白板推导系列Pytorch-隐马尔可夫模型
HMM 博客汇总
状态转移矩阵和观测概率矩阵
状态转移矩阵
A = [ a i j ] N × N α i j = P ( i t + 1 = q j ∣ i t = q i ) \begin{aligned} A &=\left[a_{i j}\right]_{N \times N} \\ \alpha_{ij} &= P(i_{t+1} = q_j|i_t=q_i) \end{aligned} Aαij=[aij]N×N=P(it+1=qj∣it=qi)
观测概率矩阵
B = [ b j ( k ) ] N × M b j ( k ) = P ( o t = v k ∣ i t = q j ) \begin{aligned} B &=\left[b_{j}(k)\right]_{N \times M} \\ b_j(k) &= P(o_{t}=v_k|i_t=q_j) \end{aligned} Bbj(k)=[bj(k)]N×M=P(ot=vk∣it=qj)
一个模型
下面我借助盒子与球模型说明HMM模型的模型参数
假设有4个盒子,每个盒子都装有红白两种颜色的球
| 盒子 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 红球数 | 5 | 3 | 6 | 8 |
| 白球数 | 5 | 7 | 4 | 2 |
按照下面的方法抽球,产生一个球的颜色的观测序列:开始,从4个盒子里以等概率随机选取1个盒子,从这个盒子里随机抽出1个球,记录其颜色后,放回;然后,从当前盒子随机转移到下一个盒子,规则是:如果当前盒子是盒子1,
那么下一盒子一定是盒子2,如果当前是盒子2或3,那么分别以概率0.4和0.6转移到左边或右边的盒子,如果当前是盒子4,那么各以0.5的概率停留在盒子4或转移到盒子3;确定转移的盒子后,再从这个盒子里随机抽出1个球,记录其
颜色,放回;如此下去,重复进行5次,得到一个球的颜色的观测序列
O = { 红 , 红 , 白 , 白 , 红 } O = \{\text{红},\text{红},\text{白},\text{白},\text{红}\} O={
红,红,白,白,红}
在这个过程中,观察者只能观测到球的颜色的序列,观测不到球是从哪个盒子取出的,即观测不到盒子的序列
- 状态集合
Q = { 盒子 1 , 盒子 2 , 盒子 3 , 盒子 4 } Q = \{\text{盒子}1,\text{盒子}2,\text{盒子}3,\text{盒子}4\} Q={ 盒子1,盒子2,盒子3,盒子4}
- 观测集合
V = { 红 , 白 } V = \{\text{红},\text{白}\} V={ 红,白}
- 初始概率分布
π = ( 0.25 , 0.25 , 0.25 , 0.25 ) T \pi= (0.25, 0.25, 0.25, 0.25)^T π=(0.25,0.25,0.25,0.25)T
- 状态转移矩阵 P ( i t + 1 ∣ i 1 , i 2 , . . . , i t , o 1 , o 2 , . . . o t ) P(i_{t+1}|i_1,i_2,...,i_t,o_1,o_2,...o_t) P(it+1∣i1,i2,...,it,o1,o2,...ot)
A = [ 0 1 0 0 0.4 0 0.6 0 0 0.4 0 0.6 0 0 0.5 0.5 ] A=\left[\begin{array}{cccc} 0 & 1 & 0 & 0 \\ 0.4 & 0 & 0.6 & 0 \\ 0 & 0.4 & 0 & 0.6 \\ 0 & 0 & 0.5 & 0.5 \end{array}\right] A=⎣⎢⎢⎡00.400100.4000.600.5000.60.5⎦⎥⎥⎤
- 观测概率分布 P ( o t + 1 ∣ i 1 , i 2 , . . . , i t + 1 , o 1 , o 2 , . . . , o t ) P(o_{t+1}|i_1,i_2,...,i_{t+1},o_1,o_2,...,o_t) P(ot+1∣i1,i2,...,it+1,o1,o2,...,ot)
B = [ 0.5 0.5 0.3 0.7 0.6 0.4 0.8 0.2 ] B=\left[\begin{array}{ll} 0.5 & 0.5 \\ 0.3 & 0.7 \\ 0.6 & 0.4 \\ 0.8 & 0.2 \end{array}\right] B=⎣⎢⎢⎡0.50.30.60.80.50.70.40.2⎦⎥⎥⎤
两个假设
齐次马尔可夫假设
P ( i t ∣ i t − 1 , o t − 1 , ⋯ , i 1 , o 1 ) = P ( i t ∣ i t − 1 ) , t = 1 , 2 , ⋯ , T P\left(i_{t} \mid i_{t-1}, o_{t-1}, \cdots, i_{1}, o_{1}\right)=P\left(i_{t} \mid i_{t-1}\right), \quad t=1,2, \cdots, T P(it∣it−1,ot−1,⋯,i1,o1)=P(it∣it−1),t=1,2,⋯,T
观测独立假设
P ( o t ∣ i T , o T , i T − 1 , o T − 1 , ⋯ , i t + 1 , o t + 1 , i t , i t − 1 , o t − 1 , ⋯ , i 1 , o 1 ) = P ( o t ∣ i t ) P\left(o_{t} \mid i_{T}, o_{T}, i_{T-1}, o_{T-1}, \cdots, i_{t+1}, o_{t+1}, i_{t}, i_{t-1}, o_{t-1}, \cdots, i_{1}, o_{1}\right)=P\left(o_{t} \mid i_{t}\right) P(ot∣iT,oT,iT−1,oT−1,⋯,it+1,ot+1,it,it−1,ot−1,⋯,i1,o1)=P(ot∣it)
现在我们所有知道的东西都在这了,看看我们能做什么
三个问题
一、概率计算问题(Evaluation)
给定模型 λ = ( A , B , π ) \lambda=(A, B, \pi) λ=(A,B,π) 和观测序列 O = ( o 1 , o 2 , ⋯ , o T ) O=\left(o_{1}, o_{2}, \cdots, o_{T}\right) O=(o1,o2,⋯,oT) , 计算在模型 λ \lambda λ 下观测序列 O O O 出现的概率 P ( O ∣ λ ) P(O \mid \lambda) P(O∣λ).
直接计算法
P ( O ∣ λ ) = ∑ I P ( O , I ∣ λ ) = ∑ I P ( O ∣ I , λ ) ⋅ P ( I ∣ λ ) P(O|\lambda) = \sum_{I}P(O,I|\lambda) = \sum_{I}P(O|I,\lambda)\cdot P(I|\lambda) P(O∣λ)=I∑P(O,I∣λ)=I∑P(O∣I,λ)⋅P(I∣λ)
前向算法
定义前向概率为
α t ( i ) = P ( o 1 , o 2 , . . . , o t , i t = q i ∣ λ ) \alpha_t(i) = P(o_1,o_2,...,o_t,i_t=q_i|\lambda) αt(i)=P(o1,o2,...,ot,it=qi∣λ)
那么我们要求的
P ( O ∣ λ ) = P ( o 1 , o 2 , . . . , o T ∣ λ ) = ∑ i t P ( o 1 , o 2 , . . . , o T , i T = q i ∣ λ ) = ∑ i α T ( i ) P(O|\lambda) = P(o_1,o_2,...,o_T|\lambda) = \sum_{i_t}P(o_1,o_2,...,o_T,i_T=q_i|\lambda) = \sum_{i}\alpha_T(i) P(O∣λ)=P(o1,o2,...,oT∣λ)=it∑P(o1,o2,...,oT,iT=qi∣λ)=i∑αT(i)
算法过程:
(1)初值
α 1 ( i ) = P ( o 1 , i 1 = q i ∣ λ ) = P ( i 1 ∣ λ ) ⋅ P ( o 1 ∣ i 1 = q i , λ ) = π i b i ( o 1 ) \alpha_1(i) = P(o_1,i_1=q_i|\lambda) = P(i_1|\lambda)\cdot P(o_1|i_1=qi,\lambda) = \pi_i b_i(o_1) α1(i)=P(o1,i1=qi∣λ)=P(i1∣λ)⋅P(o1∣i1=qi,λ)=πibi(o1)
(2)递推
α t + 1 ( i ) = P ( o 1 , o 2 , . . . , o t , o t + 1 , i t + 1 = q i ∣ λ ) = P ( o 1 , o 2 , . . . , o t , i t + 1 = q i ∣ λ ) ⋅ P ( o t + 1 ∣ o 1 , o 2 , . . . , o t , i t + 1 = q i ∣ λ ) = [ ∑ j = 1 P ( o 1 , o 2 , . . . , o t , i t = q j , i t + 1 = q i ∣ λ ) ] ⋅ P ( o t + 1 ∣ i t + 1 = q i ) = [ ∑ j = 1 P ( o 1 , o 2 , . . . , o t , i t = q j ∣ λ ) ⋅ P ( i t + 1 = q i ∣ o 1 , o 2 , . . . , o t , i t = q j , λ ) ] ⋅ b i ( o t + 1 ) = [ ∑ j = 1 α t ( j ) ⋅ P ( i t + 1 = q i ∣ i t = q j , λ ) ] ⋅ b i ( o t + 1 ) = [ ∑ j = 1 α t ( j ) ⋅ a j i ] ⋅ b i ( o t + 1 ) \begin{aligned} \alpha_{t+1}(i) &= P(o_1,o_2,...,o_t,o_{t+1},i_{t+1}=q_i|\lambda) \\ &= P(o_1,o_2,...,o_t,i_{t+1}=q_i|\lambda)\cdot P(o_{t+1}|o_1,o_2,...,o_t,i_{t+1} = q_i|\lambda) \\ &= [\sum_{j=1} P(o_1,o_2,...,o_t,i_t=q_j,i_{t+1}=q_i|\lambda)]\cdot P(o_{t+1}|i_{t+1}=q_i) \\ &= [\sum_{j=1}P(o_1,o_2,...,o_t,i_t=q_j|\lambda)\cdot P(i_{t+1}=q_i|o_1,o_2,...,o_t,i_t=q_j,\lambda)]\cdot b_i(o_{t+1}) \\ &= [\sum_{j=1}\alpha_t(j)\cdot P(i_{t+1}=q_i|i_t=q_j,\lambda)]\cdot b_i(o_{t+1}) \\ &= [\sum_{j=1}\alpha_t(j)\cdot a_{ji}]\cdot b_i(o_{t+1}) \end{aligned} αt+1(i)=P(o1,o2,...,ot,ot+1,it+1=qi∣λ)=P(o1,o2,...,ot,it+1=qi∣λ)⋅P(ot+1∣o1,o2,...,ot,it+1=qi∣λ)=[j=1∑P(o1,o2,...,ot,it=qj,it+1=qi∣λ)]⋅P(ot+1∣it+1=qi)=[j=1∑P(o1,o2,...,ot,it=qj∣λ)⋅P(it+1=qi∣o1,o2,...,ot,it=qj,λ)]⋅bi(ot+1)=[j=1∑αt(j)⋅P(it+1=qi∣it=qj,λ)]⋅bi(ot+1)=[j=1∑αt(j)⋅aji]⋅bi(ot+1)
