这里系列文章Prometheus+Grafana监控安装使用 (1)Prometheus介绍(2)Prometheus+Grafana安装配置
(1)Prometheus介绍(2)Prometheus+Grafana安装配置
前言
Prometheus是一套开源的监控&报警&时间序列数据库的组合,采集的样本以时间序列的方式保存在内存(TSDB时序数据库),并定期保存到硬盘中。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Prometheus介绍
1.1 Prometheus是什么?
Prometheus是一套开源的监控&报警&时间序列数据库的组合,采集的样本以时间序列的方式保存在内存(TSDB时序数据库),并定期保存到硬盘中。
它专门用于监控那些运行在容器中的微服务。每经过一个时间间隔,数据都会从运行的服务中流出,存储到一个时间序列数据库中,这个数据库之后可以通过PromQL语言查询。另外,因为数据是以时间序列存储的,当出现问题时,可以根据这些时间间隔进行诊断,另外还可以预测基础设施的长期监控趋势----这是Prometheus的两大功能。
1.2 Prometheus特点
- 数据模型:多维数据模型(时序列数据由metric和key/value标签组成)
- 查询:在多维度上强大灵活的查询语言(PromQL)
- 获取数据方式:基于HTTP的pull方式周期性采集时序数据
- 采用push gateway进行时序列数据推送(pushing)
- 高效存储采样数据
二、Prometheus组成与原理
2.1 Prometheus组成
- Prometheus Server:服务器,负责数据采集存储,和PromQL查询,本身是一个时序数据库,将采集到的监控数据按时间序列方式存储本地磁盘
Alertmanager:告警管理器,从Server接到告警通知,通过去重、分组、路由、向用户发送告警信息。 - Push Gateway: Push网关,因为Prometheus数据采集基于HTTP的Pull模型进行采集,必须使Server能与Exporter通信,如果不能,利用PushGateway中转,Server也可用Pull方式从PushGateway获取到监控数据。
- Pull:直接使用采集数据客户端xxx_exporters将数据传输给Prometheus。
- Exporters:周期性抓取数据采集一些web服务、mysql服务。
- Client Library: 客户端数据库,目的在于为那些期望原生提供InstrumenLalion功能的应用程序提供便捷的开发途径,用于检测应用程序代码。
- Alertmanager:从Prometheus Server接收到“告警通知”后,通过去重、分组、路由等预处理功能后,高效地向用户完成告警信息的发送:DataVisualization:Prometheus Web UI、Grafana。
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
Push 模式:这种模式,可以灵活的在被监控端使用各种语言编写数据采集脚本,通过PushGateway传输给Prometheus,传输方式为http;
Pull 模式:直接使用采集数据客户端xxx_exporters将数据传输给Prometheus,已经有很多xxx_exporters详见官档,同样也是http。
PushGateway(短周期任务)允许短暂和批量作业将其指标暴露给Prometheus。这类作业存在时间不足已被删除,将其指标推送到PushGateway,然后将这些指标暴露给Prometheus Server,用于业务数据汇报等。
Exporters(常规任务-守护进程):采集一些web服务、nginx,mysql服务。如Mysql服务不适合直接通过HTTP采集数据,通过下载mysql exporter采集数据。
2.2 Prometheus整体架构
下图说明了 Prometheus 的架构及其一些生态系统组件:
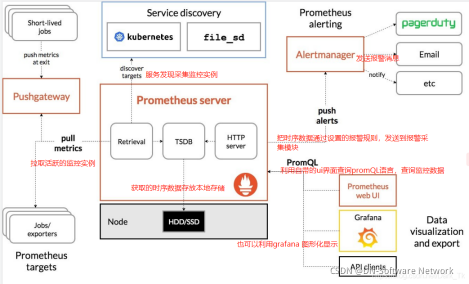
