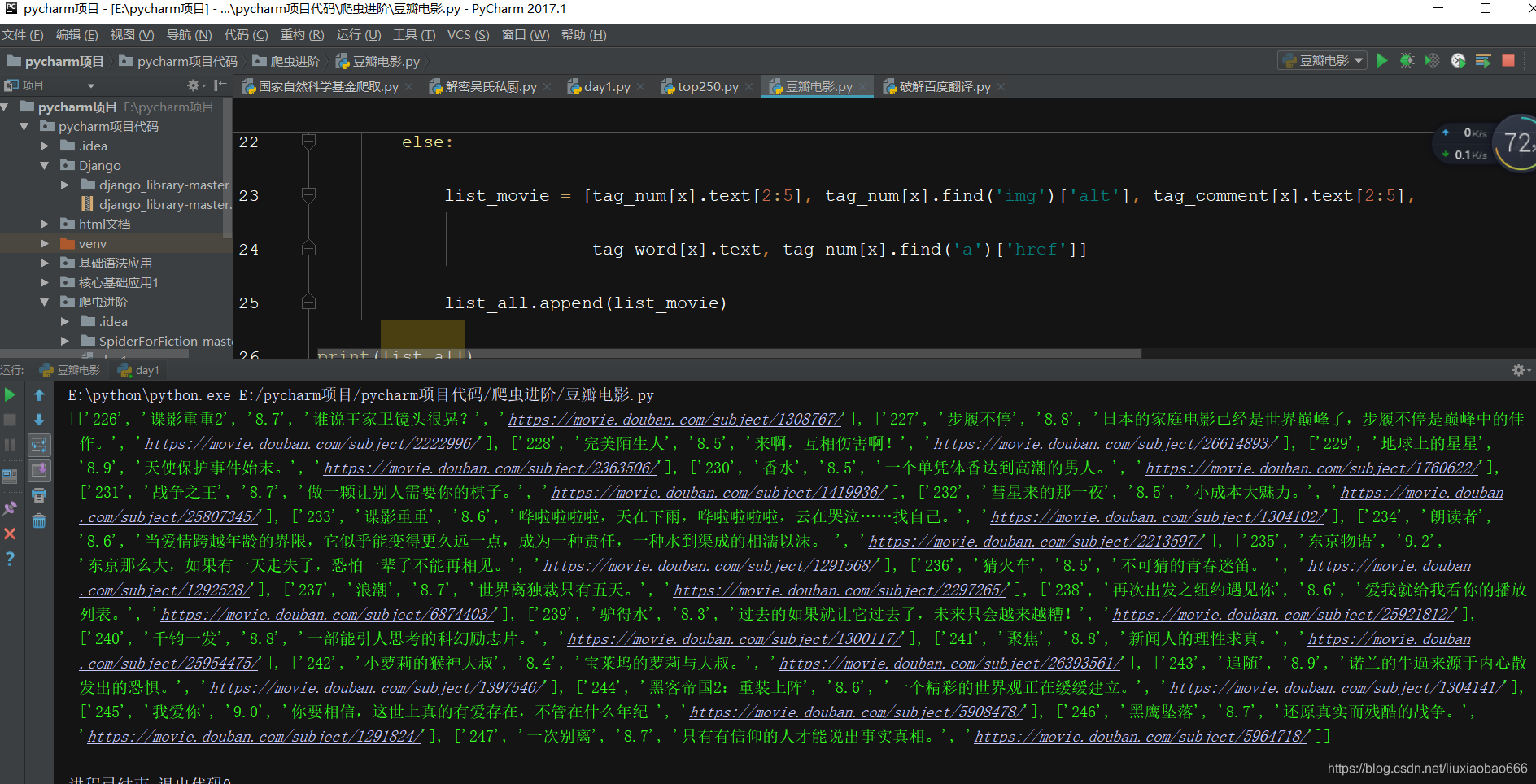
我这里应该是循环出错了,只得到了一个页面的数据,哪位大哥有方法了可以评论一下我,小弟不胜感激。