(3)终止
P ( O ∣ λ ) = ∑ i α T ( i ) P(O|\lambda) = \sum_{i}\alpha_T(i) P(O∣λ)=i∑αT(i)
算法实现
定义观测数据和 λ \lambda λ参数( π , A , B \pi,A,B π,A,B)
import numpy as np
O = [1,1,0,0,1]
Pi= [0.25,0.25,0.25,0.25]
A = [
[0, 1, 0, 0 ],
[0.4,0,0.6,0],
[0,0.4,0,0.6],
[0,0,0.5,0.5]
]
B = [
[0.5,0.5],
[0.3,0.7],
[0.6,0.4],
[0.8,0.2]
]
定义模型
class ForwardModel:
def __init__(self,Pi,A,B) -> None:
self.Pi = Pi
self.A = A
self.B = B
self.T = len(A)
def predict(self,O):
alpha = np.zeros(shape=(self.T,),dtype=float)
# 初值
for i in range(self.T):
alpha[i] = self.Pi[i]*self.B[i][O[0]]
# 递推
for observation in O:
temp = np.zeros_like(alpha)
for i in range(self.T):
for j in range(self.T):
temp[i] += alpha[j]*self.A[j][i]
temp[i] = temp[i]*self.B[i][observation]
alpha = temp
# 终止
return np.sum(alpha)
预测
model = ForwardModel(Pi,A,B)
model.predict(O)
0.01164323808
读者可自行验证是否正确
后向算法
定义后向概率为
β t ( i ) = P ( o t + 1 , o t + 2 , ⋯ , o T ∣ i t = q i , λ ) \beta_{t}(i)=P\left(o_{t+1}, o_{t+2}, \cdots, o_{T} \mid i_{t}=q_{i}, \lambda\right) βt(i)=P(ot+1,ot+2,⋯,oT∣it=qi,λ)
那么
P ( O ∣ λ ) = P ( o 1 , o 2 , . . . , o T ∣ λ ) = ∑ i = 1 N P ( o 1 , o 2 , . . . , o T , i 1 = q i ∣ λ ) = ∑ i = 1 N P ( o 1 ∣ o 2 , . . . , o T , i 1 = q i , λ ) ⋅ P ( o 2 , . . . , o T , i 1 = q i ∣ λ ) = ∑ i = 1 N P ( o 1 ∣ i 1 = q i , λ ) ⋅ P ( o 2 , . . . , o T ∣ i 1 = q i , λ ) ⋅ P ( i 1 = q i ∣ λ ) = ∑ i = 1 N b i ( o 1 ) ⋅ β 1 ( i ) ⋅ π i \begin{aligned} P(O|\lambda) &= P(o_1,o_2,...,o_T|\lambda) \\ &=\sum_{i=1}^{N}P(o_1,o_2,...,o_T,i_1=q_i|\lambda) \\ &=\sum_{i=1}^{N}P(o_1|o_2,...,o_T,i_1=q_i,\lambda)\cdot P(o_2,...,o_T,i_1=q_i|\lambda) \\ &=\sum_{i=1}^{N}P(o_1|i_1=q_i,\lambda)\cdot P(o_2,...,o_T|i_1=q_i,\lambda)\cdot P(i_1=q_i|\lambda) \\ &=\sum_{i=1}^{N}b_i(o_1)\cdot \beta_1(i)\cdot \pi_i \end{aligned} P(O∣λ)=P(o1,o2,...,oT∣λ)=i=1∑NP(o1,o2,...,oT,i1=qi∣λ)=i=1∑NP(o1∣o2,...,oT,i1=qi,λ)⋅P(o2,...,oT,i1=qi∣λ)=i=1∑NP(o1∣i1=qi,λ)⋅P(o2,...,oT∣i1=qi,λ)⋅P(i1=qi∣λ)=i=1∑Nbi(o1)⋅β1(i)⋅πi
算法过程
(1)初值
β T ( i ) = 1 \beta_T(i) = 1 βT(i)=1
(2)递推
β t ( i ) = P ( o t + 1 , o t + 2 , ⋯ , o T ∣ i t = q i , λ ) = ∑ j = 1 N P ( o t + 1 , o t + 2 , ⋯ , o T , i t + 1 = q j ∣ i t = q i , λ ) = ∑ j = 1 N P ( o t + 1 , o t + 2 , ⋯ , o T ∣ i t + 1 = q j , i t = q i , λ ) ⋅ P ( i t + 1 = q j ∣ i t = q i , λ ) = ∑ j = 1 N P ( o t + 1 , o t + 2 , ⋯ , o T ∣ i t + 1 = q j , i t = q i , λ ) ⋅ α i j \begin{aligned} \beta_{t}(i) &= P\left(o_{t+1}, o_{t+2}, \cdots, o_{T} \mid i_{t}=q_{i}, \lambda\right) \\ &=\sum_{j=1}^N P\left(o_{t+1}, o_{t+2}, \cdots, o_{T},i_{t+1}=q_j \mid i_{t}=q_{i}, \lambda\right) \\ &=\sum_{j=1}^N P\left(o_{t+1}, o_{t+2}, \cdots, o_{T}\mid i_{t+1}=q_j,i_{t}=q_{i}, \lambda\right)\cdot P(i_{t+1}=q_j|i_t=q_i,\lambda) \\ &=\sum_{j=1}^N P\left(o_{t+1}, o_{t+2}, \cdots, o_{T}\mid i_{t+1}=q_j,i_{t}=q_{i}, \lambda\right)\cdot \alpha_{ij} \end{aligned} βt(i)=P(ot+1,ot+2,⋯,oT∣it=qi,λ)=j=1∑NP(ot+1,ot+2,⋯,oT,it+1=qj∣it=qi,λ)=j=1∑NP(ot+1,ot+2,⋯,oT∣it+1=qj,it=qi,λ)⋅P(it+1=qj∣it=qi,λ)=j=1∑NP(ot+1,ot+2,⋯,oT∣it+1=qj,it=qi,λ)⋅αij
接下来这个步骤很关键,根据概率图模型。。。(挖个坑,这儿差个证明)
β t ( i ) = ∑ j = 1 N P ( o t + 1 , . . . o T ∣ i t + 1 = q j , λ ) ⋅ α i j = ∑ j = 1 N P ( o t + 2 , . . . o T ∣ i t + 1 = q j , λ ) ⋅ P ( o t + 1 ∣ o t + 2 , . . . o T , i t + 1 = q j , λ ) ⋅ α i j = ∑ j = 1 N β t + 1 ( j ) ⋅ b j ( o t + 1 ) ⋅ α i j \begin{aligned} \beta_t(i) &= \sum_{j=1}^{N}P(o_{t+1},...o_T|i_{t+1}=q_j,\lambda)\cdot \alpha_{ij} \\ &=\sum_{j=1}^{N}P(o_{t+2},...o_T|i_{t+1}=q_j,\lambda)\cdot P(o_{t+1}|o_{t+2},...o_T,i_{t+1}=q_j,\lambda) \cdot \alpha_{ij} \\ &= \sum_{j=1}^{N}\beta_{t+1}(j)\cdot b_j(o_{t+1})\cdot \alpha_{ij} \end{aligned} βt(i)=j=1∑NP(ot+1,...oT∣it+1=qj,λ)⋅αij=j=1∑NP(ot+2,...oT∣it+1=qj,λ)⋅P(ot+1∣ot+2,...oT,it+1=qj,λ)⋅αij=j=1∑Nβt+1(j)⋅bj(ot+1)⋅αij
(3)终止
P ( O ∣ λ ) = ∑ i = 1 N b i ( o 1 ) ⋅ β 1 ( i ) ⋅ π i \begin{aligned} P(O|\lambda) =\sum_{i=1}^{N}b_i(o_1)\cdot \beta_1(i)\cdot \pi_i \end{aligned} P(O∣λ)=i=1∑Nbi(o1)⋅β1(i)⋅πi
(ps 如果你都看到这儿了,可以要一个点赞吗)
算法实现
数据和参数定义部分与上面一致,略
定义模型
class BackwardModel:
def __init__(self,Pi,A,B) -> None:
self.Pi = Pi
self.A = A
self.B = B
self.T = len(A)