- Prometheus Server可以定期从活跃的目标监控主机上pull监控数据,目标监控主机可以通过配置静态job或者服务发现的方式被Prometheus。Server采集到的,这种方式默认为pull方式拉取指标,也可以通过pushgateway收集目标监控数据报给Prometheus Server,也可通过自带的Exporters采集数据。
- Prometheus把采集的监控指标数据保存到本地磁盘或数据库中。
- Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到Altermanager。
- Altermanager通过配置报警接收方,发送报警到邮箱等
- Prometheus自带的web ui界面提高Promeql查询语言,可以查询监控数据。
下图展示的是Prometheus应用流程
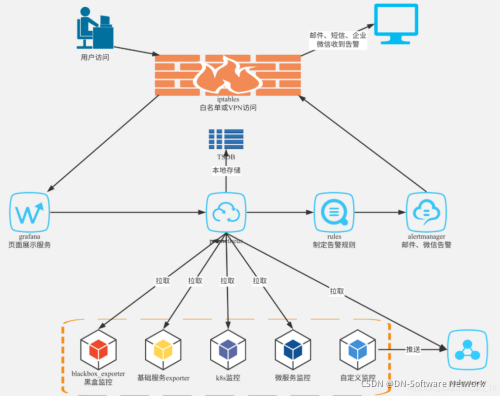
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
Prometheus根据配置定时去拉取各个节点的数据,默认使用的拉取方式是pull,也可以使用Pushgateway提供的push方式获取各个监控节点的数据。将获取到的数据存入TSDB,一款时序型数据库。此时Prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供,Alertmanager是Prometheus的告警管理和发送报警的一个组件。Prometheus原生的图标功能过于简单,可将Prometheus数据接入Grafana,由Grafana进行统一管理。
Grafana可以介入Prometheus数据源,展示监控数据。
代码如下(示例):
2.3 Prometheus基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。 不需要任何SDK或者其他的集成过程。非常适合做虚拟化环境监控系统,如VM、Docker、Kubernetes输出被监控组件信息的HTTP接口被叫做exporter。Prometheus支持通过三种类型的途径从目标上“抓取(Scrape) "指标数据(基于白盒监控) :(如下图)
Exporters 周期性的抓取数据
Instrumentation 监控对象内部
Pushgateway–专门对接数据保存
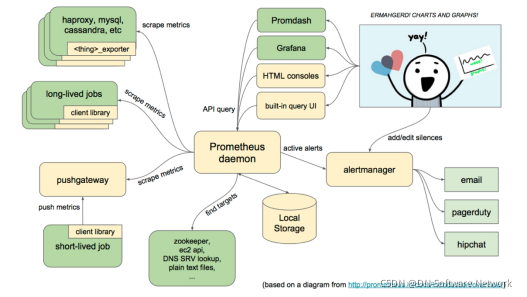
Prometheus同其他TSDB相比有一个非常典型的特性:它主动从各个Target拉取Pull数据,而非等待被控制的推送push,Prometheus的根本目标在于收集在Target上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统。
Prometheus从根本上存储的所有数据都是时间序列, 每一个时间序列数据由metric度量指标名称和它的标签labels键值对集合唯一确定。这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。
三、Prometheus同类型监控产品对比
3.1 Prometheus 与Graphite
3.1.1 范围
Graphite专注于成为具有查询语言和图形功能的被动时间序列数据库。任何其他问题都由外部组件解决。
Prometheus 是一个完整的监控和趋势系统,包括基于时间序列数据的内置和主动抓取、存储、查询、图形和警报。
3.1.2 数据模型
Graphite 存储命名时间序列的数字样本,就像 Prometheus 所做的那样。然而,Prometheus 的元数据模型更丰富:虽然 Graphite 度量名称由隐式编码维度的点分隔组件组成,但 Prometheus 将维度显式编码为键值对,称为标签,附加到度量名称。这允许通过查询语言通过这些标签轻松过滤、分组和匹配。
3.1.3 存储
Graphite 以Whisper格式将时间序列数据存储在本地磁盘上,这是一种 RRD 风格的数据库,期望样本定期到达。每个时间序列都存储在一个单独的文件中,新样本在一定时间后覆盖旧样本。