def predict(self,O):
# 初值
beta = np.ones(shape=(self.T,))
# 递推
for o in reversed(O):
temp = np.zeros_like(beta)
for i in range(self.T):
for j in range(self.T):
temp[i] += beta[j]*B[j][o]*A[i][j]
beta = temp
# 终止
res = 0
for i in range(self.T):
res += B[i][O[0]]*beta[i]*Pi[i]
return res
预测
model = BackwardModel(Pi,A,B)
model.predict(O)
0.01164323808
我们看到这跟前面使用前向算法得出的预测值是相同的
二、学习问题(Learning)
Baum-Welch算法
事实上,Baum-Welch算法是EM算法在HMM学习问题中的应用
我们要求的 λ \lambda λ应该满足
λ = a r g m a x λ P ( O ∣ λ ) \lambda = \underset{\lambda}{argmax} P(O|\lambda) λ=λargmaxP(O∣λ)
我们还是先把EM算法的公式写出来先
θ t + 1 = a r g m a x θ ∫ z l o g P ( X , Z ∣ θ ) ⋅ P ( Z ∣ X , θ ) d z \theta^{t+1} = \underset{\theta}{argmax}\int_zlogP(X,Z|\theta)\cdot P(Z|X,\theta)dz θt+1=θargmax∫zlogP(X,Z∣θ)⋅P(Z∣X,θ)dz
其中Z表示隐变量,X表示观测变量,那在HMM中,隐变量是I,观测变量是O,且是离散的
λ t + 1 = a r g m a x θ ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( I ∣ O , λ t ) = a r g m a x θ ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( O , I ∣ λ t ) P ( O ∣ λ t ) = a r g m a x θ 1 P ( O ∣ λ t ) ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( O , I ∣ λ t ) = a r g m a x θ ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( O , I ∣ λ t ) \begin{aligned} \lambda^{t+1} &= \underset{\theta}{argmax}\sum_{I}logP(O,I|\lambda)\cdot P(I|O,\lambda^t) \\ &= \underset{\theta}{argmax}\sum_{I}logP(O,I|\lambda)\cdot \frac{P(O,I|\lambda^t)}{P(O|\lambda^t)} \\ &= \underset{\theta}{argmax}\frac{1}{P(O|\lambda^t)}\sum_{I}logP(O,I|\lambda)\cdot P(O,I|\lambda^t) \\ &= \underset{\theta}{argmax}\sum_{I}logP(O,I|\lambda)\cdot P(O,I|\lambda^t) \\ \end{aligned} λt+1=θargmaxI∑logP(O,I∣λ)⋅P(I∣O,λt)=θargmaxI∑logP(O,I∣λ)⋅P(O∣λt)P(O,I∣λt)=θargmaxP(O∣λt)1I∑logP(O,I∣λ)⋅P(O,I∣λt)=θargmaxI∑logP(O,I∣λ)⋅P(O,I∣λt)
其中
F ( T ) = P ( O , I ∣ λ ) = P ( o 1 , o 2 , . . . , o T , i 1 , i 2 , . . . , i T ∣ λ ) = P ( o T ∣ o 1 , o 2 , . . . , o T − 1 , i 1 , i 2 , . . . , i T , λ ) ⋅ P ( o 1 , o 2 , . . . , o T − 1 , i 1 , i 2 , . . . , i T ∣ λ ) = P ( o T ∣ i T , λ ) ⋅ P ( o 1 , o 2 , . . . , o T − 1 , i 1 , i 2 , . . . , i T − 1 ∣ λ ) ⋅ P ( i T ∣ o 1 , o 2 , . . . , o T − 1 , i 1 , i 2 , . . . i T − 1 , λ ) = b i T ( o T ) ⋅ F ( T − 1 ) ⋅ α i T − 1 i T \begin{aligned} F(T) = P(O,I\mid \lambda) &= P(o_1,o_2,...,o_T,i_1,i_2,...,i_T|\lambda) \\ &= P(o_T\mid o_1,o_2,...,o_{T-1},i_1,i_2,...,i_T,\lambda)\cdot P(o_1,o_2,...,o_{T-1},i_1,i_2,...,i_T|\lambda) \\ &= P(o_T\mid i_T,\lambda)\cdot P(o_1,o_2,...,o_{T-1},i_1,i_2,...,i_{T-1}|\lambda)\cdot P(i_T|o_1,o_2,...,o_{T-1},i_1,i_2,...i_{T-1},\lambda) \\ &= b_{i_T}(o_T)\cdot F(T-1)\cdot \alpha_{i_{T-1}i_T} \end{aligned} F(T)=P(O,I∣λ)=P(o1,o2,...,oT,i1,i2,...,iT∣λ)=P(oT∣o1,o2,...,oT−1,i1,i2,...,iT,λ)⋅P(o1,o2,...,oT−1,i1,i2,...,iT∣λ)=P(oT∣iT,λ)⋅P(o1,o2,...,oT−1,i1,i2,...,iT−1∣λ)⋅P(iT∣o1,o2,...,oT−1,i1,i2,...iT−1,λ)=biT(oT)⋅F(T−1)⋅αiT−1iT
故(简单的等比数列)
F ( T ) = ∏ t = 2 T b i t ( o t ) ⋅ α i t − 1 i t ⋅ F ( 1 ) = [ ∏ t = 2 T b i t ( o t ) ⋅ α i t − 1 i t ] ⋅ P ( o 1 , i 1 ∣ λ ) = [ ∏ t = 2 T b i t ( o t ) ⋅ α i t − 1 i t ] ⋅ P ( o 1 ∣ i 1 , λ ) ⋅ P ( i 1 ∣ λ ) = [ ∏ t = 2 T b i t ( o t ) ⋅ α i t − 1 i t ] ⋅ b i 1 ( o 1 ) ⋅ π i 1 = [ ∏ t = 1 T b i t ( o t ) ] ⋅ [ ∏ t = 2 T α i t − 1 i t ] ⋅ π i 1 \begin{aligned} F(T) &= \prod_{t=2}^{T}b_{i_t}(o_t)\cdot \alpha_{i_{t-1}i_t}\cdot F(1) \\ &= [\prod_{t=2}^{T}b_{i_t}(o_t)\cdot \alpha_{i_{t-1}i_t}]\cdot P(o_1,i_1\mid \lambda) \\ &= [\prod_{t=2}^{T}b_{i_t}(o_t)\cdot \alpha_{i_{t-1}i_t}]\cdot P(o_1\mid i_1,\lambda)\cdot P(i_1\mid \lambda) \\ &= [\prod_{t=2}^{T}b_{i_t}(o_t)\cdot \alpha_{i_{t-1}i_t}]\cdot b_{i_1}(o_1)\cdot \pi_{i_1} \\ &= [\prod_{t=1}^{T}b_{i_t}(o_t)]\cdot [\prod_{t=2}^{T}\alpha_{i_{t-1}i_t}]\cdot \pi_{i_1} \\ \end{aligned} F(T)=t=2∏Tbit(ot)⋅αit−1it⋅F(1)=[t=2∏Tbit(ot)⋅αit−1it]⋅P(o1,i1∣λ)=[t=2∏Tbit(ot)⋅αit−1it]⋅P(o1∣i1,λ)⋅P(i1∣λ)=[t=2∏Tbit(ot)⋅αit−1it]⋅bi1(o1)⋅πi1=[t=1∏Tbit(ot)]⋅[t=2∏Tαit−1it]⋅πi1
现在我们已经得到
P ( O , I ∣ λ ) = [ ∏ t = 1 T b i t ( o t ) ] ⋅ [ ∏ t = 2 T α i t − 1 i t ] ⋅ π i 1 P(O,I\mid \lambda) = [\prod_{t=1}^{T}b_{i_t}(o_t)]\cdot [\prod_{t=2}^{T}\alpha_{i_{t-1}i_t}]\cdot \pi_{i_1} P(O,I∣λ)=[t=1∏Tbit(ot)]⋅[t=2∏Tαit−1it]⋅πi1
然后
λ t + 1 = a r g m a x θ ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( O , I ∣ λ t ) = a r g m a x θ ∑ I ( ∑ t = 1 T l o g ( b i t ( o t ) ) + ∑ t = 2 T l o g ( α i t − 1 i t ) + l o g ( π i 1 ) ) ⋅ P ( O , I ∣ λ t ) \begin{aligned} \lambda^{t+1} &= \underset{\theta}{argmax}\sum_{I}logP(O,I|\lambda)\cdot P(O,I|\lambda^t) \\ &= \underset{\theta}{argmax}\sum_{I}(\sum_{t=1}^Tlog(b_{i_t}(o_t))+\sum_{t=2}^{T}log(\alpha_{i_{t-1}i_t})+log(\pi_{i_1}))\cdot P(O,I|\lambda^t) \end{aligned} λt+1=θargmaxI∑logP(O,I∣λ)⋅P(O,I∣λt)=θargmaxI∑(t=1∑Tlog(bit(ot))+t=2∑Tlog(αit−1it)+log(πi1))⋅P(O,I∣λt)
记
Q ( λ , λ t ) = a r g m a x θ ∑ I ( ∑ t = 1 T l o g ( b i t ( o t ) ) + ∑ t = 2 T l o g ( α i t − 1 i t ) + l o g ( π i 1 ) ) ⋅ P ( O , I ∣ λ t ) Q(\lambda,\lambda^t) = \underset{\theta}{argmax}\sum_{I}(\sum_{t=1}^Tlog(b_{i_t}(o_t))+\sum_{t=2}^{T}log(\alpha_{i_{t-1}i_t})+log(\pi_{i_1}))\cdot P(O,I|\lambda^t) Q(λ,λt)=θargmaxI∑(t=1∑Tlog(bit(ot))+t=2∑Tlog(αit−1it)+log(πi1))⋅P(O,I∣λt)
为了求 π t + 1 \pi^{t+1} πt+1,我们需要求 π i t + 1 \pi_i^{t+1} πit+1
在 ∑ i = 1 N π i = 1 \sum_{i=1}^N \pi_i = 1 ∑i=1Nπi=1的约束下,
记拉格朗日函数
L ( π , η ) = ∑ I ( l o g ( π i 1 ) ⋅ P ( O ∣ I , λ t ) ) + η ⋅ ( ∑ i = 1 N π i − 1 ) = ∑ i 1 . . . ∑ i T ( l o g ( π i 1 ) ⋅ P ( O ∣ I , λ t ) ) + η ⋅ ( ∑ i = 1 N π i − 1 ) = ∑ i 1 l o g ( π i 1 ) ⋅ P ( O ∣ i 1 , λ t ) + η ⋅ ( ∑ i = 1 N π i − 1 ) = ∑ i = 1 N l o g ( π i ) ⋅ P ( O ∣ i 1 = q i , λ t ) + η ⋅ ( ∑ i = 1 N π i − 1 ) \begin{aligned} L(\pi,\eta) &= \sum_{I}(log(\pi_{i_1})\cdot P(O|I,\lambda^t)) +\eta\cdot (\sum_{i=1}^N \pi_i-1)\\ &= \sum_{i_1}...\sum_{i_T}(log(\pi_{i_1})\cdot P(O|I,\lambda^t)) +\eta\cdot (\sum_{i=1}^N \pi_i-1)\\ &= \sum_{i_1}log(\pi_{i_1})\cdot P(O|i_1,\lambda^t)+\eta\cdot (\sum_{i=1}^N \pi_i-1) \\ &= \sum_{i=1}^Nlog(\pi_i)\cdot P(O|i_1=q_i,\lambda^t) +\eta\cdot (\sum_{i=1}^N \pi_i-1) \end{aligned} L(π,η)=I∑(log(πi1)⋅P(O∣I,λt))+η⋅(i=1∑Nπi−1)=i1∑...iT∑(log(πi1)⋅P(O∣I,λt))+η⋅(i=1∑Nπi−1)=i1∑log(πi1)⋅P(O∣i1,λt)+η⋅(i=1∑Nπi−1)=i=1∑Nlog(πi)⋅P(O∣i1=qi,λt)+η⋅(i=1∑Nπi−1)
∂ L ∂ π i = P ( O ∣ i 1 = q i , λ t ) π i + η = 0 \begin{aligned} \frac{\partial L}{\partial \pi_i} &= \frac{P(O|i_1=q_i,\lambda^t)}{\pi_i} +\eta = 0 \end{aligned} ∂πi∂L=πiP(O∣i1=qi,λt)+η=0
我们对得到的N个式子求和即可求出 η \eta η
∑ i = 1 N ( P ( O ∣ i 1 = q i , λ t ) + η ⋅ π i ) = ∑ i = 1 N P ( O ∣ i 1 = q i , λ t ) + η = 0 \begin{aligned} \sum_{i=1}^{N}(P(O|i_1=q_i,\lambda^t) +\eta\cdot \pi_i) \\ =\sum_{i=1}^{N}P(O|i_1=q_i,\lambda^t) +\eta = 0 \end{aligned} i=1∑N(P(O∣i1=qi,λt)+η⋅πi)=i=1∑NP(O∣i1=qi,λt)+η=0
得
η = − ∑ i = 1 N P ( O ∣ i 1 = q i , λ t ) = − P ( O ∣ λ t ) \eta = -\sum_{i=1}^{N}P(O|i_1=q_i,\lambda^t) =-P(O|\lambda^t) η=−i=1∑NP(O∣i1=qi,λt)=−P(O∣λt)
得
π i t + 1 = − P ( O ∣ i 1 = q i , λ t ) η = P ( O ∣ i 1 = q i , λ t ) P ( O ∣ λ t ) \pi_i^{t+1} = -\frac{P(O|i_1=q_i,\lambda^t)}{\eta} = \frac{P(O|i_1=q_i,\lambda^t)}{P(O|\lambda^t)} πit+1=−ηP(O∣i1=qi,λt)=P(O∣λt)P(O∣i1=qi,λt)
**为了求 A t + 1 A^{t+1} At+1,我们即需要求 α i j t + 1 \alpha_{ij}^{t+1} αijt+1**
在状态转移矩阵的每一行和为1的约束下,定义拉格朗日函数
L ( α , η ) = ∑ I ( ∑ t = 2 T l o g ( α i t − 1 i t ) ⋅ P ( O ∣ I , λ t ) ) + ∑ i = 1 N η i ⋅ ( ∑ j = 1 N α i j − 1 ) = ∑ i = 1 N ∑ j = 1 N ∑ t = 2 T log a i j P ( O , i t − 1 = i , i t = j ∣ λ t ) + ∑ i = 1 N η i ⋅ ( ∑ j = 1 N α i j − 1 ) \begin{aligned} L(\alpha,\eta) &= \sum_{I}(\sum_{t=2}^{T}log(\alpha_{i_{t-1}i_t})\cdot P(O|I,\lambda^t)) + \sum_{i=1}^{N}\eta_i\cdot (\sum_{j=1}^N \alpha_{ij}-1)\\ &=\sum_{i=1}^{N} \sum_{j=1}^{N} \sum_{t=2}^{T} \log a_{i j} P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right)+\sum_{i=1}^{N}\eta_i\cdot (\sum_{j=1}^N \alpha_{ij}-1)\\ \end{aligned} L(α,η)=I∑(t=2∑Tlog(αit−1it)⋅P(O∣I,λt))+i=1∑Nηi⋅(j=1∑Nαij−1)=i=1∑Nj=1∑Nt=2∑TlogaijP(O,it−1=i,it=j∣λt)+i=1∑Nηi⋅(j=1∑Nαij−1)
然后对 α i j \alpha_{ij} αij求偏导
∂ L ∂ α i j = ∑ t = 2 T P ( O , i t − 1 = i , i t = j ∣ λ t ) α i j + η i = 0 \frac{\partial L}{\partial \alpha_{ij}} = \sum_{t=2}^{T}\frac{P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right)}{\alpha_{ij}}+\eta_i = 0 ∂αij∂L=t=2∑TαijP(O,it−1=i,it=j∣λt)+ηi=0
∑ t = 2 T P ( O , i t − 1 = i , i t = j ∣ λ t ) + η i ⋅ α i j = 0 \sum_{t=2}^{T}P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right) + \eta_i\cdot \alpha_{ij} = 0 t=2∑TP(O,it−1=i,it=j∣λt)+ηi⋅αij=0
我们对j求和
∑ j = 1 N ∑ t = 2 T P ( O , i t − 1 = i , i t = j ∣ λ t ) + η i ⋅ ∑ j = 1 N α i j = 0 \sum_{j=1}^{N}\sum_{t=2}^{T}P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right)+\eta_i\cdot \sum_{j=1}^N \alpha_{ij} = 0 j=1∑Nt=2∑TP(O,it−1=i,it=j∣λt)+ηi⋅j=1∑Nαij=0
得到
η i = − ∑ j = 1 N ∑ t = 2 T P ( O , i t − 1 = q i , i t = q j ∣ λ t ) = ∑ t = 2 T P ( O , i t − 1 = q i ∣ λ t ) \eta_i = -\sum_{j=1}^{N}\sum_{t=2}^{T}P\left(O, i_{t-1}=q_i, i_{t}=q_j \mid \lambda^t\right) = \sum_{t=2}^{T}P(O,i_{t-1}=q_i|\lambda^t) ηi=−j=1∑Nt=2∑TP(O,it−1=qi,it=qj∣λt)=t=2∑TP(O,it−1=qi∣λt)
故
α i j t + 1 = − ∑ t = 2 T P ( O , i t − 1 = i , i t = j ∣ λ t ) η i = ∑ t = 2 T P ( O , i t − 1 = i , i t = j ∣ λ t ) ∑ t = 2 T P ( O , i t − 1 = q i ∣ λ t ) \begin{aligned} \alpha_{ij}^{t+1} &= -\frac{\sum_{t=2}^{T}P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right)}{\eta_i} \\ &=\frac{\sum_{t=2}^{T}P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right)}{\sum_{t=2}^{T}P(O,i_{t-1}=q_i|\lambda^t)} \end{aligned} αijt+1=−ηi∑t=2TP(O,it−1=i,it=j∣λt)=∑t=2TP(O,it−1=qi∣λt)∑t=2TP(O,it−1=i,it=j∣λt)