Prometheus 还为每个时间序列创建一个本地文件,但允许在发生刮擦或规则评估时以任意间隔存储样本。由于只是简单地追加了新样本,因此旧数据可能会保留任意长的时间。Prometheus 也适用于许多短期、频繁变化的时间序列集。
3.1.4 总结
Prometheus 提供更丰富的数据模型和查询语言,此外更易于运行和集成到环境中。如果想要一个可以长期保存历史数据的集群解决方案,Graphite 可能是更好的选择。
3.2 Prometheus 与InfluxDB
InfluxDB是一个开源时间序列数据库,具有用于扩展和集群的商业选项。
3.2.1 范围
将Kapacitor与 InfluxDB 一起考虑 ,因为它们结合起来解决与 Prometheus 和 Alertmanager 相同的问题空间。
Kapacitor 的范围是 Prometheus 记录规则、警报规则和 Alertmanager 的通知功能的组合。Prometheus为图形和警报提供了更强大的查询语言。Prometheus Alertmanager 还提供分组、重复数据删除和静音功能。
3.2.2 数据模型
和 Prometheus 一样,InfluxDB 数据模型有键值对作为标签,称为标签。
InfluxDB 使用日志结构合并树的变体来存储带有预写日志,按时间分片。这比 Prometheus 的每个时间序列的仅附加文件方法更适合事件记录。
3.2.3 结构
Prometheus 服务器彼此独立运行,仅依赖其本地存储来实现其核心功能:抓取、规则处理和警报。
商业 InfluxDB 产品在设计上是一个分布式存储集群,其中的存储和查询同时由多个节点处理。类似于 Prometheus 本身。Influx提供Enterprise Kapacitor,它支持 HA/冗余警报系统。与之相比,Prometheus 和 Alertmanager 通过运行 Prometheus 的冗余副本和使用 Alertmanager 的高可用性 模式提供了一个完全开源的冗余选项 。
3.2.4 总结
两者存在类似之处,都有标签来有效支持多维指标。都有基本相同的压缩算法。
InfluxDB 仅仅是时间序列数据库,没有其他监控相关的功能。
InfluxDB更好的地方:
适合于事件记录
商业版本的提供集群,更适合长期数据存储
副本之间最终的一致的数据视图。
Prometheus更好的地方:
适合于指标
更强大的查询语言、警报和通知功能
图形和警报的更高可用性和正常运行时间。
3.3 Prometheus 与OpenTSDB
3.3.1 范围
与Graphite相同的差异范围
3.3.2 数据模型
OpenTSDB 的数据模型几乎与 Prometheus 的相同:时间序列由一组任意键值对标识(OpenTSDB 标签是 Prometheus 标签)。Prometheus 允许标签值中包含任意字符,而 OpenTSDB 的限制性更强。
3.3.3 存储
OpenTSDB的存储是在Hadoop和HBase之上实现的 。这意味着水平扩展 OpenTSDB 很容易,但是您必须从一开始就接受运行 Hadoop/HBase 集群的整体复杂性。
Prometheus 最初运行起来会更简单
3.3.4 总结
Prometheus 提供了更丰富的查询语言,可以处理更高的基数指标,并构成完整监控系统的一部分。如果您已经在运行 Hadoop 并且重视长期存储的这些好处,那么 OpenTSDB 是一个不错的选择。
总结
Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
对于集群化和水平扩展,官方和社区都没有说明,需要合理选择 Federate、Cortex、Thanos等方案。
监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。
参考网址:
监控神器-普罗米修斯Prometheus的安装
Prometheus+Grafana+Altermanager监控告警
Prometheus中文文档
Prometheus介绍