故
A t + 1 = [ α i j t + 1 ] N × N A^{t+1} = [\alpha_{ij}^{t+1}]_{N\times N} At+1=[αijt+1]N×N
为了求 B t + 1 B^{t+1} Bt+1,我们需要求 b j ( k ) t + 1 b_j(k)^{t+1} bj(k)t+1
在每行和为1的约束下,得到拉格朗日函数如下
L ( b , η ) = ∑ I [ ∑ t = 1 T l o g ( b i t ( o t ) ) ] ⋅ P ( O , I ∣ λ t ) + ∑ j = 1 N η j ⋅ [ ∑ k = 1 M b j ( k ) − 1 ] = ∑ j = 1 N ∑ t = 1 T log b j ( o t ) P ( O , i t = q j ∣ λ t ) + ∑ j = 1 N η j ⋅ [ ∑ k = 1 M b j ( k ) − 1 ] \begin{aligned} L(b,\eta) &= \sum_{I}[\sum_{t=1}^Tlog(b_{i_t}(o_t))]\cdot P(O,I|\lambda^t) + \sum_{j=1}^{N}\eta_j\cdot [\sum_{k=1}^{M}b_j(k)-1]\\ &=\sum_{j=1}^{N} \sum_{t=1}^{T} \log b_{j}\left(o_{t}\right) P(O, i_{t}=q_j \mid \lambda^t)+\sum_{j=1}^{N}\eta_j\cdot [\sum_{k=1}^{M}b_j(k)-1]\\ \end{aligned} L(b,η)=I∑[t=1∑Tlog(bit(ot))]⋅P(O,I∣λt)+j=1∑Nηj⋅[k=1∑Mbj(k)−1]=j=1∑Nt=1∑Tlogbj(ot)P(O,it=qj∣λt)+j=1∑Nηj⋅[k=1∑Mbj(k)−1]
然后对 b j ( k ) b_j(k) bj(k)求偏导
∂ L ∂ b j ( k ) = ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) b j ( k ) + η j = 0 \begin{aligned} \frac{\partial L}{\partial b_j(k)} = \sum_{t=1}^{T}\frac{P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k)}{b_j(k)}+\eta_j = 0 \end{aligned} ∂bj(k)∂L=t=1∑Tbj(k)P(O,it=qj∣λt)⋅I(ot=vk)+ηj=0
∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) + η j ⋅ b j ( k ) = 0 \sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k)+\eta_j\cdot b_j(k)= 0 t=1∑TP(O,it=qj∣λt)⋅I(ot=vk)+ηj⋅bj(k)=0
对k求和
∑ k = 1 M ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) + η j = 0 \sum_{k=1}^{M}\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k)+\eta_j = 0 k=1∑Mt=1∑TP(O,it=qj∣λt)⋅I(ot=vk)+ηj=0
得
η j = − ∑ k = 1 M ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) = ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ∑ k = 1 M I ( o t = v k ) = ∑ t = 1 T P ( O , i t = q j ∣ λ t ) \begin{aligned} \eta_j &= -\sum_{k=1}^{M}\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k) \\ &=\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\sum_{k=1}^MI(o_t=v_k) \\ &=\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t) \end{aligned} ηj=−k=1∑Mt=1∑TP(O,it=qj∣λt)⋅I(ot=vk)=t=1∑TP(O,it=qj∣λt)k=1∑MI(ot=vk)=t=1∑TP(O,it=qj∣λt)
从而得
b j ( k ) t + 1 = − ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) η j = ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) ∑ t = 1 T P ( O , i t = q j ∣ λ t ) \begin{aligned} b_j(k)^{t+1} &= -\frac{\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k)}{\eta_j} \\ &=\frac{\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k)}{\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)} \end{aligned} bj(k)t+1=−ηj∑t=1TP(O,it=qj∣λt)⋅I(ot=vk)=∑t=1TP(O,it=qj∣λt)∑t=1TP(O,it=qj∣λt)⋅I(ot=vk)
综上,得到递推式如下:
π i t + 1 = P ( O ∣ i 1 = q i , λ t ) P ( O ∣ λ t ) α i j t + 1 = ∑ t = 2 T P ( O , i t − 1 = i , i t = j ∣ λ t ) ∑ t = 2 T P ( O , i t − 1 = q i ∣ λ t ) b j ( k ) t + 1 = ∑ t = 1 T P ( O , i t = q j ∣ λ t ) ⋅ I ( o t = v k ) ∑ t = 1 T P ( O , i t = q j ∣ λ t ) \begin{aligned} &\pi_i^{t+1} = \frac{P(O|i_1=q_i,\lambda^t)}{P(O|\lambda^t)} \\ \\ &\alpha_{ij}^{t+1} =\frac{\sum_{t=2}^{T}P\left(O, i_{t-1}=i, i_{t}=j \mid \lambda^t\right)}{\sum_{t=2}^{T}P(O,i_{t-1}=q_i|\lambda^t)} \\ \\ &b_j(k)^{t+1} = \frac{\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)\cdot I(o_t=v_k)}{\sum_{t=1}^{T}P(O,i_t=q_j\mid \lambda^t)} \end{aligned} πit+1=P(O∣λt)P(O∣i1=qi,λt)αijt+1=∑t=2TP(O,it−1=qi∣λt)∑t=2TP(O,it−1=i,it=j∣λt)bj(k)t+1=∑t=1TP(O,it=qj∣λt)∑t=1TP(O,it=qj∣λt)⋅I(ot=vk)
定义
ξ t ( i , j ) = p ( O , i t = q i , i t + 1 = q j ∣ λ t ) P ( O ∣ λ t ) \begin{aligned} \xi_t(i,j) = \frac{p(O,i_{t}=q_i,i_{t+1}=q_j|\lambda^t)}{P(O|\lambda^t)} \end{aligned} ξt(i,j)=P(O∣λt)p(O,it=qi,it+1=qj∣λt)
γ t ( i ) = P ( O ∣ i t = q i , λ t ) P ( O ∣ λ t ) \gamma_t(i) = \frac{P(O|i_t=q_i,\lambda^t)}{P(O|\lambda^t)} γt(i)=P(O∣λt)P(O∣it=qi,λt)
于是
π i t + 1 = γ 1 ( i ) α i j t + 1 = ∑ t = 1 T − 1 ξ t ( i , j ) ∑ 1 T − 1 γ t ( i ) b j ( k ) t + 1 = ∑ t = 1 T γ t ( j ) ⋅ I ( o t = v k ) ∑ t = 1 T γ t ( j ) \begin{aligned} &\pi_i^{t+1} =\gamma_1(i) \\ \\ &\alpha_{ij}^{t+1} =\frac{\sum_{t=1}^{T-1}\xi_t(i,j)}{\sum_{1}^{T-1}\gamma_t(i)} \\ \\ &b_j(k)^{t+1} = \frac{\sum_{t=1}^{T}\gamma_t(j)\cdot I(o_t=v_k)}{\sum_{t=1}^{T}\gamma_t(j)} \end{aligned} πit+1=γ1(i)αijt+1=∑1T−1γt(i)∑t=1T−1ξt(i,j)bj(k)t+1=∑t=1Tγt(j)∑t=1Tγt(j)⋅I(ot=vk)
算法过程总结
(1)初始化
选取 α i j 0 , b j ( k ) 0 , π i 0 \alpha_{ij}^0,b_j(k)^0,\pi_i^0 αij0,bj(k)0,πi0
(2)递推
π i t + 1 = γ 1 ( i ) α i j t + 1 = ∑ t = 1 T − 1 ξ t ( i , j ) ∑ 1 T − 1 γ t ( i ) b j ( k ) t + 1 = ∑ t = 1 T γ t ( j ) ⋅ I ( o t = v k ) ∑ t = 1 T γ t ( j ) \begin{aligned} &\pi_i^{t+1} =\gamma_1(i) \\ \\ &\alpha_{ij}^{t+1} =\frac{\sum_{t=1}^{T-1}\xi_t(i,j)}{\sum_{1}^{T-1}\gamma_t(i)} \\ \\ &b_j(k)^{t+1} = \frac{\sum_{t=1}^{T}\gamma_t(j)\cdot I(o_t=v_k)}{\sum_{t=1}^{T}\gamma_t(j)} \end{aligned} πit+1=γ1(i)αijt+1=∑1T−1γt(i)∑t=1T−1ξt(i,j)bj(k)t+1=∑t=1Tγt(j)∑t=1Tγt(j)⋅I(ot=vk)
(3)终止
得到模型参数 λ T = ( π i T , A T , B T ) \lambda^T = (\pi_i^T,A^T,B^T) λT=(πiT,AT,BT)
算法实现
我们还是以盒子和球模型为例
生成观测序列
def generate(T):
boxes = [
[0,0,0,0,0,1,1,1,1,1],
[0,0,0,1,1,1,1,1,1,1],
[0,0,0,0,0,0,1,1,1,1],
[0,0,0,0,0,0,0,0,1,1]
]
I = []
O = []
# 第一步,选择一个盒子
index = np.random.choice(len(boxes))
for t in range(T):
I.append(index)
# 第二步,抽球
O.append(np.random.choice(boxes[index]))
# 第三步,重新选择盒子
if index==0:
index = 1
elif index==1 or index==2:
index = np.random.choice([index-1,index-1,index+1,index+1,index+1])
elif index==3:
index = np.random.choice([index,index-1])
return I,O
定义模型
class Model:
def __init__(self,M,N) -> None:
# 状态集合
self.N = N
# 观测集合
self.M = M
def _gamma(self,t,i):
return self.alpha[t][i]*self.beta[t][i]/np.sum(self.alpha[t]*self.beta[t])
def _xi(self,t,i,j):
fenmu = 0
for i1 in range(self.N):
for j1 in range(self.N):
fenmu += self.alpha[t][i1]*self.A[i1][j1]*self.B[j1][self.O[t+1]]*self.beta[t+1][j1]
return (self.alpha[t][i]*self.A[i][j]*self.B[j][self.O[t+1]]*self.beta[t+1][j])/fenmu
def backward(self):
# 初值
self.beta = np.ones(shape=(self.T,self.N))
# 递推
for t in reversed(range(1,self.T)):
for i in range(self.N):
for j in range(self.N):
self.beta[t-1][i] += self.beta[t][j]*self.B[j][self.O[t]]*self.A[i][j]
def forward(self):
self.alpha = np.zeros(shape=(self.T,self.N),dtype=float)
# 初值
for i in range(self.N):
self.alpha[0][i] = self.pi[i]*self.B[i][self.O[0]]
# 递推
for t in range(self.T-1):
for i in range(self.N):
for j in range(self.N):
self.alpha[t+1][i] += self.alpha[t][j]*self.A[j][i]
self.alpha[t+1][i] = self.alpha[t+1][i]*self.B[i][self.O[t]]
def train(self,O,max_iter=100,toler=1e-5):
self.O = O
self.T = len(O)
# 初始化
# pi是一个N维的向量
self.pi = np.ones(shape=(self.N,))/self.N
# A是一个NxN的矩阵
self.A = np.ones(shape=(self.N,self.N))/self.N
# B是一个NxM的矩阵
self.B = np.ones(shape=(self.N,self.M))/self.M
# pi是一个N维的向量
pi = np.ones(shape=(self.N,))/self.N
# A是一个NxN的矩阵
A = np.ones(shape=(self.N,self.N))/self.N
# B是一个NxM的矩阵
B = np.ones(shape=(self.N,self.M))/self.M
## 递推
for epoch in range(max_iter):
# 计算前向概率和后向概率
self.forward()
self.backward()
# 计算gamma
for i in range(self.N):
pi[i] = self._gamma(1,i)
for j in range(self.N):
fenzi = 0
fenmu = 0
for t2 in range(self.T-1):
fenzi += self._xi(t2,i,j)
fenmu += self._gamma(t2,j)
A[i][j] = fenzi/fenmu
for j in range(self.N):
for k in range(self.M):
fenzi = 0
fenmu = 0
for t2 in range(self.T):
fenzi += self._gamma(t2,j)*(self.O[t2]==k)
fenmu += self._gamma(t2,j)
B[j][k] = fenzi/fenmu
if np.max(abs(self.pi - pi)) < toler and \
np.max(abs(self.A - A)) < toler and \
np.max(abs(self.B - B)) < toler:
self.pi = pi
self.A = A
self.B = B
return pi,A,B
self.pi = pi.copy()
self.A = A.copy()
self.B = B.copy()
return self.pi,self.A,self.B
def predict(self,O):
self.O = O
self.T = len(O)
self.forward()
return np.sum(self.alpha[self.T-1])
训练
model = Model(2,4)
model.train(O,toler=1e-10)
输出如下
(array([0.25, 0.25, 0.25, 0.25]),
array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]]),
array([[0.625, 0.375],
[0.625, 0.375],
[0.625, 0.375],
[0.625, 0.375]]))
完全不对劲,但是可以理解。
监督式学习算法-极大似然估计
推导过Baum-Welch算法之后推导极大似然估计就轻松很多了
假设我们的样本如下
{ ( O 1 , I 1 ) , ( O 2 , I 2 ) , ⋯ , ( O S , I S ) } \left\{\left(O_{1}, I_{1}\right),\left(O_{2}, I_{2}\right), \cdots,\left(O_{S}, I_{S}\right)\right\} {
(O1,I1),(O2,I2),⋯,(OS,IS)}
根据极大似然估计则有
λ ^ = a r g m a x λ P ( O , I ∣ λ ) = a r g m a x λ ∏ j = 1 S P ( O j , I j ∣ λ ) = a r g m a x λ ∑ j = 1 S l o g P ( O j , I j ∣ λ ) = a r g m a x λ ∑ j = 1 S l o g ( ∏ t = 1 T b i t j ( o t ) ⋅ ∏ t = 2 T α i t − 1 t t j ⋅ π i 1 j ) = a r g m a x λ ∑ j = 1 S [ ∑ t = 1 T l o g ( b i t j ( o t ) ) + ∑ t = 2 T l o g ( α i t − 1 t t j ) + l o g ( π i 1 j ) ] \begin{aligned} \hat\lambda &= \underset{\lambda}{argmax}\ P(O,I|\lambda) \\ &= \underset{\lambda}{argmax}\ \prod_{j=1}^{S}P(O_j,I_j|\lambda) \\ &= \underset{\lambda}{argmax}\ \sum_{j=1}^{S}logP(O_j,I_j|\lambda) \\ &= \underset{\lambda}{argmax}\ \sum_{j=1}^{S}log\left(\prod_{t=1}^{T}b_{i_t}^j(o_t)\cdot \prod_{t=2}^{T}\alpha_{i_{t-1}t_t}^j\cdot \pi_{i_1}^j\right) \\ &=\underset{\lambda}{argmax}\ \sum_{j=1}^{S}\left[\sum_{t=1}^{T}log(b_{i_t}^j(o_t))+ \sum_{t=2}^{T}log(\alpha_{i_{t-1}t_t}^j)+log(\pi_{i_1}^j)\right] \\ \end{aligned} λ^=λargmax P(O,I∣λ)=λargmax j=1∏SP(Oj,Ij∣λ)=λargmax j=1∑SlogP(Oj,Ij∣λ)=λargmax j=1∑Slog(t=1∏Tbitj(ot)⋅t=2∏Tαit−1ttj⋅πi1j)=λargmax j=1∑S[t=1∑Tlog(bitj(ot))+t=2∑Tlog(αit−1ttj)+log(πi1j)]
我们先估计 π \pi π(i1省略不写),与 π \pi π相关的只有最后一项
π ^ = a r g m a x π ∑ j = 1 S log π j \hat{\pi}=\underset{\pi}{argmax} \sum_{j=1}^{S} \log \pi^{j} π^=πargmaxj=1∑Slogπj
对 π \pi π有约束
∑ i = 1 N π i = 1 \sum_{i=1}^{N}\pi_i = 1 i=1∑Nπi=1
记拉格朗日函数
L ( π , η ) = ∑ j = 1 S log π j + η ⋅ ( ∑ i = 1 N π i − 1 ) L(\pi, \eta)=\sum_{j=1}^{S} \log \pi^{j}+\eta \cdot\left(\sum_{i=1}^{N} \pi_i-1\right) L(π,η)=j=1∑Slogπj+η⋅(i=1∑Nπi−1)
对 π i \pi_i πi求偏导
∂ L ∂ π i = ∑ j = 1 S I ( I 1 j = i ) π i + η = 0 \frac{\partial L}{\partial \pi_{i}}=\frac{\sum_{j=1}^{S} I\left(I_{1 j}=i\right)}{\pi_{i}}+\eta=0 ∂πi∂L=πi∑j=1SI(I1j=i)+η=0
即
∑ j = 1 S I ( I 1 j = i ) + η ⋅ π i = 0 \sum_{j=1}^{S} I\left(I_{1 j}=i\right) + \eta \cdot \pi_i = 0 j=1∑SI(I1j=i)+η⋅πi=0
对i求和
∑ i = 1 N ∑ j = 1 S I ( I 1 j = i ) + η ⋅ ∑ i = 1 N π i = 0 \sum_{i=1}^{N}\sum_{j=1}^{S}I(I_{1j}=i) + \eta \cdot \sum_{i=1}^{N}\pi_i = 0 i=1∑Nj=1∑SI(I1j=i)+η⋅i=1∑Nπi=0
即
∑ j = 1 S ∑ i = 1 N I ( I 1 j = i ) + η = 0 ∑ j = 1 S ∑ i = 1 N I ( I 1 j = i ) + η = 0 ∑ j = 1 S 1 + η = 0 η = − S \begin{aligned} &\sum_{j=1}^{S}\sum_{i=1}^{N}I(I_{1j}=i) + \eta = 0 \\ &\sum_{j=1}^{S}\sum_{i=1}^{N}I(I_{1j}=i) + \eta = 0 \\ &\sum_{j=1}^{S}1 +\eta = 0 \\ &\eta = -S \end{aligned} j=1∑Si=1∑NI(I1j=i)+η=0j=1∑Si=1∑NI(I1j=i)+η=0j=1∑S1+η=0η=−S
所以
π ^ i = − ∑ j = 1 S I ( I 1 j = i ) η = ∑ j = 1 S I ( I 1 j = i ) S \hat \pi_i = -\frac{\sum_{j=1}^{S} I\left(I_{1 j}=i\right)}{\eta} = \frac{\sum_{j=1}^{S} I\left(I_{1 j}=i\right)}{S} π^i=−η∑j=1SI(I1j=i)=S∑j=1SI(I1j=i)
剩下A,B的推导过程,请允许我贴两张图,打公式打烦了


图里面写的有一些问题,希望读者阅读过程中可以自行发现,如果阅读的时候没发现,你看到下面也会发现的
于是我们得到最终估计为
π ^ i = ∑ j = 1 S I ( i 1 j = q i ) S α ^ i j = ∑ k = 1 S ∑ t = 1 T − 1 I ( i t k = q i , i t + 1 k = q j ) ∑ k = 1 S ∑ t = 1 T − 1 I ( i t k = q i ) b ^ j ( k ) = ∑ i = 1 S ∑ t = 1 T I ( i t i = q j , o t i = v k ) ∑ i = 1 S ∑ t = 1 T I ( i t i = q j ) \begin{aligned} &\hat \pi_i = \frac{\sum_{j=1}^{S} I\left(i_1^j=q_i\right)}{S} \\ &\hat \alpha_{ij} = \frac{\sum_{k=1}^{S} \sum_{t=1}^{T-1} I\left(i_{t}^k=q_i, i_{t+1}^k=q_j\right)}{\sum_{k=1}^{S} \sum_{t=1}^{T-1} I\left(i_{t}^k=q_i\right)} \\ &\hat b_j(k) =\frac{\sum_{i=1}^{S} \sum_{t=1}^{T} I\left(i_t^i=q_{j}, o_{t}^i=v_{k}\right) }{\sum_{i=1}^{S} \sum_{t=1}^{T} I\left(i_{t}^i=q_{j}\right)} \end{aligned} π^i=S∑j=1SI(i1j=qi)α^ij=∑k=1S∑t=1T−1I(itk=qi)∑k=1S∑t=1T−1I(itk=qi,it+1k=qj)b^j(k)=∑i=1S∑t=1TI(iti=qj)∑i=1S∑t=1TI(iti=qj,oti=vk)
算法实现
生成数据
data = []
for i in range(100):
I,O = generate(100)
data.append([I,O])
定义模型
class SupervisedModel:
def __init__(self,M,N) -> None:
self.M = M
self.N = N
def train(self,data):
# data:Sx2xT
# [[[i1,i2,...],[o1,o2,...]],[],[]]
self.pi = np.zeros(shape=(self.N,))
self.A = np.zeros(shape=(self.N,self.N))
self.B = np.zeros(shape=(self.N,self.M))
S = len(data)
self.T = len(data[0][0])
# 求 pi
for i in range(self.N):
for j in range(S):
self.pi[i] += data[j][0][0]==i
self.pi[i] = self.pi[i]/S
# 求 A
for i in range(self.N):
for j in range(self.N):
fenzi = 0
fenmu = 0
for k in range(S):
for t in range(self.T-1):
fenzi += data[k][0][t]==i and data[k][0][t+1]==j
fenmu += data[k][0][t]==i
self.A[i][j] = fenzi/fenmu
# 求 B
for j in range(self.N):
for k in range(self.M):
fenzi = 0
fenmu = 0
for i in range(S):
for t in range(self.T):
fenzi += data[i][0][t]==j and data[i][1][t]==k
fenmu += data[i][0][t]==j
self.B[j][k] = fenzi/fenmu
return self.pi,self.A,self.B
def predict(self,O):
# 初值
beta = np.ones(shape=(self.T,))
# 递推
for o in reversed(O):
temp = np.zeros_like(beta)
for i in range(self.T):
for j in range(self.T):
temp[i] += beta[j]*self.B[j][o]*self.A[i][j]
beta = temp
# 终止
res = 0
for i in range(self.T):
res += self.B[i][O[0]]*beta[i]*self.pi[i]
return res
训练模型
model = SupervisedModel(2,4)
model.train(data)
(array([0.19, 0.25, 0.2 , 0.36]),
array([[0. , 1. , 0. , 0. ],
[0.38930233, 0. , 0.61069767, 0. ],
[0. , 0.4073957 , 0. , 0.5926043 ],
[0. , 0. , 0.49933066, 0.50066934]]),
array([[0.47313084, 0.52686916],
[0.30207852, 0.69792148],
[0.60162602, 0.39837398],
[0.80851627, 0.19148373]]))
可以看到监督学习的效果非常好
三、解码问题(Decoding)
解码问题就是求 a r g m a x P ( I ∣ O , λ ) argmaxP(I|O,\lambda) argmaxP(I∣O,λ)
Viterbi算法
Viterbi算法事实上是一个动态规划的算法
这个图来自知乎
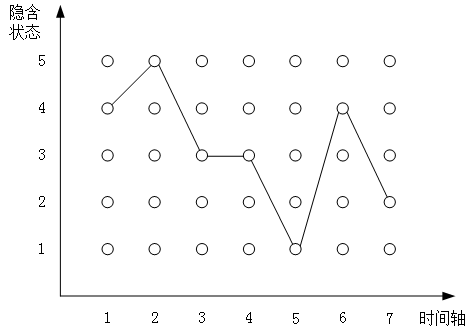
我们把概率当成距离
那么只要确定了唯一的终点,到这个终点的最大距离必然等于到前一个时间轴5个点的最大距离分别乘以这5个点到终点的距离
我们也可以用公式严格推导出这一性质
定义距离为
δ t ( i ) = m a x i 1 , i 2 , . . . , i t − 1 P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t − 1 , i t = q i ) \delta_t(i) = \underset{i_1,i_2,...,i_{t-1}}{max} P(o_1,o_2,...,o_t,i_1,i_2,...,i_{t-1},i_t=q_i) δt(i)=i1,i2,...,it−1maxP(o1,o2,...,ot,i1,i2,...,it−1,it=qi)
δ i + 1 ( i ) = m a x i 1 , i 2 , . . . , i t P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t − 1 , i t , i t + 1 = q i ) = m a x i 1 , i 2 , . . . , i t P ( o t + 1 ∣ i t + 1 = q i ) ⋅ P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t , i t + 1 = q i ) = b i ( o t + 1 ) ⋅ m a x i 1 , i 2 , . . . , i t P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t , i t + 1 = q i ) = b i ( o t + 1 ) ⋅ m a x j m a x i 1 , i 2 , . . . , i t − 1 P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t = q j , i t + 1 = q i ) = b i ( o t + 1 ) ⋅ m a x j m a x i 1 , i 2 , . . . , i t − 1 P ( i t + 1 = q i ∣ i t = q j ) ⋅ P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t = q j ) = b i ( o t + 1 ) ⋅ m a x j m a x i 1 , i 2 , . . . , i t − 1 α j i ⋅ P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t = q j ) = b i ( o t + 1 ) ⋅ m a x j ( α j i ⋅ m a x i 1 , i 2 , . . . , i t − 1 P ( o 1 , o 2 , . . . , o t , i 1 , i 2 , . . . , i t = q j ) ) = b i ( o t + 1 ) ⋅ m a x j ( α j i ⋅ δ t ( j ) ) \begin{aligned} \delta_{i+1}(i) &= \underset{i_1,i_2,...,i_t}{max} P(o_1,o_2,...,o_t,i_1,i_2,...,i_{t-1},i_t,i_{t+1}=q_i) \\ &= \underset{i_1,i_2,...,i_t}{max} P(o_{t+1}|i_{t+1}=q_i)\cdot P(o_1,o_2,...,o_t,i_1,i_2,...,i_t,i_{t+1}=q_i) \\ &=b_i(o_{t+1})\cdot \underset{i_1,i_2,...,i_t}{max} P(o_1,o_2,...,o_t,i_1,i_2,...,i_t,i_{t+1}=q_i) \\ &=b_i(o_{t+1})\cdot \underset{j}{max}\underset{i_1,i_2,...,i_{t-1}}{max}P(o_1,o_2,...,o_t,i_1,i_2,...,i_t=q_j,i_{t+1}=q_i) \\ &=b_i(o_{t+1})\cdot \underset{j}{max}\underset{i_1,i_2,...,i_{t-1}}{max}P(i_{t+1}=q_i|i_t=q_j)\cdot P(o_1,o_2,...,o_t,i_1,i_2,...,i_t=q_j) \\ &=b_i(o_{t+1})\cdot \underset{j}{max}\underset{i_1,i_2,...,i_{t-1}}{max}\alpha_{ji}\cdot P(o_1,o_2,...,o_t,i_1,i_2,...,i_t=q_j) \\ &=b_i(o_{t+1})\cdot \underset{j}{max}\left( \alpha_{ji}\cdot \underset{i_1,i_2,...,i_{t-1}}{max}P(o_1,o_2,...,o_t,i_1,i_2,...,i_t=q_j)\right) \\ &=b_i(o_{t+1})\cdot \underset{j}{max}\left( \alpha_{ji}\cdot \delta_t(j)\right) \\ \end{aligned} δi+1(i)=i1,i2,...,itmaxP(o1,o2,...,ot,i1,i2,...,it−1,it,it+1=qi)=i1,i2,...,itmaxP(ot+1∣it+1=qi)⋅P(o1,o2,...,ot,i1,i2,...,it,it+1=qi)=bi(ot+1)⋅i1,i2,...,itmaxP(o1,o2,...,ot,i1,i2,...,it,it+1=qi)=bi(ot+1)⋅jmaxi1,i2,...,it−1maxP(o1,o2,...,ot,i1,i2,...,it=qj,it+1=qi)=bi(ot+1)⋅jmaxi1,i2,...,it−1maxP(it+1=qi∣it=qj)⋅P(o1,o2,...,ot,i1,i2,...,it=qj)=bi(ot+1)⋅jmaxi1,i2,...,it−1maxαji⋅P(o1,o2,...,ot,i1,i2,...,it=qj)=bi(ot+1)⋅jmax(αji⋅i1,i2,...,it−1maxP(o1,o2,...,ot,i1,i2,...,it=qj))=bi(ot+1)⋅jmax(αji⋅δt(j))
推导完毕
但是上面还没有给出路径
对于给定终点,我们要知道到达它的上一个点
即
ψ t + 1 ( i ) = argmax j δ t ( j ) ⋅ a j i \psi_{t+1}(i)=\underset{j}{\operatorname{argmax}} \delta_{t}(j)\cdot a_{ji} ψt+1(i)=jargmaxδt(j)⋅aji
算法过程
(1)初值
δ 1 ( i ) = P ( o 1 , i 1 = q i ) = P ( o 1 ∣ i 1 = q i ) ⋅ P ( i 1 = q i ) = b i ( o 1 ) π i \delta_1(i) = P(o_1,i_1=q_i) = P(o_1\mid i_1=q_i)\cdot P(i_1=q_i) = b_i(o_1)\pi_i δ1(i)=P(o1,i1=qi)=P(o1∣i1=qi)⋅P(i1=qi)=bi(o1)πi
(2)递推
δ i + 1 ( i ) = b i ( o t + 1 ) ⋅ m a x j ( α j i ⋅ δ t ( j ) ) ψ t + 1 ( i ) = argmax j ( δ t ( j ) ⋅ a j i ) \begin{aligned} \delta_{i+1}(i) &= b_i(o_{t+1})\cdot \underset{j}{max}\left( \alpha_{ji}\cdot \delta_t(j)\right) \\ \psi_{t+1}(i) &= \underset{j}{\operatorname{argmax}}(\delta_{t}(j)\cdot a_{ji}) \end{aligned} δi+1(i)ψt+1(i)=bi(ot+1)⋅jmax(αji⋅δt(j))=jargmax(δt(j)⋅aji)
(3)终止
P ∗ = m a x 1 ⩽ i ⩽ N δ T ( i ) i T ∗ = a r g m a x 1 ⩽ i ⩽ N [ δ T ( i ) ] \begin{array}{c} P^{*}=\underset{
{1 \leqslant i \leqslant N}}{max} \delta_{T}(i) \\ i_{T}^{*}=\underset{
{1 \leqslant i \leqslant N}}{argmax}\left[\delta_{T}(i)\right] \end{array} P∗=1⩽i⩽NmaxδT(i)iT∗=1⩽i⩽Nargmax[δT(i)]
(4)回溯(对 t t t 从 T − 1 , T − 2 , . . . , 1 T-1,T-2,...,1 T−1,T−2,...,1)
i t ∗ = a r g m a x 1 ⩽ i ⩽ N [ δ t ( i ) ] i_t^* = \underset{
{1 \leqslant i \leqslant N}}{argmax}\left[\delta_{t}(i)\right] it∗=1⩽i⩽Nargmax[δt(i)]
算法实现
import numpy as np
pi= [0.25,0.25,0.25,0.25]
A = [
[0, 1, 0, 0 ],
[0.4,0,0.6,0],
[0,0.4,0,0.6],
[0,0,0.5,0.5]
]
B = [
[0.5,0.5],
[0.3,0.7],
[0.6,0.4],
[0.8,0.2]
]
定义模型
class Model:
def __init__(self,pi,A,B) -> None:
self.pi = np.array(pi)
self.A = np.array(A)
self.B = np.array(B)
self.N = len(A)
self.M = len(B[0])
def decode(self,O):
T = len(O)
delta = np.zeros(shape=(T,self.N))
fi = np.zeros(shape=(T,self.N),dtype=int)
# 初始化
delta[0] = self.B[:,O[0]]*self.pi
# 前向计算
for t in range(0,T-1):
for i in range(self.N):
p = self.A[:,i]*delta[t]
delta[t+1][i] = self.B[i,O[t+1]]*p.max()
fi[t+1][i] = p.argmax()
#回溯
I = []
index = delta[T-1].argmax()
I.append(index)
for t in reversed(range(1,T)):
index = fi[t,index]
I.insert(0,index)
return I
解码
model = Model(pi,A,B)
I,O = generate(5)
print(I)
print(O)
model.decode(O)